关键字 on 数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。 在使用 left jion 时,on 和 where 条件的区别如下:
1、 on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
2、where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
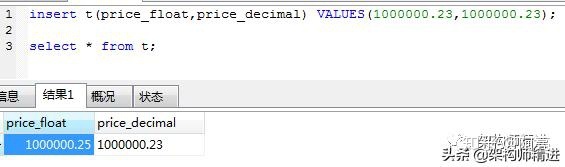
假设有两张表: 表1:tab2 idsize110220330 表2:tab2 sizename10AAA20BBB20CCC 两条 SQL: select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name='AAA' select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name='AAA') 第一条SQL的过程: 1、中间表 on条件: tab1.size = tab2.sizetab1.idtab1.sizetab2.sizetab2.name11010AAA22020BBB22020CCC330(null)(null) 2、再对中间表过滤 where 条件: tab2.name='AAA'tab1.idtab1.sizetab2.sizetab2.name11010AAA 第二条SQL的过程: 1、中间表 on条件: tab1.size = tab2.size and tab2.name='AAA' (条件不为真也会返回左表中的记录)tab1.idtab1.sizetab2.sizetab2.name11010AAA220(null)(null)330(null)(null) 其实以上结果的关键原因就是 left join、right join、full join 的特殊性,不管 on 上的条件是否为真都会返回 left 或 right 表中的记录,full 则具有 left 和 right 的特性的并集。 而 inner jion没这个特殊性,则条件放在 on 中和 where 中,返回的结果集是相同的。 19、优化 MYSQL 数据库的方法 (1) 选取最适用的字段属性,尽可能减少定义字段长度,尽量把字段设置 NOT NULL, 例如’省份,性别’, 最好设置为 ENUM (2) 使用连接(JOIN)来代替子查询: (3) 使用联合 (UNION) 来代替手动创建的临时表 (4) 事务处理: (5) 锁定表,优化事务处理: (6) 使用外键,优化锁定表 (7) 建立索引 (8) 优化 sql 语句 20、适用MySQL 5.0以上版本: 1.一个汉字占多少长度与编码有关: UTF-8:一个汉字=3个字节 GBK:一个汉字=2个字节 21、什么时候适合创建索引 1、适合创建索引条件 1.、主键自动建立唯一索引 2、频繁作为查询条件的字段应该建立索引 3、查询中与其他表关联的字段,外键关系建立索引 4、单键/组合索引的选择问题,组合索引性价比更高 5、查询中排序的字段,排序字段若通过索引去访问将大大提高排序效率 6、查询中统计或者分组字段 2、不适合创建索引条件 1、表记录少的 2、经常增删改的表或者字段 3、where条件里用不到的字段不创建索引 4、过滤性不好的不适合建索引 22、常见的sql语句 1、表名order中有 1 2 3 4 1 去掉重复值 sql : select distinct from order 结果为company 1 2 3 4 2、asc 是升序 是从小到大 desc 是大到小 group 是分组 3、IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为 NULL 则返回第一个参数的值。 6、查找学生 查询姓“赵”的用户 select * from table where name like '赵%' 查询姓名中最后一个字段带赵字 select * from table where name like '%赵' 查询姓名中带有赵的字段 select * from table where name like '%赵%' 7、汇总分析 查询一个学生总分 select sum(*) from table where 课程号='0002' 查询选课程的学生人数 select count(distinct 学号) as 学生人数 from table 8、分组 查询各科成绩最高和最低的分 select 课程号 max(成绩)as 最高分,min(成绩)as 最低分 from table group by 课程号 查询每门课程被选修的学生数 select 课程号,count(学号) from score group by 课程号 查询男生 和女生人数 select 性别,count(*) from tabel group by 性别 9、分组结果的条件 查询平均成绩大于60分的学号和平均成绩 select 学号,avg(成绩)from group by 学号 having avg(成绩) > 60 查询至少选修俩门课程的学生学号 select 学号,count(课程号)as 选修课程数目 from table group by 学号 having count(课程号)>=2; 查询同名同性学生名单并统计人数 select 姓名,count()as 人数from table group by 姓名 having count(*)>=2; 查询不及格的课程并按课程号从大到小排序 select 课程号 from table where 成绩<60 order by 课程号 desc; 10、类似于成绩这一类型表类型为float 23、php读取文件内容的几种方法和函数? 打开文件,然后读取。Fopen() fread() 打开读取一次完成 file_get_contents()