高可用 Kubernetes 集群搭建教程
集群架构
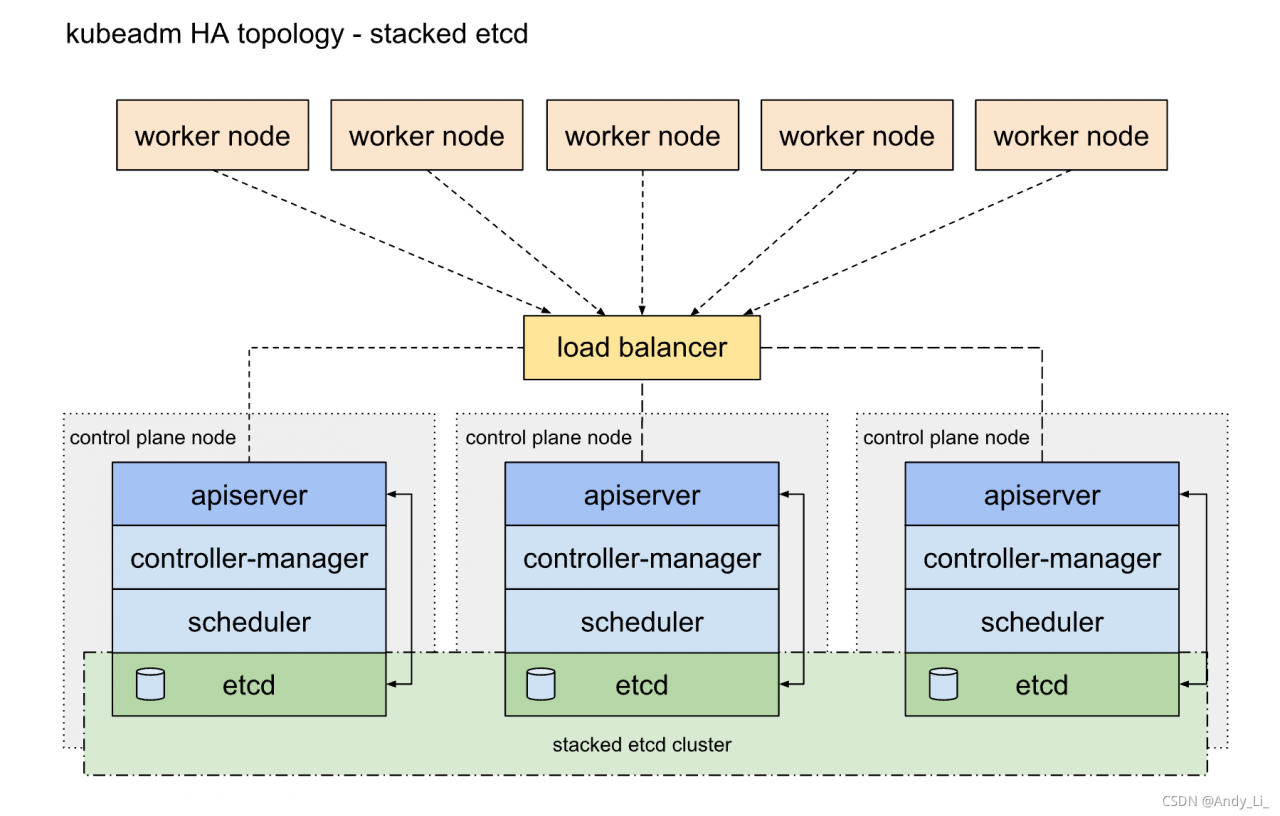
堆叠(Stacked)
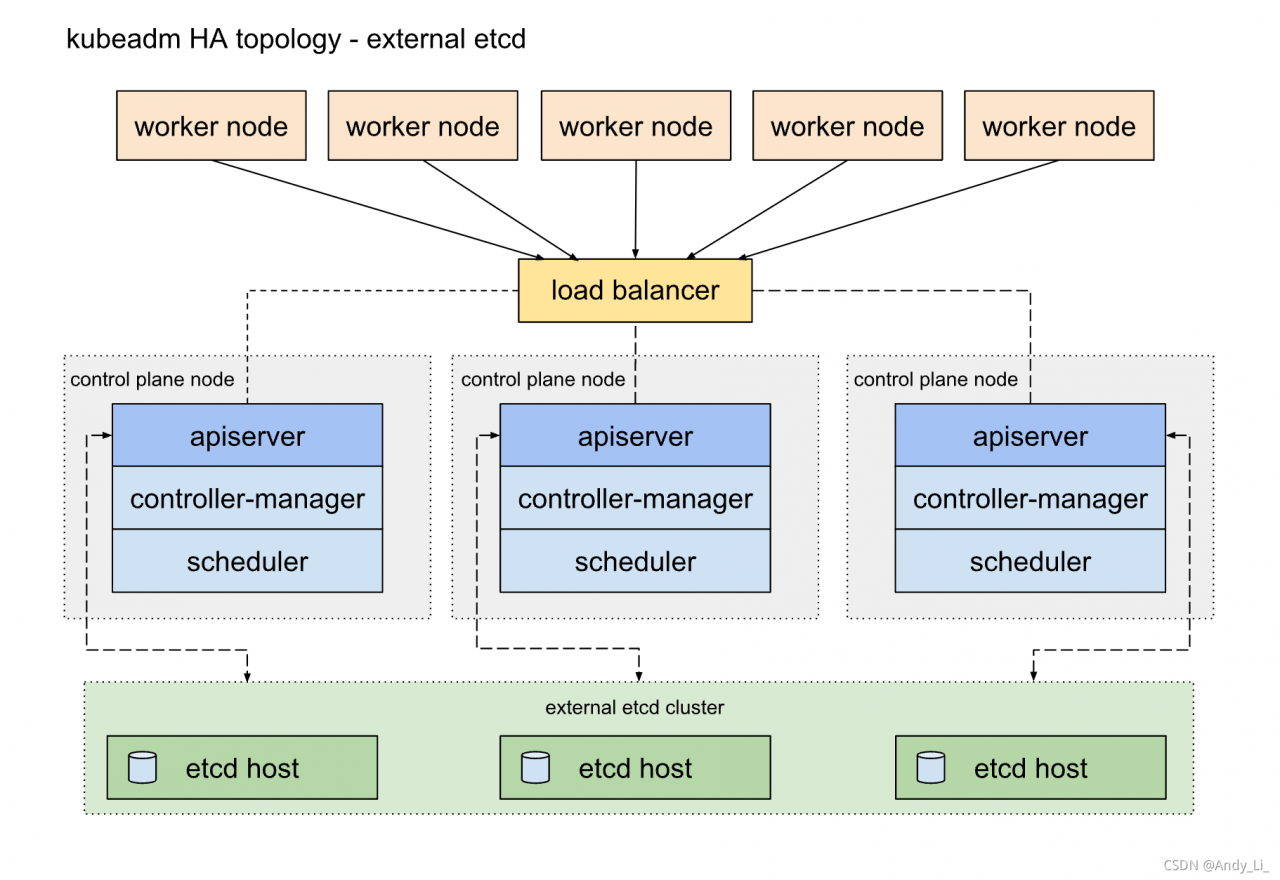
etcd拓扑外部
etcd拓扑
优缺点
- 堆叠(Stacked)
etcd拓扑- 更加节省服务器资源,但节点故障同时影响
ctcd和控制面节点
- 更加节省服务器资源,但节点故障同时影响
- 外部
etcd拓扑需要更多服务器资源,- 需要更多服务器资源,但节点故障时对集群影响更小,可用性更高
- 堆叠(Stacked)
当前选择
- 堆叠(Stacked)
etcd拓扑
- 堆叠(Stacked)
安装步骤
服务器准备
服务器列表
主机名 IP CPU 内存(G) 备注 k8s-master-01 172.18.212.94 4 8 控制面节点1(keepalived-master+haproxy) k8s-master-02 172.18.212.95 4 8 控制面节点2(keepalived-backup+haproxy) k8s-master-03 172.18.212.96 4 8 控制面节点3 k8s-worker-01 172.18.212.97 4 8 工作节点1 k8s-worker-02 172.18.212.98 4 8 工作节点2 k8s-worker-03 172.18.212.99 4 8 工作节点3 - 如果条件允许,最好把
keepalived和haproxy部署在独立的两台机器。
- 如果条件允许,最好把
设置主机名和 hosts
设置主机名。例如:
hostnamectl set-hostname k8s-master-01
设置 hosts,例如
cat <<EOF >> /etc/hosts 172.18.212.94 k8s-master-01 172.18.212.95 k8s-master-02 172.18.212.96 k8s-master-03 172.18.212.97 k8s-worker-01 172.18.212.98 k8s-worker-02 172.18.212.99 k8s-worker-03 EOF
校验 mac 地址和 uuid 的唯一性
- 你可以使用命令
ip link或ifconfig -a来获取网络接口的 MAC 地址 - 可以使用
sudo cat /sys/class/dmi/id/product_uuid命令对 product_uuid 校验 - 一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。 Kubernetes 使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装 失败
设置防火墙为 iptables 并设置空规则
systemctl stop firewalld && systemctl disable firewalldyum -y install iptables-services && systemctl start iptables && systemctl enable iptables && iptables -F && service iptables save
关闭 SELinux 和 交换分区
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
模块加载
modprobe br_netfilter lsmod | grep br_netfiltercat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF
调整内核参数
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl --system
安装容器运行时
安装 Docker
删除旧版本
sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-engine
安装 yum-utils
sudo yum install -y yum-utils
配置 yum 源
sudo yum-config-manager \ --add-repo \ http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
开始安装
sudo yum install -y docker-ce docker-ce-cli containerd.io
配置 Docker
mkdir /etc/docker cat <<EOF | sudo tee /etc/docker/daemon.json { "registry-mirrors": ["https://fnzkmit7.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2" } EOF- 其中
https://fnzkmit7.mirror.aliyuncs.com是镜像加速器地址。可以在阿里云免费申请。
systemctl daemon-reload && systemctl restart docker && systemctl enable docker- 其中
升级 Linux 内核(可选)
查看当前系统内核版本
uname -a
如果内核版本低于 4.4 ,需要升级,否则 Docker 和 Kubernetes 运行时会存在一些问题
导入ELRepo仓库的公共密钥
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
安装ELRepo仓库的yum源
yum install https://www.elrepo.org/elrepo-release-8.el8.elrepo.noarch.rpm
查看可用的系统内核安装包
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
安装最新版内核
yum --enablerepo=elrepo-kernel install kernel-lt -y
查看已经安装的内核
grubby --info=ALL
设置以新的内核启动
grub2-set-default 00 表示最新安装的内核,设置为 0 表示以新版本内核启动
生成grub配置文件并重启系统
grub2-mkconfig -o /boot/grub2/grub.cfgreboot
再次查看内核信息
uname -a此时应该看到内核版本升级到了 5.x
安装 Kubeadm
配置 Kubenertes 源
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF- 使用阿里云源在国内下载速度更快
安装 Kubeadm、Kubelet、Kubectl
yum -y install kubeadm-1.22.2 kubectl-1.22.2 kubelet-1.22.2设置 kubelet 开机启动
systemctl enable kubelet.service
安装负载均衡器
选择负载均衡器
- 软件负载平衡选项指南
keepalived+haproxy- 传统负载均衡解决方案,技术相对成熟,久经考验
kube-vipKubernetes官方提供的解决方案
- 选择方案
keepalived+haproxy
安装负载均衡器
安装 KeepAlived
安装方式选择 Docker 安装
在
master服务器(172.18.212.94)启动容器:docker run --name keepalived-1.2.2 -d --net=host --cap-add NET_ADMIN \ -e KEEPALIVED_AUTOCONF=true \ -e KEEPALIVED_STATE=MASTER \ -e KEEPALIVED_INTERFACE=eth0 \ -e KEEPALIVED_VIRTUAL_ROUTER_ID=2 \ -e KEEPALIVED_UNICAST_SRC_IP=172.18.212.94 \ -e KEEPALIVED_UNICAST_PEER_0=172.18.212.95 \ -e KEEPALIVED_TRACK_INTERFACE_1=eth0 \ -e KEEPALIVED_VIRTUAL_IPADDRESS_1="172.18.212.120/24 dev eth0" \ arcts/keepalived:1.2.2
在
backup服务器(172.18.212.95)启动容器docker run --name keepalived-1.2.2 -d --net=host --cap-add NET_ADMIN \ -e KEEPALIVED_AUTOCONF=true \ -e KEEPALIVED_STATE=BACKUP \ -e KEEPALIVED_INTERFACE=eth0 \ -e KEEPALIVED_VIRTUAL_ROUTER_ID=2 \ -e KEEPALIVED_UNICAST_SRC_IP=172.18.212.95 \ -e KEEPALIVED_UNICAST_PEER_0=172.18.212.94 \ -e KEEPALIVED_TRACK_INTERFACE_1=eth0 \ -e KEEPALIVED_VIRTUAL_IPADDRESS_1="172.18.212.120/24 dev eth0" \ arcts/keepalived:1.2.2
安装 HaProxy
创建配置文件
cat <<EOF > haproxy.cfg # /etc/haproxy/haproxy.cfg #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global log /dev/log local0 log /dev/log local1 notice daemon #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 1 timeout http-request 10s timeout queue 20s timeout connect 5s timeout client 20s timeout server 20s timeout http-keep-alive 10s timeout check 10s #--------------------------------------------------------------------- # apiserver frontend which proxys to the control plane nodes #--------------------------------------------------------------------- frontend apiserver bind 0.0.0.0:6000 mode tcp option tcplog default_backend apiserver #--------------------------------------------------------------------- # round robin balancing for apiserver #--------------------------------------------------------------------- backend apiserver option httpchk GET /healthz http-check expect status 200 mode tcp option ssl-hello-chk balance roundrobin server kube-master-01 172.18.212.94:6443 check server kube-master-02 172.18.212.95:6443 check server kube-master-03 172.18.212.96:6443 check # [...] EOF
创建 Dockerfile
cat <<EOF > Dockerfile FROM haproxy:2.4.4 COPY haproxy.cfg /usr/local/etc/haproxy/haproxy.cfg EOF
创建镜像
docker build -t my-haproxy:2.4.4 .
启动 HaProxy
docker run -d -p 6000:6000 --name my-haproxy --sysctl net.ipv4.ip_unprivileged_port_start=0 my-haproxy:2.4.4
初始化控制面节点
下载初始化所需镜像
由于直接安装,速度非常慢,强烈建议下载镜像后导入。
查看所需镜像列表
[root@k8s-master-01]# kubeadm config images list k8s.gcr.io/kube-apiserver:v1.22.2 k8s.gcr.io/kube-controller-manager:v1.22.2 k8s.gcr.io/kube-scheduler:v1.22.2 k8s.gcr.io/kube-proxy:v1.22.2 k8s.gcr.io/pause:3.5 k8s.gcr.io/etcd:3.5.0-0 k8s.gcr.io/coredns/coredns:v1.8.4
通过可以科学上网的电脑下载镜像
重复执行以下命令获取镜像
docker pull k8s.gcr.io/<image name> docker save k8s.gcr.io/<image name> > <image name>.tar- 把
<image name>替换成具体的镜像名称
- 把
v1.22.2版本镜像百度网盘下载地址:将镜像文件上传到所有节点,并导入到 Docker(非常关键)
docker load < <image name>.tar把
<image name>替换成具体的镜像名称docker load < coredns.tar docker load < etcd.tar docker load < kube-apiserver.tar docker load < kube-controller-manager.tar docker load < kube-proxy.tar docker load < kube-scheduler.tar docker load < pause.tar
获取默认初始化配置模板
通过 kubeadm 命令生成默认初始化模板
kubeadm config print init-defaults > kubeadm-config.yaml
修改模板内容
apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: k8s.gcr.io kind: ClusterConfiguration kubernetesVersion: 1.22.2 controlPlaneEndpoint: "172.18.212.120:6000" networking: podSubnet: "10.244.0.0/16" dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 scheduler: {}- 首先,删除其他内容,仅保留集群配置部分(即
kind: ClusterConfiguration) - 确认版本号:
kubernetesVersion: 1.22.2 - 在
networking下新增podSubnet配置项。这里预先网络组件(flannel)相关配置 。flannel在后续步骤安装。 - 新增
controlPlaneEndpoint配置,内容为负载均衡器虚拟IP和端口,即Keepalived维护的虚拟IP和端口- 注意:要确保虚拟IP可用。例如上面的安装负载均衡器 通过
keepalived实现了虚拟IP172.18.212.120,绑定了两条haproxy负载均衡器, - 其中
172.18.212.94为主负载均衡器,其中172.18.212.95为备用负载均衡器 - 如果由于条件限制,虚拟IP不可用,可用把
controlPlaneEndpoint配置修改为其中一个负载均衡器,例如修改为:172.18.212.94:6000。只是这样一来,负载均衡器就会有单点问题,高可用集群存在一些瑕疵。
- 注意:要确保虚拟IP可用。例如上面的安装负载均衡器 通过
- 首先,删除其他内容,仅保留集群配置部分(即
开始初始化控制面节点
执行初始化命令
kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log指定配置文件进行初始化
设置自动颁发证书(高可用模式下需要)
输出日志到
kubeadm-init.log
执行完成之后,可以在 kubeadm-init.log 看到类似内容
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 172.18.212.120:6000 --token fpfbvy.zbnlawsk29yucqa9 \ --discovery-token-ca-cert-hash sha256:6103ba08fad6e508b5717abf2720a068ff1ddca747c578ba2db39f3d4dd02908 \ --control-plane --certificate-key 0112f7a40c5fff61aa4d39c410bc2238e0b4adf6b00025930c5cea98447159f4 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 172.18.212.120:6000 --token fpfbvy.zbnlawsk29yucqa9 \ --discovery-token-ca-cert-hash sha256:6103ba08fad6e508b5717abf2720a068ff1ddca747c578ba2db39f3d4dd02908普通用户执行(建议 root 用户也执行)
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
root 用户执行
export KUBECONFIG=/etc/kubernetes/admin.conf
添加其他控制面节点
以 root 账号登录其他控制面节点,执行以下命令:
kubeadm join 172.18.212.120:6000 --token fpfbvy.zbnlawsk29yucqa9 \ --discovery-token-ca-cert-hash sha256:6103ba08fad6e508b5717abf2720a068ff1ddca747c578ba2db39f3d4dd02908 \ --control-plane --certificate-key 0112f7a40c5fff61aa4d39c410bc2238e0b4adf6b00025930c5cea98447159f4加入成功之后,可以看到如下日志:
This node has joined the cluster and a new control plane instance was created: * Certificate signing request was sent to apiserver and approval was received. * The Kubelet was informed of the new secure connection details. * Control plane (master) label and taint were applied to the new node. * The Kubernetes control plane instances scaled up. * A new etcd member was added to the local/stacked etcd cluster. To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster.同样执行命令:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
初始化工作节点
- 以 root 账号登录其他控制面节点,执行以下命令
kubeadm join 172.18.212.120:6000 --token fpfbvy.zbnlawsk29yucqa9 \ --discovery-token-ca-cert-hash sha256:6103ba08fad6e508b5717abf2720a068ff1ddca747c578ba2db39f3d4dd02908
安装网络插件
安装网络插件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml kubectl create -f kube-flannel.yml网络插件的安装需要一点时间
查看集群状况
查看节点信息、Pod 信息
kubectl get node kubectl get pod --all-namespaces -o wide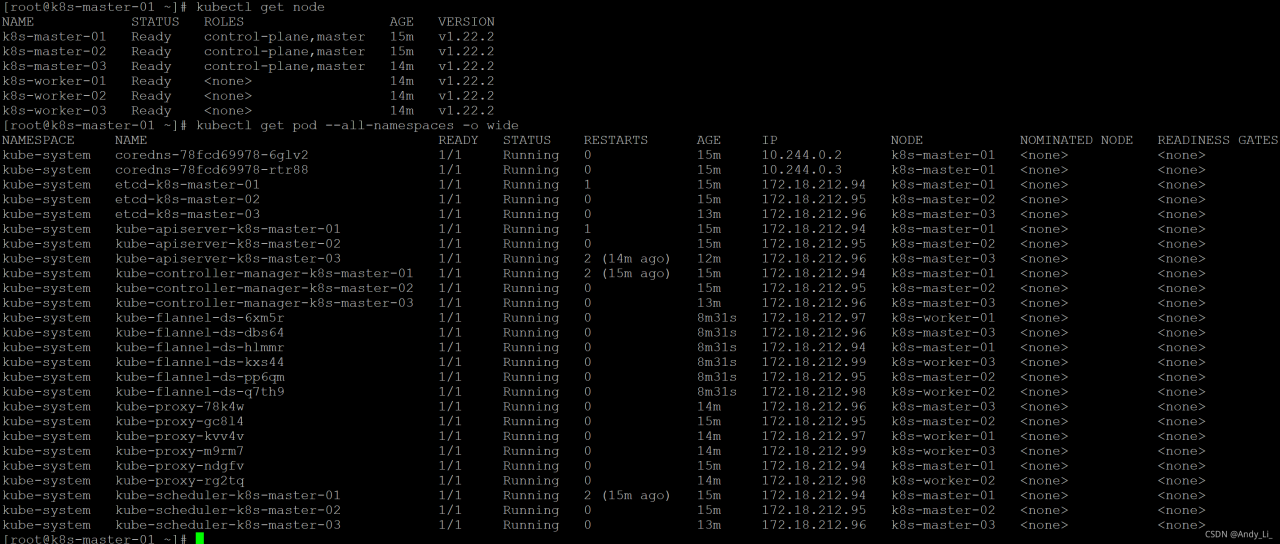
部署测试
测试方式:多副本
Nginx部署创建资源清单文件
cat <<EOF > nginx-deployment.yml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx EOF
部署
3个Nginxkubectl create -f nginx-deployment.yml
查看
Pod信息kubectl get pod -o wide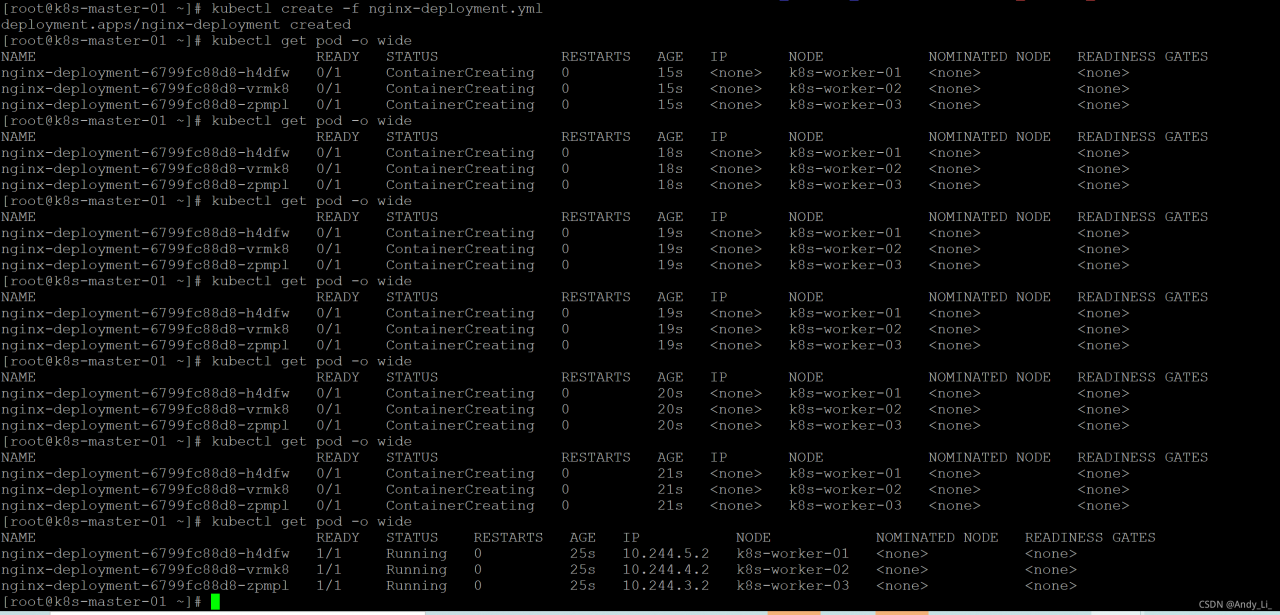
可以看到
3个 nginx 实例分别运行在3个工作节点上