参考:https://blog.csdn.net/zghnwsc/article/details/115982794
参考视频:李宏毅机器学习2021
https://www.bilibili.com/video/BV1y44y1e7FW?spm_id_from=333.337.search-card.all.click
self attention解决的问题
到目前为止,我们network的input都是一个向量,输入可能是一个数值或者一个类别。但是假设我们需要输入的是一排向量,并且向量的个数可能会发生改变,这个时候要怎么处理。
比如文字处理的时候: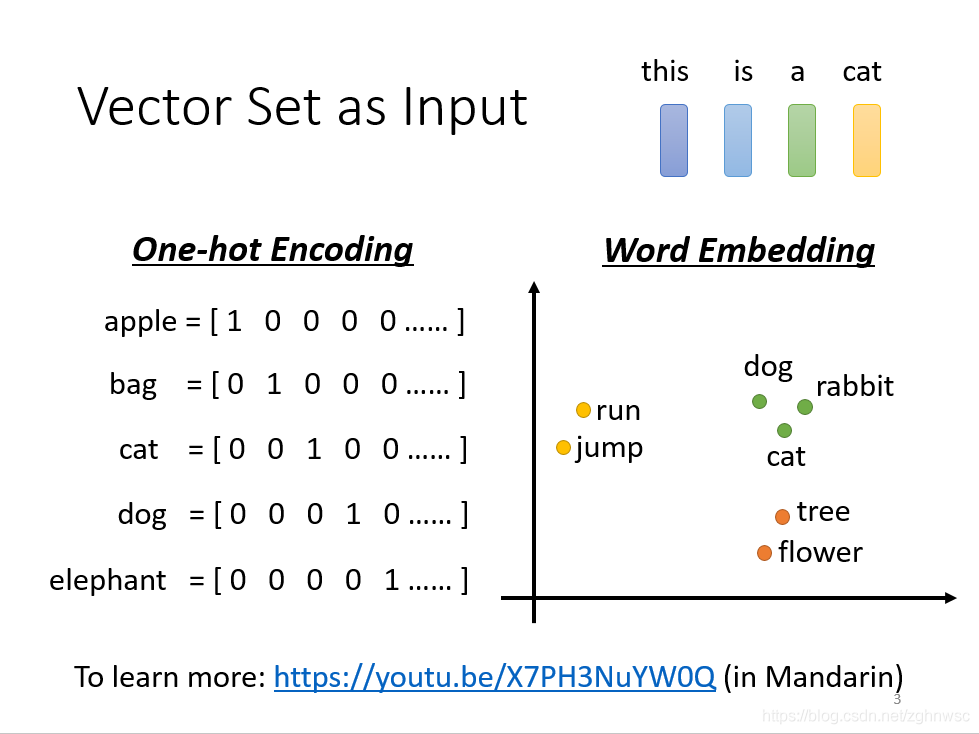
比如我们输入词汇,每个词汇都相当于一个向量,我们可以用很长的一个向量,来表示世界上所有的东西,但是这里有一个问题,就是它假设所有的词汇都是没有关系的,比如猫和狗,都是动物,但是这样没有办法把它分类在一起,没有语义的资讯。
有一个叫word embedding的方法,可以把一些东西分类,比如猫狗分类成动物,树、花分类到植物里面去。
又比如:一个图,也可以看成是一堆向量。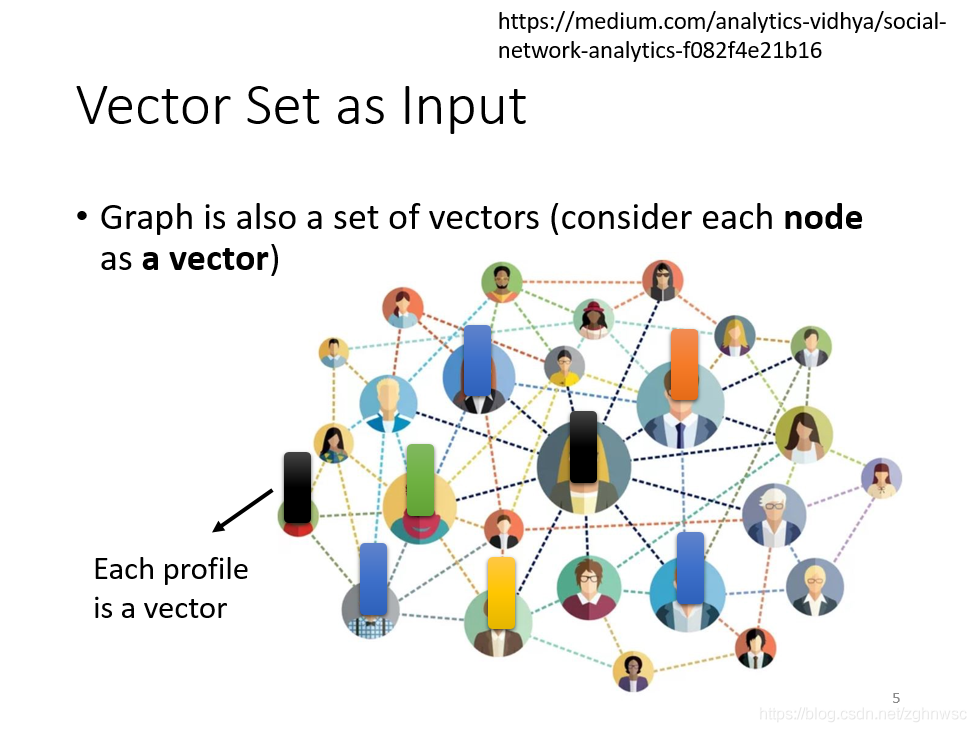
一个social network,一个graph,也可以看成是一堆向量表示的,里面的一个节点,可以看成是一个向量。
输出是什么
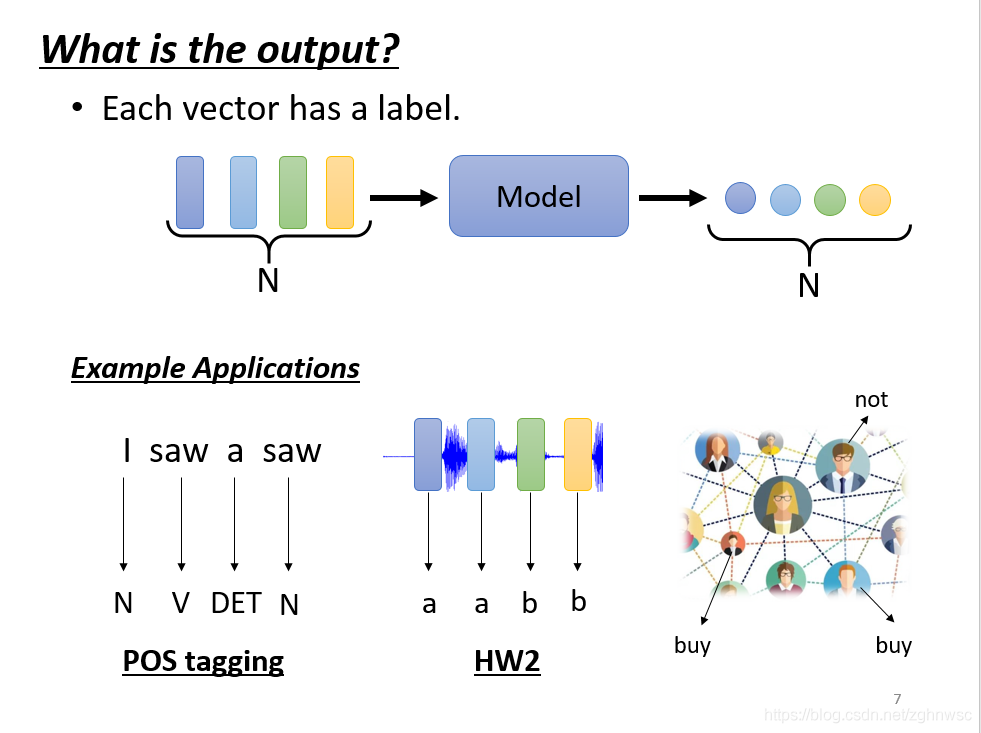
第一种类型,输入是几个向量,输出就是几个lable,它可能是一个数值,就是一个regression的问题,输出也可能是一个分类,就是一个classification的问题。这里输入4个向量就是输出4个向量。
比如输入一个句子,I saw a saw,这里每一个输入的词汇就有一个对应的lable。
又比如一个social network,比如给一个图片,机器要决定每一个节点,比如说这个人会不会买某一个商品。
第二种类型,就是一整个sequence,只需要输出一个lable就可以了。
比如给机器一句话,它判断这个句子是正面的还是负面的。
第三种可类型,就是输入n个向量,输出的几个lable是机器自己决定的。
(seq2seq就是sequence to sequence,比如这一种翻译的例子,就是seq2seq的任务,后面还会讲到)
sequence labeling
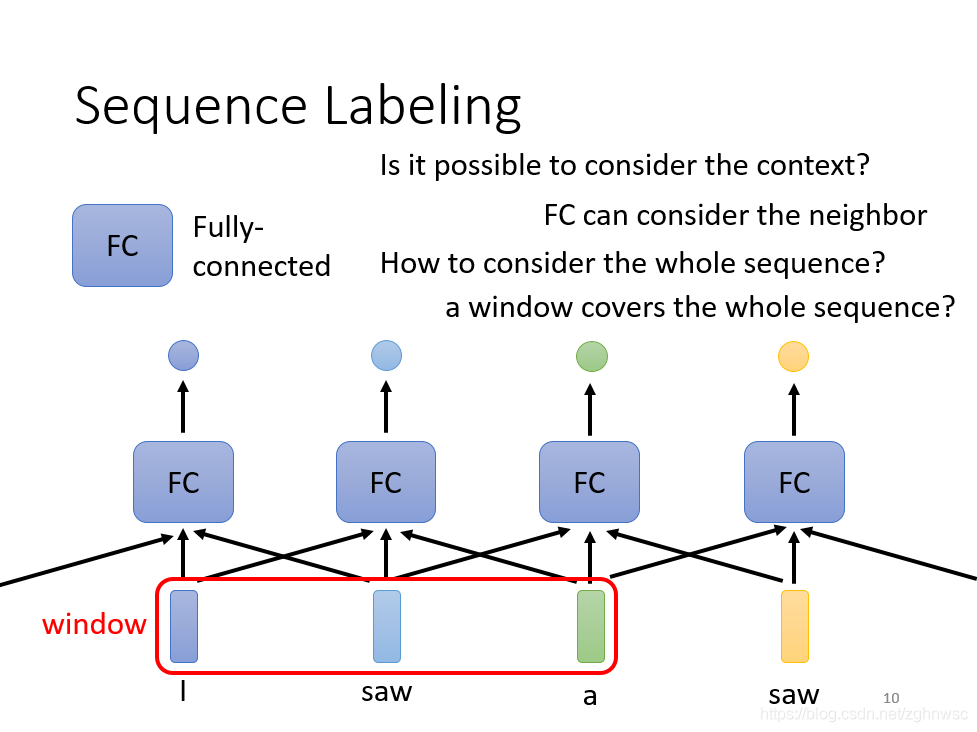
输入和输出一样多的情况,也叫做sequence labeling。
我们可以用fully conneted network解决这个问题,但是这样会有瑕疵,比如输入I saw a saw,这两个saw,对于FC(fully conneted network,全连接网络,下同)来说,是一模一样的,但是实际上它们一个是动词,一个是名字,还是有区别的。
或者我们可以直接把这几个向量前后串联起来,然后一起丢到FC里面。
但是这样不能解决所有的问题,我们输入的sequence是有长有短的,如果开一个大的Window,那FC就需要非常多的参数,不止是很难训练,而且很容易过拟合。
这里我们就需要一个self-attention的技术。
**
self-attention
**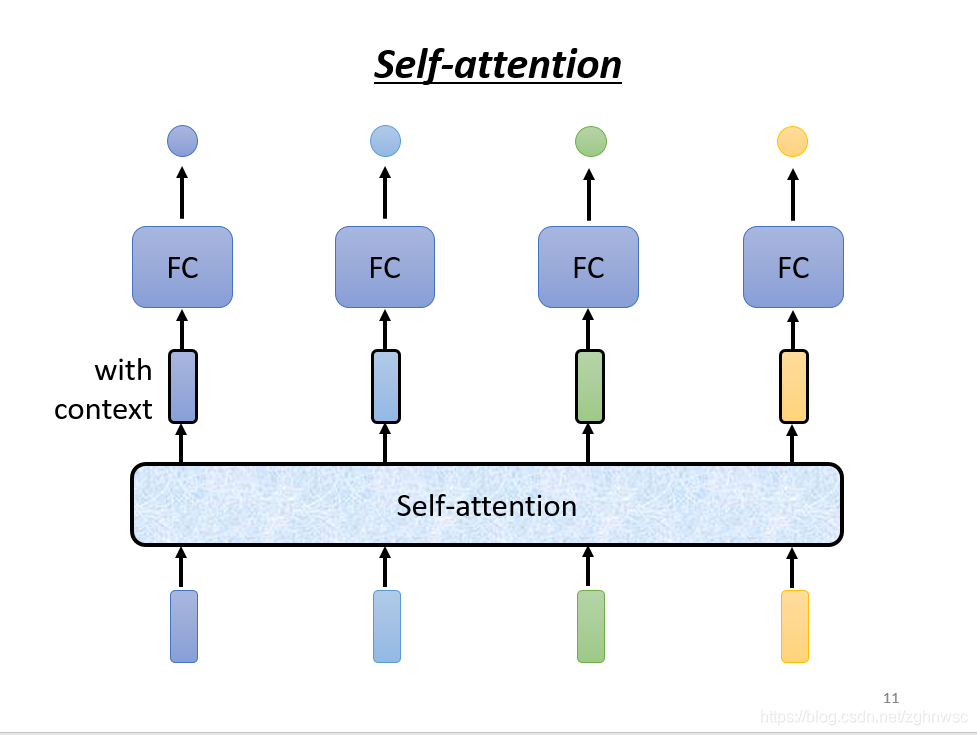
self-attention会把一整个sequence的资讯都吃进去,然后你输入几个向量,它就输出几个向量,比如图上,输入不同颜色的向量,就会输出不同颜色的向量,这里用黑色的框框,表示它不是普通的向量,是用来表示考虑了一整个sequence的向量。
self-attention也可以和FC交替使用,用self-attention来处理整个sequence的资讯,FC来专注处理某一个位置的资讯。
self-attention是怎么运作的呢?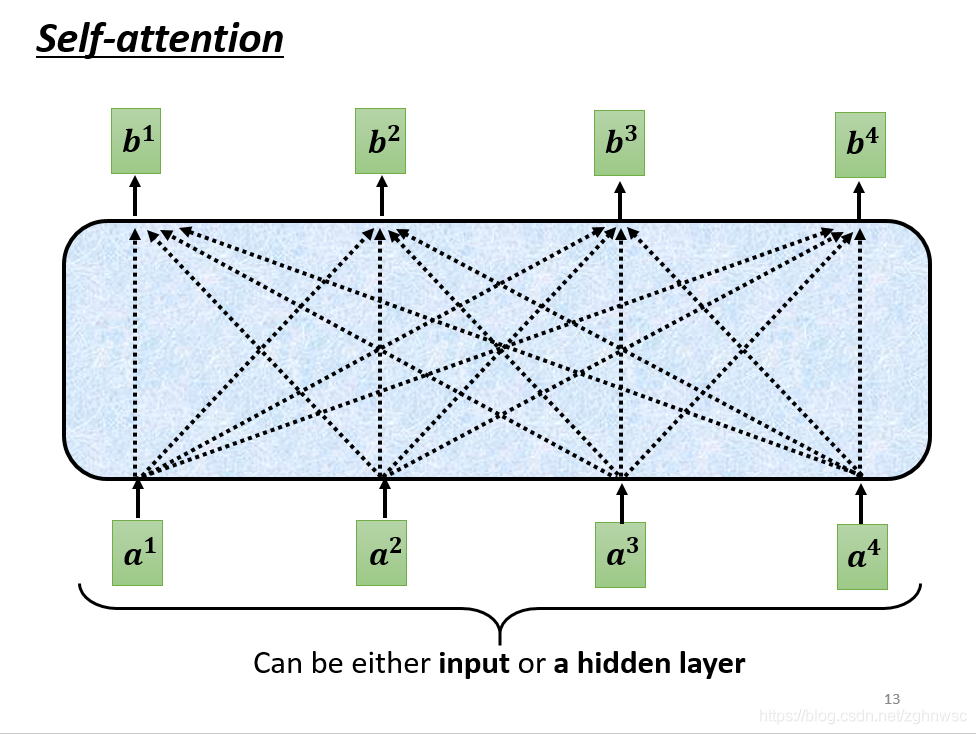
self-attention的inpu就是一串的向量,这个向量可能是整个网络的input,也可能是中间某一层的output,所以我们用a来表示它,代表它可能做过一些处理。
这里的每一个b都是考虑了所有的a产生的,比如b1是考虑a1~a4产生的,b2是考虑a1 ~ a4产生的。
那么怎么产生b1这个向量呢?
第一个步骤:根据a1找出这个sequence里面和a1相关的其他向量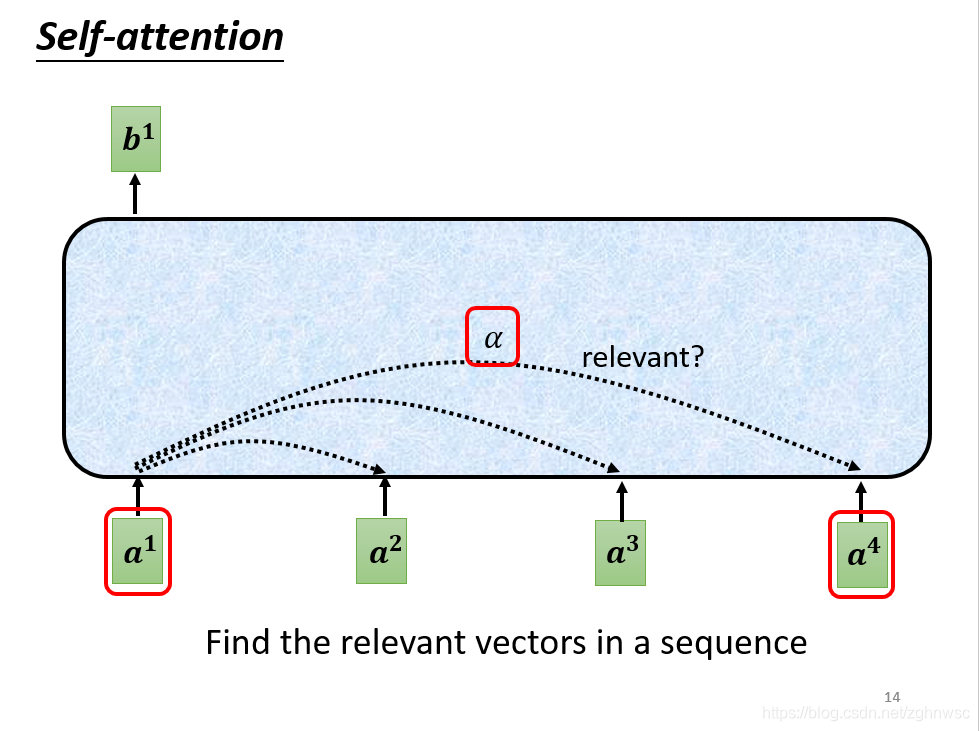
每一个向量和a1关联的程度,我们用一个数值α来表示。
那么这个α是怎么产生的呢?
就是给一个a1和a4,怎么去决定它们之间的关联程度α是怎么样的呢?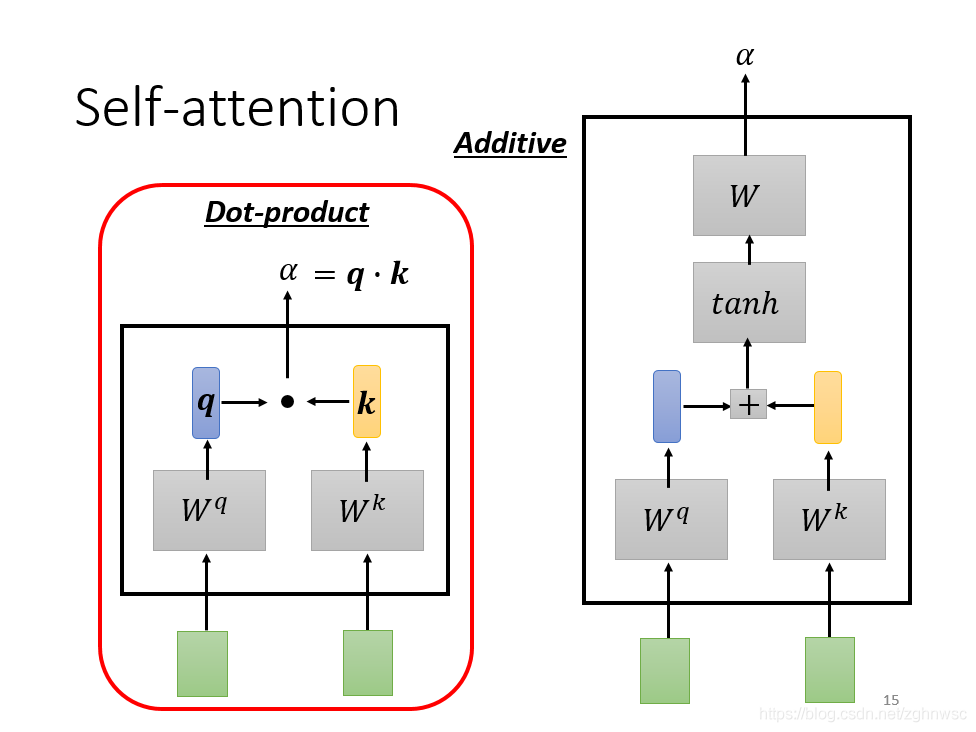
那我们就需要一个计算attention的模组。
这个模组,就是拿两个向量a1和a4作为输入,然后输出的是一个α。
怎么计算这个数值,有各种不同的做法,比较常见的有dot-product。
这里就是左边这个向量乘以一个Wq,右边这个向量乘以一个Wk,得到q和k,再把他们做element-wise(就是对应数值相乘,这里听了好几遍哈哈,要不是以前听过一遍课绝对听不出来),然后再全部加起来,得到一个scalar,这个scalar就是α。
这是一种计算的方式,还有其他的方式,比如additive,就是把他们分别乘以一个矩阵,再加起来,再经过一个激活函数,最后经过一个transfor,最后得到一个α。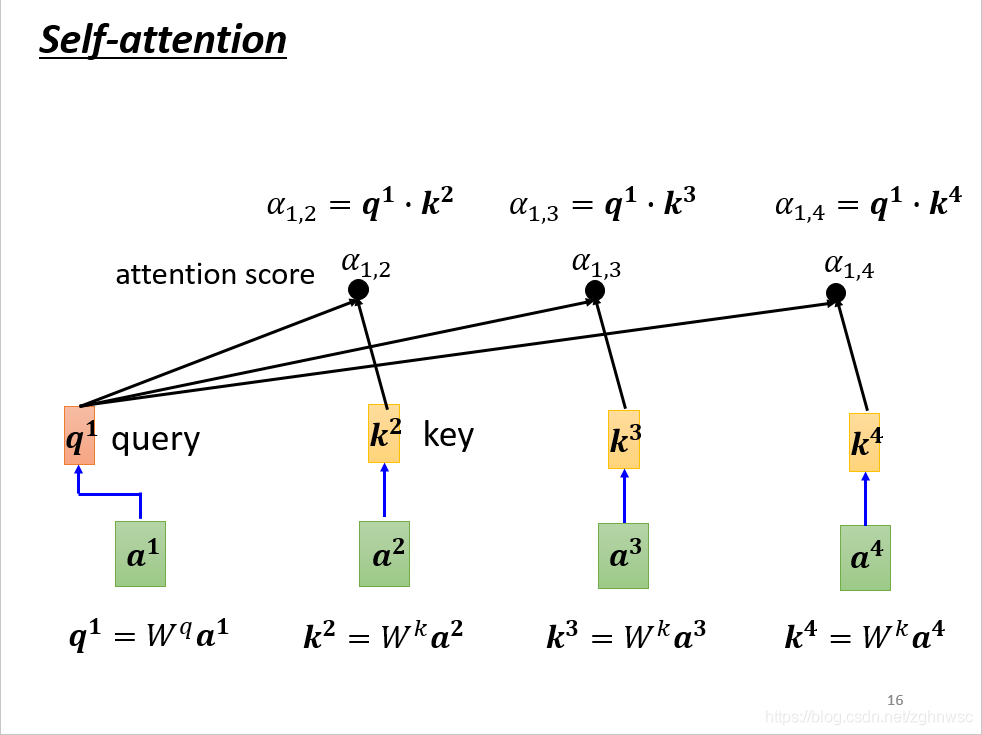
那么怎么把它套用在self-attention里面呢?
这里就是把a1和a2、a3、a4分别去计算他们之间的关联性。
就是把a1乘上Wq得到q1,叫做query。
a2、a3、a4都乘以一个Wk得到一个k2,叫做key。
再把q1和k2算inner-product得到α。α1,2就表示,query是1提供的,key是2提供的,就表示1和2之间的关联性。
α1,2也叫做attention score,就是attention的分数。
接下来就以此类推,和a3、a4计算,得到α1,3,和α1,4。
(实际操作中,a1也会计算和自己的关联性,就是算出来一个α1,1)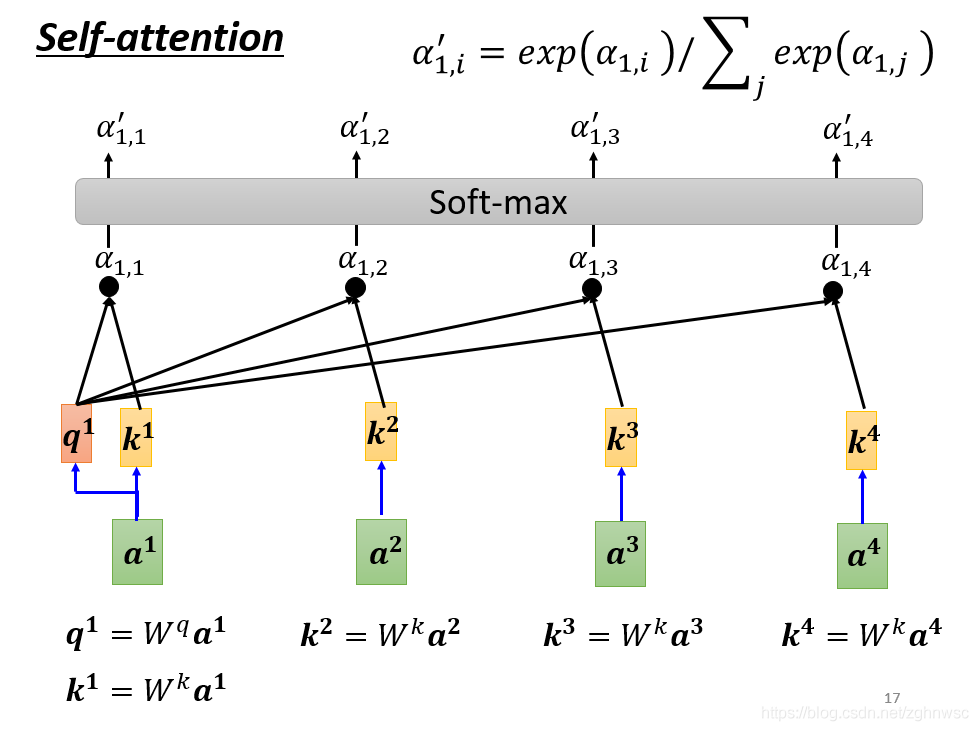
算完关联性之后,会做一个soft-max。跟前面的分类的soft-max是一模一样的。
(softmax就是把多个数值标准化到0~1之间,分类问题里面是根据这个可能更好的看出最后是分到哪一类里面,相当于增强最大可能的项)
(也可以用别的,不一定非要用soft-max)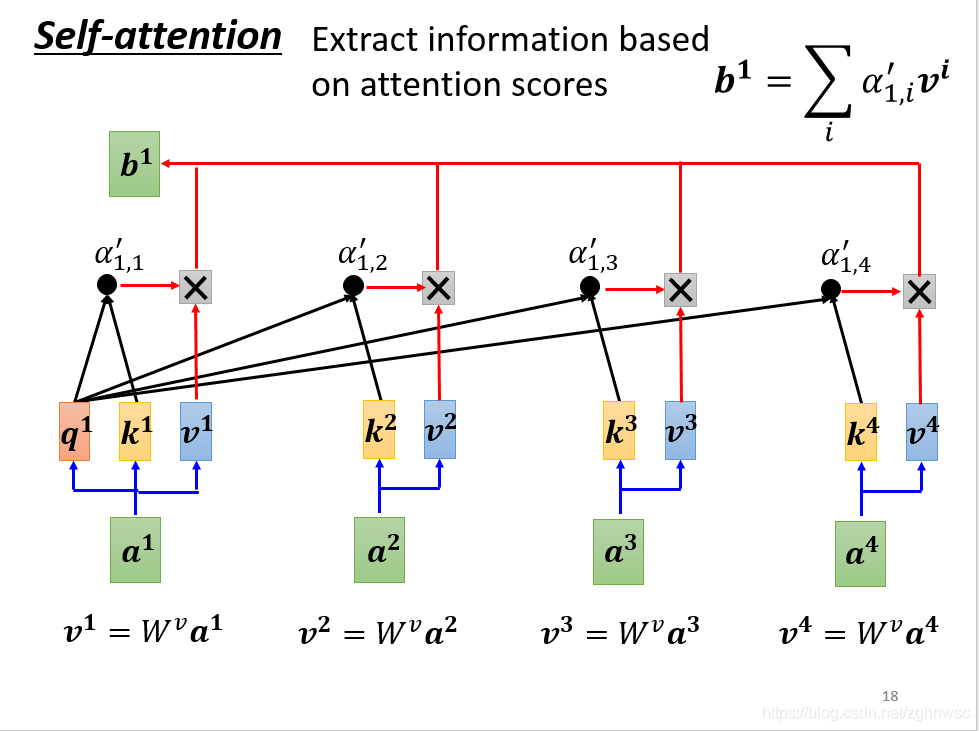
接下来我们要根据这个关联性,来抽取重要的资讯。
我们会把a1~a4这里面每一个向量,乘上Wv得到一个新的向量,用v1、v2、v3、v4表示。
接下来,把v1~v4每一个都乘上α’,然后加起来得到b。这里就是如果某一个关联性很强,比如得到的v2的值很大,那么加起来之后,这个值可能就会更加接近v2
总结:所以这里我们就讲了,怎么从一整个sequence得到一个b1.
之前我们已经介绍了,怎么根据input的一排a,得到一个b1.
这里需要强调一点,b1到b4,并不需要按顺序。
(这里就不再赘述怎么得到b1了)
这里我们从矩阵乘法的角度再来看一遍b是怎么产生的。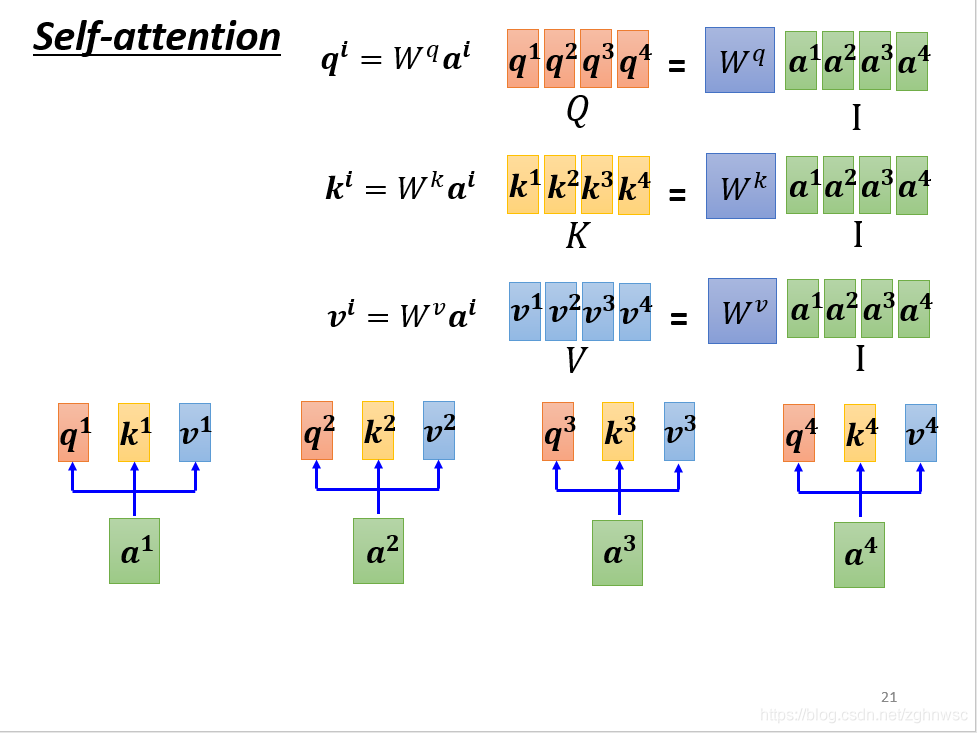
每一个a,都分别要产生不同的q,k,v。
要用矩阵运算表示的话,就是每一个a都要乘上一个wq,这里我们可以把它们合起来看成是一个矩阵。就相当于矩阵I乘上一个Wq得到一个矩阵Q。(线性代数内容,很简单)
k和v以此类推,只是现在把它写成了矩阵的形式。
下一步: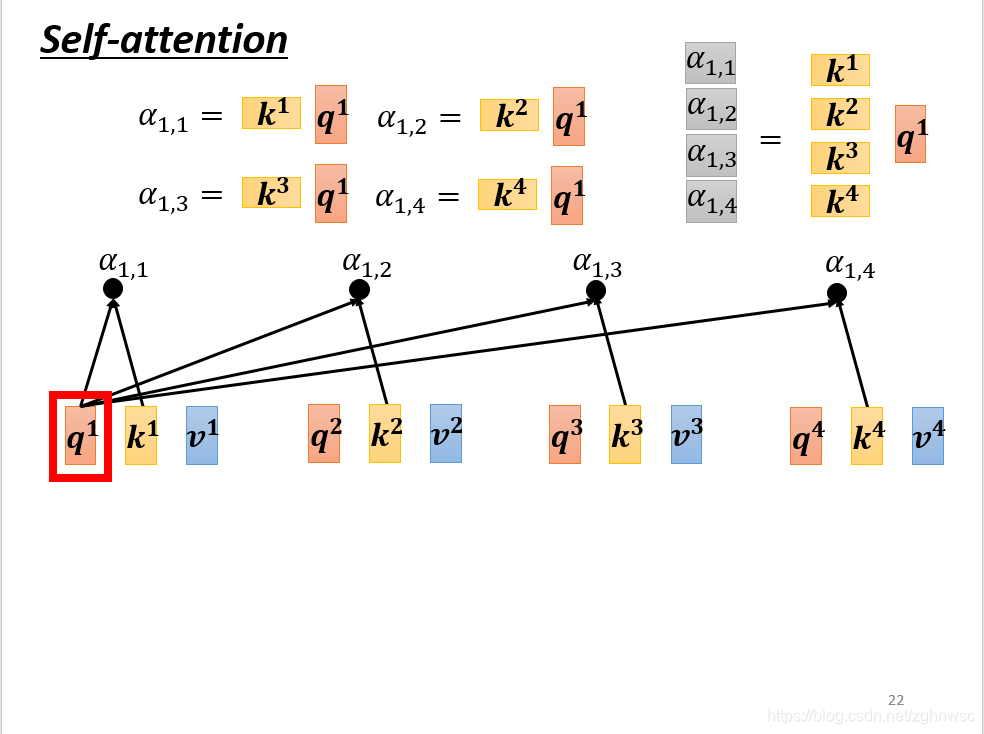
就是k1和q1做inner-product,得到α1,1,同理得到α1,2和α1,3……
这几步的操作,可以看做是一个矩阵的相乘。写成右上角的形式。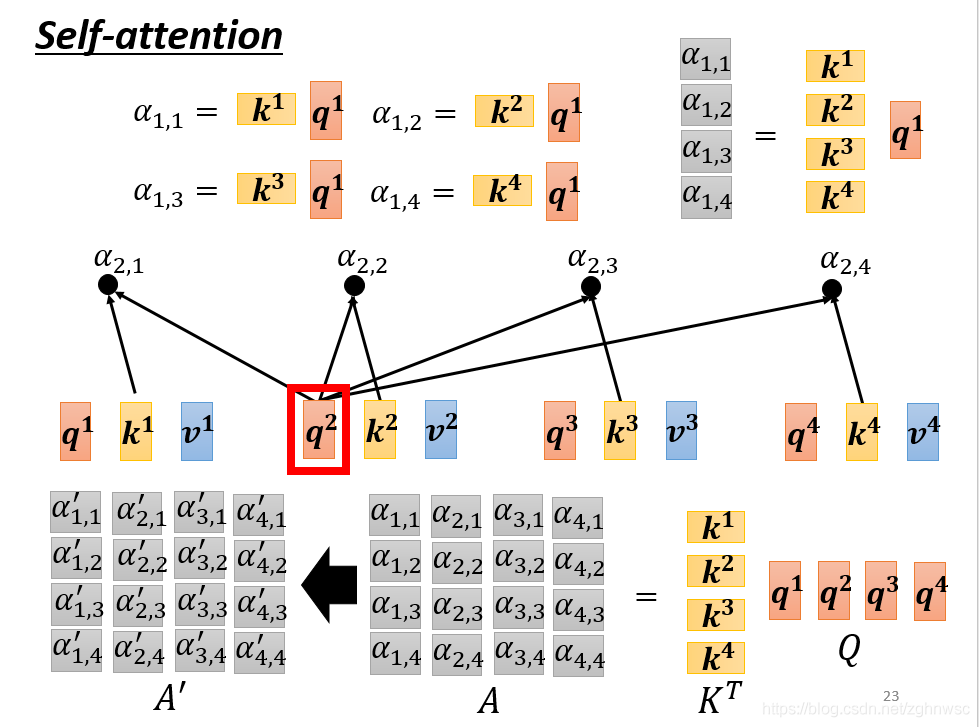
然后这几步的操作是一模一样的,矩阵相乘,行乘以列,线性代数内容。
然后我们把A做一个normalization,比如做一个softmax,让每一个column里面的值,相加得1,得到一个A’。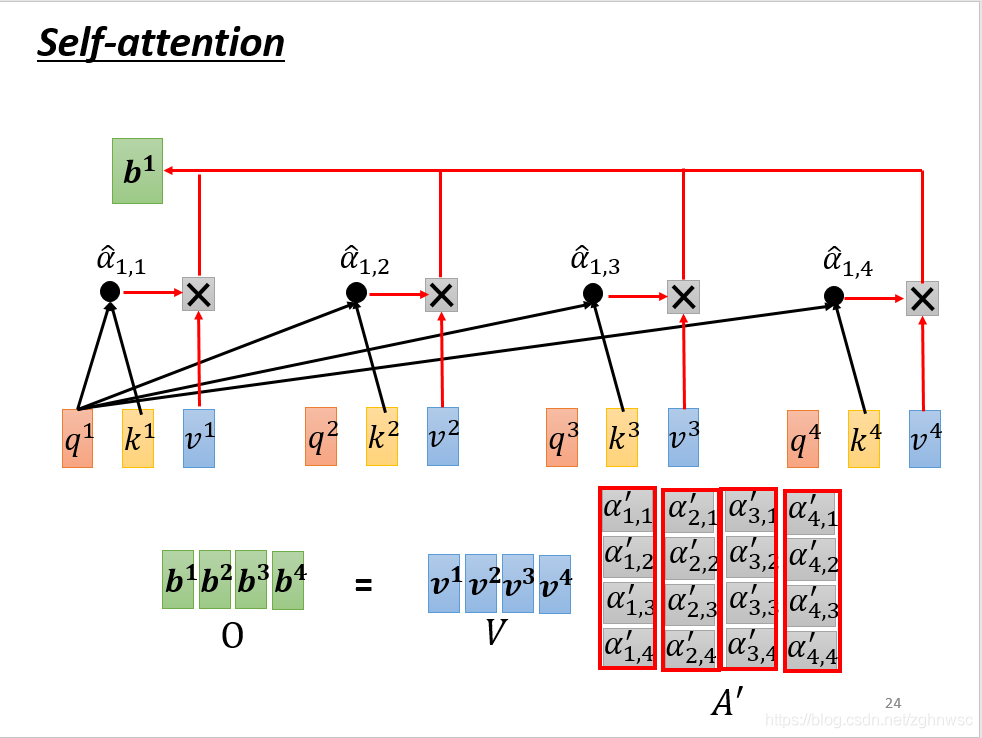
b就是把v拼起来,乘以一个A’,两个矩阵相乘。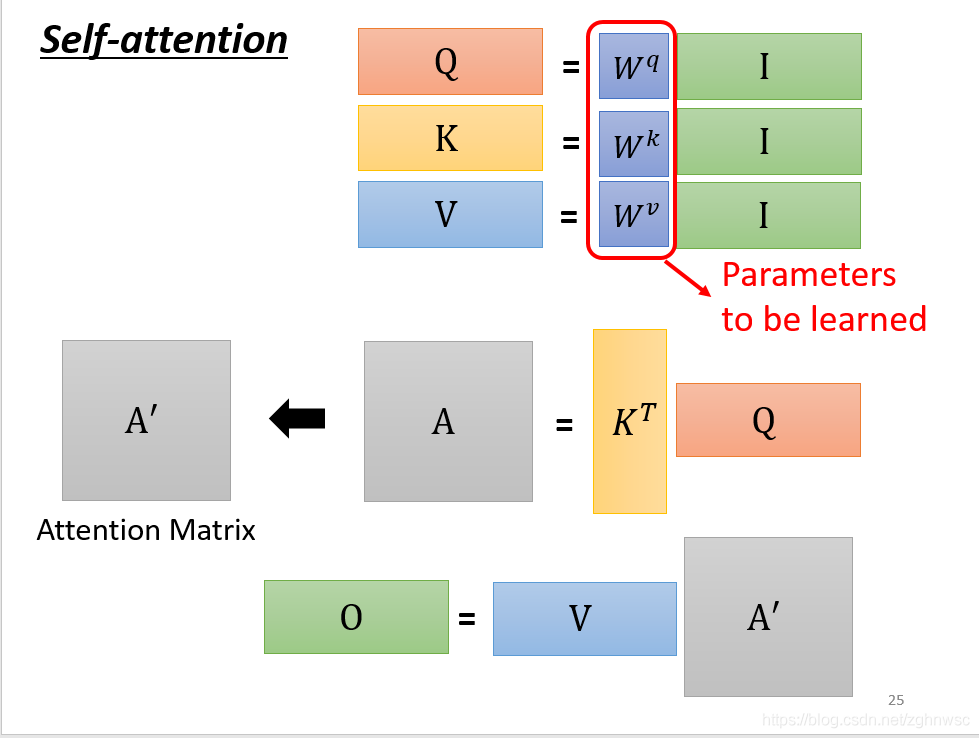
其实这一连串的操作,就是矩阵的乘法。
O就是这层的输出。
这里只有Wq和Wk和Wv是未知的,是需要通过我们的训练资料找出来的。

关于self-attention的理解可以拿这个例子来比喻。一个海王有n个备胎,他需要从n个备胎中选择出最符合自己期望的以便于分配注意力与合理安排时间。
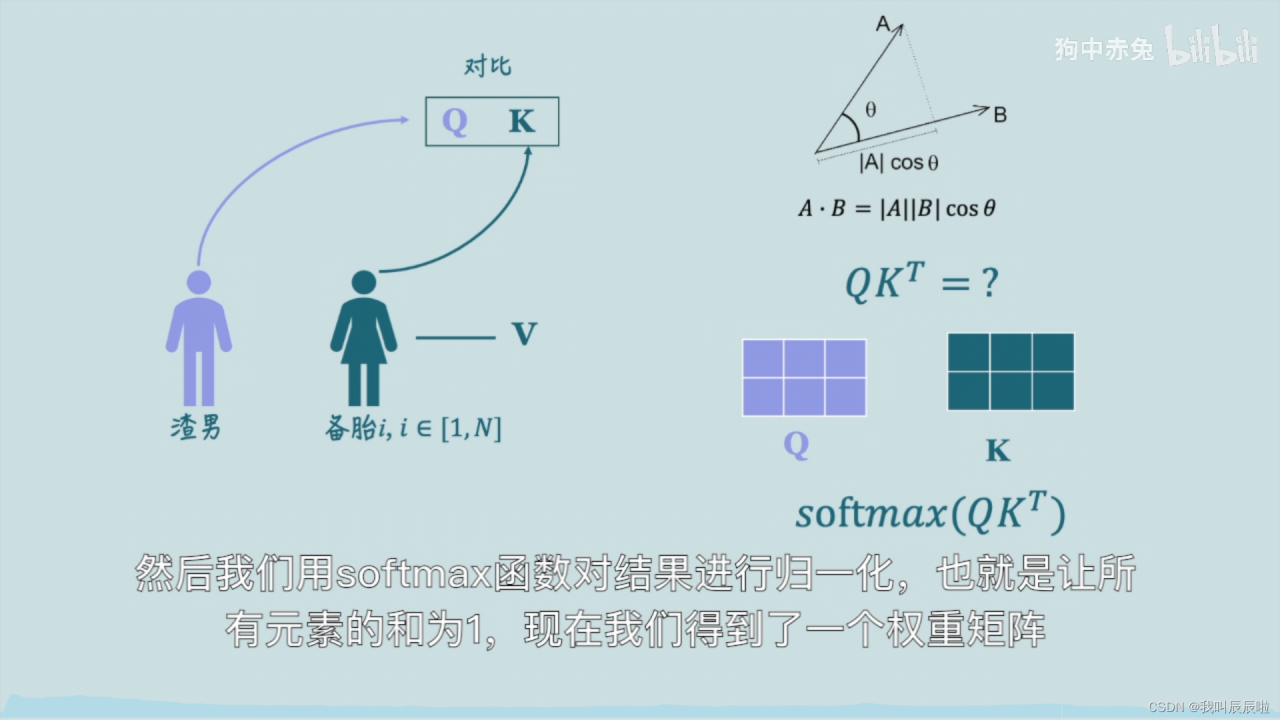
Q为择偶条件,K为自身条件,需要对比Q与K的相关度以得到相似度最高的,所以Q与K点乘结果就反映了两个向量的相似度。

通过softmax函数进行归一化,得到权重
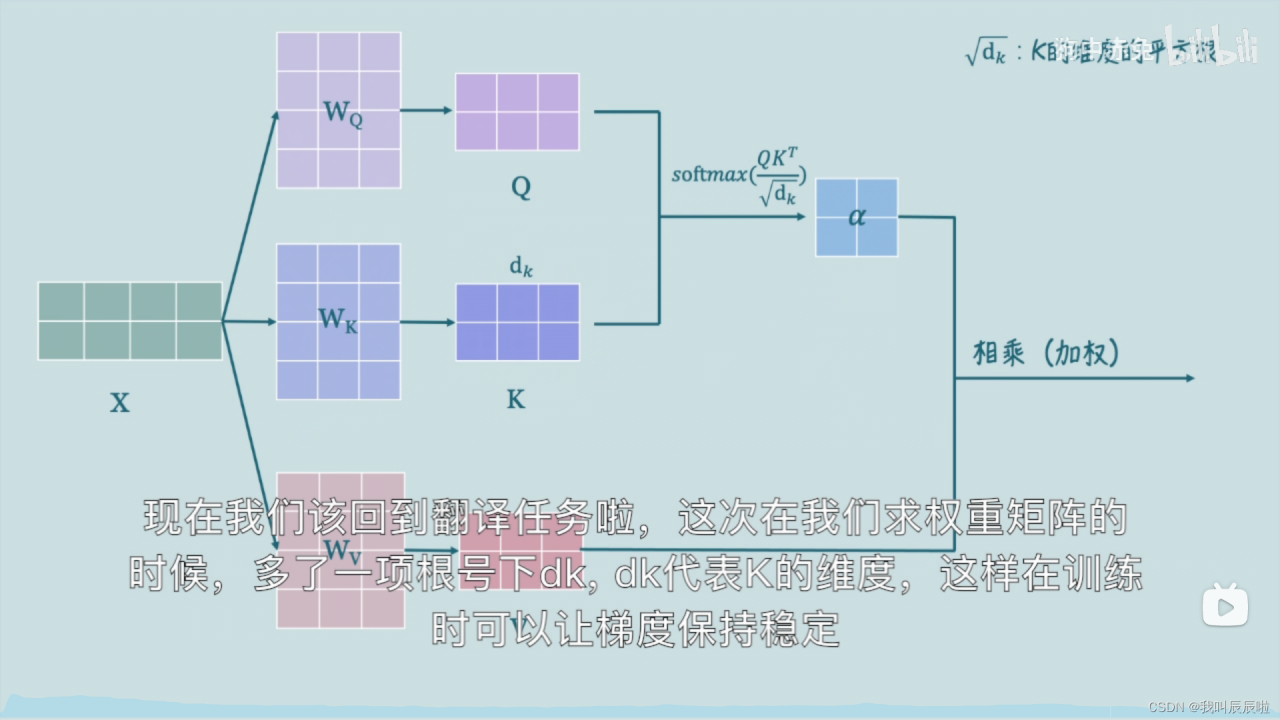
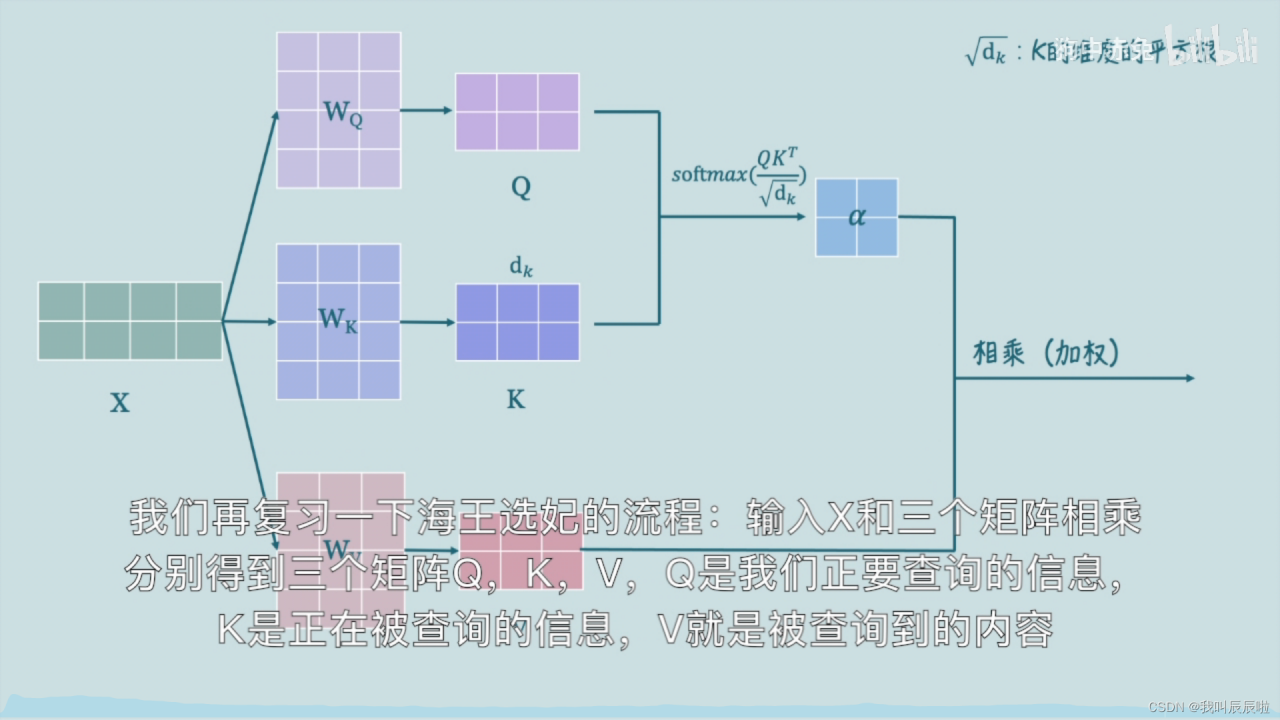
首先Q与K点乘得到Q与K的相似程度,之后通过softmax函数进行归一化得到权重矩阵,最后通过权重矩阵对V进行加权,也就是与它相乘。
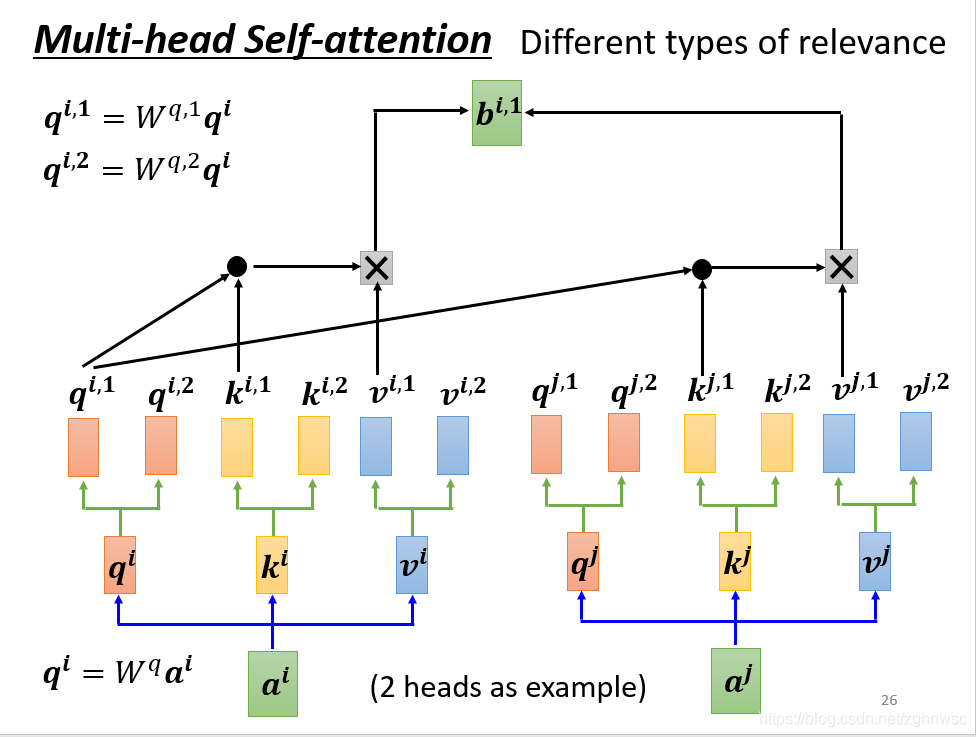
这里有一个进阶的版本,叫做multi-head self-attention
相关,有很多种不同的定义,有很多不同的形式。
我们先得到q再乘以不同的东西,得到两个不同的q,这就是产生了多个“头”。
接下来做self-attention,就是把1这类一起做,把2这类一起做,得到bi,1
然后得到不同的bi1和bi2,再乘以一个矩阵W0,最后得到一个bi。
但是这样的话,每一个input,它的位置的信息是没有的,对于输入而言,每一个操作都是一模一样的。但是在实际上,有一些位置的信息是很重要的,比如动词不容易放在句首。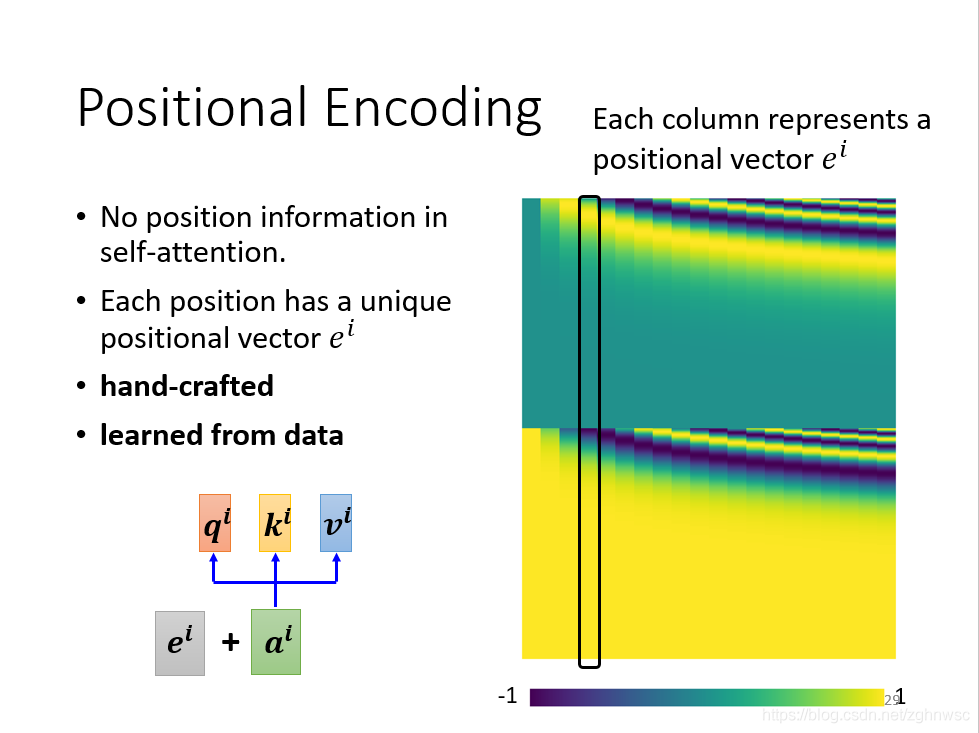
这里用到一个叫做positional encoding的技术:
为每一个位置设定一个向量,叫做位置向量,每一个不同的位置,有一个不同的向量ei,然后把ei加到ai上面。
最早的transformer用的ei,就像涂上,每一个颜色,都代表一个向量,把向量分别在不同的位置相加得到,每一个位置都有一个专属的e。
这样的位置向量,是人为设定的,但是它会产生很多问题。比如我定义向量的时候它的长度只有128,但是sequence有129怎么办呢?
这个位置向量,是一个仍然待研究的问题。有各种各样不同的人为设定的位置向量,还可以让机器根据资料去自己学习出来。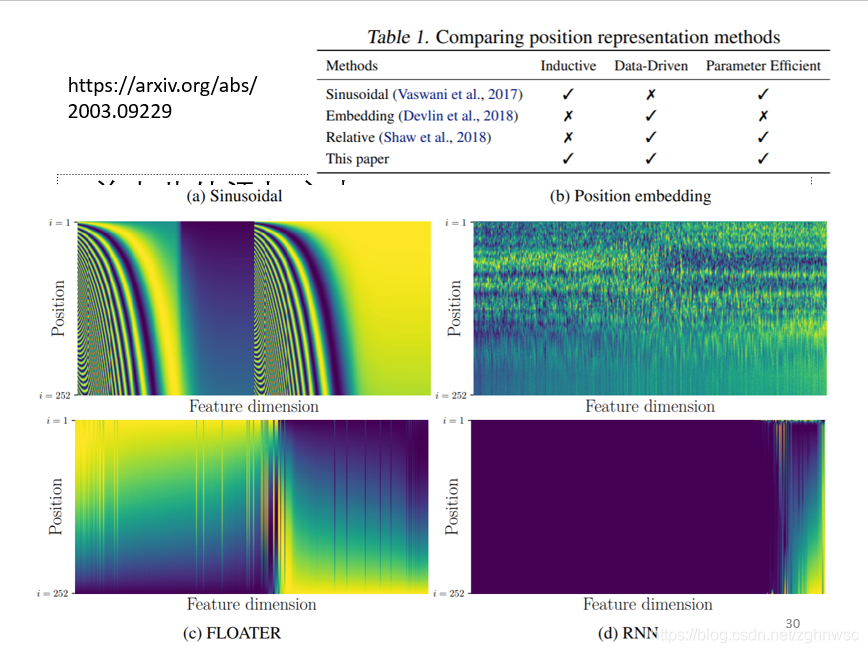
这个图上面就是各种各样不同的位置向量。
下面就是self-attention在不同领域的应用。以图像领域为例: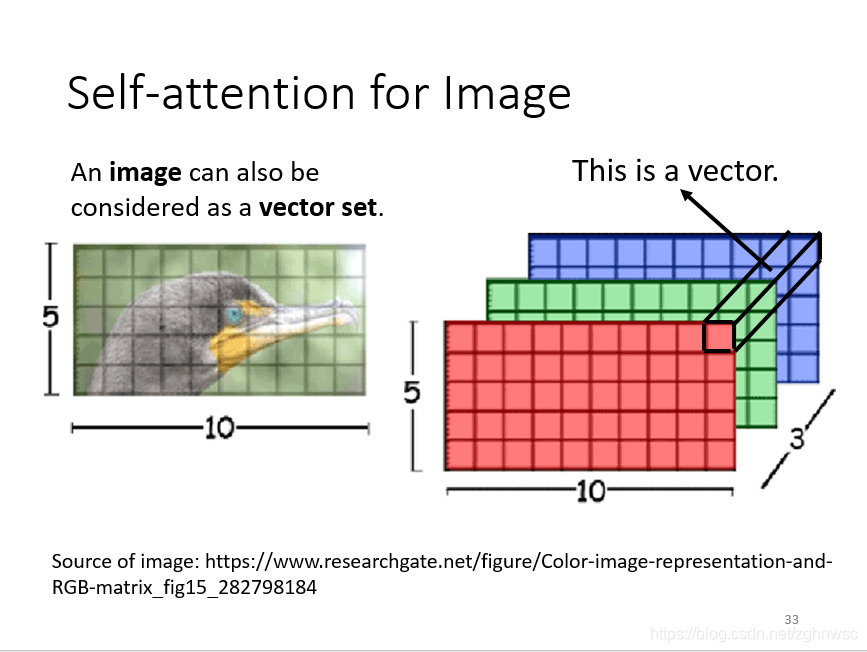
我们之前所讲的,self-attention是在输入一排向量的时候,比较适用。
图像就可以看做是一个向量集合,就是把每一个位置的像素,看成是一个向量,这样的话我们就可以把图片看成一个向量集合。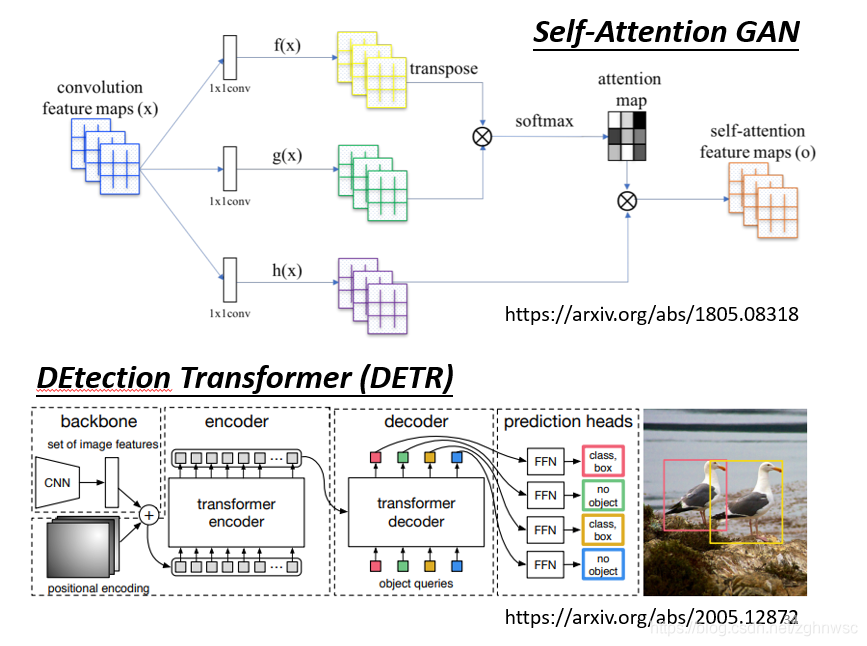
这里有两个把self-attention用在图像处理上的例子。
那么用self-attention和用CNN处理图片有什么区别和联系呢?
如果我们用self-attention来处理图片,其中一个1产生query,用其他的像素产生key,那我们在做内积的时候,是考虑到整张图片的。但是如果我们是用卷积核,filter的话,就是我们只会考虑这里面的一部分信息,那么CNN就相当于是一种简化版的self-attention。
对于CNN来说,我要划定感受野,它的范围的大小,是人为决定的。
对于self-attention来说,它是机器自动学出来的。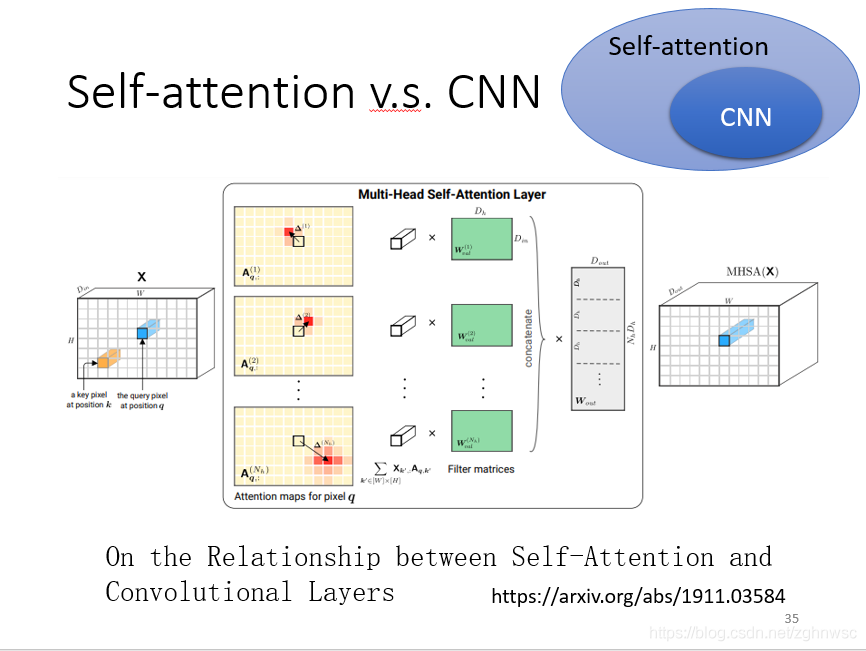
有这么一篇论文,19年1月发的,它会用数学关系严格的证明,CNN就是简化版的self-attention。self-attention只要设定一定的参数,可以做到和CNN一模一样的事情。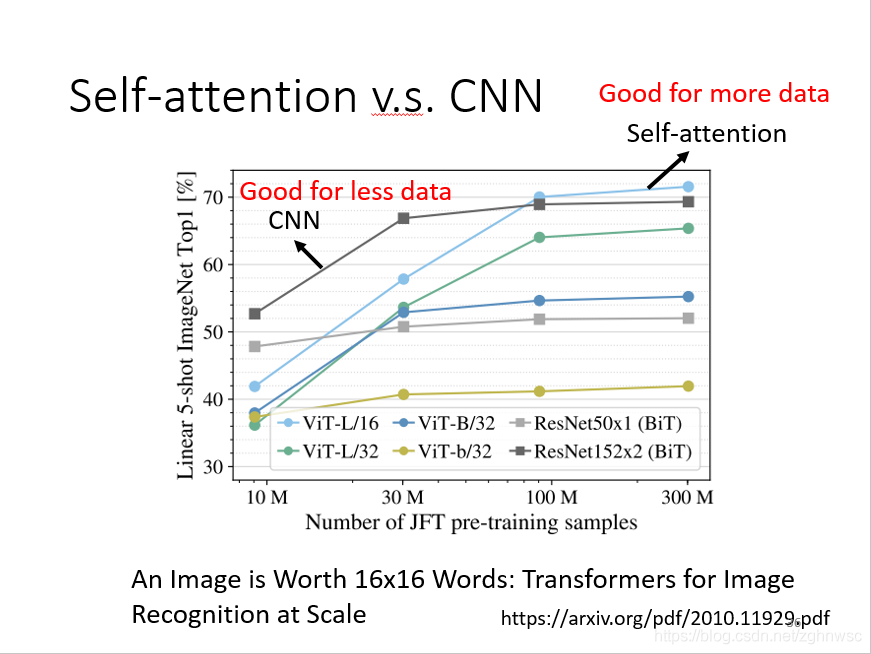
我们在讲overfiting的时候说,比较灵活的模型,它需要更多的数据,如果数据集不够,它效果可能不好。
上面这张图片,就是谷歌发的一篇论文,
把一张图片拆成16x16的patch,然后它就把每一个patch看成是一个word,(因为transformer一开始是用在NLP上面的),取了一个名字,叫做一张图价值16x16个文字。
横轴是训练的图片的量,10M就是一千万,比较了self-attention是浅蓝色这条线,CNN是深灰色这条线。随着资料量越来越多,self-attention的结果越来越好,但是在数据集小的时候,CNN的结果是要比self-attention要好的。
至于RNN,RNN已经基本上被self-attention取代了。
RNN之前博主也看过,就是一个记忆机制,也是,在考虑一个向量的信息的时候 ,加入其它向量的位置信息,可以看成是self-attention的一种特殊情况。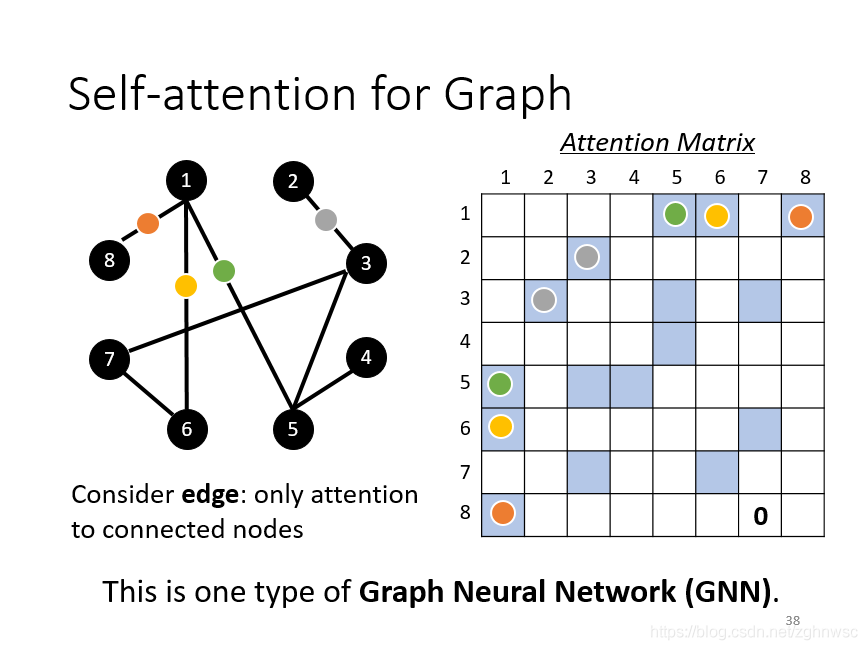
self-attention也可以用在GNN上面,在做attention matrix的时候,只需要计算有edge相连的node就好。
self-attention有非常多的变形。
它的一个问题就是,运算量会非常大(肯定的嘛,CNN就相当于是全连接去掉一些权重,把CNN进行简化),然后它会有各种各样的变形 ,最早的transformer,用的就是这个 ,广义的transformer就是指的self-attention。
我们可以看到,很多新的former,横轴表示比原来的transformer运算速度快 ,但是纵轴表示效果变差。