1 需求
在TDH集群环境获取jar包目录下dict.json文件,调用udf函数getDictName( ), 传入两个入参,分别是一级编码和二级编码(srcCode及srcSbuCode),最终返回值为"字典名称"(dictName)。
比如函数入参传入‘1001’和‘0’,返回值为“董事长”,入参传入‘1001’和‘3’,返回值为“财务负责人”。
2 思路分析
2.1 现有方案
对于解析字典的需求,现有做法是在大数据集群hdfs指定路径上传xml文件,通过调用udf函数,在udf函数逻辑中解析xml文件,获取字典名称。
该做法可以正常实现要求,但是也存在两个劣势:1) 需要在hdfs指定目录上传xml文件,否则无法读取到文件;2) 函数入参中除传入两个入参外,同时要求传入xml文件路径。如果路径错误或者没有传入,就存在执行失败或者无法解析出正确字典名称的问题。
2.2 优化方案
针对现有的解决方案,如何避免以上两个问题?是否存在优化方案,可以做到不上传xml文件到hdfs目录,同时函数只传入两个入参(srcCode及srcSbuCode),在满足以上前提下,可以正常获取返回值dictName。
需求已经明确了,接下来就是考虑如何实现需求。通过分析发现,可以通过以下步骤实现:
1)编写json文件,文件名称为“dict.json”(该文件需要满足json文件格式),上传至java工程项目中resources目录下;
2)在udf函数getDictName( )代码逻辑中编写解析json文件逻辑;
3)项目打包后上传jar包至集群指定的自定义函数目录(非hdfs路径);
4)在spark on yarn 模式下,通过sql调用udf函数getDictName( srcCode,srcSbuCode),传入两个入参后保证在集群环境下可以获取返回值dictName。
3 实现方案
3.1 编写Json文件
附:json文件格式
{
"1001":{
"0":"董事长",
"1":"控制人",
"2":"主要负责人",
"3":"财务负责人",
"4":"监事长"
},
"1002":{
"0":"证件地址",
"1":"联系地址",
"2":"家庭地址",
"3":"单位地址",
"4":"户籍地址",
"5":"出生地址"
},
......
}
3.2 编写udf函数
3.2.1 编写函数工具类
package com.ccsg.udf.utils;
/**
* @author allan
* @version 1.0
* @date 2022/3/5 21:43
* @desc 读取文件工具类
*/
import java.io.*;
public class FileUtil {
/**
* 读取文件文本内容
*
* @param inputStream
* @return 返回字符串
*/
public static String readFile(InputStream inputStream) throws IOException {
Reader reader = new InputStreamReader(inputStream, "utf-8");
int ch = 0;
StringBuffer sb = new StringBuffer();
while ((ch = reader.read()) != -1) {
sb.append((char) ch);
}
reader.close();
return sb.toString();
}
}
3.2.2 编写函数核心逻辑
package com.ccsg.udf.function.udf;
import com.alibaba.fastjson.JSON;
import com.ccsg.udf.utils.FileUtil;
import org.apache.commons.lang.StringUtils;
import org.apache.spark.sql.api.java.UDF2;
import java.io.InputStream;
import java.util.Map;
/**
* @author allan
* @version 1.0
* @date 2022/3/5 21:43
* @desc 字典转换
* @parm srcCode 及 srcSubCode
* @return dictName
*/
public class GetDictName implements UDF2<String, String, String> {
private static final String DEFAULT_DICT_NAME = " ";
public String call(String srcCode, String srcSubCode) throws Exception {
// 获取文件所在包路径,调用工具类FileUtil中方法readFile()读取json文件
InputStream inputStream = UDFGetDictName.class.getClassLoader().getResourceAsStream("dict.json");
String jsonStr = FileUtil.readFile(inputStream);
// 定义返回结果
String dictName = null;
// 数据结构为嵌套Map结构: Map<srcCode,Map<srcSubCode,dictName>>
if (StringUtils.isNotBlank(jsonStr) && StringUtils.isNotBlank(srcCode) && StringUtils.isNotBlank(srcSubCode)) {
// 解析json字符串,获取最终返回结果dictName
Map<String, Object> jsonMap = (Map) JSON.parse(jsonStr);
Map<String, String> destMap = (Map<String, String>) jsonMap.get(StringUtils.trim(srcCode));
if (null != jsonMap && null != destMap
&& jsonMap.containsKey(StringUtils.trim(srcCode))
&& destMap.containsKey(StringUtils.trim(srcSubCode))) {
dictName = destMap.get(StringUtils.trim(srcSubCode));
return dictName;
} else {
return DEFAULT_DICT_NAME;
}
}
return DEFAULT_DICT_NAME;
}
}
说明:
1)建议类中获取文件所在包路径方式:类名.class.getClassLoader().getResourceAsStream(“dict.json”);该方式支持本地和集群环境下正常找到json文件所在目录;
2)调用Json转map方式进行逻辑处理: Map<String, Object> jsonMap = (Map) JSON.parse(jsonStr)
3)已验证以下两种方式支持在本地环境找到文件所在目录,不支持集群环境,所以不作为优先考虑方式
方式1:String fileRelativePath = Thread.currentThread().getContextClassLoader().getResource(“dict.json”).getFile();
方式2:UDFGetDictName.class.getResource("/") + “dict.json”;
4)充分考虑数据场景,考虑代码健壮性,对可能传入错误参数 或者传入空值 进行优化处理,避免运行时报空指针异常;
5)以上udf函数编写使用spark中自定义函数框架,通过实现UFD2接口,重写call()方式处理,两个入参及返回值都为String类型。
3.2.3 本地环境main()方法自测
public static void main(String[] args) throws Exception {
GetDictName gdn = new GetDictName();
// 1 正确场景:" 1001", "0"
String result1 = gdn.call("1001", "0");
// 2 入参为空场景
String result2 = gdn.call(" ", " ");
String result3 = gdn.call("", " ");
String result4 = gdn.call(null, " ");
String result5 = gdn.call("1001", " ");
// 3 错误数据 "1100", "18" / "1100", "1" / "1001", "7"
String result6 = gdn.call("1100", "18");
String result7 = gdn.call("1100", "1");
String result8 = gdn.call("1001", "7");
System.out.println(result1);
System.out.println(result2);
System.out.println(result3);
System.out.println(result4);
System.out.println(result5);
System.out.println(result6);
System.out.println(result7);
System.out.println(result8);
}
返回结果:
只有result1存在返回值“董事长”,其他都返回默认值(空格)
3.3 打包注意事项
3.3.1 目录结构图
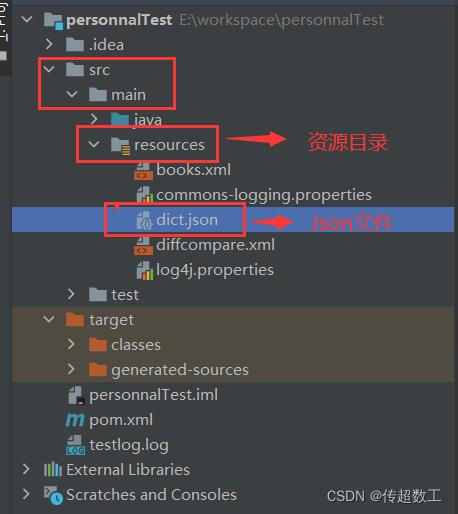
说明:在resources目录下上传指定Json文件,如idea中该目录不存在则新建即可。
3.3.2 pom.xml新增内容
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.xml</include>
<include>**/*.properties</include>
<include>**/*.json</include>
</includes>
<filtering>true</filtering>
</resource>
3.3.3 执行maven install效果
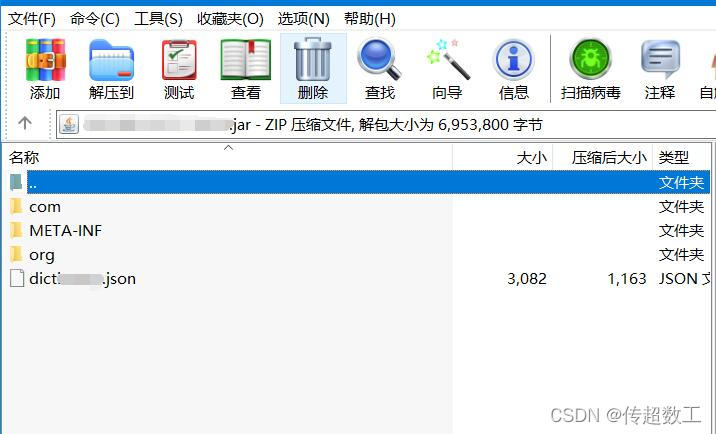
说明:可以看到打包后json文件在根目录下
3.4 TDH集群环境验证
1)上传jar包到集群指定自定义函数目录
2)sql中调用函数
select t.id_kind, GetDictName('1001',t.id_kind) as dict_name from person t where t.id_kind in ('0','1','2');
返回值:
id_kind dict_name
0 董事长
1 控制人
2 主要负责人
说明:项目中使用类名作为函数名称
4 回顾总结
1)充分考虑需求,结合Json文件格式和业务逻辑,合理设计实优化方案;
2)考虑使用udf函数,保证集群环境下找到Json文件目录并读取内容,重点验证获取路径方式,即优先考虑方式:类名.class.getClassLoader().getResourceAsStream(“dict.json”);
3)实现业务逻辑时充分考虑各种数据场景,增强代码健壮性;
4)本需求涉及IO流、反射、udf函数专业知识,需要对java及大数据基础有深入了解。