文章目录
node 爬虫 puppeteer 使用
puppeteer 是一个基于 Chromium 的 node 爬虫框架。其厉害之处就是他具备浏览器的所有功能,并且通过 nodejs 就可以控制。完美实现我们要的爬虫效果 (后面附有完整代码~)
安装 puppeteer 时还会同步下载 Chromium 。网络不好的直接用 cnpm 下载即可。
当然官方也有一个另外的包,原话如下:
Since version 1.7.0 we publish the puppeteer-core package, a version of Puppeteer that doesn't download any browser by default.
意思大概就是使用 puppeteer-core 就可以使用 puppeteer 核心功能,而不用安装完整的浏览器。这次我还没用上,下次用上了在细说~
记录一个实战 demo
一个 node 命令行的小工具,原理是从 https://ping.chinaz.com/ 网站获取对应的网址的 IP 信息和请求时长,然后在从本地 Ping 对应的 IP,找到网址的最佳节点
运行效果: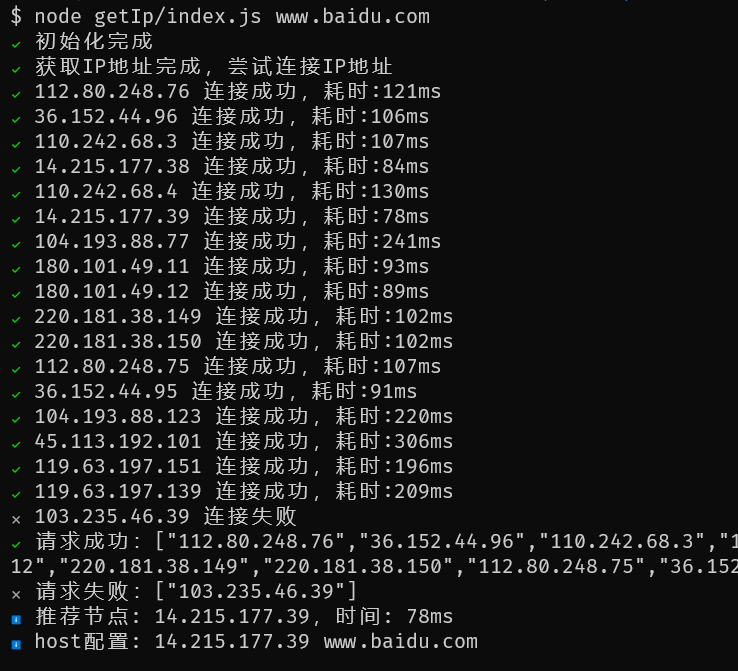
PS: 为啥不直接用这个网站查,还得自己写一次?因为网站查出来的 IP 显示是可以的,可是本地 ping 不一定通,总不能一个个尝试把,所以这个工具就诞生了~
至于为什么要用到 puppeteer ?是因为这个网站没对外提供 api,所以只能从请求的界面上,获取我们要用的信息
开发先看文档
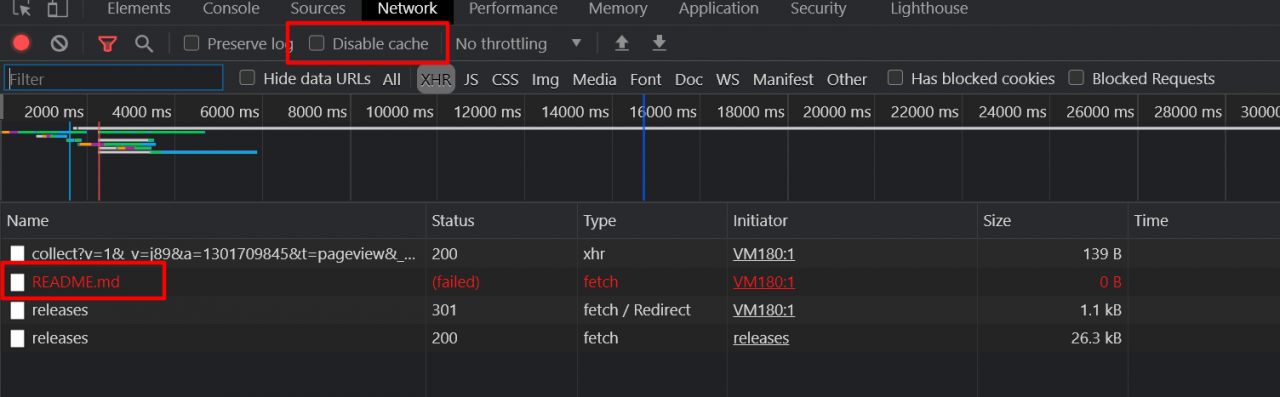
如果第一次打不开呢,就把 185.199.110.133 raw.githubusercontent.com 加到 host 文件去,因为文档是从 github 加载的。而且把 netword 面板的 禁用缓存 去掉。
启动浏览器
官网的入门 demo
const puppeteer = require('puppeteer')
;(async () => {
// 创建一个浏览器对象
const browser = await puppeteer.launch()
// 打开一个新的页面
const page = await browser.newPage()
// 设置页面的URL
await page.goto('https://www.google.com')
// other actions...
// 最后关闭浏览器(如果不关闭,node程序也不会结束的)
await browser.close()
})()
puppeteer.launch
先看启动的文档把~ launch 文档
关于 launch 我只用到了一个参数, headless 是否不显示浏览器界面
一开始的调试模式,我还是选择了打开浏览器界面
const browser = await puppeteer.launch({
headless: false // 是否 不显示浏览器界面
})
page.goto
await page.goto('https://ping.chinaz.com/www.baidu.com', {
timeout: 0, // 不限制超时时间
waitUntil: 'networkidle0'
})
page 就是当前的 tab 标签页了。page.goto 文档
打开界面后,https://ping.chinaz.com/ 如果后面有网址的话,会自动开始请求,所以我要做的就是,等他们完全请求完成,我才开始获取内容
goto 提供了几个选项,一个是等待多少 s 后,页面没加载完,就算 GG 了。除非设置 -1 就会一直等下去
第二个就是 waitUntil 我用的是networkidle0。就是 500 毫秒内没有任何请求了,就会继续往下执行

获取页面上的元素
平时我们都会在控制台用 $ 运算符,进行查询。puppeteer 也提供了类似的功能,而且分的更加细了。
可以看到上面有 page.$ 和 page.$$ 很多 api 都会有 $ 和 $$ 区别。其实都是同一个意思,用 $ 的话只会查询匹配的第一个元素,而用 $$ 类的 api,会帮你把对应元素都查出来,变成一个数组元素
page.$$(selector) 和 page.$$eval(selector, pageFunction[, ...args]) 也很类似,都是查询元素
不过 page.$$ 是查询到了所有匹配的节点,然后给你提供对应的方法,比如你可以查到那些节点后在执行 page.$eval
page.$$eval 则是最贴近我们的查询对应节点,然后后面的回调函数可以操作 node 节点
所以,我用了 page.$$eval 查询表格中的所有的数据,在回调函数中再去操作每一项的 innerText。
let list = await page.$$eval('#speedlist .listw', options =>
options.map(option => {
let [city, ip, ipaddress, responsetime, ttl] = option.innerText.split(/[\n]/g)
return { city, ip, ipaddress, responsetime, ttl }
})
)
剩下就是业务逻辑的问题了
实现 ping 方法
ping 方法的实现特别的简单粗暴,就是引入 npm - ping
ping.sys.probe(IP地址,回调函数)
所以下面基于这个异步方法封装了一下,传入 IP,计算本机具体 ping 的时间。并且用 Promise 封装一下,方便我们使用 async 和 await
const pingIp = ip =>
new Promise((resolve, reject) => {
let startTime = new Date().getTime()
ping.sys.probe(ip, function(isAlive) {
if (isAlive) {
resolve({
ip: ip,
time: new Date().getTime() - startTime
})
} else {
reject({
ip: ip,
time: -1
})
}
})
})
await 锦上添花
如果我们的 Promise 返回的是 reject 。通常来说我们只能用 try/catch 去处理。这可不太优雅,可以参考以前的文章 [http://jioho.gitee.io/blog/JavaScript/%E5%A6%82%E4%BD%95%E4%BC%98%E9%9B%85%E5%A4%84%E7%90%86async%E6%8A%9B%E5%87%BA%E7%9A%84%E9%94%99%E8%AF%AF.html)
const awaitWrap = promise => {
return promise.then(data => [data, null]).catch(err => [null, err])
}
项目中的 loading 效果
由于整套过程下来比较漫长,需要等待时间比较多,所以有一个好的 loading 提示非常重要。于是使用 npm - ora
在各个地方加上 loading 和对应的提示
完整的项目代码
依赖项:
| npm 包名 | 作用 |
|---|---|
| ora | 友好的 loading 效果 |
| puppeteer | 爬虫框架 |
| ping | node 进行 ping 的方法 |
index.js
const ora = require('ora')
let inputUrl = process.argv[2]
if (!inputUrl) {
ora().warn('请输入需要判断的链接')
process.exit()
}
const puppeteer = require('puppeteer')
const { awaitWrap, pingIp, moveHttp } = require('./utils')
let url = moveHttp(inputUrl)
const BaiseUrl = 'https://ping.chinaz.com/'
;(async () => {
const init = ora('初始化浏览器环境').start()
const browser = await puppeteer.launch({
headless: true // 是否不显示浏览器界面
})
init.succeed('初始化完成')
const loading = ora(`正在解析 ${url}`).start()
const page = await browser.newPage() // 创建一个新页面
await page.goto(BaiseUrl + url, {
timeout: 0, // 不限制超时时间
waitUntil: 'networkidle0'
})
loading.stop()
let list = await page.$$eval('#speedlist .listw', options =>
options.map(option => {
let [city, ip, ipaddress, responsetime, ttl] = option.innerText.split(/[\n]/g)
return { city, ip, ipaddress, responsetime, ttl }
})
)
if (list.length == 0) {
ora().fail('请输入正确的网址或IP')
process.exit()
}
ora().succeed('获取IP地址完成,尝试连接IP地址')
let ipObj = {}
let success = []
let failList = []
let fast = Infinity
let fastIp = ''
for (let i = 0; i < list.length; i++) {
let item = list[i]
let time = parseInt(item.responsetime)
if (!isNaN(time) && !ipObj[item.ip]) {
const tryIp = ora(`尝试 ${item.ip}`).start()
let [res, error] = await awaitWrap(pingIp(item.ip))
if (!error) {
success.push(res.ip)
if (res.time < fast) {
fast = res.time
fastIp = res.ip
}
tryIp.succeed(`${res.ip} 连接成功,耗时:${res.time}ms`)
} else {
failList.push(error.ip)
tryIp.fail(`${error.ip} 连接失败`)
}
ipObj[item.ip] = time
}
}
if (success.length > 0) {
ora().succeed(`请求成功:${JSON.stringify(success)}`)
}
if (failList.length > 0) {
ora().fail(`请求失败:${JSON.stringify(failList)}`)
}
if (fastIp) {
ora().info(`推荐节点: ${fastIp},时间: ${fast}ms`)
ora().info(`host配置: ${fastIp} ${url}`)
}
browser.close() // 关闭浏览器
})()
utils/index.js
var ping = require('ping')
module.exports = {
awaitWrap: promise => {
return promise.then(data => [data, null]).catch(err => [null, err])
},
pingIp: ip =>
new Promise((resolve, reject) => {
let startTime = new Date().getTime()
ping.sys.probe(ip, function(isAlive) {
if (isAlive) {
resolve({
ip: ip,
time: new Date().getTime() - startTime
})
} else {
reject({
ip: ip,
time: -1
})
}
})
}),
moveHttp: val => {
val = val.replace(/http(s)?:\/\//i, '')
var temp = val.split('/')
if (temp.length <= 2) {
if (val[val.length - 1] == '/') {
val = val.substring(0, val.length - 1)
}
}
return val
}
}
总结
整个项目下来,最主要的就是打开浏览器,和学会看文档中的各个事件,这里展示的只是浏览器的网络请求的等待,还有很多其他的方法
- 比如等到某个节点出现的回调
- 拦截请求
- 等待某个请求结束后回调
- 屏幕截图
- 网站性能分析
- 等…
总的来说 puppeteer 的出现让 node 出现了更多的可能。希望 node 生态可以越来越好~
当然,调试 node 程序,尤其是有那么多节点和原型链方法的东西,仅仅用终端调试显然不够,所以想更好的调试你们的 node 脚本,可以看下 调试 node 程序工具对比
最后附上请求文档URL的IP情况(getIp是我的文件夹,index.js 就是上面代码的 index.js 代码了~)


完 ~