一、kettle主要功能
接触kettle很长时间了,现在已经改名为Pentaho Data Integration,就是数据整合的意思和原来的水壶很相像,数据从壶口装入,壶嘴统一输出。
kettle的功能很多,我当时用的最多的就是跨数据库同步数据的功能,举例,把mysql数据库中的商品信息导入到orcle,因为涉及到跨数据库,手动实现太复杂了,kettle就体现了价值。
最常见功能之一就是更新、插入的功能,如果数据发生了变化或新增,那么就可以将关联对应的字段,将有变化的记录进行更新,插入新增的记录。
二、简述
1.kettle过程描述
整个的数据过程,就是把数据从一个地方搬运到另外一个地方,中途可能需要对数据做一些简单的加工,这是我对这个抽象过程的描述。
比如热水和茶叶一起放到一个茶壶中,经过浸泡,最后输出到一个茶碗中,这就是一个‘转化’的过程。
还有就是将暖壶中的热水,倒进茶壶中,然后再把茶壶中的水倒出到一个碗里面。听起来好像有点鸡肋,其实这就是跨数据库同步数据的过程,因为暖壶的水无法直接倒进茶碗中,因为数据格式等等都是不一样的。
2.输入控件
kettle重要是通过在控件中进行数据的抽取、转化和加载。
输入控件可以简单理解为数据的来源,也就是数据提供方(处),也就是类似于暖壶。
3.输出控件
输出控件类似于茶碗,从茶壶中承接倒出来的内容。
4.kettle
kettle就是中间的茶壶,处理暖壶等来源带来的数据内容。
三、表输入-表输出
这里我用oracle举例,将newjs表中的数据导出到一个新表newjstlt20,大家可以把这一步当成从业务数据层把数据抽到ODS层,基本上就是按照业务数据直接抽取过来。
1.建表
我是在plsql里面建的数据表,这就是将要作为输入的表
create table t_csdn_01(
id number(10)
, name varchar2(50)
, age number
);
2.造数据
这里写一个存储过程,插入40条数据。存储过程的写法,大家参考平台的其他入门文章即可。
--向t_csdn_01中插入数据
create or replace procedure sp_csdn_01(p_id in number) --总id数量
is
v_name varchar2(40); --接收姓名
v_age number(10); --接收年龄
begin
for m in 1..p_id loop --循环插入即可
v_name := dbms_random.string('U', 3); --随机函数造v_name
v_age := dbms_random.value * 10 + m; --随机函数v_age
insert into t_csdn_01(id, name, age)
values(m, v_name, v_age);
--这里没有用动态sql
end loop;
commit;
dbms_output.put_line('sp_csdn_01 insert into finished');
end;
设置一个接收变量,直接执行即可,我插入了40条数据。
declare
v_id number := &id;
begin
sp_csdn_01(v_id);
dbms_output.put_line('block finished');
end;
3.表输出
现在暖壶和茶壶都有了,我现在要把数据转到另外一个表中。可以在数据库中新建一个表,虽然kettle也可以在过程中建表。
--创建输出表
create table t_csdn_02
as
select id
, name
, age
from t_csdn_01
where 1 = 2;
四、新建转化
基础的安装大家参考其他的文章即可,包括需要对应下载的驱动。
首先打开spoon.bat,在文件菜单栏新建一个转换,我们将orcle中的表数据输出到excel中。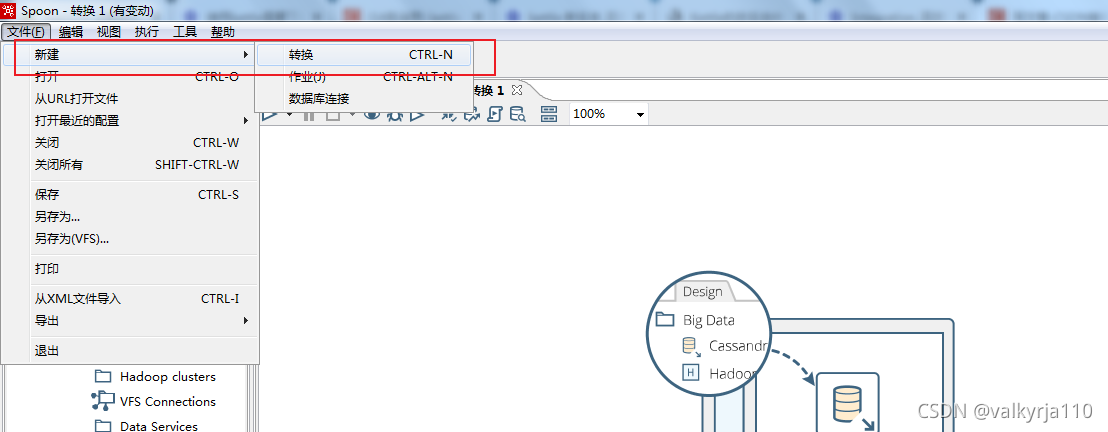
从核心对象中的输入、出入将表输入和表输出拖拽到右侧,按住shift链接2个控件。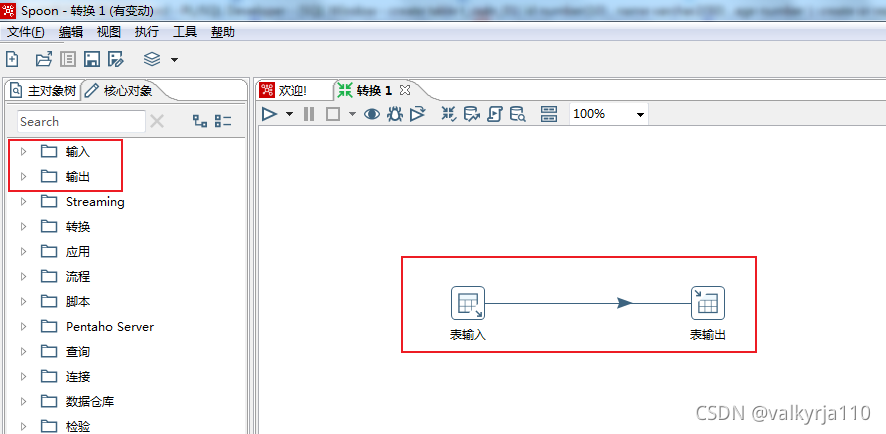
这里需要连接数据库,连接名称,主机名ip地址,数据库名称,端口号默认1521,用户名和登录密码。先测试数据库的连接,看看是否成功。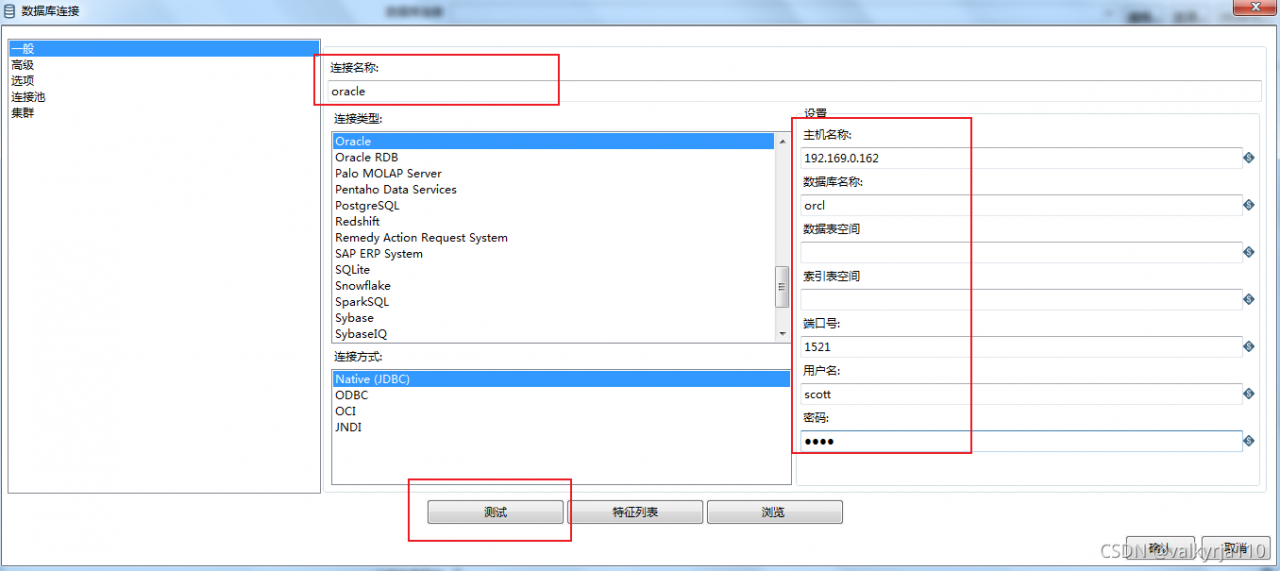
这里写查询,需要的对应字段和数据,注意结尾无分号,然后确定。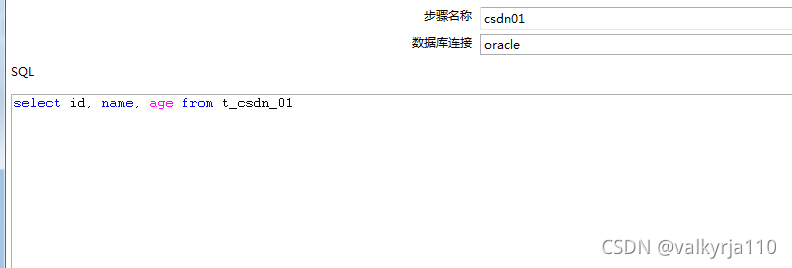
这里是设置目标表的内容,同样需要连接数据库,对应的表名,需要勾选指定数据库字段,使用批量插入。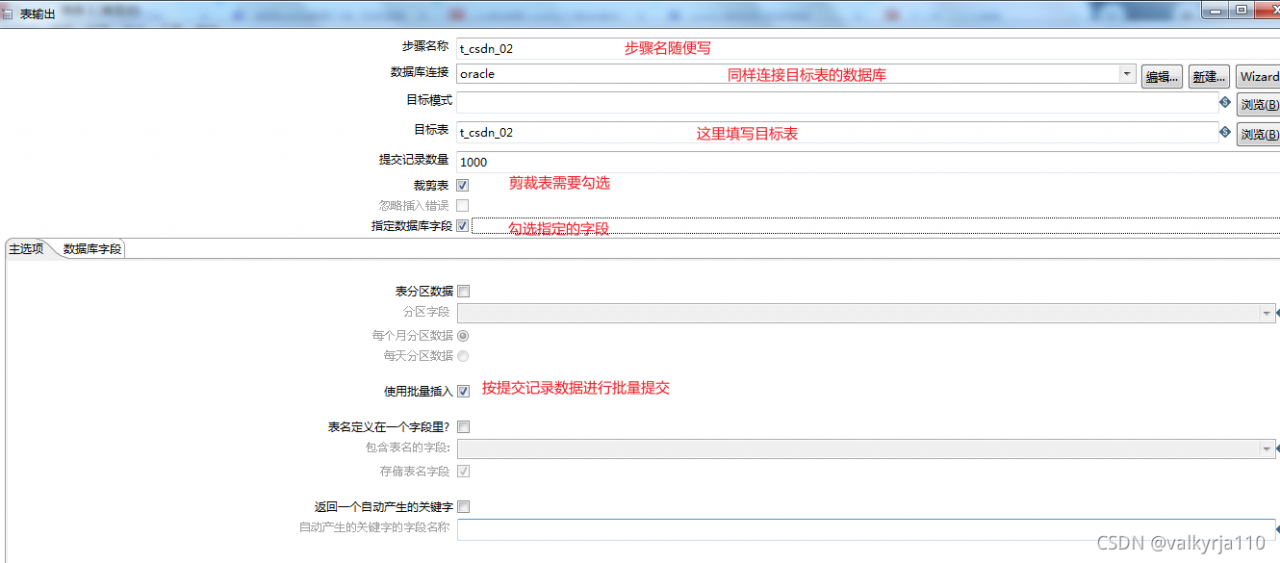
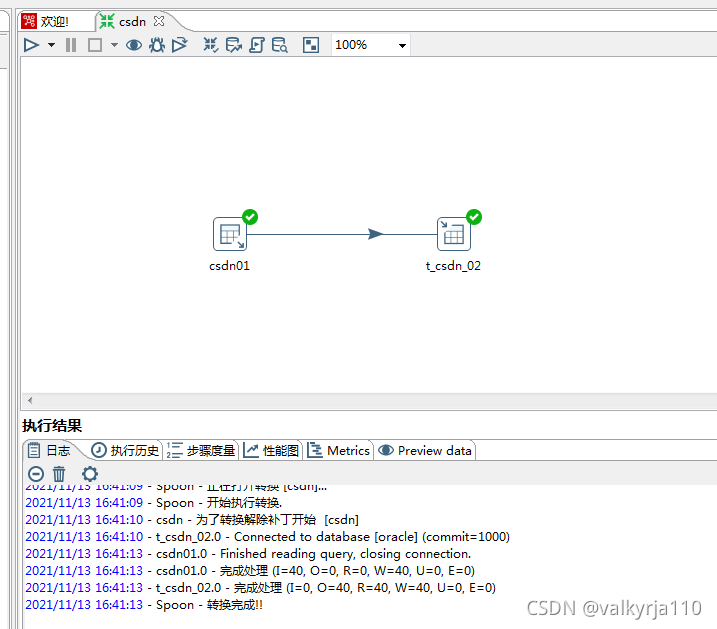
在数据字段中获取字段,就是表字段和流字段的对应情况。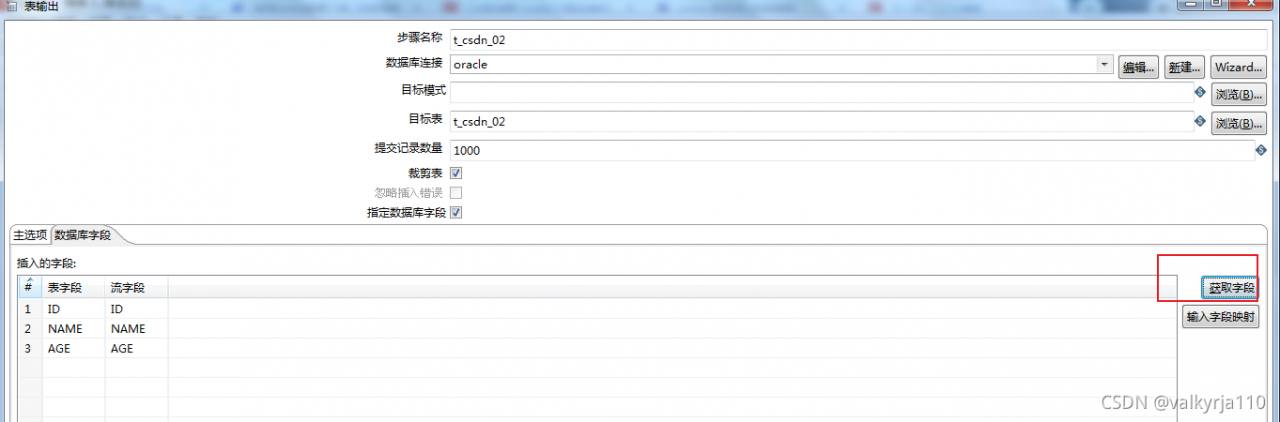 点击进行运行,需要进行保存。
点击进行运行,需要进行保存。
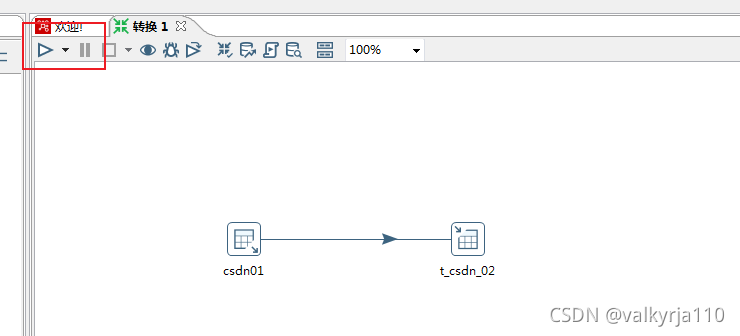
控件出现绿箭头,就表示过程没有问题,最后就完成了数据转化。