语法解析器生成工具
有很多生成解析器/编译器的工具,帮你来实现自定义的语言(DSL)。
- yacc Yet Another Compiler Compiler
- jacc just another compiler compiler fro Java,
- ANTLR ANother Tool for Language Recognition
下面主要介绍的是Antlr。
Anltr简介
Antlr的作者是 Terence Parr ,关于他的介绍见Anltr之父 (很励志的成长经历)。他说这个命名是在看了平头哥(蜜獾,话说马云也很赞赏这种勇猛的动物)的视频后想到的,无所畏惧,逮啥吃啥。无论你给啥语法来,都不在话下。
ANTLR v4 is named the “Honey Badger” release after the fearless hero of the YouTube sensation, “The Crazy Nastyass Honey Badger,” It takes whatever grammar you give it; it doesn’t give damn!
参考资料:
- ANTLR 官方网址 http://www.antlr.org/
- ANTLR 官方 Github https://github.com/antlr/antlr4
- 大量语法文件例子 https://github.com/antlr/grammars-v4
Antlr是有很多编辑开发的工具,包括常用的IDE插件都有。
简单介绍下使用,主要有两部分工作,先是用antlr的语法来描述解析规则,用antlr的工具来生成解析器的代码;第二步就看通过扩展生成的解析器代码调用这个解析器了。
解析过程简单来说,就是词法解析Lexer,把输入字符解析成tokens,再通过语法解析Parser得到语法树。如下图: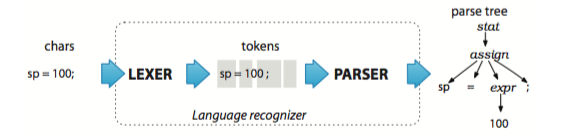
简单体验一下Antlr的使用
就用最朴素的例子来体验一下
1、下载antlr工具包
目前版本是 antlr-4.7.1-complete.jar,地址如下:
https://www.antlr.org/download/antlr-4.7.1-complete.jar
2、编写语法的描述文件
描述文件一般是以.g4为后缀的。
注意这里例子是一个整数加减法的计算器,Calc.g4
我只做了一些简单注解。
grammar Calc; //名称需要和文件名一致
s : expr EOF; //解决问题: no viable alternative at input '<EOF>'
expr
: expr '+' expr #add //标签会生成对应访问方法方便我们实现调用逻辑编写
| expr '-' expr #sub
| INT #int
;
INT : [0-9]+ //定义整数
;
WS
: [ \r\n\t]+ -> skip //跳过空白类字符
;
3、用Antlr的工具来生成类
$ java -cp antlr-4.7.1-complete.jar org.antlr.v4.Tool Calc.g4
当然你可以配置别名(unix下)或批处理脚本(win下)来简化执行命令,详见其入门文档
执行完生成,目录下会多出以下文件
Calc.interp
Calc.tokens
CalcBaseListener.java
CalcLexer.interp
CalcLexer.java
CalcLexer.tokens
CalcListener.java
CalcParser.java
运行时只需要java文件,编译成class
$ javac -cp antlr-4.7.1-complete.jar Calc*.java
这时我们可以通过工具看看我们的解析器代码是否能正常工作了。
$ java -cp antlr-4.7.1-complete.jar:. org.antlr.v4.gui.TestRig Calc expr -tree
注意windows下的classpath的分隔符是
;而unix的是:-cp antlr-4.7.1-complete.jar;.
接下来输入一个表达式,回车换行,然后输入一个EOF,在win下是^Z,在unix下是^D,会输出解析后的表达式。
$ java -cp antlr-4.7.1-complete.jar:. org.antlr.v4.gui.TestRig Calc expr -tree
1+2
(expr (expr 1) + (expr 2))
当然你可以把
-tree参数换成-gui,会在你输入EOF后弹出一个GUI的窗口展示解析的树,非常直观。
4、编写访问逻辑
这里需要创建一个java工程或使用IDE工具(如:eclipse)比较方便,当然也可以仍在命令行终端搞定这一切。
要运行执行解析器,只需要antlr4-runtime的jar即可。如果你在IDE工程中,只需要加入POM中这个依赖就行;然后把生成的.java文件拷贝到工程当中即可。
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.7.1</version>
</dependency>
如果需要生成的代码有包路径,在生成命令中可以通过
-package来指定。
我这里使用默认包,也就是没有指定包名。
继续回到命令行环境,我们需要编写一个CalcExecuteListener类,继承CalcBaseListener类,通过覆盖(或者说实现)几个访问方法来达到访问我们解析表达式生成的语法树(AST)。
注意,Antlr对语法树访问提供两种模式Visitor和Listener。默认是生成Listener模式代码。这种模式实现了事件访问机制的调用。
其实也可以直接修改生成的CalcBaseListener类,实现其中的需要的方法,但是在修改的表达式定义后,重新生成代码会需要重新修改。所以一般不直接修改生成的代码,而是继承。
CalcExecuteListener.java 如下:
import java.util.Stack;
public class CalcExecuteListener extends CalcBaseListener {
Stack<Integer> stack = new Stack<>();
@Override
public void exitInt(CalcParser.IntContext ctx) {
stack.add(Integer.parseInt(ctx.INT().getText()));
}
@Override
public void exitAdd(CalcParser.AddContext ctx) {
int r = stack.pop();
int l = stack.pop();
stack.add(l + r);
}
@Override
public void exitSub(CalcParser.SubContext ctx) {
int r = stack.pop();
int l = stack.pop();
stack.add(l - r);
}
public int result() {
return stack.pop();
}
}
然后我们写一个测试类,来调用一下
T.java
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CodePointCharStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
public class T {
public static int exec(String input) {
CodePointCharStream cs = CharStreams.fromString(input);
CalcLexer lexer = new CalcLexer(cs);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalcParser parser = new CalcParser(tokens);
ParseTree tree = parser.expr();
ParseTreeWalker walker = new ParseTreeWalker();
CalcExecuteListener listener = new CalcExecuteListener();
walker.walk(listener, tree);
return listener.result();
}
public static void main(String[] args) {
String input = "1+2";
System.out.println(exec(input));
}
}
编译一下,然后执行
$ javac -cp antlr-4.7.1-complete.jar:. CalcBaseListener.java T.java
$ java -cp antlr-4.7.1-complete.jar:. T
输出了结果,看起挺顺利。
3
你可以尝试修改input的值,比如: 1+2+3试试。
至此,一个简单的解释模式表达式解析器就完成了,感觉还不错吧。为了提高执行效率,我们还可以实现访问语法树时,生成一个调用栈,来实现编译模式。
只不过目前的例子里表达式都是常量。如果当一个表达式中包含执行上下文中带来的变量,这个表达式会多次执行的时候,我们就可以用提前编译,在后续执行时省去解析语法树过程,从而加速执行速度。