近期由于工作原因,碰巧使用到了flink+kafka+hdfs+kerberos流式计算。一路走来,崎岖坎坷,满是荆棘。以此文记录一下学习实践经历。若能为各位后来者提供帮助,实乃我幸!
关于一些基础的理论性知识我也不再赘述,需要的童鞋们可以去度娘或者google,这里我只说自己在实践中遇到的坑和解决的方案。
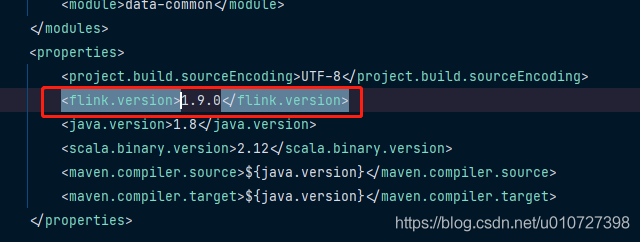
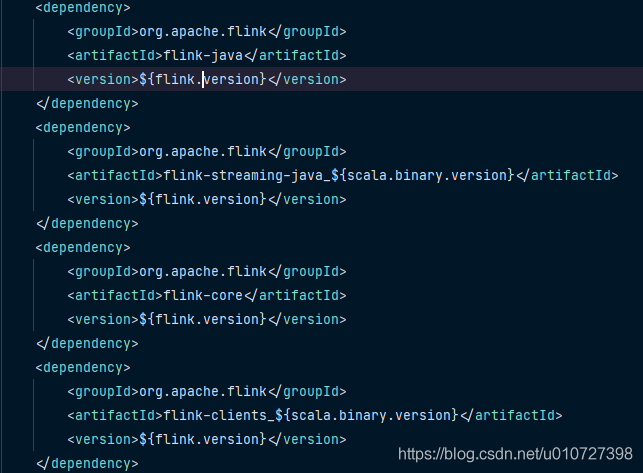
1.在IDEA中可以正产运行,但是提交到flink单机集群或者yarn集群报类加载的相关错误,请排查flink的jar包版本和flink集群是否匹配,如不匹配,则更换至对应的核心jar,因为flink各版本之间存在兼容问题。如下图:

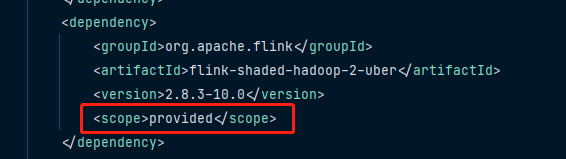
2.Hadoop相关的jar包在maven中务必使用provided,否则可能会导致jar冲突类似问题,且flink报错不是很准确。如下图:
3.flink程序中尽量不要用static Map做jvm缓存,在实际运行代码的时候,IDEA没有问题,但是在集群运行会出现取不到值的情况,实在要用,则在new Function时,作为构造函数的参数传递进去。如图:

4.如果你存在多个kdc认证服务,flink中kerberos认证配置需要指定特殊的krb5.conf,而不是直接访问/etc/krb.conf。通过-Djava.security.krb5.conf=/home/mcd_cep/kerberos/krb5.conf指定,你会发现无效。这个时候需要通过指定taskManager的运行参数,才能生效。且flink-conf.yaml中 不需要指定jaaz。conf文件。如图:

5.提交任务到flink yarn 执行,需要指定特殊krb5.conf时,1.13版本之前的flin需要保证yarn节点的机器存在kdc的配置文件,即krb5.conf,然后类似上一个问题一样设置即可。
6.如果要提交到yarn运行,建议现在standalone Cluster验证通过后,在提交任务至yarn。因为单机集群定位问题,相对比较方便。
7.日志查看:可以修改flink/conf目录下面log4j相关的配置文件。通过flink-conf.yaml指定日志目录,flink-xxxx-client-xxxx.log为客户端启动日志;flink-xxxx-taskexecutor-xxxx.log为任务的运行日志。学会看日志很有帮助,可以减少很多盲目的问题。
实际远不止这一点坎坷,暂时只想起这些。后续想起来在补充一二。