Multi-Agent Reinforcement Learning Based Frame Sampling for Effective Untrimmed Video Recognition
ICCV 2019 (oral)
2019-08-01 15:08:19
Paper:https://arxiv.org/abs/1907.13369
1. Backgroud and Motivation:
本文提出一种基于多智能体强化学习的未裁剪视频识别模型,来自适应的从未裁剪视频中,截取出样本视频帧进行行为识别。具体的示意图如下所示:

2. Architecture
2.1 Context-aware Observation Network:
这个 context-aware observation network 是一个基础的观测网络,随后是 context network。这个基础的观测网络是用于编码 选中的视频帧的视频信息,输出为 feature vector,作为 context network 的输入。与 single-agent 系统不同的是,multi-agent 的系统,每一个智能体的选择不仅依赖于 local environment state,而且受到 context information 的影响。所以,我们设计了一个 context-aware module,来维持一个 joint internal state of agents,用一个 RNN 网络将 history context information 进行总结。为了能够使之更加有效的工作,每一个智能体 only accesses context information from its 2M neighboring agents but not from all agents. 正式的来说,所有的时间步骤 t,智能体 a 观测到一个组合的状态 $s_t^a$ 及其 之前的 hidden state $h_{t-1}^a$ 作为 context module 的输入,然后产生其当前的 hidden states:

2.2 Policy Network:
作者采用 fc + softmax function 作为 policy network。在每一个时间步骤 t,每一个智能体 a,根据策略网络产生的概率分布, 选择一个动作 $u_t^a$ 来执行。动作集合是一个离散的空间 {moving ahead, moving back and staying}。并且设置一定的步幅。当所有的智能体都选择 staying 的时候,意味着该停止了。
2.3 Classification Network:
就是将选中的视频帧进行 action 的分类。
3. Objectives
本文将同时进行 奖励最大化的优化 以及 分类网络的优化。
3.1 MARL Objective:
Reward function: 奖励函数反应了 agents 选择动作的好坏。当所有的智能体都选择动作时,每一个时刻 t,每一个智能体基于分类的概率 $p_t^a$ 得到了其各自的奖励 $r_t^a$ 。给予 agent 奖励可以促使其知道更加具有信息量的 frame,从而一步一步的改善正确预测的概率。所以,作者设计了一个简单的奖励函数,鼓励模型增加其 confidence。特定的,对于第 t 个时间步骤来说,agent a 接收的奖励按照如下的方式进行计算:
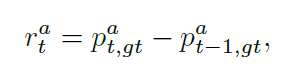
其中,$p_{t,c}^a$ 代表了智能体 a 在时刻 t 模型将其预测为 class c 的概率,gt 是视频的 ground truth label。所有的智能体共享同一个 reward function。考虑到序列决策的场景,考虑累积折扣回报是更加合适的,即:将来的奖励对当前的步骤贡献更小一些。特别的,在时刻 t,对于智能体 a 来说,折扣的回报可以计算如下:
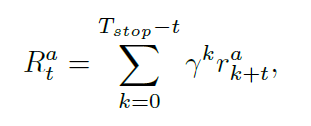
Policy Gradient: 服从 REINFORCE 算法,作者将目标函数设置为:
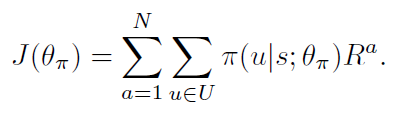
在本文的情况下,学习网络参数使其可以最大化上述公式,其梯度为:
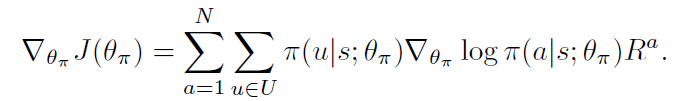
这变成了一个 non-trivial optimization problem, 由于 action sequence space 的维度过高。REINFORCE 通过蒙特卡洛采样的方式,进行梯度的估计:
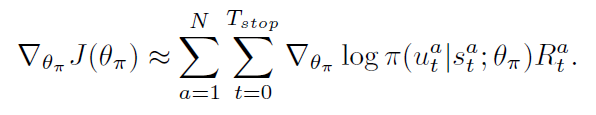
然后,我们可以利用随机梯度下降的方式,来最小化下面的损失:

Maximum entropy:
为了避免让策略迅速变的 deterministic,研究者考虑将 entropy regularization 技术引入到 DRL 算法中,以鼓励探索。更大的熵,agent 就会更加偏向于探索其他动作。所以,我们利用 policy 的 entropy 来进行正则:
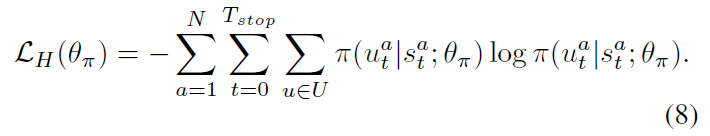
所以,MARL 总得损失是上述两个损失函数的加和:

3.2 Classification Objective :
作者用 Cross-entropy loss 来最小化 gt 和 prediction p 之间的 KL-散度:
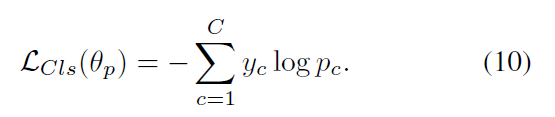
最终,我们优化组合损失,即:
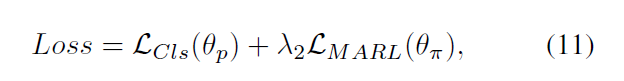
4. Experiments:
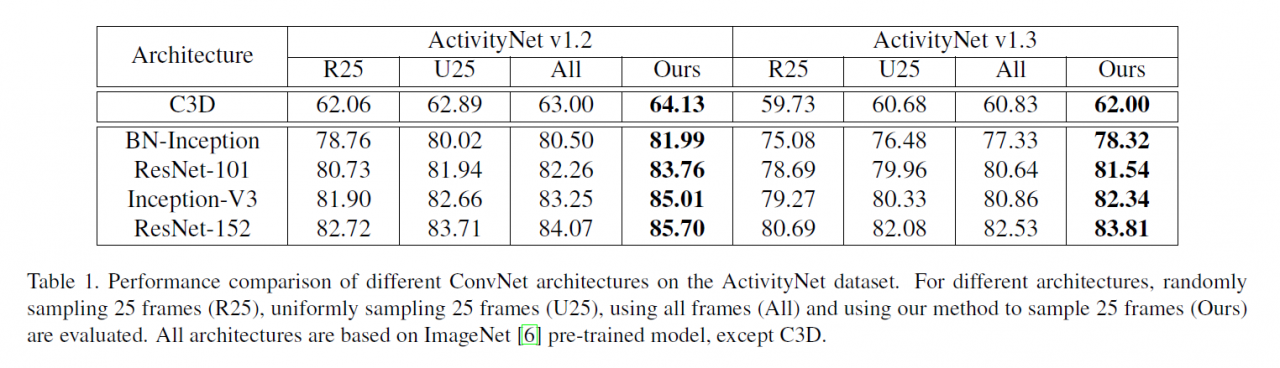
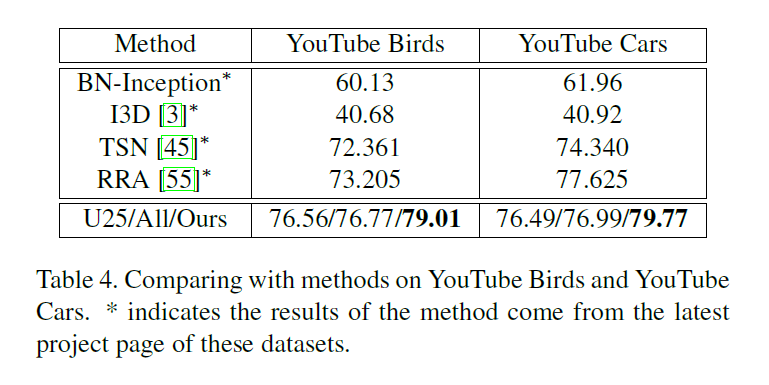
==
转载于:https://www.cnblogs.com/wangxiaocvpr/p/11281864.html