博主前面系列博客用到的tensorflow, keras,caffe,pytorch都是国外的,国内也有优秀的深度学习框架,这就是paddlepaddle.
身边有朋友在配置PaddleOCR时碰到了点问题,我也整了下,关于其介绍可以参考官网

一.Win10下配置:
环境:
opencv-4.2.0(参考博主较久博客配置)
VS2019
Cmake 3.22.0
博主的opencv直接安装在D盘根目录下

1.下载官方示例源码(注意这个不是用来编译获得paddleocr推断库来用的,可以认为只是一个调用paddleocr推断库的示例),博主这里选择的2.0分支版本下载的。
README.md · release/2.3 · PaddlePaddle / PaddleOCR · GitCode
博主存放的路径如下
D:\PaddleOCR-release-2.0\deploy\cpp_infer文件夹下新建一个build,下面开始cmake
2.选择好cmake的源文件和目标文件

点击左下角的Configure按钮,出来的界面上,如下配置
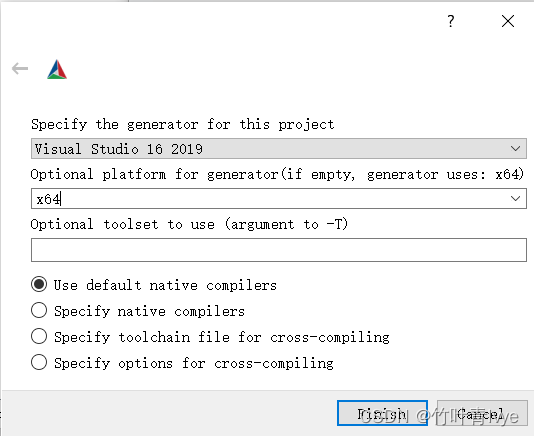
在出来界面上,按照如下配置
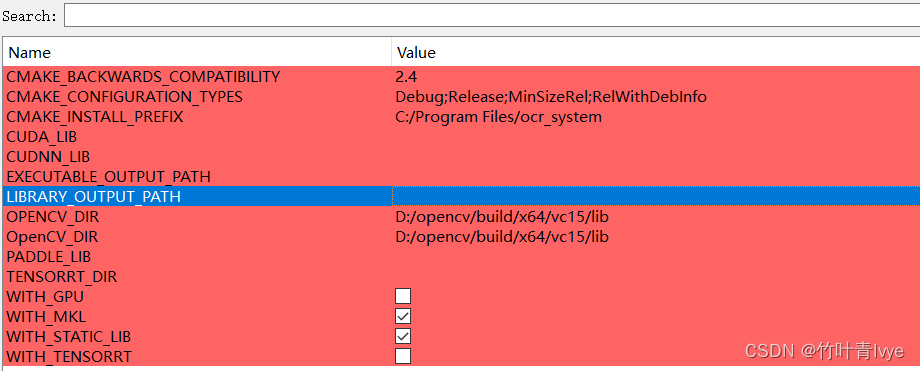
因为博主win10环境下没有安装cuda和cuddn, 所以这边WITH_GPU没有勾选。别忘了给下opencv的的lib路径,结合自己的路径,如上选择完毕后,再次点击configure。然后再点击Generate。没有出现报错后。
3. 点击Open Project按钮,下面需要配置下需要的include和lib路径
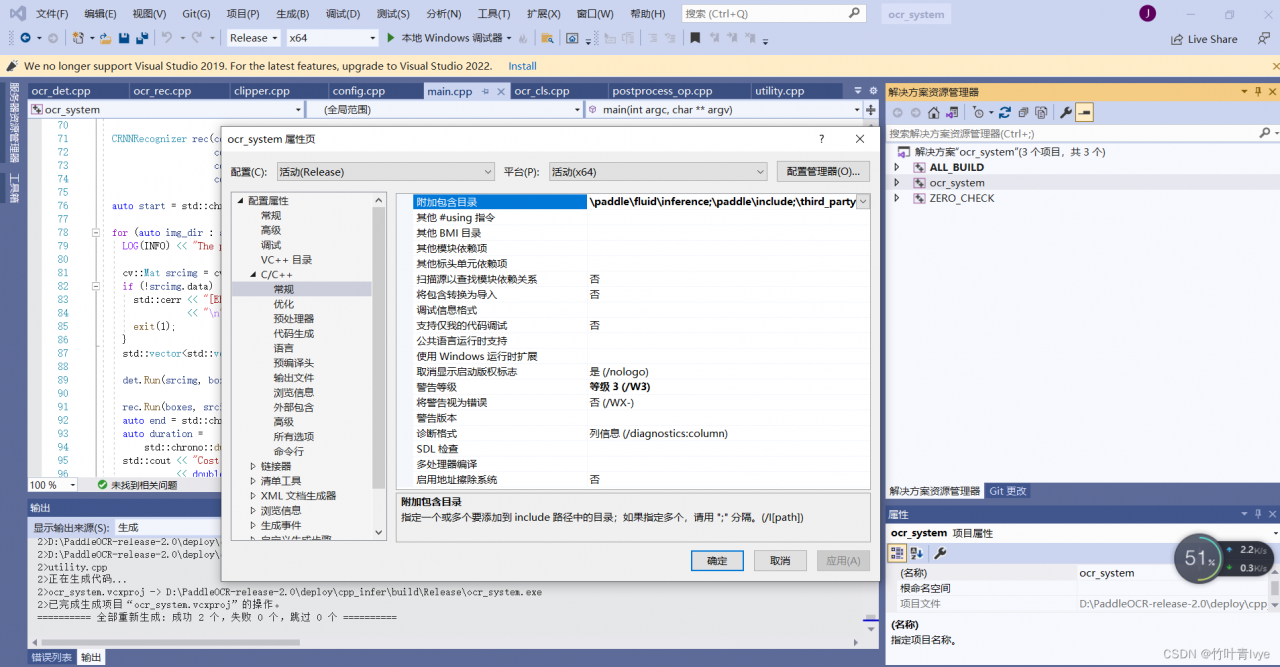
所以这里需要下载下paddleOCR进行推断(预测)所需要的头文件和lib库,这边才是paddleocr的库,官网上已经有编译好的,我们直接用就行,如下链接上可进行下载。
安装与编译 Windows 预测库-使用文档-PaddlePaddle深度学习平台
注意下图左上角,对应的选择的也是2.0版本,然后下载下图红线标记的版本
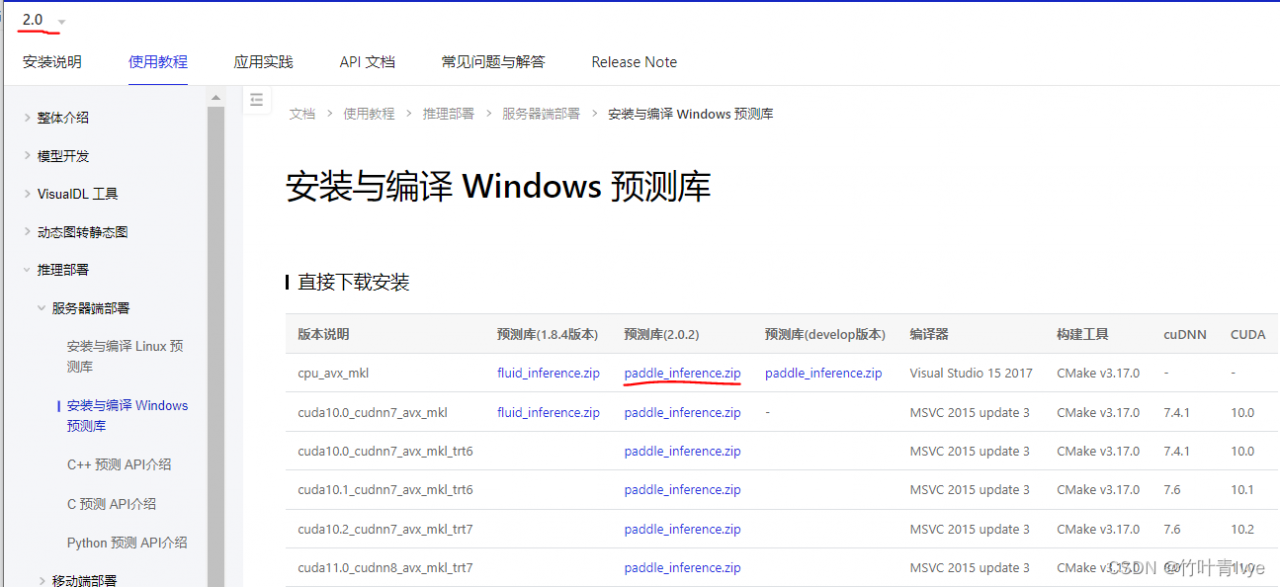
下载完毕后,paddle_inference文件夹在博主电脑上所存放的路径

ocr_system项目C/C++所附加包含目录设置为(结合自己的路径)
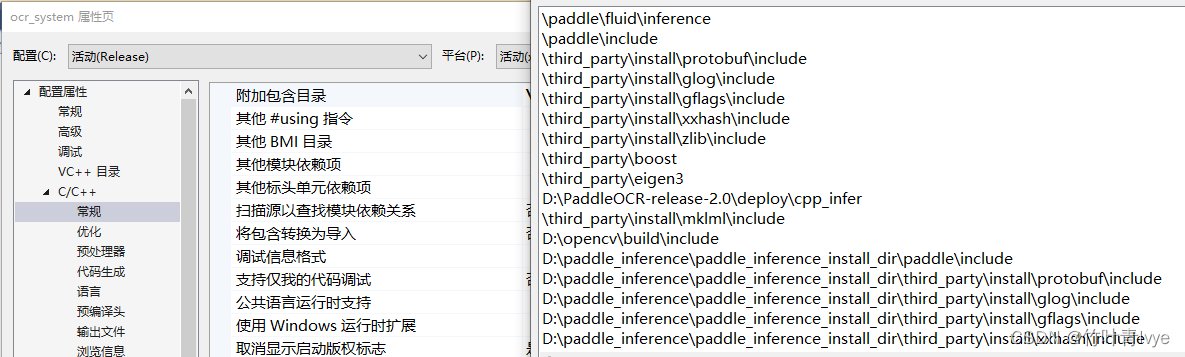
ocr_system项目连接器输入附加依赖库设置为(结合自己的路径)
D:\paddle_inference\paddle_inference_install_dir\paddle\lib\paddle_inference.lib
D:\paddle_inference\paddle_inference_install_dir\third_party\install\mklml\lib\mklml.lib
D:\paddle_inference\paddle_inference_install_dir\third_party\install\mklml\lib\libiomp5md.lib
D:\paddle_inference\paddle_inference_install_dir\third_party\install\glog\lib\glog.lib
D:\paddle_inference\paddle_inference_install_dir\third_party\install\gflags\lib\gflags_static.lib
D:\paddle_inference\paddle_inference_install_dir\third_party\install\protobuf\lib\libprotobuf.lib
D:\paddle_inference\paddle_inference_install_dir\third_party\install\xxhash\lib\xxhash.lib
libcmt.lib
shlwapi.lib
D:\opencv\build\x64\vc15\lib\opencv_world420.lib
kernel32.lib
user32.lib
gdi32.lib
winspool.lib
shell32.lib
ole32.lib
oleaut32.lib
uuid.lib
comdlg32.lib
advapi32.lib然后编译ALL_BUILD,出现报错:
严重性 代码 说明 项目 文件 行 禁止显示状态
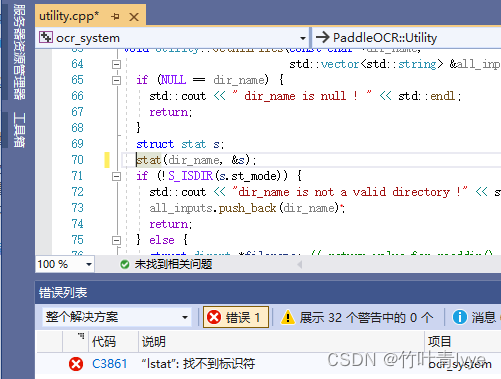
错误 C1083 无法打开包括文件: “dirent.h”: No such file or directory ocr_system D:\PaddleOCR-release-2.0\deploy\cpp_infer\src\utility.cpp 15
要解决此问题,需要去mirrors / tronkko / dirent · GitCode下载下dirent
下载完毕后在电脑上的位置如下
ocr_system项目C/C++所附加包含目录中再添加一条如下路径
![]()
继续编译又出现“lstat":找不到标识符错误,只要找到对应行,将lstat改成stat即可,如下已经改成了stat
继续编译又出现表达式的计算结果不是常数

找到报错处,将那边代码改为如下:
char* strs = new char[str.length() + 1];
//char strs[str.length() + 1];
std::strcpy(strs, str.c_str());
char* d = new char[delim.length() + 1];
//char d[delim.length() + 1];
std::strcpy(d, delim.c_str());注释掉的语句,是原来文件里的代码,这边换了一种写法,修改完毕后,编译成功
生成的文件可在如下目录找到
4.接下来通过命令行方式运行生成的ocr_system.exe去预测一张图片,这里就需要下载推理模型。

这三份文件博主放在了D:\model文件夹下,并进行解压
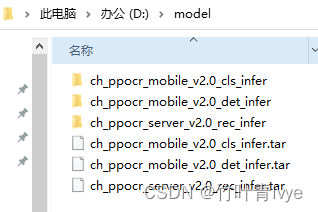

因为这里是通过命令行方式预测的,配置都是通过D:\PaddleOCR-release-2.0\deploy\cpp_infer\tools下的config.txt(结合自己的路径)文件来配置, config.txt,博主修改为如下:
# model load config
use_gpu 0
gpu_id 0
gpu_mem 4000
cpu_math_library_num_threads 10
use_mkldnn 0
# det config
max_side_len 960
det_db_thresh 0.3
det_db_box_thresh 0.5
det_db_unclip_ratio 1.6
use_polygon_score 1
det_model_dir D:\model\ch_ppocr_mobile_v2.0_det_infer
# cls config
use_angle_cls 0
cls_model_dir D:\model\ch_ppocr_mobile_v2.0_cls_infer
cls_thresh 0.9
# rec config
rec_model_dir D:\model\ch_ppocr_server_v2.0_rec_infer
char_list_file D:\PaddleOCR-release-2.0\ppocr\utils\ppocr_keys_v1.txt
# show the detection results
visualize 1
# use_tensorrt
use_tensorrt 0
use_fp16 0
博主的图片如下:

终端cd到ocr_system.exe目录下,执行如下命令
ocr_system.exe D:\PaddleOCR-release-2.0\deploy\cpp_infer\tools\config.txt D:\2.bmp
可看到图片中的关键字符都被读出来了

预测结果图片如下(效果还是不错的):

二.Ubuntu下配置:
此时博主的环境配置和在写博客时保持一致
cuda version: 11.2
cudnn version: cudnn-11.2-linux-x64-v8.1.1.33
python3.8
主要按照官网来快速配置下,预测上面同样的图
文件 · release/2.3 · PaddlePaddle / PaddleOCR · GitCode
根据tutrials中红框内步骤操作就行,其它的可以后续再去了解,这过程和step-by-step通过学习tensorflow,keras,pytorch等一样,先从一个简单的示例入手,再去深入了解,这首学习东西的一个方法,一定要多看官网。

1.博主这边已经是ananconda下的环境,此前系列博主的博客都是此环境,可以追溯到此篇帖子了此篇帖子了,里面创建一个python3.8的虚拟环境,(如何创立可见之前博客,可以看到此前系列博客,博主在验证一些东西的时候,都是在一个个单独虚拟环境下进行了,防止环境库版本冲突,这是一个很好的习惯)。点击如下链接
飞桨PaddlePaddle-源于产业实践的开源深度学习平台
结合自己的环境选择相应的版本
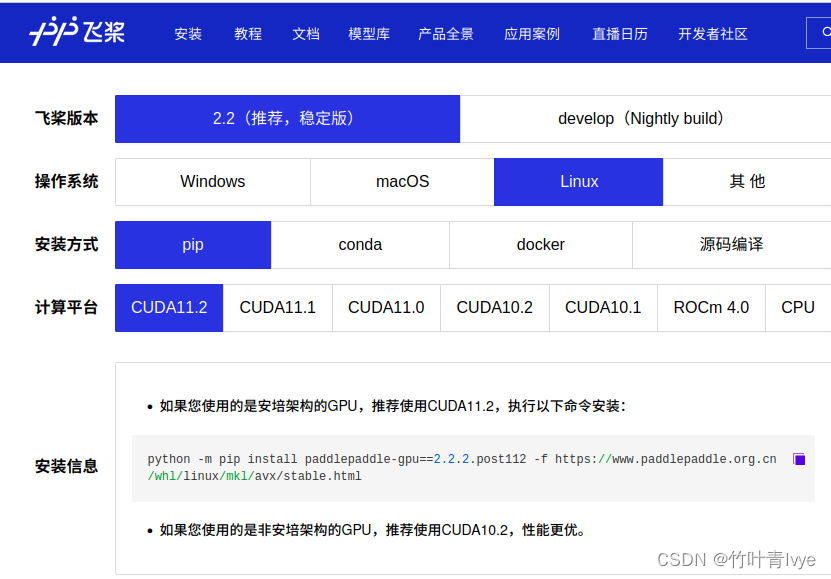
执行安装信息里的语句,安装paddlepaddle(gpu版本)
python -m pip install paddlepaddle-gpu==2.2.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html完毕后再安装下 paddleocr
pip install "paddleocr>=2.0.1" 完毕后就可以开始测试了,这边下载下官方的图片示例。
doc/doc_en/quickstart_en.md · release/2.3 · PaddlePaddle / PaddleOCR · GitCode
打开的界面上点击here按钮即可以下载

博主直接把此文件夹放在了Home目录下,对文件夹中的1.jpg进行预测

如下命令行语句即可以完成预测(cd到对应目录下,结合自己的路径)
paddleocr --image_dir ./imgs/1.jpg --use_angle_cls true --lang ch --use_gpu true
预测结果如下,关键字都被预测出来了。

2.上面的命令行方式也可以改成code方式,这边打开下pycharm,代码如下:
import paddle as p
from paddleocr import PaddleOCR,draw_ocr
# Paddleocr supports Chinese, English, French, German, Korean and Japanese.
# You can set the parameter `lang` as `ch`, `en`, `fr`, `german`, `korean`, `japan`
# to switch the language model in order.
print(p.__version__)
ocr = PaddleOCR(use_angle_cls=True, lang='ch',use_gpu=True) # need to run only once to download and load model into memory
img_path = '/home/sxhlvye/ppocr_img/ppocr_img/imgs/1.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
# draw result
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/home/sxhlvye/ppocr_img/ppocr_img/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('./result.jpg')
运行结果如下:
2.2.2
[2022/05/01 10:11:08] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='/home/sxhlvye/.paddleocr/whl/cls/ch_ppocr_mobile_v2.0_cls_infer', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_fce_box_type='poly', det_limit_side_len=960, det_limit_type='max', det_model_dir='/home/sxhlvye/.paddleocr/whl/det/ch/ch_PP-OCRv2_det_infer', det_pse_box_thresh=0.85, det_pse_box_type='quad', det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_polygon=False, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, ir_optim=True, label_list=['0', '180'], lang='ch', layout=True, layout_label_map=None, layout_path_model='lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config', max_batch_size=10, max_text_length=25, min_subgraph_size=15, mode='structure', ocr=True, ocr_version='PP-OCRv2', output='./output', precision='fp32', process_id=0, rec=True, rec_algorithm='CRNN', rec_batch_num=6, rec_char_dict_path='/home/sxhlvye/anaconda3/envs/paddle/lib/python3.8/site-packages/paddleocr/ppocr/utils/ppocr_keys_v1.txt', rec_image_shape='3, 32, 320', rec_model_dir='/home/sxhlvye/.paddleocr/whl/rec/ch/ch_PP-OCRv2_rec_infer', save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], show_log=True, structure_version='STRUCTURE', table=True, table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=True, use_mp=False, use_onnx=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2022/05/01 10:11:11] ppocr DEBUG: dt_boxes num : 2, elapse : 1.8988311290740967
[2022/05/01 10:11:11] ppocr DEBUG: cls num : 2, elapse : 0.015882492065429688
[2022/05/01 10:11:11] ppocr DEBUG: rec_res num : 2, elapse : 0.19820570945739746
[[[296.0, 299.0], [330.0, 298.0], [345.0, 847.0], [311.0, 848.0]], ('土地整治与土壤修复研究中心', 0.9510211944580078)]
[[[343.0, 300.0], [375.0, 299.0], [385.0, 657.0], [353.0, 658.0]], ('华南农业大学|东图', 0.9190022349357605)]
Process finished with exit code 0预测结果图片如下:

3.这边也跑下前面win10下用到的的 PaddleOCR project
文件 · release/2.3 · PaddlePaddle / PaddleOCR · GitCode
这里选择2.3版本进行下载,下载完毕后解压缩,博主放在Home路径下
然后将win10配置时所下载的图片和model放到如下目录下
cd到上面目录下
![]()
然后执行命令航语句:
python3 ./tools/infer/predict_system.py --image_dir="./2.bmp" –det_model_dir="./model/ch_ppocr_mobile_v2.0_det_infer/" --cls_model_dir="./model/ch_ppocr_mobile_v2.0_cls_infer/" --rec_model_dir="./model/ch_ppocr_server_v2.0_rec_infer/" --use_angle_cls=true结果如下:
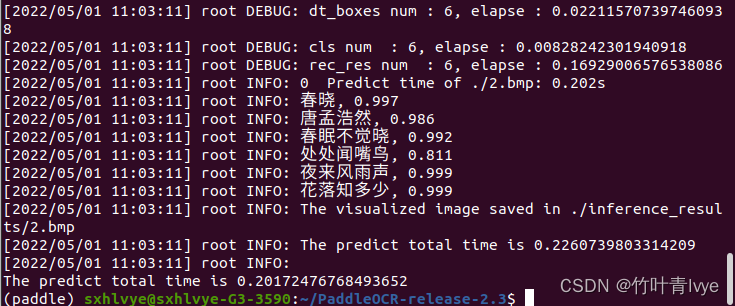
字符也全部读出来了,且由于跑在gpu上,ct也大大加快了。
此工程demo的运行,可见官网说明
doc/doc_en/inference_ppocr_en.md · release/2.3 · PaddlePaddle / PaddleOCR · GitCode