混淆矩阵(Confusion Matrix)
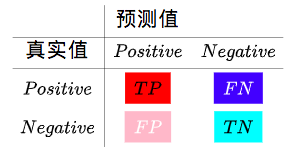
- 预测值为正(Positive),并且真实值也为正(Positive),预测为真(True),True Positive (TP)。
- 预测值为负(Negative),但是真实值为正(Positive),预测失败(False),False Negative (FN)。
- 预测值为正(Positive),但是真实值为负(Negative),预测失败(False),False Positive (FP)。
- 预测值为负(Negative),并且真实值也为负(Negative),预测为真(True),True Negative (TN)。
准确率(Accuracy)
既然我们是做预测,那自然希望我们做出的预测尽可能的准确,准确率就是在所有样本数中,我们做出正确预测(True)的样本比例。在图中就是
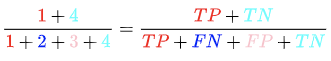
准确率(Accuracy)的适用场景:
不同的分类是同等地位的,对猫狗喜好进行分类,问题中并没有对猫和狗有特定的侧重,因此在这里我们只强调于分类的正确度,即准确率。
精确率(Precision)
但更一般的分类问题,对于类别往往有所侧重,例如银行进行用户违约预测的例子中,银行更关注的是那些少量的违约案例,因为这关系到贷出资金能否收回,涉及坏账率,因此需要一个针对于正预测(Positive)的指标,所以这里银行会更加看重所做出的正预测中,预测为真(True)的比例。
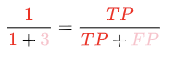
精确率(Precision)的适用场景:
因为预测为正但真实为负(FP)的成本很高,因此非常看重预测正样本预测的准确度。比如在银行对用户违约与否进行预测时,假如将客户分类为会违约,但客户实际不违约,那么银行损失了一名客户,同时也损失了利息收入,所以银行会比较看重预测的精确度。
召回率(Recall)
召回率又可以被翻译为查全率,同样基于对于正(Positive)案例的指标。但与精确率不同之处在于,召回率更加侧重真实为正(Positive)的样本中被成功预测的比例。

召回率(Recall)的适用场景:
在真实值为正,而未被成功预测为正(FN)的成本很高,因此非常看重真实为正样本被正确预测的比例。比如在流行病的案例中,如果真实为正而未被正确预测,即本身患病而被判断为不患病,那么对于社会公共安全造成极大危害,后果严重,所以这里会很看重召回率。
总结:
- precision是从已经预测为同一类别的样本抽样。是针对预测结果而言的,表示:预测样本为正的样本中有多少是真正的正样本。
- recall是从dataset的同一类的样本抽样。是针对原来样本而言的,表示:样本中的正例有多少被预测正确。
但仔细想想,单纯以精确率或者召回率作为度量标准其实存在一个很大的问题,让我们因为虽然真实的类别是已经存在的客观事实,我们可以通过主观地修改预测比例来“调整”混淆矩阵,从而有意提高精确率或召回率。
例如,银行若仅以精确率为度量标准,非常谨慎地进行正预测,那么只给收入最低、学历最低、工作没有保障的少量用户分类为正(Positive),判断他们将无力偿还贷款,那精确度将非常高。但这种做法会使很多其他方面有问题,而无力偿还贷款的人不被判定为违约者,而给他们发放贷款,造成资金无法收回,坏账率提高。
又比如,假设在流行病检验中,假设检疫局仅以召回率作为唯一度量标准进行分类,那么将以非常松散的标准进行正(Positive)分类,将大部分人预测为患病。这样操作会使召回率非常高(想象一下极端情况下将所有样本预测为正,召回率将为100%),但同时很多未患病的人会被误分类为患病,造成很多不必要的隔离措施。
F值
因此,在实际情况中,不会有分类器仅仅以精确度(Precision)或者召回率(Recall)作为单一的度量标准,而是使用这两者的调和平均,于是就有了F值(F-Score),F值的一般表达式为:


在实际过程中,我本以为二分类的话只能是0,1。(类别可以,但我理解的是分数iou这种吧,其实这种可以直接用)
>>> from sklearn.metrics import f1_score
>>> y_true = [0, 1, 2, 0, 1, 2]
>>> y_pred = [0, 2, 1, 0, 0, 1]
>>> f1_score(y_true, y_pred, average='macro')
0.26...
>>> f1_score(y_true, y_pred, average='micro')
0.33...
>>> f1_score(y_true, y_pred, average='weighted')
0.26...
>>> f1_score(y_true, y_pred, average=None)
array([0.8, 0. , 0. ])参考: