Spring Cloud 微服务化
前言
- 结合自己对微服务的理解和近段时间的工作经历,博主写了这篇博客。
- 由于博主水平有限,博客中难免有错误的地方,希望各位同学不吝赐教。
概述
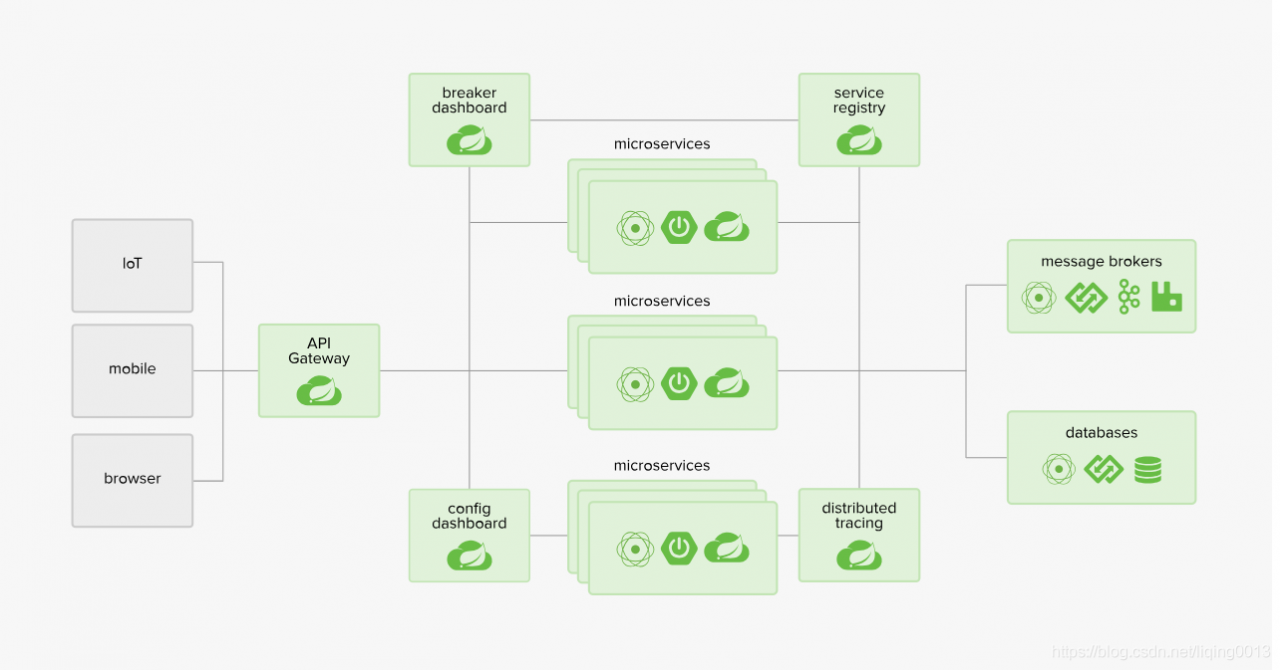
- Spring Cloud 让为服务化变的更加简单,为微服务化的提供了一站式的解决方案。官网上有一张图,描述了一个最通用的分布式系统的模型:
- 结合这个模型,博主构建了这样一个系统:
- API Gateway(网关) : Spring Could Gateway 。
- Breaker dashboard(断路器) : Spring Could Netflix Hystrix 。
- Config dashboard(配置中心):Spring Could Consul Config。这和博主选择使用 Consul 来完成服务注册与发现有关。另外,Spring Cloud Config 也是一个可选方案。
- Service Registry(服务注册中心):Spring Cloud Consul。由于某些原因,博主没有选择 Eureka。
- Distributed tracing(分布式追踪):Spring Cloud Sleuth
- Message broker(消息中间件):消息服务通过 Spring Cloud Stream 实现,消息中间件选择 Kafka(RabbitMQ 也是一个可选方案)
- Database(数据库):Mysql。
- Microservice(微服务项目):提供具体服务的项目,它有以下内涵:
- 它是基于Spring Boot 创建的 Web 项目 。
- 使用 Redis 作为缓存
- 使用 Elasticsearch 作为搜索引擎
- 使用 Mybatis 框架实现数据库访问功能
- 完整系统源码地址:
架构设计说明
- 系统分为三层:
- 整体架构图:
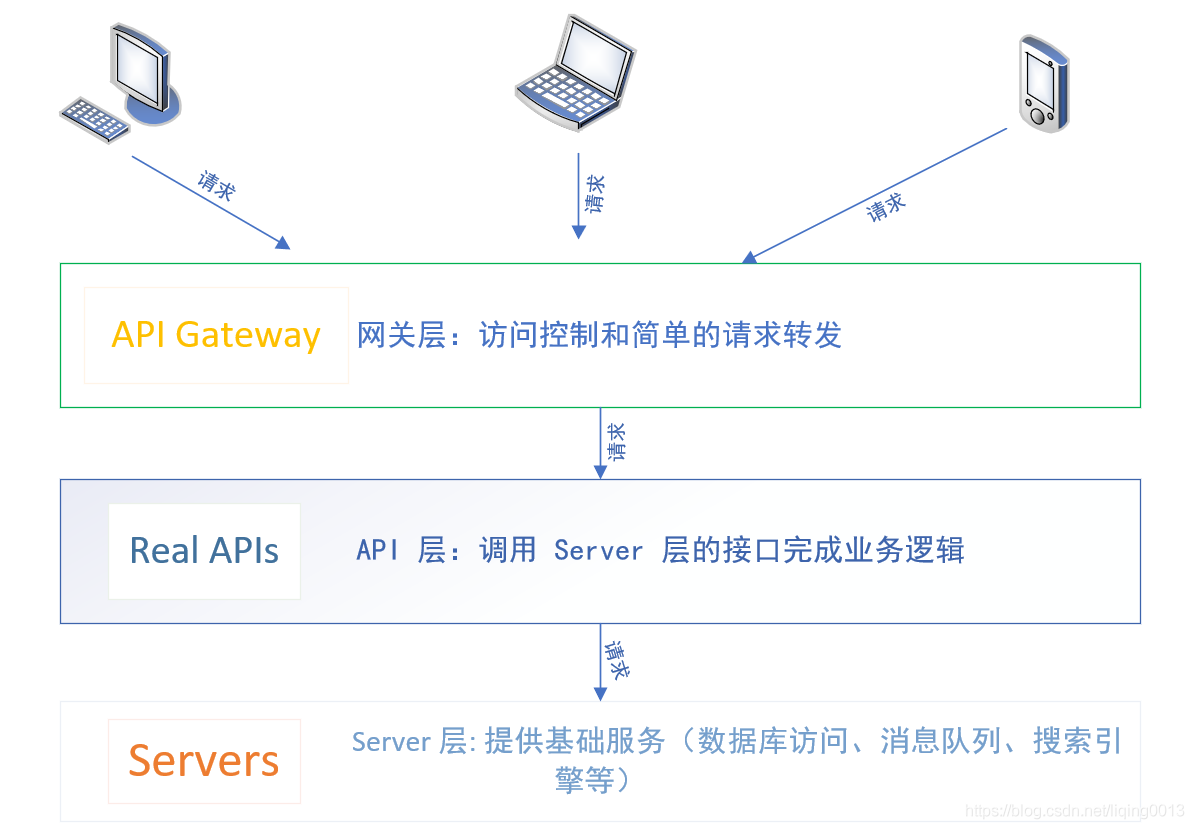
系统设计说明
- 这里主要是设计一个微服务架构的模型(“玩具”)系统,不实现特别复杂的功能,但求“五脏俱全”。
- 现在,设计一个购物系统,实现它的用户模板、商品模块和消息服务模块。
- 用户模块:主要实现用户登陆
- 商品模块:主要实现商品搜索
- 消息服务模块:主要发送登陆提醒消息
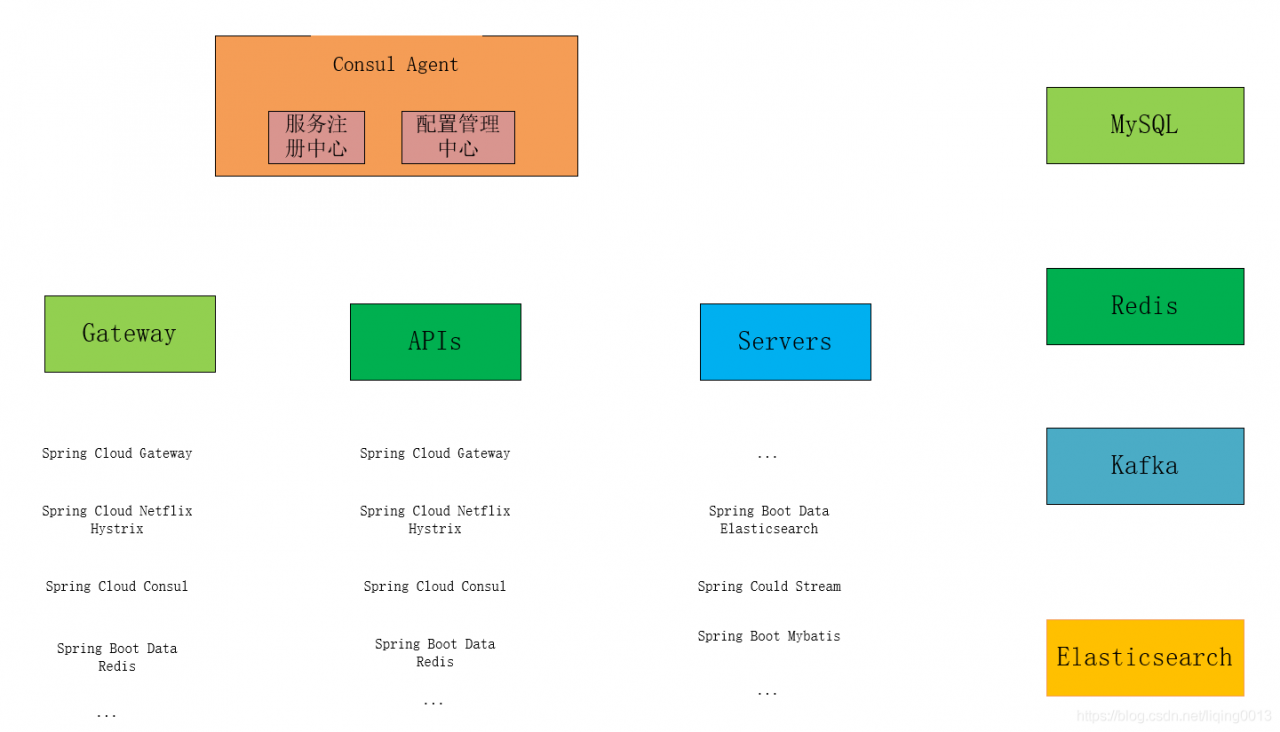
- 根据上面的架构图,把购物系统整体上分为 三层。
- 购物系统包含:
- 一个网关(博主把它命名为:awesome-gateway)—— 网关层
- 两个 API 服务(博主分别把它们命名为:awesome-user-api 、awesome-product-api )—— API 层
- 四个 Server(博主分别把它们命名为:awesome-user-server 、awesome-product-server、awesome-elasticsearch-server 、awesome-message-consumer-server、awesome-message-producer-server)—— Server 层
构建步骤
参考概述中的分布式系统的模型图,开始构建一个分布式系统。下面按照模型图的指示,逐步构建构建各个部分。
Service Registry(服务注册中心)
- 服务注册中心是分布式系统最基础的设施。所以,它必须第一个构建。
- 如何基于 Spring Cloud Consul 搭建的服务注册中心,博主写在另外的博客:
API Gateway(网关)
- 网关的作用是:接受用户请求,并对他们进行过滤和路由。如果拿概述中模型图来对比说明,网关包含以下内容:
- API Gateway
- 其他基础设施:Breaker dashboard、Config dashboard、Service Registry、Distributed tracing 等等。
- 如何构建基于 Spring Cloud Gateway 的网关项目,博主写在另外的博客:
Config Dashboard(配置中心)
- 博主把系统分成了三层。但不管是那一层,配置中心都是必须的。所以,博主把它的优先级排的很高。
- 如何构建基于 Spring Cloud Consul 的配置中心项目,博主写在另外的博客:
Microservices(微服务项目)
- 博主把这部分分成两层
- API 层
- 它的作用是接收网关层转发的请求,并调用相关 Server 层的接口完成业务逻辑。
- 和网关层相比,它多了个功能:
- 远程调用 Server 层的接口,并完成相关业务逻辑
- 所以,API 层项目,只是网关层项目的基础上,添加远程调用功能。如何实现远程服务调用,博主选择的是 Spring Cloud Feign。如何构建 基于 Spring Cloud Feign 的远程服务调用,博主写在另外的博客:
- Server 层
- 它的作用是实现比较基础的具体的业务。
- 根据使用的技术,博主简单把它分为三种类型:
- 包含数据库访问的 server:
- 所以的系统都离不开数据库。博主这里选择通过 Mybatis 实现数据库访问。
- 如何构建 基于 Mybatis 实现数据库访问 的 基础服务项目,博主写在另外的博客:
- 包含消息中间件的 server:
- 引入消息中间件,有利于应用间的解耦,某些场景非常有用。
- 博主选择 kafka,并引入 Spring Cloud Stream 实现。这部分内容博主写在另外的博客:
- 包含搜索引擎的 server:
- 搜索引擎在项目中是必不可少的,特别是数据量特别大的时候。这部分内容,博主写在另外的博客:
- 包含数据库访问的 server:
- API 层
Distributed tracing(分布式追踪)
- 进行微服务化之后,项目的总数会非常多。为了方便问题的排查,日志追踪是很必要的。
- 如何构建基于 Spring Cloud Sleuth 的分布式追踪项目,博主写在另外的博客:
部署说明
- 最好引入 DevOps 实现自动化部署。
- 这部分内容博主也还在学习中。
- 传统手动部署:
- 启动 Consul Agent
- 启动 Zipkin
- 启动 Kafka
- 启动 Elasticsearch 服务器
- 任意顺序启动所有的项目
- 部署完毕
测试
- 启动 consul agent
- 启动 Zipkin
- 启动 Kafka
- 启动内置的 zookeeper:
- 启动 Kafka
- 启动内置的 zookeeper:
- 启动 Elasticsearch
- 依次启动各个项目:
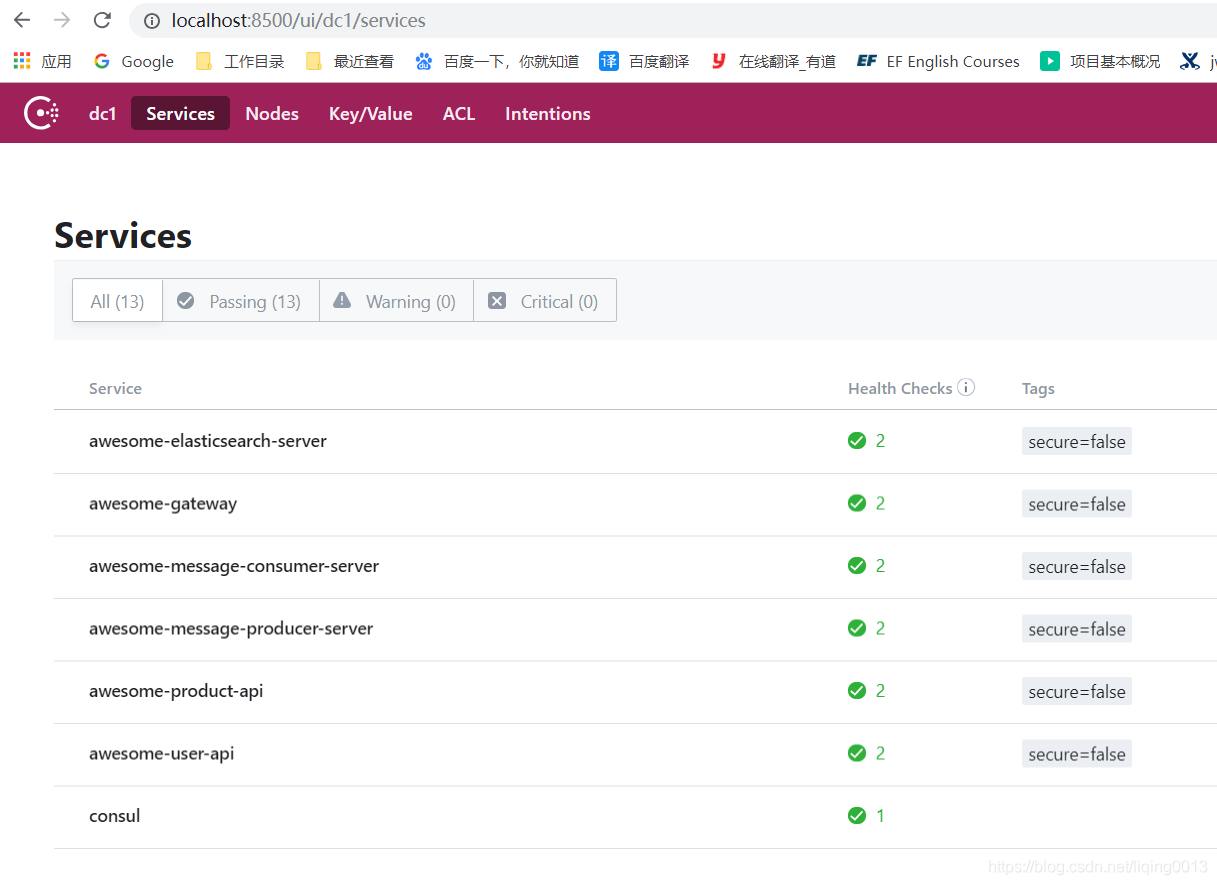
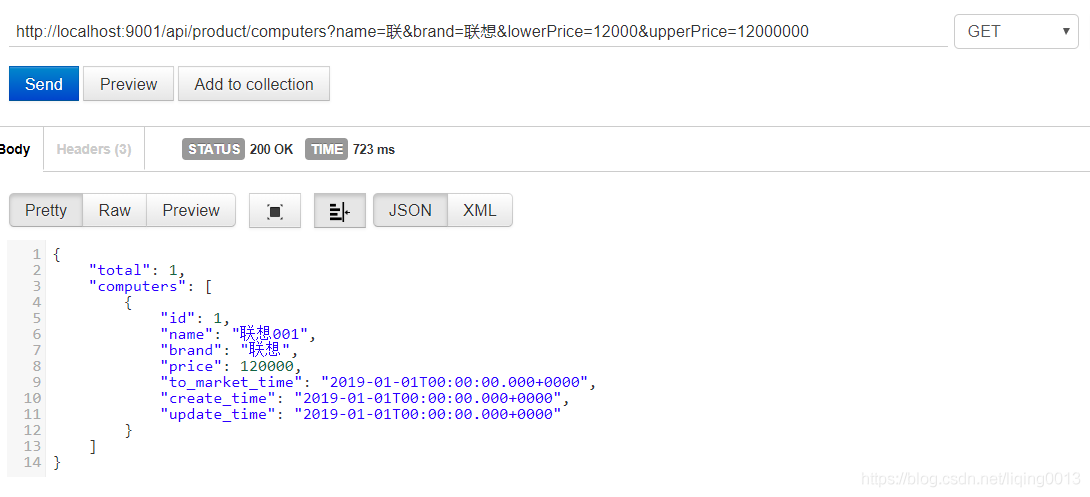
- 接口访问:
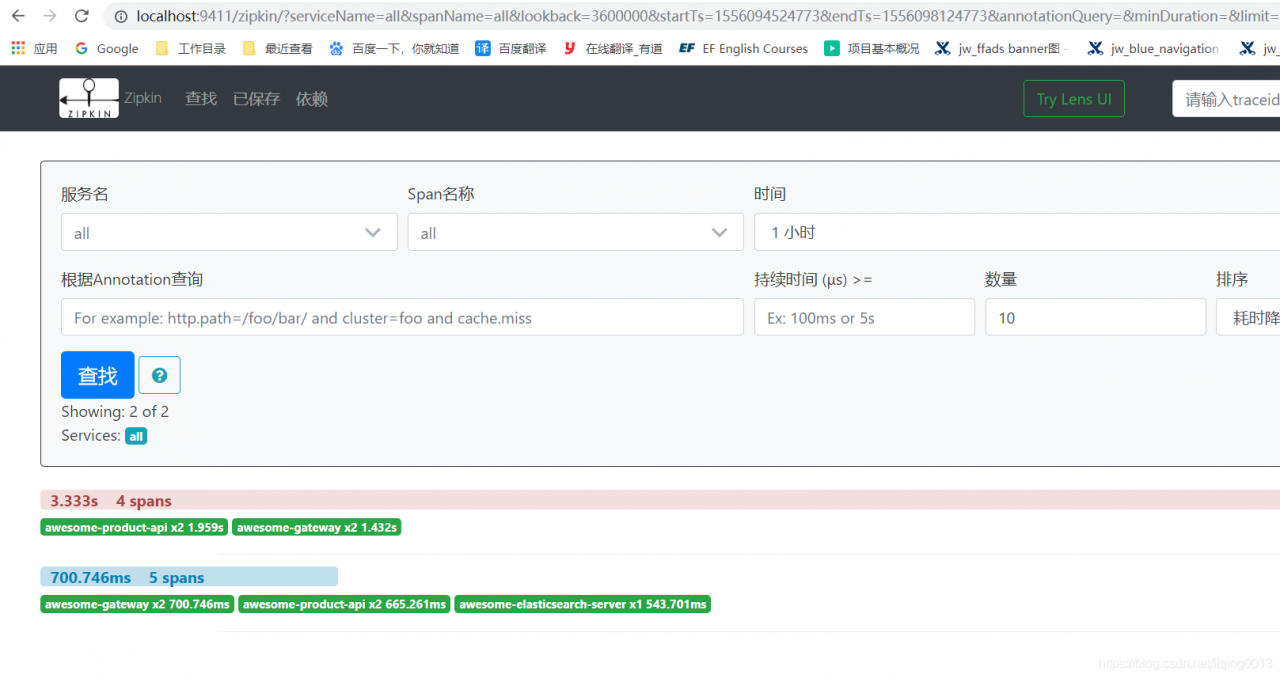
- 追踪访问:

版权声明:本文为liqing0013原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。