一、Sqoop简介
官方文档:http://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html
参考命令文档:http://www.360doc.com/content/16/1116/10/37253246_606951065.shtml
1.产生背景
早期由于技术的匮乏,要首先非结构和和结构化同步,是非常困难的,Hadoop生态研发了sqoop这样的一个同步工具,主要是实现异构化数据同步,不过sqoop更新较慢,因为sqoop工具比较小,最新版本是1.4.7
基于Hadoop生态的一个早期同步工具,可以集成在数据仓库中,实现数据同步操作,可以导入,也可以抽取。类似的工具有 datax、kettle、canal
2.原理
底层使用的是MapReduce的maptask完成数据的导入导出,虽然能并行执行,但是依旧只能处理离线数据,不能实时导入导出。
3.Sqoop的特点
优点:可以跨平台进行数据传输
缺点:不够灵活,数据较少,更新较慢
MySQL<->HDFS
MySQL<->Hive
MySQL<->Hbase
二、基本语法
1.查询数据库和表
# 查看库
[root@hdp01 sqoop-1.4.7]# sqoop list-databases --connect jdbc:mysql://10.9.68.199:3306 --username root --password 123456
# 查看表
[root@hdp01 sqoop-1.4.7]# sqoop list-tables --connect jdbc:mysql://10.9.68.199/spark-1 --username root --password 123456
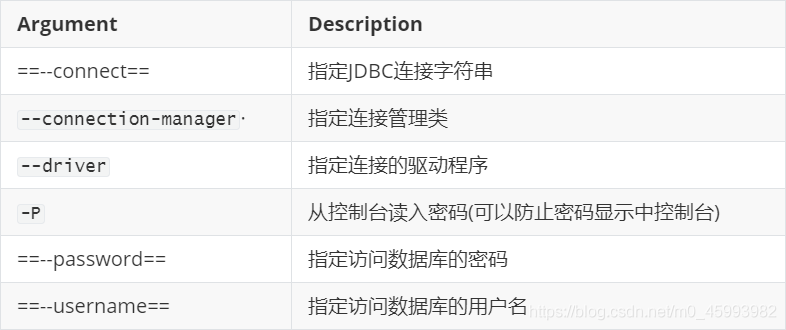
2.常用参数
3.增量导入
sqoop import \
--connect jdbc:mysql://10.9.68.199:3306/spark-1 \
--username root \
--password 123456 \
--check-column empno \
--incremental append \
--last-value '1' \
--query 'select * from emp where $CONDITIONS' \
--target-dir /sqoop/hdfs-emp/ \
-m 1
4.Job应用
使用job的方式可以自动维护last-value值,自动更新,每次导入都是根据新增的数据,进行添加,注意使用主键为导入的key
sqoop job --create jobTest \
-- import \
--connect jdbc:mysql://10.9.68.199:3306/spark-1 \
--username root \
--password 123456 \
--table emp \
--check-column empno \
--incremental append \
--last-value '0' \
--target-dir /sqoop/hdfs-emp/ \
-m 1
[root@hdp01 ~]# sqoop job --list
[root@hdp01 ~]# sqoop job -exec jobTest
版权声明:本文为m0_45993982原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。