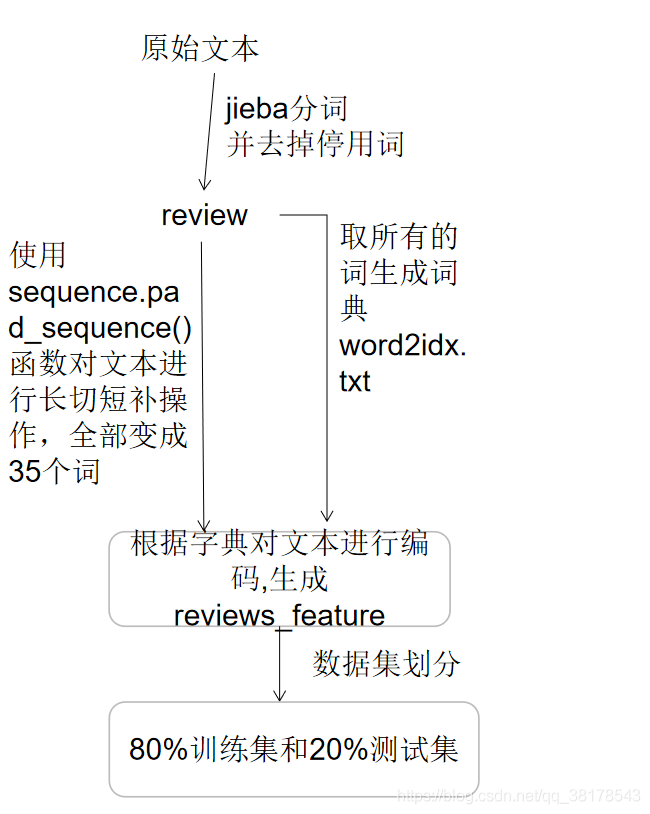
总流程
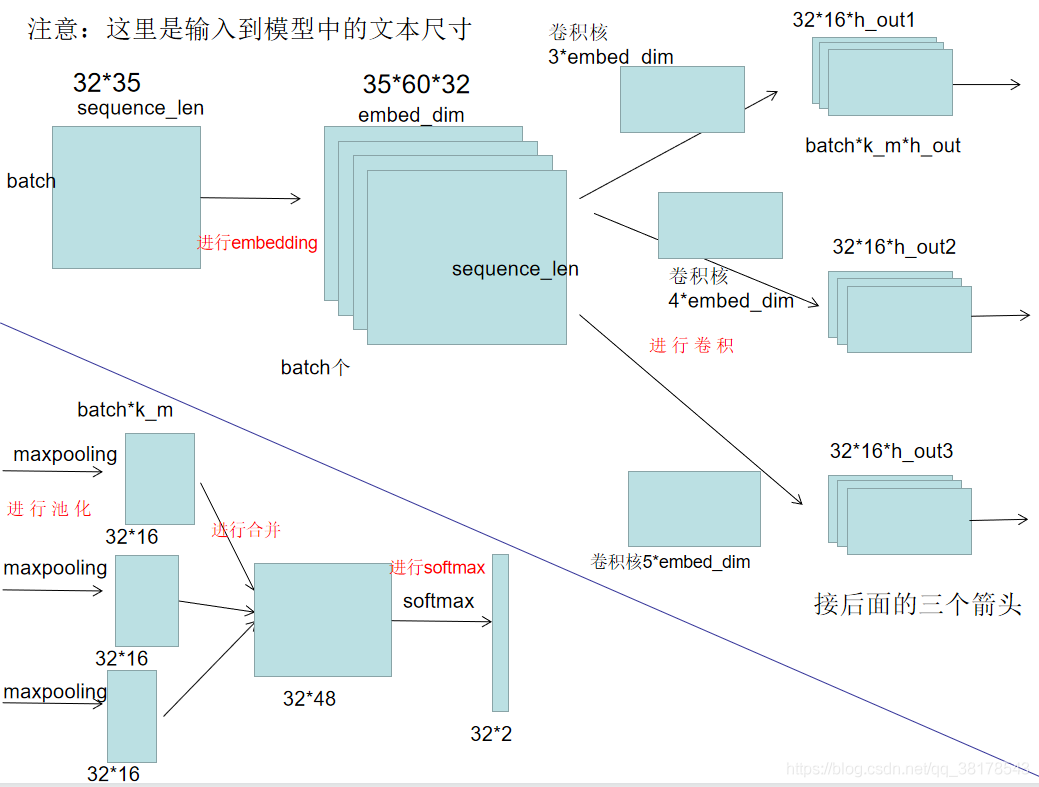
TextCNN
京东评论数据

读取数据
#训练数据预处理
import numpy as np
from sklearn.utils import shuffle
import os
import pandas as pd
import matplotlib.pyplot as plt
import jieba
#语料目录
corpus_neg_dir = 'neg'
corpus_pos_dir = 'pos'
dataset = './data/datasets/'
apple_data_dir = 'corpus/'
def get_file_content(path, type):
''''
path:目录
'''
#所有文件名
fileList = []
#返回一个列表,其中包含在目录条目的名称
files = os.listdir(path)
for f in files:
if(os.path.isfile(path + '/' + f)):
#添加文件
fileList.append(f)
pd_all = pd.DataFrame()
for f1 in fileList:
#打开文件读取数据
pd_one = pd.read_csv(path + "/" + f1, encoding='gb18030').astype(str)
pd_one.type = type
pd_all = pd_all.append(pd_one)
return pd_all
#读取文件的所有正样本和负样本
negative = get_file_content(corpus_neg_dir, 0)
positive = get_file_content(corpus_pos_dir, 1)
#平衡数据集
def get_balance_corpus(corpus_size, corpus_pos, corpus_neg):
sample_size = corpus_size // 2
pd_corpus_balance = pd.concat([corpus_pos.sample(sample_size, replace=corpus_pos.shape[0] < sample_size), \
corpus_neg.sample(sample_size, replace=corpus_neg.shape[0] < sample_size)])
return pd_corpus_balance
ChnSentiCorp_fruit_40000 = get_balance_corpus(20000, positive, negative)
data = ChnSentiCorp_fruit_40000
#打乱数据集
data = shuffle(data, random_state=1)
review = data.content#评论的文本内容
label = data.type#label
#读取停用词表
stopword = []
with open("stopword.txt","r",encoding="utf-8") as f:
for w in f.read().splitlines():
stopword.append(w)
#去除停用词并分词写入文件cut_all_data.txt
with open("cut_all_data.txt", "a", encoding="utf-8") as f:
for line in review:
#jieba分词
text_cut = list(jieba.cut(line))
#文本清洗
filter_word = [w for w in text_cut if w not in stopword]
for fw in filter_word:
f.write(str(fw.strip()))
f.write(str(" "))
f.write("\n")
#将对应的label写入all_label.txt
with open("all_label.txt", "a", encoding="utf-8") as f:
for la in label:
f.write(str(la))
f.write("\n")
# 去除停用词并不进行分词写入文件all_data.txt
with open("all_data.txt", "a", encoding="utf-8") as f:
for line in review:
# jieba分词
text_cut = list(jieba.cut(line))
# 文本清洗
filter_word = [w for w in text_cut if w not in stopword]
for fw in filter_word:
f.write(str(fw.strip()))
f.write("\n")
生成的all_data.txt文件(不进行分词)
生成的cut_all_data.txt文件(进行分词)
生成的all_label.txt文件
生成word2idx
# -*- coding: utf-8 -*-
from collections import Counter
from keras.preprocessing import sequence
import nltk
def get_wordlist(filepath):
#读取数据
review = []
word_all_list = []
with open(filepath + "/" + "cut_all_data.txt", "r", encoding="utf-8") as f:
for line in f.read().splitlines():
word1 = nltk.word_tokenize(line)
for word in line.split(" "):
word_all_list.append(word)
review.append(line)
return review, word_all_list
def get_word2idx(filepath, review, wordlist):
#创建一个字典对文本进行编码
word_counts = Counter(wordlist)#统计词频
word_list = sorted(word_counts, key=word_counts.get, reverse=True)#按词频从大到小排序
#根据词频高低对词进行编号,词频高的编号越小
vocab_to_int = {word: ii for ii, word in enumerate(word_list, 1)} #<class 'dict'>: {'': 1, '买': 2, '好': 3, '吃': 4, '新鲜': 5, '不错': 6, '非常': 7, '好吃': 8, '没有': 9, '小': 10, '包装': 11, '烂': 12, '坏': 13, ……
index = 0
#将词与词的编号写入文件word2idx.txt中——>这是一个词典
for word,ii in vocab_to_int.items():
f = open(filepath, "a", encoding="utf-8")
d = word + ' ' + str(index) + ' ' + str(ii) + '\n'
index += 1
f.write(d)
#根据字典vocab_to_int对文本进行编码
encoded_reviews = []
for re in review:
encoded_reviews.append([vocab_to_int[word] for word in re.split()])
def get_worddict(file):
#从文件中获取词典
datas = open(file, 'r', encoding='utf_8').read().split('\n')
datas = list(filter(None, datas))
word2ind = {}
for line in datas:
line = line.split(' ')
word2ind[line[0]] = int(line[1])
ind2word = {word2ind[w]: w for w in word2ind}
return word2ind, ind2word
def encoded_text(review, vocab_to_int):
# 根据字典vocab_to_int对文本进行编码
encoded_reviews = []
for re in review:
encoded_reviews.append([vocab_to_int[word] for word in re.split()])
review_lens = Counter([len(x) for x in encoded_reviews])#查看文本长度
# 将句子长度统一为35 长切 短补0
seq_len = 35
encoded_reviews = sequence.pad_sequences(encoded_reviews, seq_len)
return encoded_reviews
if __name__ == "__main__":
#生成word2idx.txt词典
review, word_all_list = get_wordlist("corpus")
get_word2idx("word2idx.txt", review, word_all_list)
textCNN模型
#读取清洗过并且分好词的数据
#生成词表
#根据词表将文本转换为数字向量
#模型搭建 embedding 卷积层 dropout层 全连接层
#训练
import os
import torch
import torch.nn as nn
from sklearn import metrics
from torch.nn import functional as F
import math
import time
import numpy as np
from torch.utils.data import TensorDataset, DataLoader
from get_word_list import get_worddict, encoded_text
import utils
class textCNN(nn.Module):
def __init__(self, param):
super(textCNN, self).__init__()
ci = 1 # 通道数
kernel_num = param['kernel_num']
kernel_size = param['kernel_size'] #卷积核的尺寸
vocab_size = param['vocab_size'] #所有词的数目
embed_dim = param['embed_dim']
dropout = param['dropout']
class_num = param['class_num']
self.param = param
#Embedding层
self.embed = nn.Embedding(vocab_size, embed_dim, padding_idx=1)
#三个卷积层
self.conv11 = nn.Conv2d(ci, kernel_num, (kernel_size[0], embed_dim))
self.conv12 = nn.Conv2d(ci, kernel_num, (kernel_size[1], embed_dim))
self.conv13 = nn.Conv2d(ci, kernel_num, (kernel_size[2], embed_dim))
#dropout 增强模型的泛化能力
self.dropout = nn.Dropout(dropout)
#全连接层
self.fc1 = nn.Linear(len(kernel_size) * kernel_num, class_num)
def init_embed(self, embed_matrix):
self.embed.weight = nn.Parameter(torch.Tensor(embed_matrix))
@staticmethod
def conv_and_pool(x, conv):
# x: (batch, 1, sentence_length, embed_dim)
x = conv(x)
# x: (batch, kernel_num, H_out, 1)
x = F.relu(x.squeeze(3))
# x: (batch, kernel_num, H_out)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
# (batch, kernel_num)
return x
def forward(self, x):
# x: (batch, sentence_length)
x = self.embed(x)
# x: (batch, sentence_length, embed_dim)
# TODO init embed matrix with pre-trained
x = x.unsqueeze(1)
#卷积层
# x: (batch, 1, sentence_length, embed_dim)
x1 = self.conv_and_pool(x, self.conv11) # (batch, kernel_num)
x2 = self.conv_and_pool(x, self.conv12) # (batch, kernel_num)
x3 = self.conv_and_pool(x, self.conv13) # (batch, kernel_num)
x = torch.cat((x1, x2, x3), 1) # (batch, 3 * kernel_num)
x = self.dropout(x)
#softmax分类器
logit = F.log_softmax(self.fc1(x), dim=1)
return logit
def init_weight(self):
#初始化权重参数
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def train_TextCNN(net):
EPOCH = 15
net.train()
print("training……")
for epoch in range(EPOCH):
count = 0
for content, labels in test_loader:
count += 1
optimizer.zero_grad()
sentences = content.type(torch.LongTensor)
labels = labels.type(torch.LongTensor)
out = net(sentences)
loss = criterion(out, labels)
loss.backward()
optimizer.step()
if (count + 1) % 10 == 0:
labels = labels.data.cpu().numpy()
pred = torch.max(out.data, 1)[1].cpu().numpy()
# compare predictions to true label
train_acc = metrics.accuracy_score(labels, pred)
print("epoch:", epoch + 1, "step:", count + 1, "train_loss:", loss.item(), "train_acc:", train_acc)
print("保存模型...")
torch.save(net.state_dict(), weightFile)
def test_TextCNN(net):
net.eval()#测试模式
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
start_time = time.time()
with torch.no_grad():
for content, labels in test_loader:
sentences = content.type(torch.LongTensor).cuda()
labels = labels.type(torch.LongTensor).cuda()
out = net(sentences)
loss = criterion(out, labels)
loss_total = loss_total + loss
labels = labels.data.cpu().numpy()
predict = torch.max(out.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predict)
test_loss = loss_total / len(test_loader)
test_acc = metrics.accuracy_score(labels_all, predict_all)
test_report = metrics.classification_report(labels_all, predict_all, target_names=["positive", "negative"], digits=4)
test_confusion = metrics.confusion_matrix(labels_all, predict_all)
msg = 'Test Loss:{}, Test Acc:{}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score")
print(test_report)
print("Confusion Maxtrix")
print(test_confusion)
time_dif = utils.get_time_dif(start_time)
print("使用时间:", time_dif)
if __name__ == '__main__':
#获取label
label = []
with open("corpus/all_label.txt", "r", encoding="utf-8") as f:
for line in f.read().splitlines():
label.append(int(line))
label = np.array(label)
# 获取文本
review = []
word_all_list = []
with open("corpus/cut_all_data.txt", "r", encoding="utf-8") as f:
for line in f.read().splitlines():
for word in line.split(" "):
word_all_list.append(word)
review.append(line)
#获得词表字典
vocab_to_int, _ = get_worddict("word2idx.txt")
# 对文本进行编码和统一长度
reviews_feature = encoded_text(review, vocab_to_int)
# 数据集的划分
split_radio = 0.8
split_idx = int(len(reviews_feature) * split_radio)
train_x, test_x = reviews_feature[:split_idx], reviews_feature[split_idx:]
train_y, test_y = label[:split_idx], label[split_idx:]
# DataLoaders and Batching
# 创建Tensor datasets
train_data = TensorDataset(torch.from_numpy(train_x), torch.from_numpy(train_y))
test_data = TensorDataset(torch.from_numpy(test_x), torch.from_numpy(test_y))
# dataloaders
batch_size = 32
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size)
textCNN_param = {
'vocab_size': len(vocab_to_int),
'embed_dim': 60,
'class_num': 2,
"kernel_num": 16,
"kernel_size": [3, 4, 5],
"dropout": 0.2,
'EPOCH': 15,
}
print("初始化textcnn……")
net = textCNN(textCNN_param)
weightFile = 'saved-dict/weight.pkl'
if os.path.exists(weightFile):
print('加载 weight')
net.load_state_dict(torch.load(weightFile))
else:
net.init_weight()
print(net)
#定义损失函数和优化器
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
criterion = nn.NLLLoss()
#训练集与测试集
train_TextCNN(net)
test_TextCNN(net)
这个是半年前做的 今天有人问我 我放上来了 其实这个代码写的很low( 因为我当时刚入门 还啥也不懂) 其实有很多地方可以美化 如果不嫌弃 自己拿去看看吧
链接:https://pan.baidu.com/s/1CMF2EiTvc3iVPFr_ZnBfdA
提取码:vpnc
版权声明:本文为qq_38178543原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。