情况
VMware上安装了Linux系统,部署伪分布式hadoop2。我在Windows宿主机用IDEA或Eclipse编写MapReduce程序,提交任务之后,运行时报错:
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class WordCount$MyMapper not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2074)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:186)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:742)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.ClassNotFoundException: Class com.lance.common.entity.LineSplitMapper not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:1980)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2072)
... 8 more软硬件
JDK 1.7
Hadoop 2.6.0
CentOS 6.7
Windows 10
IDEA 2016
Spring Tool Suite Version: 3.7.3.RELEASE
hadoop-eclipse-plugin-2.7.1.jar
样例代码
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
String inputPath = "input/protocols";
String outputPath = "output";
// 获取Job ID
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://192.168.147.128:9000");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "192.168.147.128");
conf.set("mapreduce.app-submission.cross-platform", "true");
Job job = Job.getInstance(conf, "Word Count");
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMapper.class);
job.setCombinerClass(MyReducer.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path path = new Path(outputPath);
path.getFileSystem(conf).delete(path, true);
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
// 提交任务
if (job.waitForCompletion(true)) {
System.out.println("-----------------MR Finished-------------------");
}
System.out.println("Finished");
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
}
说明
我百度、必应、google、stackoverflow等都查过,解决方案无非是以下几种:
(1)setJarByClass(无效);
(2)用hadoop的eclipse插件(无效);
(3)Run as Hadoop(无效)
总而言之,下面的相关链接的内容都试过了
尝试
(1)手动打包成jar,上传到linux(运行成功)
(2)手动打包成jar,Windows下调用“hadoop jar ..”(运行成功)
(3)IDEA或Eclipse提交任务(都失败)
分析
提交mapreduce任务的原理是这样的,参考《Hadoop权威指南 第3版》P207:
(1)拷贝相关jar包、配置信息、分片信息到HDFS(默认10个备份),提交任务至master;
(2)slave节点分配到任务后,从HDFS取得上述数据,并运行;
(3)运行完毕后,删除上述jar包、配置信息xml等
报错的位置是ApplicationMaster,也就是说与客户端的代码无关,任务已经提交到master,并且准备运行了,但是缺少类(这个可以看上面的异常栈,看到YarnChild)。
直接运行jar包的结果,可以看到HDFS左侧有10个备份,右侧显示的job.jar就是运行时的jar包,job.xml就是Configuration的内容:
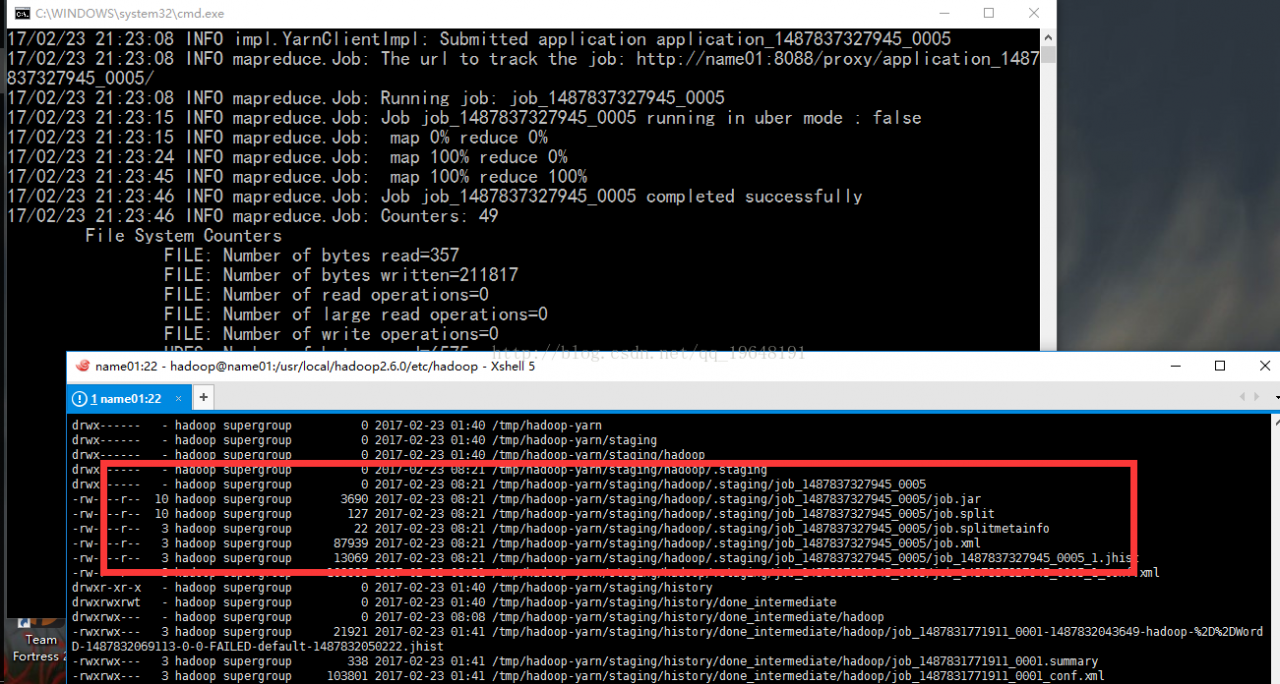
用IDE运行的情况,可以看到,是没有job.jar的,slave节点当然就拿不到Mapper/Reducer等类,但是由于有job.xml,所以可以拿到一串字符串表示Mapper/Reducer等类:

解决方案
(1)如果没有出现这种情况的,不太清楚,没试过其他的机子(确实有群友是可以正常运行的);
(2)打包成jar,然后运行jar;
(3)conf.set("mapred.jar", "E:\\WordCount.jar"); eclipse下执行wordcount报错 java.lang.ClassNotFoundException
简化做法
我个人比较懒,但是花了一周多的时间都没解决这个问题,所以准备按第三种方案来操作:
上面的代码中的Configuration要改成:
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("mapred-site.xml");
conf.addResource("yarn-site.xml");(1)Eclipse,将配置信息都设置放到core-site.xml等文件。然后每次运行前都要生成jar,这样是适用于每一个类的,代码里不用写这一段。实际发布时就将下面的mapred.jar删掉。
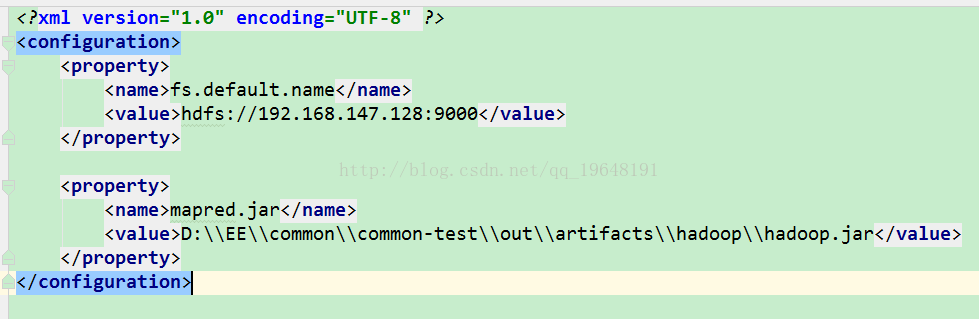
(2)IDEA,Intellij Idea 将java项目打包成jar,这个链接里就是IDEA打包jar的方法,下面我展示一下我的简化:
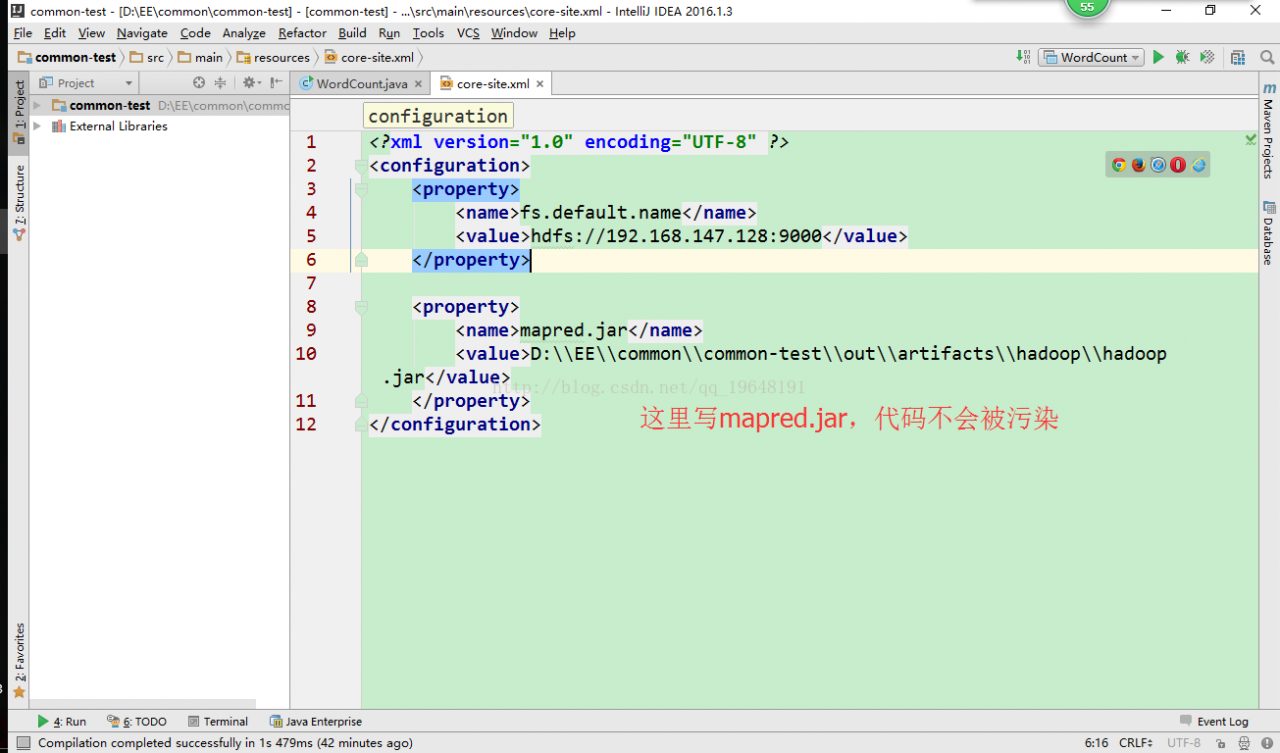
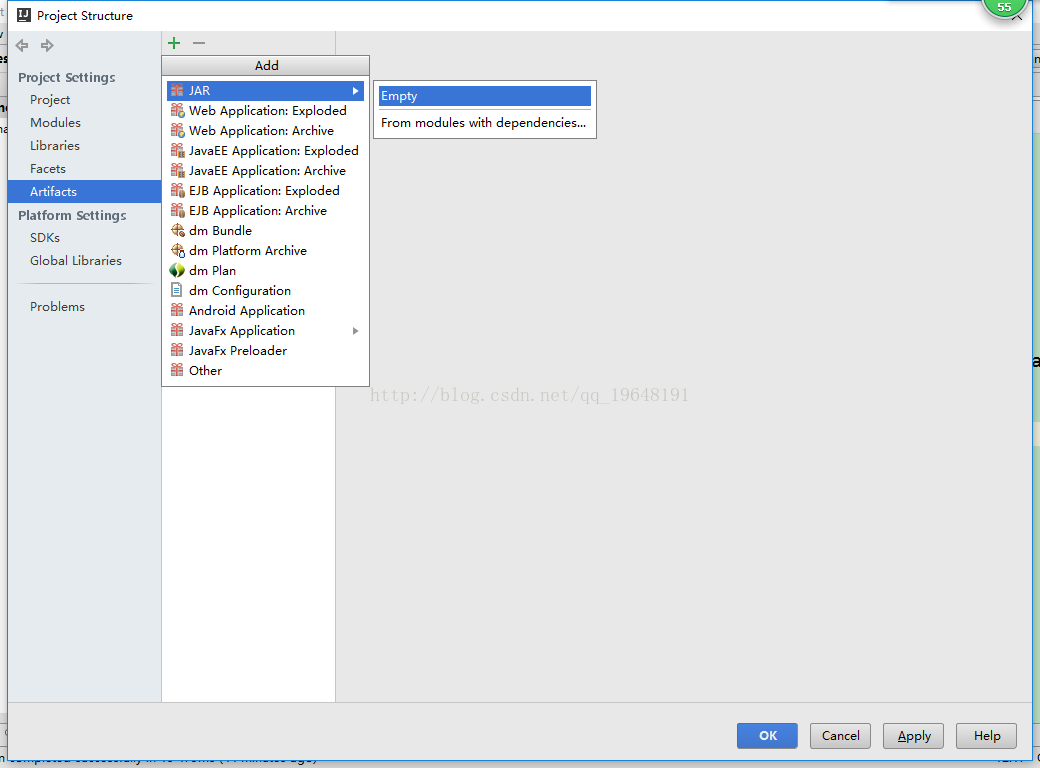
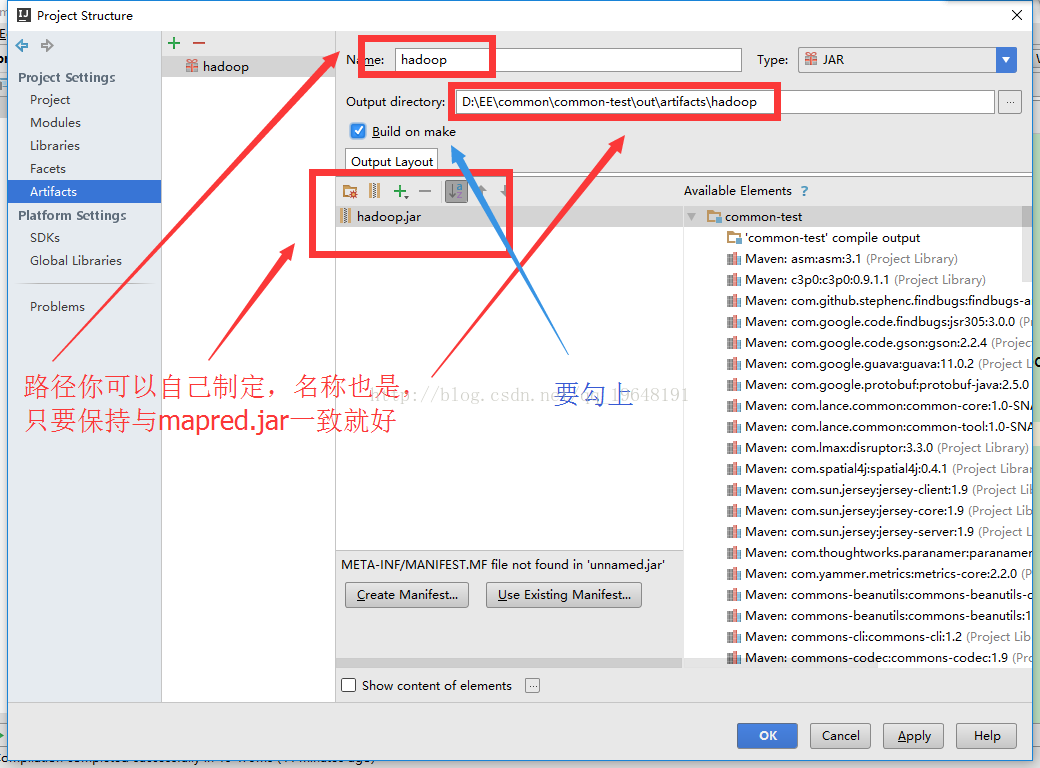
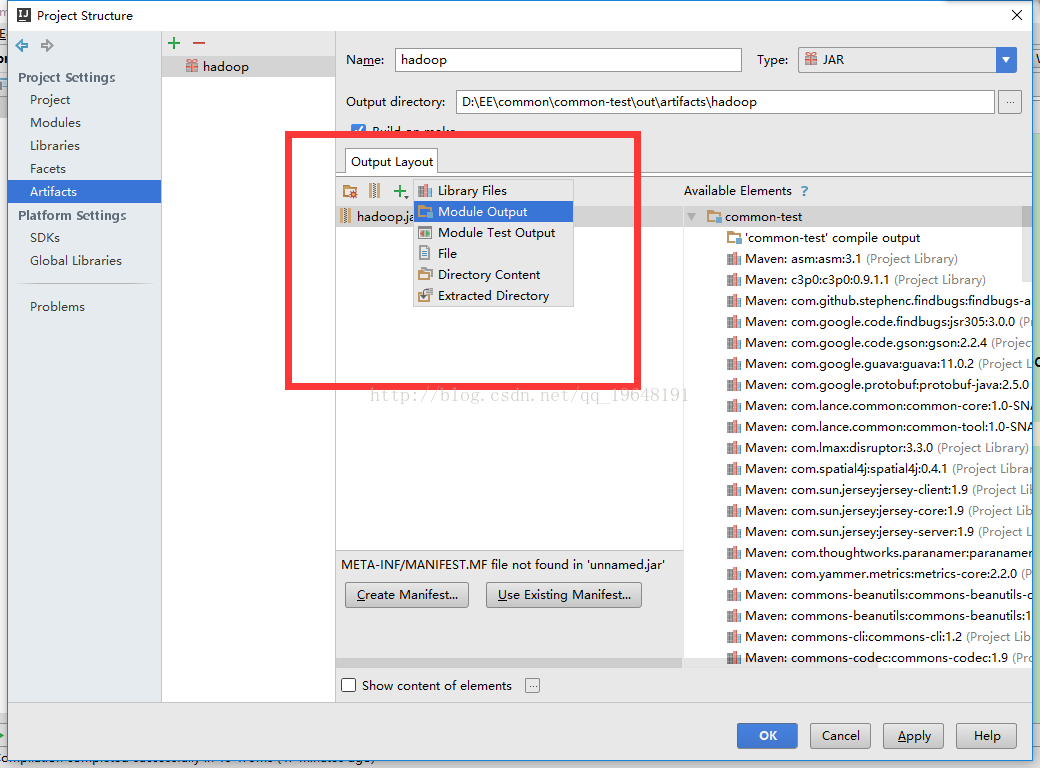
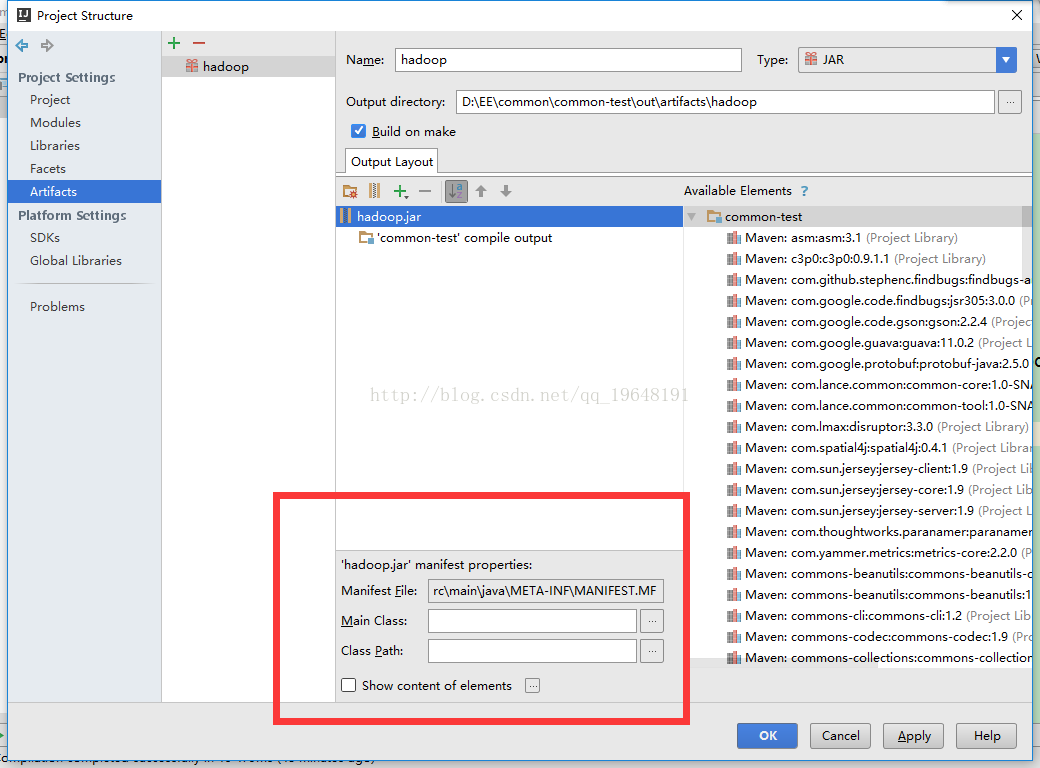
运行时,首先是Build-Make Project,生成了一个out文件夹,并且里面有hadoop.jar(这个可以随便改,没必要一定就叫hadoop.jar),然后再正常地运行java程序,这样就不会报错了。每次写程序,只要额外点一下Build-Make Project就好,又简单又方便:

相关链接
(1)Hadoop集群(第7期)_Eclipse开发环境设置
(2)WIN7下运行hadoop程序报:Failed to locate the winutils binary in the hadoop binary path