文章目录
1. MQ的作用
1.1 流量削峰
大量并发请求到服务器时,可能会造成很大的性能压力。增加MQ之后,可以让这些请求在消息队列中进行排队
1.2 应用解耦
如果没有MQ,当子系统出现故障时就会阻塞订单系统的正常功能使用。增加MQ之后,如果子系统出现问题,请求可以通过MQ进行重试,增加了服务的可用性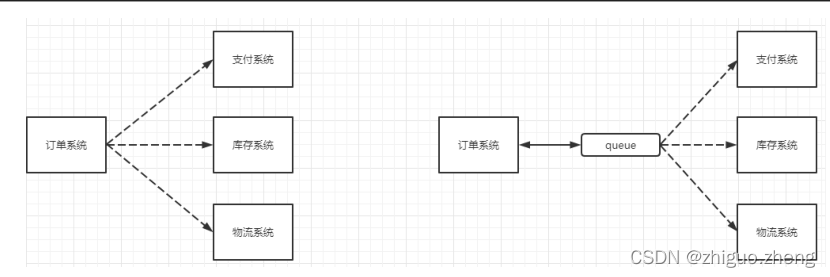
1.3 异步处理
A服务需要调用B服务,但是B服务处理需要很长时间,让A服务一直等待肯定是不行的,有了MQ之后A就可以将请求发送给MQ,由MQ去通知服务B。服务B执行完成之后还可以通过MQ去通知服务A已经执行完成了
2. 四大核心
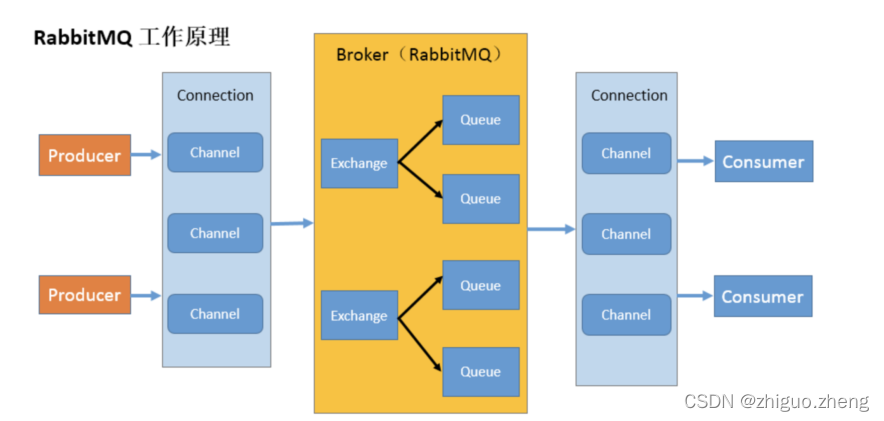
Connection: publisher/consumer 和 broker 之间的 TCP 连接
Channel: 如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP Connection 的开销将是巨大的,效率也较低。Channel 是在 connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个 thread 创建单独的 channel 进行通讯 AMQP method 包含了 channel id 帮助客户端和 message broker 识别 channel,所以 channel 之间是完全隔离的。Channel 作为轻量级的Connection 极大减少了操作系统建立 TCP connection 的开销
Binding: exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key,Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据
2.1 生产者
2.2 交换机
2.3 队列
2.4 消费者
3. 工作队列
也就是由多个消费者,默认情况下消息是轮询分发给每一个消费者
3.1 开启手动应答
自动ack会造成接收到消息后可能要处理比较长的时间,这时如果出现问题,其实这条消息是没有被处理成功的,但是MQ却认为我们处理成功了。所以一般情况下都不使用自动应答,当然这也是需要做出权衡的,因为自动应答性能更高。
// 声明消费者时设置 autoAck
boolean autoAck = false;
channel.basicConsume("queueName", autoAck, deliverCallback, consumer);
// 消费完成后手动应答
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
// 使用此方法进行应答
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
3.2 消息重新入队
当MQ发现消费者断开了连接但是没有发送 ACK 时,就会将消息重新入队分发给其他消费者处理
4. 队列持久化
重启MQ队列不会被删除
// 持久化的重点就是声明队列时设置durable
boolean durable = true;
channel.queueDeclare("queueName", durable, false, false, null);
5. 消息持久化
将队列中的消息写入磁盘中,但也不能保证不会丢失,消息可能还在内存中没有刷盘此时宕机也会丢失消息
// 设置这个的同时也要设置队列持久化,否则队列都没有了消息持久化也没用
// 持久化的重点就是发送消息时设置 MessageProperties.PERSISTENT_TEXT_PLAIN
// 生产者端设置
channel.basicPublish("exchangeName", "queueName", MessageProperties.PERSISTENT_TEXT_PLAIN, message)
6. 消息不公平分发
能者多劳
// 默认是0,轮询分发。改成1就是不公平分发,如果大于1就表示预取值,可以理解为最多可以屯多少条消息
// 消费者端设置,每个消费者都要设置
channel.basicQos(1);
7. 发布确认
解决消息丢失问题
发布确认的操作由生产者完成
// 开启确认发布
// 生产者端设置
channel.confirmSelect();
7.1 单个确认发布
每次发送完一条消息就要等待消费者确认之后,才会发送下一条消息
速度慢性能差,如果消息没有被确认后面的消息一直发不出去
for (i = 0; i < 1000; i++) {
channel.basicPublish("", queueName, null, message.getBytes());
// 等待确认,服务端返回 false 或超时时间内未返回,生产者可以消息重发
boolean flag = channel.waitForConfirms();
}
7.2 批量确认发布
一次性确认多条消息,具体数目由自己决定
缺点就是如果出现问题,不知道具体是哪个消息没有处理成功。
for (i = 0; i < 1000; i++) {
channel.basicPublish("", queueName, null, message.getBytes());
// 假设count统计已发送消息的数量,以下就是每100条确认一次
if (count % 100 == 0) {
// 等待确认,服务端返回 false 或超时时间内未返回,生产者可以消息重发
boolean flag = channel.waitForConfirms();
}
}
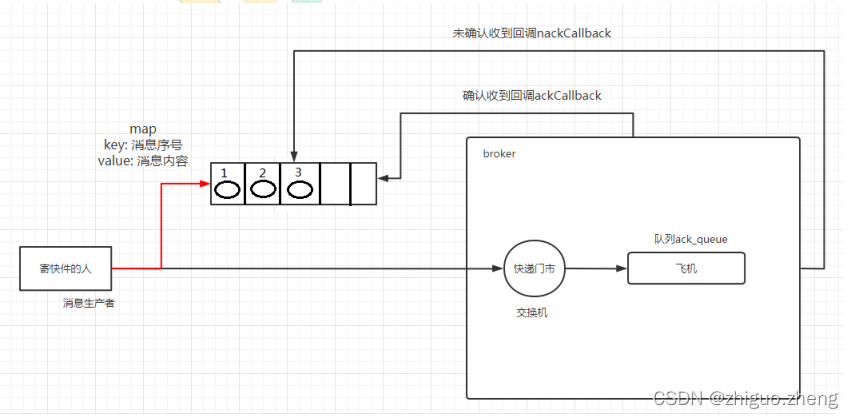
7.3 异步确认发布
性能最好
内存中维护已发送消息的一个 map,保存已发送的消息。当受到消息的确认之后就从map中移除这一条消息,代表消息成功消费了
8. 交换机
8.1 funout (广播)
8.2 direct (精准匹配)
8.3 topic (通配符)
9. 死信队列
消息没有正常被消费掉,就成为了死信会被放入死信队列中
9.1 死信来源
- 消息TTL过期,发消息时可以设置消息的过期时间,队列也可以设置消息的存放时间
- 消息被消费者拒绝,basic.reject() basic.nack() 并且requeue=false.
- 队列满了
10. 延迟队列
设置延迟一定时间,然后消息取出进行一些操作
下单十分钟未付款就取消订单
申请退款,24小时无人处理就通知后台
10.1 基于死信队列实现
通过死信队列实现延迟队列的效果时可能会出现问题,如果我们在发送消息时设置消息的过期时间,第一条为10秒,第二条为1秒。此时会出现问题,在死信队列的消费者端发现,ttl 为 1秒的消息并没有在 1 秒之后就被让如死信队列中,而是在第一条消息被消费之后才轮到他,也就是说是会排队的
10.2 基于插件
可以解决死信队列实现时存在的,延迟短的消息却没有被先消费的问题
安装插件 rabbitmq_delayed_message_exchange
交换机类型多了一个 x-delayed-message
也就是说延迟的操作交给了交换机实现
11. 发布确认高级
生产者发消息时,如果MQ宕机,或者说交换机和队列之间有一个没有了。此时消息就会被丢弃,这是我们不希望看到的。所以要对没有被交换机或者队列接收到的消息进行处理
11.1 交换机收不到消息
# 交换机接收消息后回调
spring.rabbitmq.publisher-confirm-type=correlated
11.2 队列收不到消息
# 回退消息
spring.rabbitmq.publisher-returns=true
12. 备份交换机
通过给交换机指定一个备份交换机,使得消息无法发送到交换机时可以由备份交换机接收,不一定要回退给生产者
交换机可能是不可用状态,也可能是 routekey 写错了
13. 幂等性问题
幂等性:多次重复的操作结果应该是一致的
如何保证消息不被重复消费,就是解决幂等性问题的关键
场景:不能重复对用户进行扣款
13.1 唯一ID + 指纹码
指纹码指的是根据业务规则时间戳等,生成一个唯一的id。
消费消息时从数据库中判断一下id是否存在。如果存在就说明消费过了
13.2 redis setnx
推荐使用redis的分布式锁
14. 优先队列
消息增加一个优先等级的数字 0-255,越大越优先
队列设置为优先级队列 x-max-priority
消息需要先全部发送到队列中再由消费者来消费才可以排序
15. 惰性队列
消息直接存储到磁盘上,而不是存储再内存中
用于消费者出现问题长时间不能进行消费,就先通过惰性队列存储到磁盘上,减少内存的空间占用
消费时再从磁盘读取到内存中,性能较差
普通队列想实现持久话,需要队列是持久化并且消息发送时也设置了持久化
16. 镜像队列
再集群模式下,再一个节点中创建的队列,再其他节点中