目录
问题引出:
海量数据怎么存储?
解决方法:数据集分块,每一块存储在不同的服务器上。
为了保证数据的可靠性,文件分成多个数据块后,需要对数据块做冗余操作,数据块的冗余会带来需要的磁盘空间变大,这二者不可兼得。在生产上一般设置3个备份,2份存储在相同机柜的两台不同服务器上,另一份存在不同机柜的一台服务器内。
分布式存储服务器的信息怎么管理?
比如总共有多少台服务器,每台服务器ip地址,每台服务器的磁盘容量,每台服务器健康情况怎么记录和管理?
答:在主节点上记录所有从节点的状态
分布式存储一个完整的数据集怎么表达?
答:通过元数据和真正的数据构成。

通过元数据来访问磁盘上的数据,根据此原理,分布式存储将数据集分为元数据和磁盘上的数据,每一个数据块的元数据存储在主节点上,所有的真正的数据存储在从节点上。
因此得到架构为一主多从,主节点存储各个数据块的元数据,从节点存储真正的数据。
从节点间通信如何完成?
不同从节点之间的通信,通过RPC完成,RPC,其实也就是一种socket通信
HDFS分布式存储的流程?
客户端比如说要存储1TB的数据,向主节点发起请求,我要存储1TB数据,文件名是/test.txt,主节点先检查客户端有无权限,在检查有无此文件,如有权限,无此文件的话,接受请求,将此文件分为 n个,每个 x MB,并将元数据存储下来,将文件分块信息给客户端,客户端接收到分块信息,按照要求将文件分成不同的块存储在各个从节点上。
每块的真实数据存储在各从节点上,从节点向主节点上报元数据信息并且备份数据块,主节点记录了每个数据块的元数据情况,当客户端想要读取此文件时,主节点接受请求,分别从不同的从节点读取数据,给到客户端。
主节点的元数据是怎么存储的?
元数据本身数据量不大, 并且访问很频繁,会实时更新,因此元数据存储在主节点内存中,那么当主节点宕机,元数据丢失问题很严重,因此将元数据再在磁盘中冗余存储。那二者如何保证内存和磁盘的数据一致?引入一个辅助结点secondaryNameNode,帮助主节点完成内存元数据和磁盘元数据的同步工作。
因此我们得到HDFS集群:
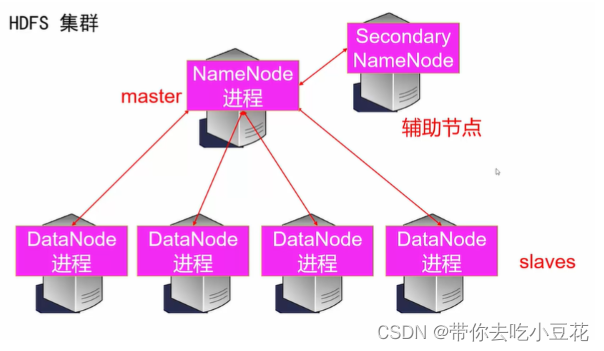
删除分布式文件删除的流程?
客户端发出请求,主节点NameNode接受请求,查看有无权限,是否存在,均为是,然后删除文件目录树,即元数据信息删除,当数据块所在的从节点DataNode向主节点向主节点发送心跳包,这时候主节点会向从节点发送指令,让其删除数据块。
如何保证主节点的元数据不会丢失?
editslog文件
EditsLog 将元数据的每次修改(创建、删除)都会记录在磁盘文件中
因此可以从editslog日志来恢复数据
如何解决editslog过大,数据难以恢复的问题?
合并editslog为fsimage,合并条件:
1. EditsLog 的条数(record数量)大于等于 1000000,
dfs.namenode.checkpoint.txns 来配置
2. 距离上次合并的时间超过了 3600 秒(1小时),
dfs.namenode.checkpoint.period 来配置
如何查看fsimage?
more fsimage 会出现乱码
查看的正确方法是:
hdfs oiv -p XML -i fsimage_XXXXXXXXXX -o ~/path/to/save.xml
more save.xml为什么有fsimage还要有editslog?
FSImage 是某一时刻的内存元数据(其实就是文件目录树)的真实组织情况;
EditsLog 则是记录了该时刻后所有元数据的改动;
1. 从 NameNode 内存元数据中直接生成 FsImage 需要时间的
2. 不能时时生成 FsImage
FSImage + EditsLog 机制:
可以保证NameNode中的内存元数据不会丢掉
可以保证很快的从磁盘中恢复出来