在上一篇文章《InfluxDB基础知识(一)》中主要介绍了时序数据库及InfluxDB的一些使用层面的基本概念,本篇将在上一篇的基础上进一步介绍InfuxDB中与底层存储相关的一些基础知识
目录
Database
InfluxDB中有Database的概念, 用户可以通过 CREATE DATABASE <DBNAME>的方式创建。
一个实例可以包含多个Database,一个Database可以包含多个mesurement。
RententionPolicy
简称RP,数据保留策略。用来指定数据的保留时间、副本数量以及每个shardgroup的时间跨度。shardgroup的概念将在后文介绍。RP创建语句如下:
CREATE RETENTION POLICY ON <retention_policy_name>
ON <database_name>
DURATION <duration>
REPLICATION <n> [SHARD DURATION <duration> ] [DEFAULT]其中retention_policy_name表示RP的名称,database_name表示数据库名称,duration表示数据保留时间,n表示数据副本数。SHARD DURATION将在后文介绍。例如在testdb创建一个只保留一天数据且副本数为1的RP:
CREATE RETENTION POLICY "one_day"
ON "testdb"
DURATION 1d
REPLICATION 1 SHARD DURATION 1h DEFAULT RP有如下特征:
- RP是Database的属性
- 一个Database可以包含多个RP,但只有一个默认RP
- 写入数据时可以指定RP写入,不指定则使用Database的默认RP,指定方式:在measurement前加指定RP的名称,例如:RP_oneday.measurement_name
ShardGroup & Shard
shardgroup
shardgroup是InfluxDB中一个重要的逻辑概念,它负责指定时间跨度的数据存储,这个时间跨度就由上文提到的创建RP时指定。如果没有指定,系统将通过RP的数据保留时间来计算:

不同shardgroup的时间跨度不会重叠。shardgroup实现了数据按时间分区,这样做的目的是什么?
1. 一定程度上缓解数据写入热点问题
2. 加快数据删除效率
将数据按照时间分割成小的粒度会使得数据过期实现非常简单,InfluxDB中数据过期删除的执行粒度就是Shard Group,系统会对每一个Shard Group判断是否过期,而不是一条一条记录判断。InfluxDB没有提供删除和更新数据的接口,数据只能通过RP进行删除
3. 加快数据按时间维度查找的效率
实现了将数据按照时间分区的特性。将时序数据按照时间分区是时序数据库一个非常重要的特性,基本上所有时序数据查询操作都会带有时间的过滤条件,比如查询最近一小时或最近一天,数据分区可以有效根据时间维度选择部分目标分区,淘汰部分分区
shard
从前文介绍的shardgroup的字面含义可知,一个shardgroup包含多个shard(单机版本只有1个),Shard是InfluxDB中真正存储数据以及提供读写服务的概念,Shard是InfluxDB的存储引擎实现,具体称之为TSM(Time Sort Merge Tree) Engine,负责数据的编码存储、读写服务等。如下图:
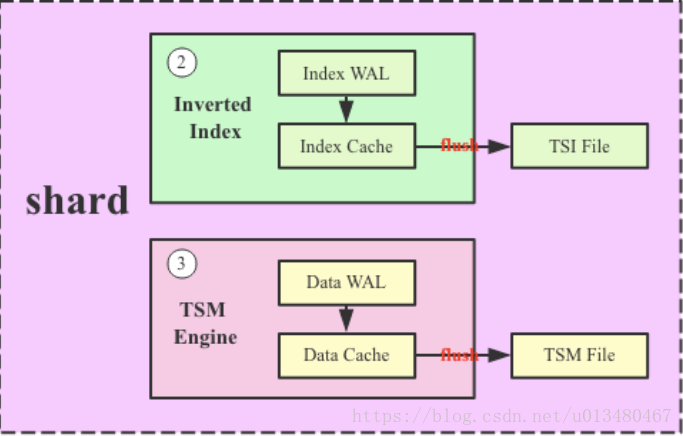
shard中各个小模块的作用及结构将在接下来的几篇文章中详细介绍。
sharding
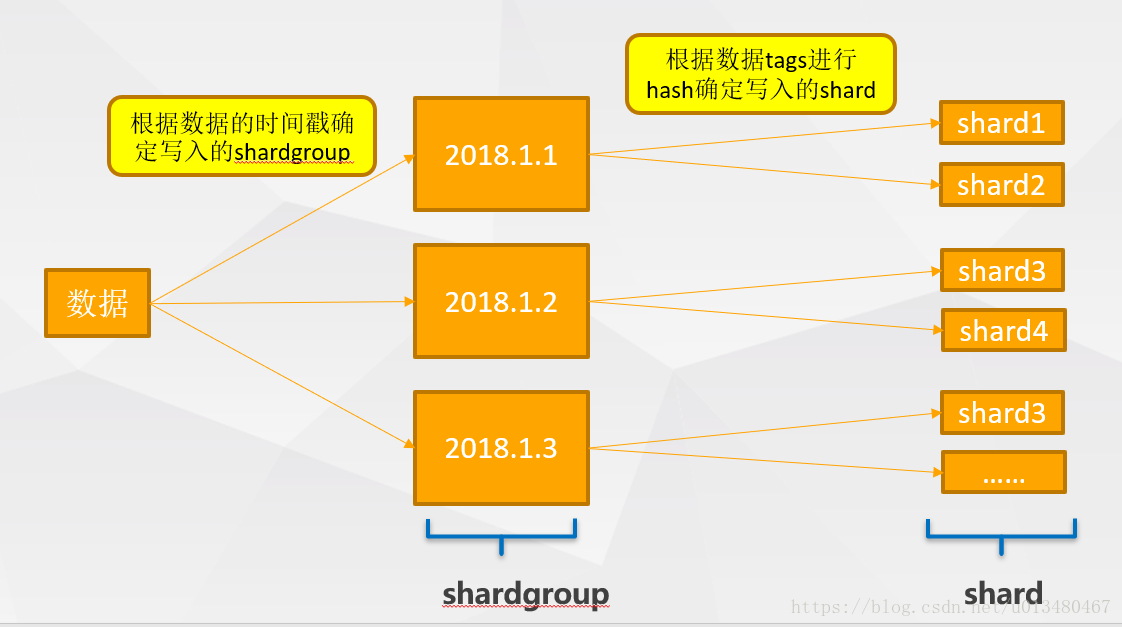
Shard Group对数据按时间进行了分区,那落在一个Shard Group中的数据又是如何映射到哪个Shard上呢?
这里我们就要说要InfluxDB的sharding策略。InfluxDB的sharding策略,在确定数据应该写入哪个shardgroup之后,会根据series进行hash,决定数据写入shardgroup下的哪个shard。
关系图示例:
本篇主要简单介绍了InfluxDB中DB、RP、Shardgroup、Shard、Sharding几个概念,这些概念对了解InfluxDB的存储引擎非常重要。