一、研究背景
Collaborative Learning(协作学习),比如联邦学习受到越来越广泛的应用。和传统机器学习的训练方法相比,协作学习不只在一个单一数据集上由单个用户训练数据,而是由多个用户在各自私人数据集上训练,共享训练信息来对目标模型更新。
二、研究内容
文章研究的是Collaborative Learning(协作学习)中,通过一些意外的的特征来泄露秘密信息。Collaborative Learning(协作学习)要用到梯度更新,作者证明了这些更新会泄漏参与者相关的训练数据的信息,并开发了被动和主动的推理攻击来利用这种泄漏。
三、文章内容
1.introduction
Collaborative Learning(协作学习)的主要工作是为了,提高训练速度,减少训练所需要的时间。但与此同时,如何保护每个训练成员的数据安全也很重要。本文围绕 what can beinferred about a participant’s training dataset from themodel updatesrevealed during collaborative model training。
作者的三大贡献为:
1)作者展示了敌手是如何推理出某特定数据的存在性(类似成员推断攻击)
2)作者展示了敌手是怎么推理 unintended properties(属性)的
3)作者对这种攻击做出了评估,并提出了防御方法
2.background
(1)Collaborative learning 联合学习
Stochastic Gradient Descent (SGD) 随机梯度下降是深度学习模型中模型参数更新的常用方法,也就是优化器经常使用的优化函数。SGD通过更新参数 θ ,将 θ 向梯度下降的方向减少,用学习率来规范每次更新的大小


- C相当于参与梯度更新用户的比例,用来控制参与梯度更新的用户数
- m=max(C*K,1),m是参与梯度更新的用户数,最少一个用户参与
- St 参与梯度更新的m个参与者
- nk:第k个参与者训练集的size
- n:所有训练数据的size
算法核心流程就是,在所有用户中随机选择m个参与梯度更新,然后每一个用户使用SGD计算更新后的参数值,然后对所有用户求的参数值做加权平均值。
3.REASONING ABOUTPRIVACY INMACHINELEARNING
在机器学习中,关于隐私的推理部分。一个机器学习模型如果是比较好的,那么这个模型一定携带了训练信息。
(1)Inferring class representatives
之前的攻击例如模型逆向攻击,基于GAN的攻击,训练集上的数据都是比较相似的,但是作者的攻击情景比较普遍,各个参与方的数据可以不是相似的。
(2)Inferring membership in training data
成员推理:推理某个数据是否出现在训练集中
(3)Inferring properties of training data
- 作者的目标是推断训练输入的一个子集的属性,而不是作为一个整体的属性的类别。
- 作者可以推断一个属性是否在参与方的训练集上出现
- 作者可以推断一个属性出现的时间
4.INFERENCEATTACKS
(1)Threat model
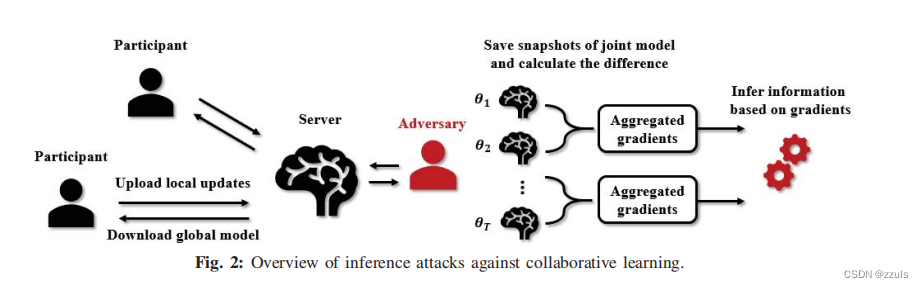
- 假设有K个参与者(K>2)
- 参与者中包含了:Adversary(攻击者)、 target participant(被攻击者)、honest participant
- 一般的参与者无法知道是否有攻击者存在,即使知道也无法找到攻击者
- 攻击者通过梯度的更新来推理被攻击者的数据信息
(2)Overview of the attacks(攻击描述)
- 在每次训练过程中,攻击者下载联合模型,按照梯度更新算法计算梯度,并发送给服务器
- 攻击者保存联合模型的参数
,并计算两次
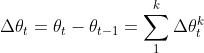
是所有参与者的聚和更新,
是除了敌手的其他所有参与者的聚合更新
Leakage from the embedding layer
对于一些非数值性的训练数据,例如自然语言处理,其中输入空间是离散和稀疏的,这时候可以用嵌入层将输入转换为低维向量。
- word:离散tokens,例如具体的词语或者特定的位置
- V:所有词语的集合
- 训练数据中的每个单词通过嵌入矩阵映射到一个单词嵌入向量
- 嵌入矩阵:
|v|是词向量的大小,d是嵌入的维度
- 在训练的过程中,嵌入矩阵相当于模型的一个参数,用来协同优化。嵌入层的梯度相对于输入词来说是稀疏的:给定一批文本,只有输入词存在梯度才会更新,其他词的梯度其他词的梯度为零。这种差异诚实的显示了参与者在协作学习期间,哪些词出现了。
Leakage from the gradients
对于深度学习的神经网络,梯度的更新,在最后一层到第一层的反向传播的过程中完成。一个给定层的梯度是利用该层的特征和上面一层的误差(损失)来计算的。
- 对于全连接层
,
,
(
式权重矩阵)
- 误差E相对于Wl的梯度计算为:
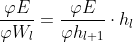
- 观察到权重的更新可以用于推理特征值,而特征值来自于参与者的私人训练数据集,所以会泄露参与者隐私。
(3)Membership inference
根据上述攻击描述,可以得出嵌入层的非零梯度显示了哪些单词出现在这一batch中,这有助于推断一个给定的文本或位置是否出现训练集中。
- Vt 是包含于
中的单词
- 在训练过程中,攻击者收集一个单词序列[V1,...,VT]
- 给定一个文本记录 r,其中包含单词 Vr,攻击者通过检测是否
来判断r 是否是成员。如果是,那么Vr至少在序列中出现一次。
(4)Passive property inference(被动属性推理)
假设对手有有数据点组成的辅助数据,这些数据点具有所关注的属性和不关注的属性
。
攻击者可以利用全局模型的快照生成具有该属性的聚合更新和没有该属性的聚合更新,这样的话攻击者就可以构建一个二分类器。这种攻击是被动的,攻击者并不改变训练过程,只是观察训练过程的更新。
Batch property classififier

上面的算法是Batch property classififier算法,主要是根据关注的属性样本在 参数 梯度来构造二分类数据集,在联邦学习情境下,是可以得到梯度信息的。
表示这个batch中没有要关注的属性
表示这个batch中有要关注的属性
Inference algorithm
随着协作训练的进展,对手观察梯度更新: =
,对于single-batch推理,对手只需将观察到的梯度更新提供给批处理属性分类器fprop,fprop在[0,1]中输出一个分数,表示批处理具有该属性的概率。攻击者可以使用所有迭代中的平均分数来决定目标的整个数据集是否具有有问题的属性
(5)Active property inference
攻击者可以利用 multi-task learning 实现攻击能力更强的主动属性推理攻击,攻击者通过把增强属性分类器连接到最后一层,来扩展他的协作训练模型的本地副本
- y :主任务标签
- p:属性标签
- 模型联合损失为:
- 对手基于这种联合损失上传更新
,使得联合模型学习了有和没有该属性的数据的不同 表示
- 简单一点解释,就是使用这种方式计算损失,那么有该属性的数据和没有该属性的数据,就 会表现出差异,这种差异可以被攻击者发现,从而实现主动属性推理。
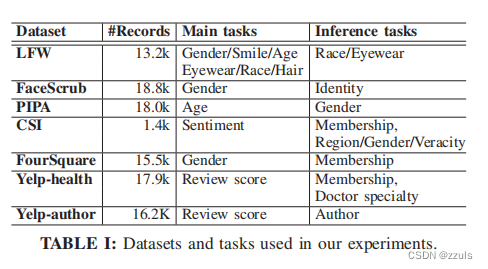
5.DATASETS AND MODEL ARCHITECTURES
6.TWO-PARTYEXPERIMENTS
(1) Membership inference
- 对手首先为输入建立一个词袋(BoW),以便推断该输入在目标训练数据中的成员身份,作者称之为 test BoW
- 嵌入层的非零梯度揭示了目标数据的每个批次中存在哪些 "词",使对手能够建立一个batch的BoW。如果test Bow是这个batch Bow的一个子集,那么对手就会推断感兴趣的输入出现在这个batch 的 Bow中。
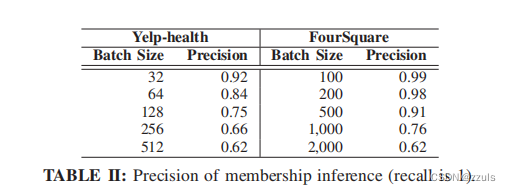
表二展示了在Yelp-helth数据集和FourSqure数据集上,不同batch size下成员推断攻击的准确率
(2)Single-batch property inference
- 攻击者要分辨那些batch是
- 将训练数据平均分配给目标参与者和攻击者,并假设在两个子集中具有该属性的输入比例一样
LFW:作者在LFW数据上来实验single-batch属性推理攻击
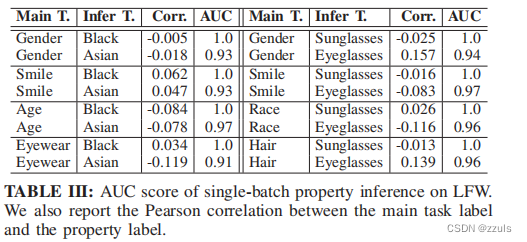
作者用AUC,和Corr来衡量推断的效果。简单来说,Auc越大,准确率越高,Corr 用的是皮尔森相关系数,Corr越大,相关性越强。
总结:协作学习会泄露训练数据的属性,即使这些训练数据的属性与主任务没有关联。
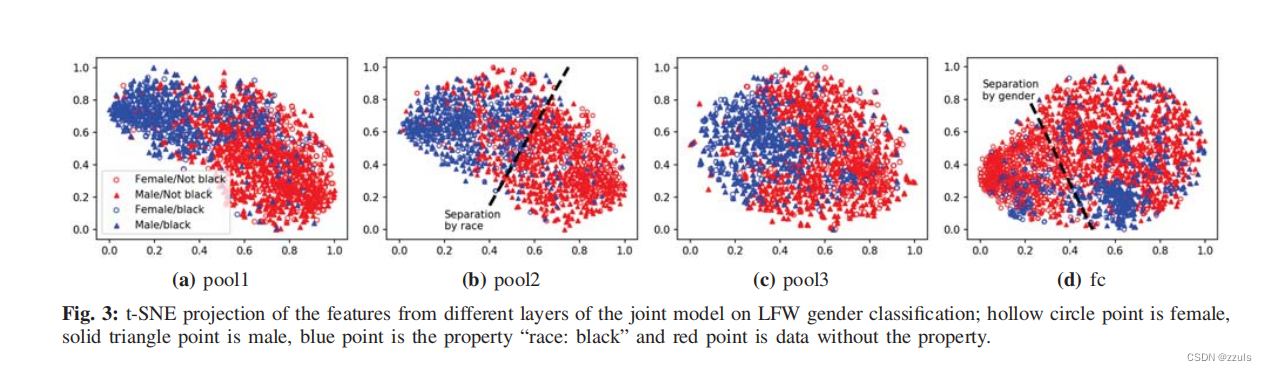
图3解释了为什么会泄露数据,图3表示了不同层的 t-SNE,不难看出,底层的pool1、pool2、pool3是根据property分类的,而高层的全连接层是根据class分类的
model的底层会学习不同于模型分类任务的properties,因此本文的推理攻击能够利用这种unintended的功能来学习其他目标。
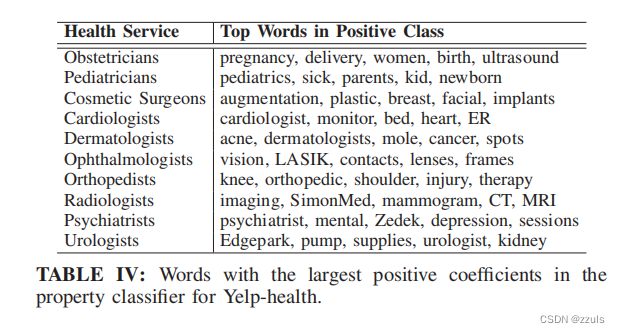
- 在这个数据集上,作者把分类的得分值score作为主要任务,医生的专业作为推理目标
- 作者使用语料库中最常见的3000个单词作为词汇表,并进行了3000次迭代的训练
- 使用来自嵌入层梯度的BoWs,该攻击实现了几乎完美的AUC
- 表4 显示了在逻辑回归中,对预测贡献最大的一些单词
 Fractional properties
Fractional properties
- 在之前的实验中,1/2 的 target 的 batch中含有攻击者感兴趣的属性,另外1/2没有。在这里作者考虑了这个比例对实验结果的影响,因此在FaceScrub’s top 5 face IDs and Yelp-author两个任务上进行了实验。
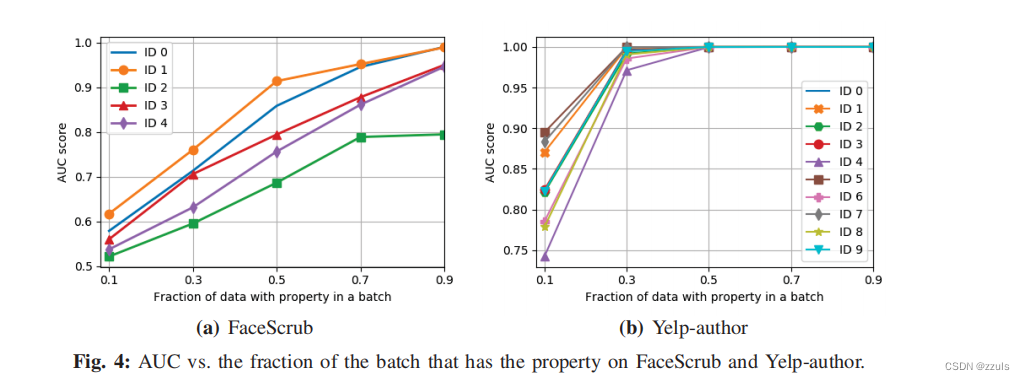
- 可以看出,这个比例还是会影响推理的效果的
(3)Inferring when a property occurs
PIPA
- 主任务:检测是否有young man在这些训练数据中
- 推理任务:检测这些训练数据中 young man 是否有相同的性别
- 作者在500-1500轮将训练数据替换为有相同性别属性的batch
FaceScrub
- 对于FaceScrub上的性别分类模型,攻击者的目标是推断某个人的照片是否出现在其他参与者的数据集上,以及何时出现在其他参与者的数据集上。
- 联合模型共训练了2500轮,作者将target participants(被攻击者)的训练数据做了修改,在0-500和1500-2000 ID0 出现,在500-1000,2000-2500 ID1出现,ID2 没有出现在训练数据集中。
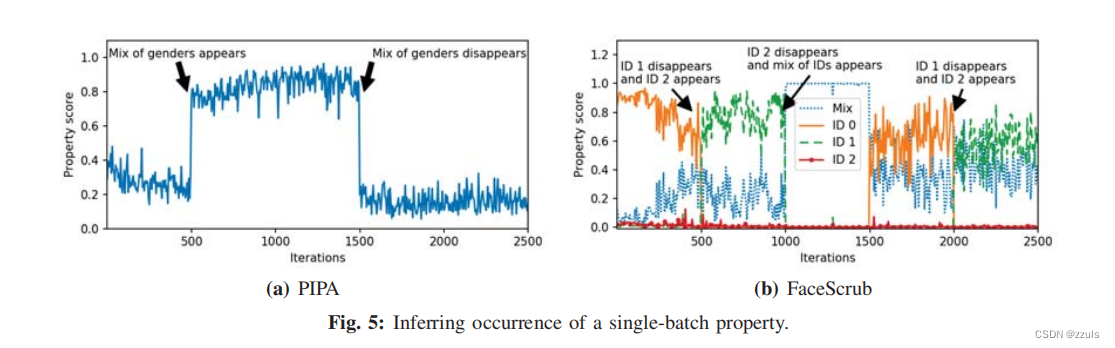
图5显示了,在PIRA和FaceScrb上,某些特定数据的出现,会对property score造成较大的影响,可以从影响是否出现和出现的区间来完成属性推理。
(4)Inference against well-generalized models
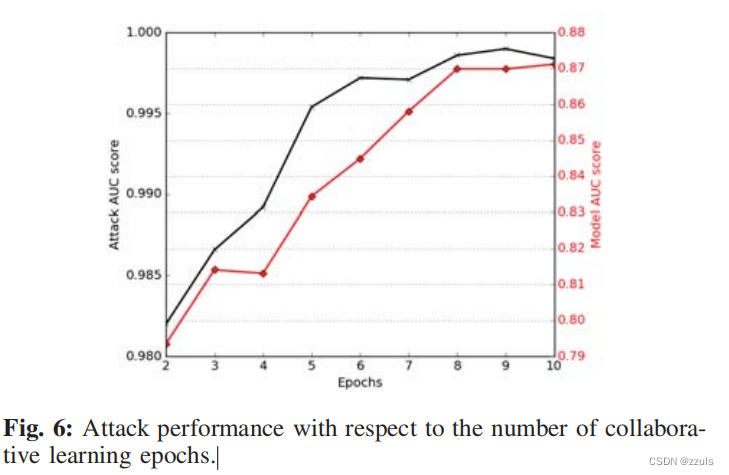
- 图6 显示了仅在两个batch 的过程,Attack Auc score 就会达到一个比较高的程度,证明这种攻击效率比较高
- 图6还显示了该模型没有被过度拟合。其在主要情绪分析任务上的测试精度较高,且随着时代数量的增加而提高,主任务没有受到攻击的影响。
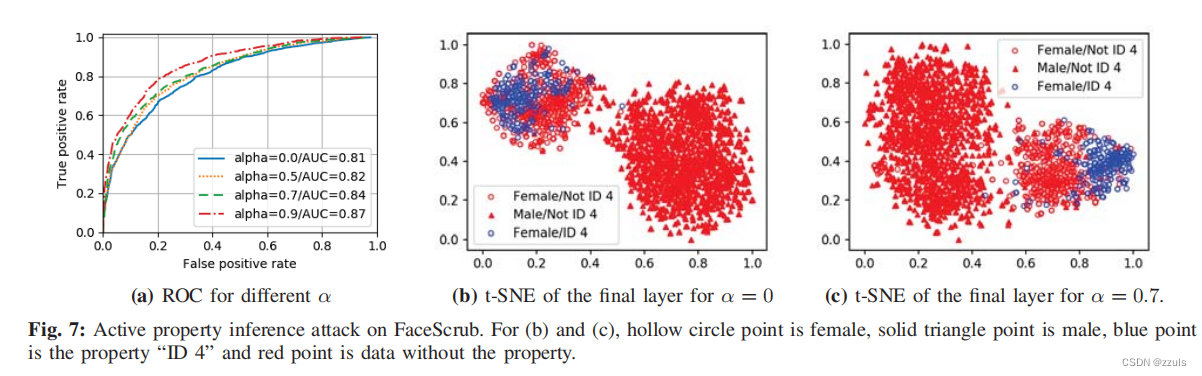
(5)Active property inference
- 为了显示主动攻击的额外能力,作者使用了FaceScrub,主要任务是性别分类,对手的任务是推断训练数据中ID 4的存在。
- 作者假设 ID 4 存在于一半的数据
- Figure7a 显示了AUC随着α的增加而增加
- Figure 7b and Figure 7c 显示了最终全连接层的t-SNE投影,分别为α=0和α=0.7
- 当α=0.7时,具有属性(蓝色点)的数据分组比在被动攻击下训练(α=0)的模型中更紧密。这说明,作为主动攻击的结果,联合模型学习了有感兴趣的属性和没有这个属性的差异,能更好的识别出这种差异。
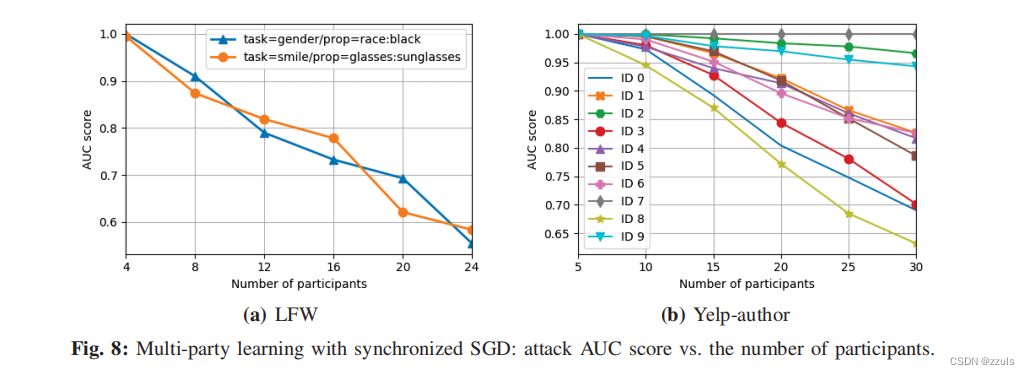
6.MULTI-PARTYEXPERIMENTS
(1)Synchronized SGD
- 随着协作学习中诚实参与者数量的增加,对手的任务变得更加困难,因为观察到的梯度更新是跨多个参与者聚合的。此外,推断出的信息可能不能直接揭示数据所属的参与者的身份。
- 在接下来的实验中,作者将训练数据均匀地分配给所有参与者,但这样只有目标和对手才拥有具有该属性的数据,联合模型采用与两种情况下相同的超参数进行训练。
(2)Model averaging
- 在每一轮t的联邦学习与模型平均(算法2)攻击者通过观察
来获得参与者的数据
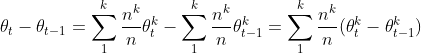
- 在我们的实验中,我们将训练数据在诚实的参与者之间平均分配
- 但确保在目标参与者的子集中,pˆ%的输入具有要推测的属性,而其他诚实参与者的数据都没有这个属性
Inferring presence of a face
- 作者使用FaceScrub,并选择Face ID1 和Face ID3,作者想要推断它们的存在
- In the “property” case(实验组)中设置 pˆ=80%,In the control case(对照组)设置 pˆ=0%
- 图9 显示了,当特定的脸存在时,得分会比较高。
- 攻击的成功取决于所推断的属性、数据在参与者之间的分布以及其他因素。例如,Face ID2和Face ID4的分类器与Faceid1和3的分类器的训练方式相同,但无法推断出训练数据中是否存在相应的人脸。

Inferring when a face occurs
- 这个实验中,作者的目的是推断一个本地数据具有特定属性的参与者何时加入了协作训练
- 攻击者和普通参与者才250轮之前产与训练,目标参与者(被攻击者)在250轮之后参与训练
- 可以看出目标参与者参与训练后,AUC几乎从0增加到1
7.DEFENSES
(1)Sharing fewer gradients
攻击来自于梯度信息共享,少分享些梯度信息,让攻击者拿不到关键的梯度信息,从而无法实现攻击。
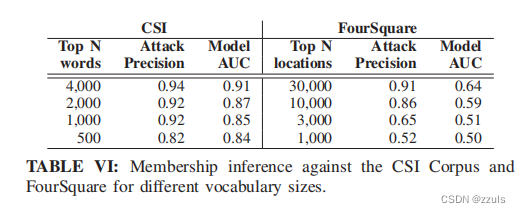
(2)Dimensionality reduction(降维)
如果模型的输入空间是稀疏的,并且输入必须嵌入到低维空间,嵌入层的非零梯度更新显示训练批中存在哪些输入。从下表中可以看出数据降维可以较少对模型的攻击性准确率,但是也会使模型的质量降低。
(3) Dropout
通过dropout可以减轻攻击,因为dropout会丢弃某些神经元,使攻击者只能观察到更少的激活神经元的梯度。
(4)Participant-level differential privacy
当honest参与者的数量增多时,会让攻击者供给更加困难,因为攻击者要下载聚和模型的梯度等信息,使用差分隐私保护技术,可以使得被攻击者泄露更少的信息。
8.LIMITATIONS OF THE ATTACKS 攻击的限制
- 需要辅助数据,但是有时获得辅助数据是不可行的
- 参与者数量的问题,本文中的模型参与人数较少(2-30人),现实中联邦训练可能涉及成百上千人
- 不能检测到的属性:有一些特征并不是内部可分的,此时推理攻击就会失败
- 无法确定推理出的属性究竟是属于那个参与者