
Surpise包之协同过滤
一. CoClustering
这是一个基于聚类的协同过滤算法,该算法是根据文献【1】来实现的。该算法的主要思想是分别将user和item进行分类(类似分桶),然后根据类中心来进行预测。其预测函数如下:

其中,
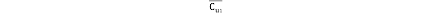
是用户u和item i所在的联合类中的所有成员的分数均值,类中的成员以(u,i)的形式存在。
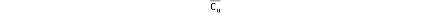
是用户u所在的用户类中的所有成员的分数均值,
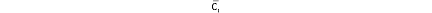
是item i所在的item 类中的所有成员的分数均值,
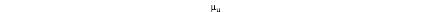
是用户u历史上打过的所有的分值的均值,
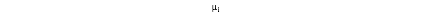
是item i得到的所有分数的均值。
Surprise包在实现该算法时,逻辑如下:
1) 初始化所有item和user所属的类
2) 计算

3) 更新每一个item和user所属的类
4) 跳转到2)循环进行
步骤3)中的user所属类的更新逻辑是:遍历每一个打分记录,对于当前的记录(u,i,rating),假设用户u依次属于每一个类别,item i的类别不变,然后使用用户u历史上评价过低所有item计算该类别下的误差,然后取误差最小的类别来更新用户u所属的类别。Item所属类别的更新逻辑类似。
二. SlopeOne
这是迄今为止非常简单且有效的一种完全基于统计的协同过滤算法, 该算法是根据文献【2】来实现的。该算法的主要思想是通过当前用户打分的所有item与当前item i在同一用户下的得分偏差总和来估算当前用户对item i的打分。其预测函数如下:


其中,
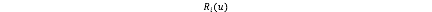
表示用户u所打分的所有的item集合,
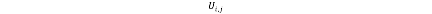
表示item i与item j的共同用户的集合,即集合中的每一个用户都曾经即给item i打过分也给item j打过分。
三. 参考文献
【1】 Thomas George and Srujana Merugu. A scalable collaborative filtering framework based on co-clustering. 2005. URL: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.113.6458&rep=rep1&type=pdf.
【2】 Daniel Lemire and Anna Maclachlan. Slope one predictors for online rating-based collaborative filtering. 2007. URL: http://arxiv.org/abs/cs/0702144.