Visual Attention Network(VAN)算法分析
VAN 提出了一种新的大核注意力large kernal attention(LKA)模型, LKA吸收了卷积和自我注意的优点,包括局部结构信息、长程依赖性和适应性。同时,避免了忽略在通道维度上的适应性等缺点。作者进一步介绍了一种基于LKA的新型神经网络,即视觉注意网络(VAN)。VAN在图像分类、目标检测、实例分割、语义分割方面,都”远远超过了”SOTA的CNN和视觉transformer。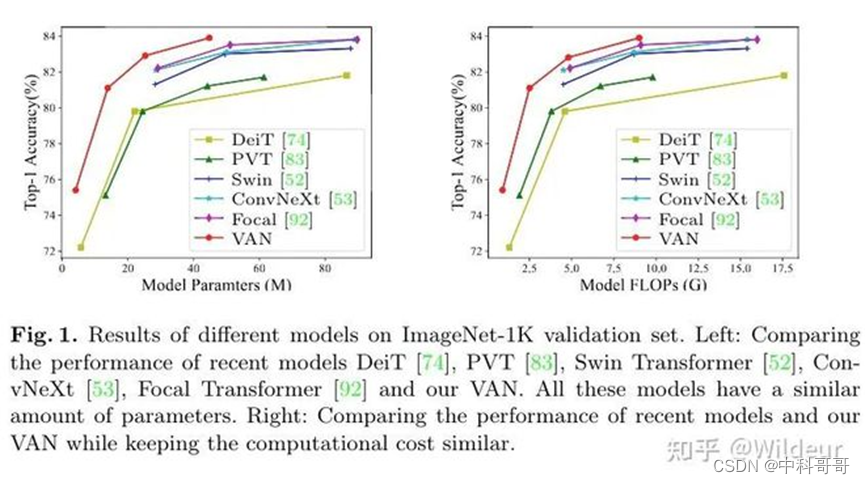
代码链接:https://link.zhihu.com/?target=https%3A//github.com/Visual-Attention-Network
论文链接:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2202.09741
需要训练模型的找我,有源码有结果
该文章主要工作
CNN 提出后
学习特征表示(feature representation)很重要, CNN因为使用了局部上下文信息和平移不变性,极大地提高了神经网络的效率。 在加深网络的同时,网络也在追求更加轻量化。 本文的工作与MobileNet有些相似,把一个标准的卷积分解为了两个部分: 一个depthwise conv,一个pointwise conv。 本文把一个卷积分解成了三个部分: depthwise conv, depthwise and dilated conv 和pointwise conv。 我们的工作将更适合高效地分解大核的卷积操作。 我们还引入了一个注意力机制来获得自适应的特性。
视觉注意力方法
注意力机制使得很多视觉任务有了性能提升。 视觉的注意力可以被分为四个类别: 通道注意力、空间注意力、时间注意力和分支注意力。 每种注意力机制都有不同的效果。
Self-attention 是一个特别的注意力,可以捕捉到长程的依赖性和适应性,在视觉任务中越来越重要。但是,self-attention有三个缺点:
- 它把图像变成了1D的序列进行处理,忽略了2D的结构信息。
- 对于高分辨率图片来说,二次计算复杂度太高。
- 它只实现了空间适应性却忽略了通道适应性。
**对于视觉任务来说,不同的通道经常表示不同的物体,通道适应性在视觉任务中也是很重要的。**为了解决这些问题,我们提出了一个新的视觉注意力机制:LKA。它包含了self-attention的适应性和长程依赖,而且它还吸收了卷积操作中利用局部上下文信息的优点。
视觉MLP
在CNN出现之前,MLP曾是非常知名的方法。 但是由于高昂的计算需求和低下的效率,MLP的能力被限制了很长一段时间。 最近的一些研究成功地把标准的MLP分解为了spatial MLP和channel MLP,显著降低了计算复杂度和参数量,释放了MLP的性能。 与我们最相近的MLP是gMLP, 它分解了标准的MLP并且引入了注意力机制。
但是gMLP有两个缺点:
- gMLP对输入尺寸很敏感,只能处理固定尺寸的图像。
- gMLP只考虑了全局信息而忽略了局部的信息。
论文核心技术:
大核注意力机制LKA
注意力的关键就是生成显示不同点之间关系的注意力图。
目前有两种知名的方法来构建不同点之间的关系:
- 用自注意力机制,但是2.2讲了它有三个缺点
- 用大核卷积,但是计算量和参数量太大
为了解决上述的缺点并且利用self-attention 和 large kernel conv的优点。本文提出分解大核卷积操作来获取长程关系。Fig.2所示, 一个大核卷积可以被分成三个部分:一个局部空间卷积(depthwise conv)、一个空间长程卷积(depthwise dilation conv)、一个通道卷积(1 x 1 conv)。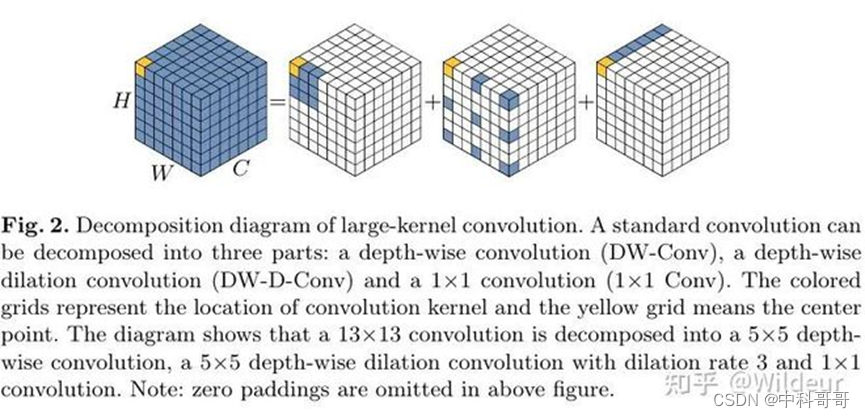
通过上述分解,我们可以用很少的计算量和参数去捕获长程的关系。在得到长程关系之后,我们可以估计一个点的重要性并且生成注意力图。
LKA如图所示: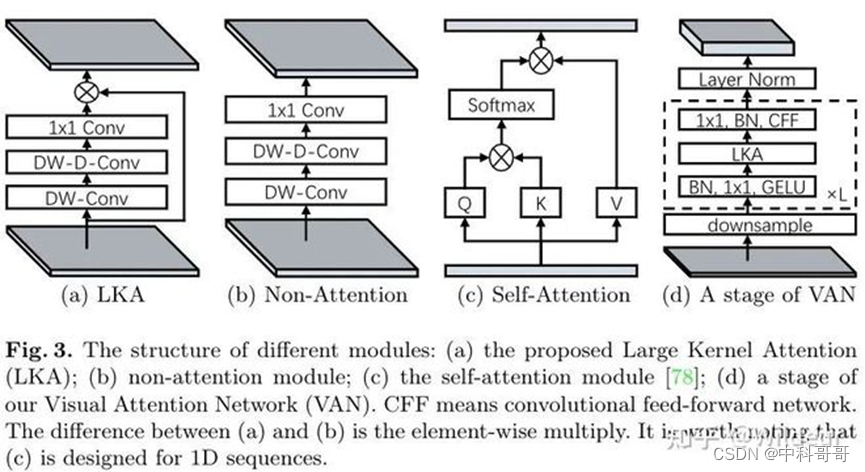
LKA模块可以被写成:
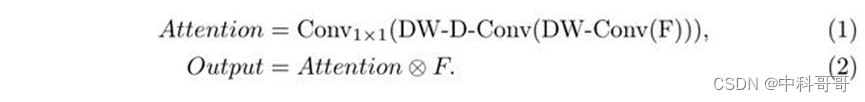
就如表1所述,LKA融合了Conv和self-Attention的优点。

视觉注意力网络(VAN)
VAN是一个简单的层级 结构,由四个stage序列构成,每个stage都会降低空间分辨率和增加通道数。

1、计算复杂度分析
我们假设输入和输出的特征都具有相同的大小 HxWxC,则参数和FLOPs可以被写成如下:
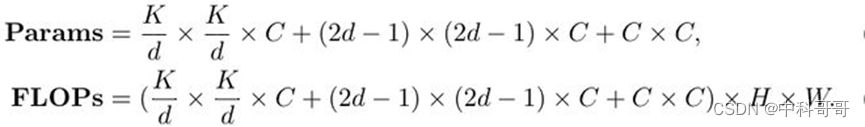
在这里,d是空洞率,K是核大小,当K=21时,Params可以被写成:
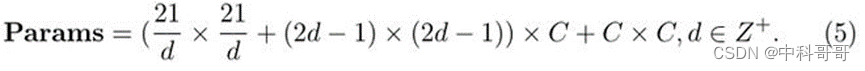
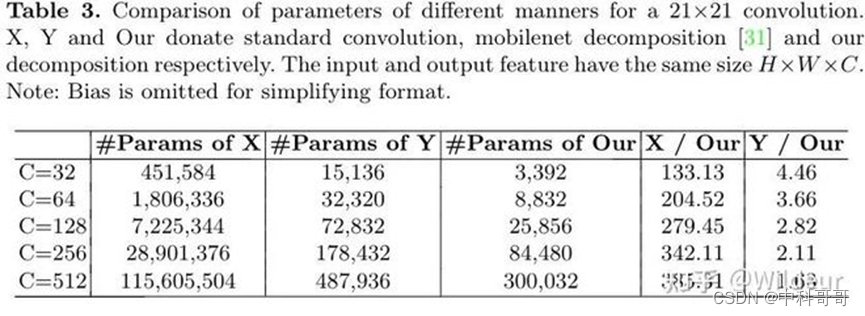
我们发现d=3时,公式(5)最小,所以我们默认把K设为21,d设为3,表3表明我们的分解方法在分解大核卷积时有显著的优势。
2、实现细节
默认的,我们使用5x5depthwise conv、7x7的空洞为3的卷积和1x1卷积来近似一个21x21的卷积。在这种设置下,VAN可以有效的实现本地信息和长程的连接。
未来VAN改进方向:
继续改进它的结构。在本文中,只展示了一个直观的结构,还存在很多潜在的改进点,例如:应用大核、引入多尺度结构和使用多分支结构。
大规模的自监督学习和迁移学习。VAN 自然地结合了CNN和ViT的优点。一方面VAN利用了图像的2D结构。另一方面 VAN可以基于输入图片动态的调整输出,它很适合自监督学习和迁移学习。结合了这两点,作者认为VAN可以在这两个领域有更好的性能。
更多的应用场景。由于资源有限,作者只展示了它在视觉任务中的优秀性能。作者期待VAN在各个领域都展示优秀性能并变成一个通用的模型。