Go Web开发扩展项-其他配套框架
作者:可乐可乐可:https://blog.csdn.net/weixin_44494373
上一篇:Go Web开发入门指南<前半>
内容:Go Web开发套装,Gin,Gorm,viper,validator,zap,go-redis,grpc本文难度:适合入门
上半部分,我们讲了讲Gin,想做到web开发,我们现在已经有了基础的MVC,我们只需要ORM框架(操作数据库)日志框架就能满足基本80%的需求了,初次之外,就是配置文件的支持,rpc微服务体系支持
我们一点一点来扩展我们的知识范围,相比各位已经很心急了,那我们按照这样的流程进行讲解
ORM框架gorm -> 日志框架:logrus、zap -> 配置文件viper
用Gorm来开启你的CRUD之旅(不是
功夫再深,也逃不了CRUD的命运,我与大佬的不同,不在与拧螺丝的工作,在于在什么地点拧螺丝,(开玩笑)
Go是编程语言里面的新生儿这种事情就不用再强调了,新时代的CRUD,呸呸呸,ORM操作,加上Go简洁的追求,Go的ORM框架用起来很轻松(但是经验告诉我,用起来越简单,听起来越全自动的东西,都越恐怖,声明,本句与Kubernetes没有任何关系)
这里也算提个醒吧,工具自动化是好事,但是这意味着你可能会有需要进入这自动化的代码中,看看他的原理,找到你的解答
来,先码一下gorm的官方文档:文档地址
官方文档写的很棒,多看看官方文档(毕竟中文版本)
写到这里,弟弟又去复习了一遍文档,gorm的文档,确实。。太到位了,建议各位看看官方文档吧,这里我给大家讲一下基本的思路让大家对gorm里的一些概念有个基础的认识
但是不写Gorm,总感觉很空虚,思来想去,最后还是写了出来,我会尽量用简单便于理解的方式帮助大家了解gorm,后面就只需要在官方文档找api了
操作数据库,一般需要两个部分,1、数据库驱动 2、orm框架
而一个orm框架,大致会有这些构建
- 类与表的映射
- 建立数据库连接
- 数据库连接池
- CRUD操作
- 事务控制
- 日志配置
这几个步骤也是我们使用一个ORM框架的基本步骤
数据库表映射
gorm没有另辟蹊径,是很经典的类型->表,字段对应表字段
我们创建一个model
package model
// data将会变成表名称
type Data struct {
ID uint `json:"id,omitempty" gorm:"primaryKey"`
Msg string `json:"msg,omitempty" gorm:"type:varchar(10) unique"`
}
关于表名与字段这里需要注意以下
GORM在字段和表面的约定
使用 ID 作为主键
默认情况下,GORM 会使用 ID 作为表的主键。
type User struct {
ID string // 默认情况下,名为 `ID` 的字段会作为表的主键
Name string
}
你可以通过标签 primaryKey 将其它字段设为主键
// 将 `UUID` 设为主键
type Animal struct {
ID int64
UUID string `gorm:"primaryKey"`
Name string
Age int64
}
此外,您还可以看看 复合主键
复数表名
GORM 使用结构体名的 蛇形命名 作为表名。对于结构体 User,根据约定,其表名为 users
这里我很疑惑,我们使用AaBc会被创建为aa_bcs,但是我们命名为Data,将创建为data
总之,官方并没有仔细的叙述这里的逻辑,很无奈,我们只能被逼再次打开源码(好耶!
进入(db *DB) AutoMigrate(dst …interface{})方法,
我们发现他是适配器模式,调用了db.Migrator().AutoMigrate(dst…)
进入db.Migrator().AutoMigrate(dst…),这个接口只有一个实现类,妥妥的适配器模式
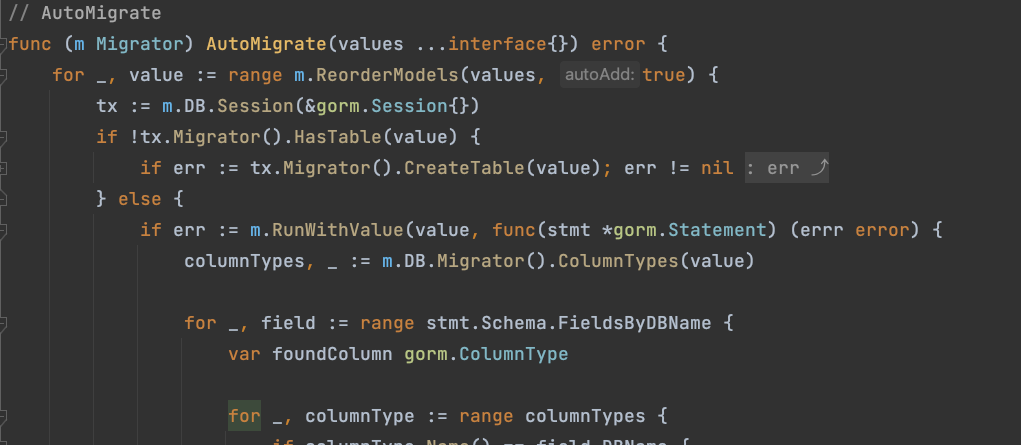
在这里,我们大致看了看,逻辑分为创建和修改表,不用多想,他们的策略一定是一样的,我们看create即可
代码贴在了下面,大家来一起观赏一下,gorm的骚操作,原来也就是sql的拼接罢了
各位先复习一下sql创建表的语句
CREATE TABLE Persons
(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
大概看看就行,流程其实很简单,就是拼凑出一个sql
func (m Migrator) CreateTable(values ...interface{}) error {
// 传进来的是多个表,遍历创建每一个
for _, value := range m.ReorderModels(values, false) {
// 开一个session
tx := m.DB.Session(&gorm.Session{})
// 开始拼接sql
if err := m.RunWithValue(value, func(stmt *gorm.Statement) (errr error) {
// CREATE TABLE ? (
var (
// sql语句,参数用?
createTableSQL = "CREATE TABLE ? ("
// sql参数
values = []interface{}{m.CurrentTable(stmt)}
hasPrimaryKeyInDataType bool
)
// 拼接上每一个字段,还会加上PRIMARY KEY
// CREATE TABLE ? ( ? ? )
for _, dbName := range stmt.Schema.DBNames {
field := stmt.Schema.FieldsByDBName[dbName]
createTableSQL += "? ?"
// 获取标签,取出字符串 PRIMARY KEY
hasPrimaryKeyInDataType = hasPrimaryKeyInDataType || strings.Contains(strings.ToUpper(string(field.DataType)), "PRIMARY KEY")
values = append(values, clause.Column{Name: dbName}, m.DB.Migrator().FullDataTypeOf(field))
createTableSQL += ","
}
if !hasPrimaryKeyInDataType && len(stmt.Schema.PrimaryFields) > 0 {
createTableSQL += "PRIMARY KEY ?,"
primaryKeys := []interface{}{}
for _, field := range stmt.Schema.PrimaryFields {
primaryKeys = append(primaryKeys, clause.Column{Name: field.DBName})
}
values = append(values, primaryKeys)
}
// 索引逻辑
for _, idx := range stmt.Schema.ParseIndexes() {
if m.CreateIndexAfterCreateTable {
defer func(value interface{}, name string) {
if errr == nil {
errr = tx.Migrator().CreateIndex(value, name)
}
}(value, idx.Name)
} else {
if idx.Class != "" {
createTableSQL += idx.Class + " "
}
createTableSQL += "INDEX ? ?"
if idx.Option != "" {
createTableSQL += " " + idx.Option
}
createTableSQL += ","
values = append(values, clause.Expr{SQL: idx.Name}, tx.Migrator().(BuildIndexOptionsInterface).BuildIndexOptions(idx.Fields, stmt))
}
}
// 关系
for _, rel := range stmt.Schema.Relationships.Relations {
if !m.DB.DisableForeignKeyConstraintWhenMigrating {
if constraint := rel.ParseConstraint(); constraint != nil {
if constraint.Schema == stmt.Schema {
sql, vars := buildConstraint(constraint)
createTableSQL += sql + ","
values = append(values, vars...)
}
}
}
}
for _, chk := range stmt.Schema.ParseCheckConstraints() {
createTableSQL += "CONSTRAINT ? CHECK (?),"
values = append(values, clause.Column{Name: chk.Name}, clause.Expr{SQL: chk.Constraint})
}
// 要是结尾有, 就去掉
createTableSQL = strings.TrimSuffix(createTableSQL, ",")
createTableSQL += ")"
if tableOption, ok := m.DB.Get("gorm:table_options"); ok {
createTableSQL += fmt.Sprint(tableOption)
}
// 跑sql
errr = tx.Exec(createTableSQL, values...).Error
return errr
}); err != nil {
return err
}
}
return nil
}
诶,不对啊,这里好像,没有处理字段名,?,不好意思(故意的,还不承认
我们回到上一级,发现这里有个ReorderModels的方法,好家伙就是你了,捞开看看
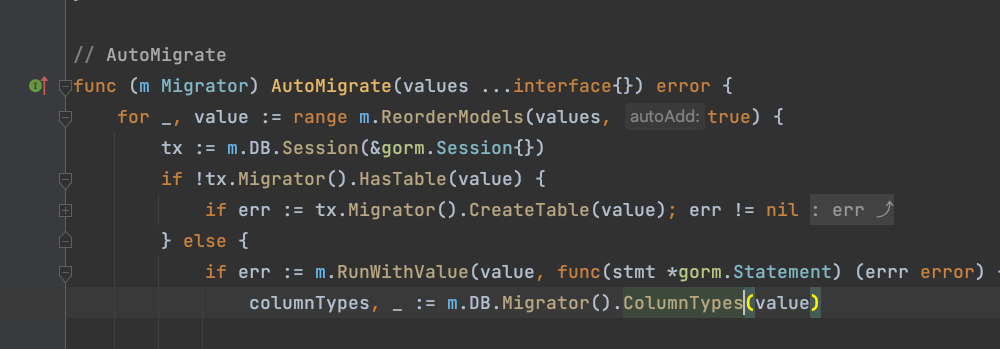
这个方法里面,有这样一段代码,
parse,parse value,这是编程界处理解析数据的官话,我们锁定这个方法,点进去
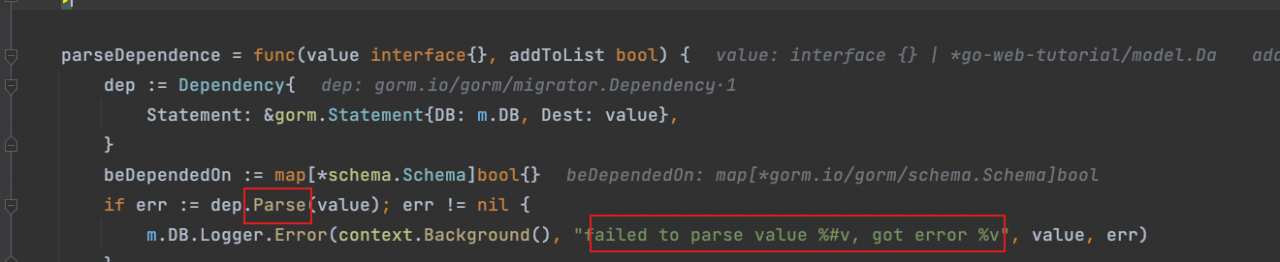
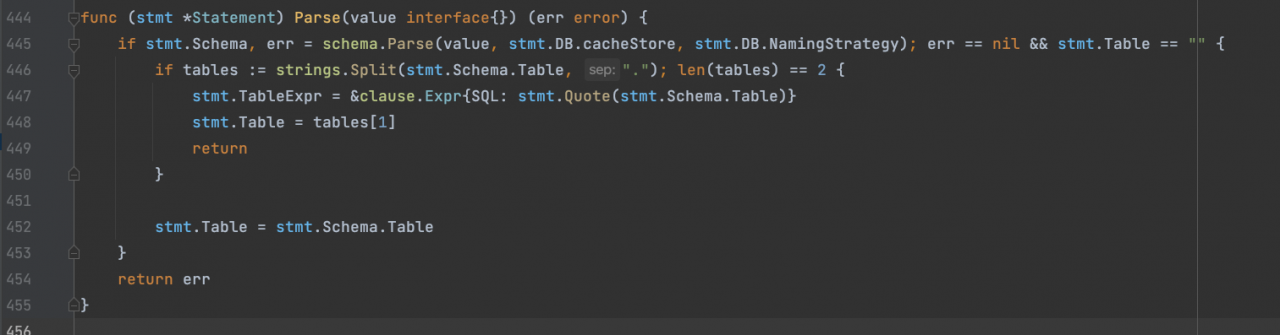
schema是关系的意思,直接点进去,我们看到了反射,没毛病了,就是这里了
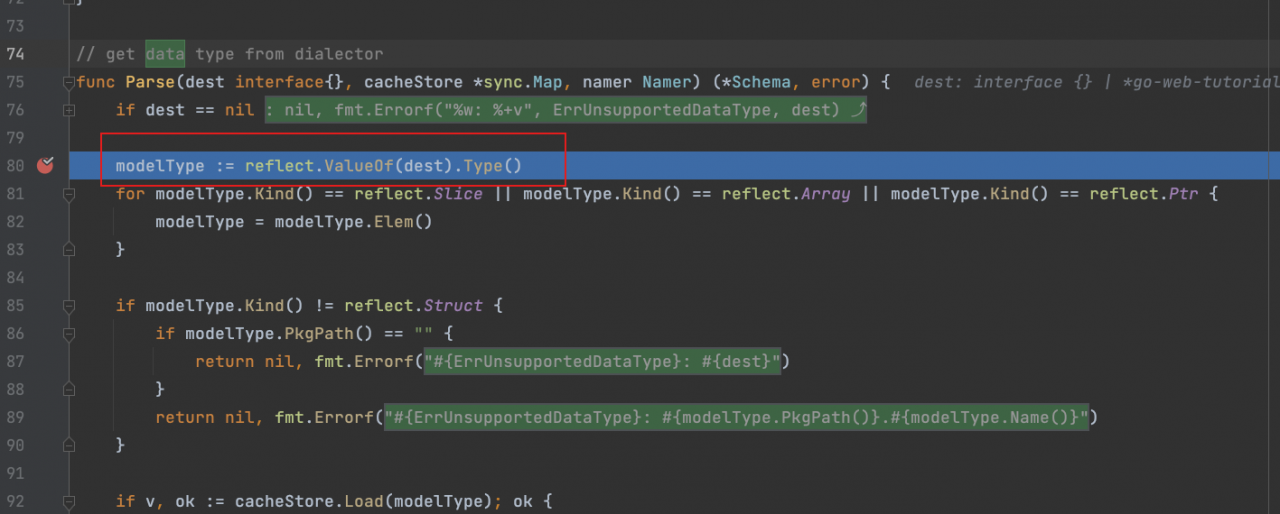
首先就是经典的反射处理,验证类型,适配类型
检查类型是否实现了接口TableName,如果使用了,就直接调用返回
然后利用得到的类型创建一个新的空对象
接着用namer.TableName()获取解析后的表名,好家伙,可找到你了
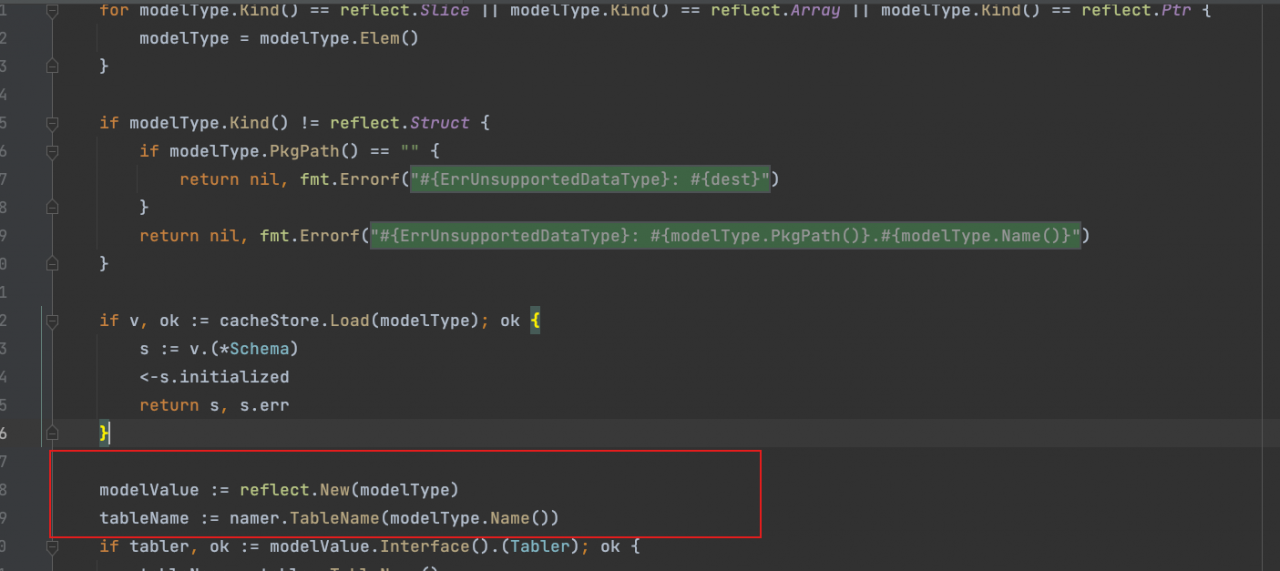
// TableName convert string to table name
func (ns NamingStrategy) TableName(str string) string {
// 单数的table,说明这里来判断末尾是不是加s
if ns.SingularTable {
return ns.TablePrefix + ns.toDBName(str)
}
// 加上s
return ns.TablePrefix + inflection.Plural(ns.toDBName(str))
}
// 将字符串处理
// 大小写变动,驼峰转下划线形式,想看可以看,其实就是一个字符一个字符判断,判断当前是转化,插入,还是加下划线
// Dat->dat
// Data->data
func (ns NamingStrategy) toDBName(name string) string {
if name == "" {
return ""
}
if ns.NameReplacer != nil {
name = ns.NameReplacer.Replace(name)
}
if ns.NoLowerCase {
return name
}
var (
value = commonInitialismsReplacer.Replace(name)
buf strings.Builder
lastCase, nextCase, nextNumber bool // upper case == true
curCase = value[0] <= 'Z' && value[0] >= 'A'
)
// 遍历表名
for i, v := range value[:len(value)-1] {
nextCase = value[i+1] <= 'Z' && value[i+1] >= 'A'
nextNumber = value[i+1] >= '0' && value[i+1] <= '9'
if curCase {
if lastCase && (nextCase || nextNumber) {
buf.WriteRune(v + 32)
} else {
if i > 0 && value[i-1] != '_' && value[i+1] != '_' {
buf.WriteByte('_')
}
buf.WriteRune(v + 32)
}
} else {
buf.WriteRune(v)
}
lastCase = curCase
curCase = nextCase
}
if curCase {
if !lastCase && len(value) > 1 {
buf.WriteByte('_')
}
buf.WriteByte(value[len(value)-1] + 32)
} else {
buf.WriteByte(value[len(value)-1])
}
ret := buf.String()
return ret
}
然后 Plural(str string) string 处理已经大小写处理过的字符串
Plural 复数
// Plural converts a word to its plural form
func Plural(str string) string {
for _, inflection := range compiledPluralMaps {
if inflection.regexp.MatchString(str) {
return inflection.regexp.ReplaceAllString(str, inflection.replace)
}
}
return str
}
等等,这个代码,马萨卡(不会),他竟然是枚举所有的特殊复数(比如fish鱼,的复数为fish,ac的复数为acs)。。。可真有你的
问题解决了兄弟们,data表名,是因为。。data是不可数(英语知识)
总结:Gorm创建表,默认会使用复数做表名,同时语义符合英文语法(尽管形式很生猛),可以通过Config进行选择是否使用复数。
TableName
您可以实现 Tabler 接口来更改默认表名,例如:
type Tabler interface {
TableName() string
}
// TableName 会将 User 的表名重写为 `profiles`
func (User) TableName() string {
return "profiles"
}
注意:
TableName不支持动态变化,它会被缓存下来以便后续使用。想要使用动态表名,你可以使用Scopes,例如:
func UserTable(user User) func (tx *gorm.DB) *gorm.DB {
return func (tx *gorm.DB) *gorm.DB {
if user.Admin {
return tx.Table("admin_users")
}
return tx.Table("users")
}
}
db.Scopes(UserTable(user)).Create(&user)
临时指定表名
您可以使用 Table 方法临时指定表名,例如:
// 根据 User 的字段创建 `deleted_users` 表
db.Table("deleted_users").AutoMigrate(&User{})
// 从另一张表查询数据
var deletedUsers []User
db.Table("deleted_users").Find(&deletedUsers)
// SELECT * FROM deleted_users;
db.Table("deleted_users").Where("name = ?", "jinzhu").Delete(&User{})
// DELETE FROM deleted_users WHERE name = 'jinzhu';
查看 from 子查询 了解如何在 FROM 子句中使用子查询
命名策略
GORM 允许用户通过覆盖默认的命名策略更改默认的命名约定,命名策略被用于构建: TableName、ColumnName、JoinTableName、RelationshipFKName、CheckerName、IndexName。查看 GORM 配置 获取详情
列名
根据约定,数据表的列名使用的是 struct 字段名的 蛇形命名
type User struct {
ID uint // 列名是 `id`
Name string // 列名是 `name`
Birthday time.Time // 列名是 `birthday`
CreatedAt time.Time // 列名是 `created_at`
}
您可以使用 column 标签或 命名策略 来覆盖列名
type Animal struct {
AnimalID int64 `gorm:"column:beast_id"` // 将列名设为 `beast_id`
Birthday time.Time `gorm:"column:day_of_the_beast"` // 将列名设为 `day_of_the_beast`
Age int64 `gorm:"column:age_of_the_beast"` // 将列名设为 `age_of_the_beast`
}
时间戳追踪
CreatedAt
对于有 CreatedAt 字段的模型,创建记录时,如果该字段值为零值,则将该字段的值设为当前时间
db.Create(&user) // 将 `CreatedAt` 设为当前时间
user2 := User{Name: "jinzhu", CreatedAt: time.Now()}
db.Create(&user2) // user2 的 `CreatedAt` 不会被修改
// 想要修改该值,您可以使用 `Update`
db.Model(&user).Update("CreatedAt", time.Now())
UpdatedAt
对于有 UpdatedAt 字段的模型,更新记录时,将该字段的值设为当前时间。创建记录时,如果该字段值为零值,则将该字段的值设为当前时间
db.Save(&user) // 将 `UpdatedAt` 设为当前时间
db.Model(&user).Update("name", "jinzhu") // 会将 `UpdatedAt` 设为当前时间
db.Model(&user).UpdateColumn("name", "jinzhu") // `UpdatedAt` 不会被修改
user2 := User{Name: "jinzhu", UpdatedAt: time.Now()}
db.Create(&user2) // 创建记录时,user2 的 `UpdatedAt` 不会被修改
user3 := User{Name: "jinzhu", UpdatedAt: time.Now()}
db.Save(&user3) // 更新世,user3 的 `UpdatedAt` 会修改为当前时间
注意 GORM 支持拥有多种类型的时间追踪字段。可以根据 UNIX(毫/纳)秒,查看 Model 获取详情
使用gorm:"primaryKey"标签可以指定主键
gorm支持创建数据表,使用AutoMigrate即可
err = db.AutoMigrate(&model.Data{})
if err != nil {
fmt.Printf("error :%s",err.Error())
}
我们执行这个命令后,发现字符串类型为longText这万万不可啊,没关系,go提供了丰富的字段标签支持,帮助我们定义一个数据表
声明 model 时,tag 是可选的,GORM 支持以下 tag: tag 名大小写不敏感,但建议使用 camelCase 风格
| 标签名 | 说明 |
|---|---|
| column | 指定 db 列名 |
| type | 列数据类型,推荐使用兼容性好的通用类型,例如:所有数据库都支持 bool、int、uint、float、string、time、bytes 并且可以和其他标签一起使用,例如:not null、size, autoIncrement… 像 varbinary(8) 这样指定数据库数据类型也是支持的。在使用指定数据库数据类型时,它需要是完整的数据库数据类型,如:MEDIUMINT UNSIGNED not NULL AUTO_INCREMENT |
| size | 指定列大小,例如:size:256 |
| primaryKey | 指定列为主键 |
| unique | 指定列为唯一 |
| default | 指定列的默认值 |
| precision | 指定列的精度 |
| scale | 指定列大小 |
| not null | 指定列为 NOT NULL |
| autoIncrement | 指定列为自动增长 |
| autoIncrementIncrement | 自动步长,控制连续记录之间的间隔 |
| embedded | 嵌套字段 |
| embeddedPrefix | 嵌入字段的列名前缀 |
| autoCreateTime | 创建时追踪当前时间,对于 int 字段,它会追踪秒级时间戳,您可以使用 nano/milli 来追踪纳秒、毫秒时间戳,例如:autoCreateTime:nano |
| autoUpdateTime | 创建/更新时追踪当前时间,对于 int 字段,它会追踪秒级时间戳,您可以使用 nano/milli 来追踪纳秒、毫秒时间戳,例如:autoUpdateTime:milli |
| index | 根据参数创建索引,多个字段使用相同的名称则创建复合索引,查看 索引 获取详情 |
| uniqueIndex | 与 index 相同,但创建的是唯一索引 |
| check | 创建检查约束,例如 check:age > 13,查看 约束 获取详情 |
| <- | 设置字段写入的权限, <-:create 只创建、<-:update 只更新、<-:false 无写入权限、<- 创建和更新权限 |
| -> | 设置字段读的权限,->:false 无读权限 |
| - | 忽略该字段,- 无读写权限 |
| comment | 迁移时为字段添加注释 |
为了最大化复用字段,我们可能会用嵌套的方式,来表达一个数据,在Go里面也是支持嵌套的
这里补充一点官方没有提到的:tag怎么用233,事实上,gorm的tag是这么用的
package model
// data将会变成表名称
type Data struct {
ID uint `json:"id,omitempty" gorm:"primaryKey"`
// 都是用gorm标签,空格区分
Msg string `json:"msg,omitempty" gorm:"type:varchar(10) unique"`
}
以下来自官方文档
嵌入结构体
对于匿名字段,GORM 会将其字段包含在父结构体中,例如:
type User struct {
gorm.Model
Name string
}
// 等效于
type User struct {
ID uint `gorm:"primaryKey"`
CreatedAt time.Time
UpdatedAt time.Time
DeletedAt gorm.DeletedAt `gorm:"index"`
Name string
}
对于正常的结构体字段,你也可以通过标签 embedded 将其嵌入,例如:
type Author struct {
Name string
Email string
}
type Blog struct {
ID int
Author Author `gorm:"embedded"`
Upvotes int32
}
// 等效于
type Blog struct {
ID int64
Name string
Email string
Upvotes int32
}
并且,您可以使用标签 embeddedPrefix 来为 db 中的字段名添加前缀,例如:
type Blog struct {
ID int
Author Author `gorm:"embedded;embeddedPrefix:author_"`
Upvotes int32
}
// 等效于
type Blog struct {
ID int64
AuthorName string
AuthorEmail string
Upvotes int32
}
创建连接
如何创建一个数据库连接
我们使用大伙用的最多的数据库MySQL,
首先需要我们找一下mysql的驱动,gorm提供了mysql的驱动https://github.com/go-gorm/mysql
在你的项目路径里面,跑俩命令
go get -u gorm.io/gorm
go get -u gorm.io/driver/mysql
使用下面的命令创建一个数据库连接
// 参考 https://github.com/go-sql-driver/mysql#dsn-data-source-name 获取详情
dsn := "user:pass@tcp(127.0.0.1:3306)/dbname?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{})
现在我们获取到的这个db变量*gorm.DB类型,gorm与gin的风格类似,使用一个类完成所有可能的操作
CRUD
GORM有两种风格来运行sql,第一种风格为链式调用,第二种风格为原生sql
当然,链式调用更轻松,一般用这个就够了,
在初始化测试数据,清空表等场景,用原生sql更快,更直白
这里我只简单讲解重要的点,更多内容建议移步官方文档 https://gorm.io/zh_CN/docs/create.html
看完基础后,各位回来看看下面的问题
链式调用
GORM内部有很多api,Where,Order,Frist,Last,Find等等,
这些文件分为三大类:链式方法,Finisher方法,新建会话方法
我们先不管后面两个,先来看看调用链
调用链?
我们以Where进行举例
// Where add conditions
func (db *DB) Where(query interface{}, args ...interface{}) (tx *DB) {
tx = db.getInstance()
if conds := tx.Statement.BuildCondition(query, args...); len(conds) > 0 {
tx.Statement.AddClause(clause.Where{Exprs: conds})
}
return
}
从代码我们可以看出,首先获取db内部的tx对象,然后Where语句下一步是拼接出条件,然后调用db内部tx的AddClause()方法,将条件注册到内部的tx对象中,然后返回tx
那么这个tx是什么,getInstance是什么?
我们拿出get Instance的代码
func (db *DB) getInstance() *DB {
if db.clone > 0 {
tx := &DB{Config: db.Config, Error: db.Error}
if db.clone == 1 {
// clone with new statement
tx.Statement = &Statement{
DB: tx,
ConnPool: db.Statement.ConnPool,
Context: db.Statement.Context,
Clauses: map[string]clause.Clause{},
Vars: make([]interface{}, 0, 8),
}
} else {
// with clone statement
tx.Statement = db.Statement.clone()
tx.Statement.DB = tx
}
return tx
}
return db
}
从这段代码,我们可以看出来,如果clone大于0,将新建一个tx出来,这个tx就是DB类型的对象,然后判断是clone还是新建,新建的话就新建一个tx.Statement出来,而且新建的tx的clone为0
也就是说,我们使用open获得的db,是一个根DB,其clone值为1,在使用它时,它将创建新的DB,而创建出的新DB,其clone值为0,将继续使用下去
这里大家要注意的是,gorm底层其实还是sql的拼接,所以各位要注意sql语法
创建会话模式
在上面的分析中,我们发现当使用db创建一个新调用时,db内部的clone为1,然后会创建新的DB来给后面的语句操作
那么这个clone为1的语句是从哪里来的?
——创建会话模式
新初始化的 *gorm.DB 或调用 新建会话方法
我们点开gorm.Open(mysql.Open(dsn), &gorm.Config{})这个代码,
其中有一行代码为
db = &DB{Config: config, clone: 1}
ok,实锤了一个
还有就是新建会话方法,没毛病,都是clone值为1
// Session create new db session
func (db *DB) Session(config *Session) *DB {
var (
txConfig = *db.Config
tx = &DB{
Config: &txConfig,
Statement: db.Statement,
Error: db.Error,
clone: 1,
}
)
...
}
所以官网示范中,下面的语句
db, err := gorm.Open(sqlite.Open("test.db"), &gorm.Config{})
// db 是一个刚完成初始化的 *gorm.DB 实例,其属于 `新建会话模式`
tx := db.Where("name = ?", "jinzhu")
// `Where("name = ?", "jinzhu")` 是第一个被调用的方法,它创建了一个新的 `Statement` 并添加条件
tx.Where("age = ?", 18).Find(&users)
// `tx.Where("age = ?", 18)` 会复用上面的那个 `Statement`,并向其添加条件
// `Find(&users)` 是一个 finisher 方法,它运行注册的查询回调,生成并运行下面这条 SQL:
// SELECT * FROM users WHERE name = 'jinzhu' AND age = 18
tx.Where("age = ?", 28).Find(&users)
// `tx.Where("age = ?", 18)` 同样会复用上面的那个 `Statement`,并向其添加条件
// `Find(&users)` 是一个 finisher 方法,它运行注册的查询回调,生成并运行下面这条 SQL:
// SELECT * FROM users WHERE name = 'jinzhu' AND age = 18 AND age = 28;
注意: 在示例 2 中,第一个查询会影响第二个查询生成的 SQL,因为 GORM 复用了
Statement这可能会导致预期之外的问题,查看 协程安全 以避免该问题
这段话,就很轻松可以理解了。
协程安全
初次之外,文章还提到了协程安全,为什么这么说呢,协程安全,也就是其他语言里面的多线程安全,也就是说,没有锁,为什么呢?
——Where等语句操作的是db对象内部的tx对象,tx属于临界区,所以这是危险的。
然后在末尾补一句:
Order类似于order by 语句,Order后接First或者Last时,First或者Last的order失效
最近活多起来了,本次就先更到这里
后续:日志框架:logrus、zap -> 配置文件viper