标题## MapReduce@[toc]
Hadoop之MapReduce
MapReduce
入门
# MapReduce是hadoop体系下的一种计算模型(计算框架|编程框架),主要是用来对存储在hdfs上的数据进行统计,分析的。
MapReduce的核心思想
分而治之:大任务拆分小任务。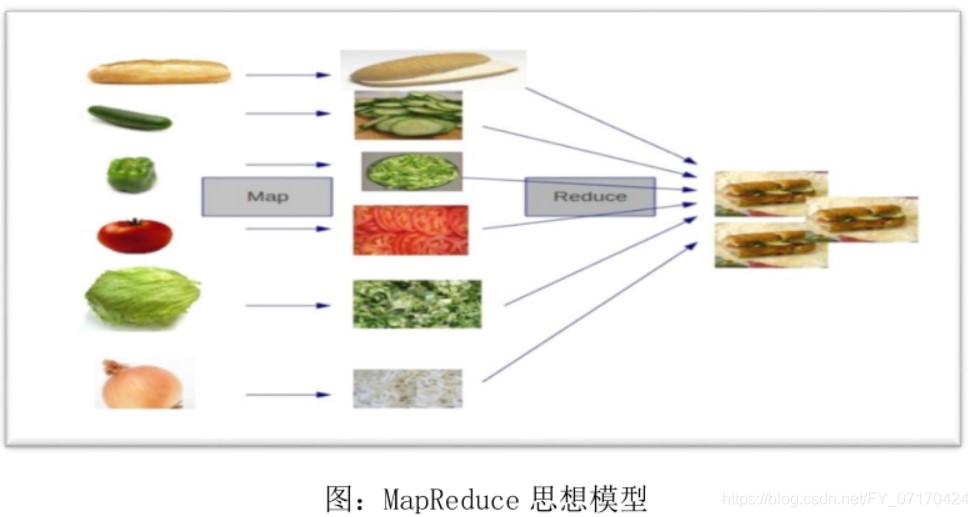
MapReduce计算
# 1. Job(一个大型任务)[Application](多个Map,一个Reduce)
一组MapReduce又统称为一个Job作业
# 2. Map(拆分后的小任务)
局部计算
# 3. Reduce(整合任务)
对局部计算结果进行汇总计算。
yarn框架(资源调度器)
# 作用(包工队)
资源调度,任务监控 主要用来整合hadoop集群中的资源(CPU 内存),进行统一调度 同时监控任务的执行情况
总结: 联合多个服务器节点的硬件,共同完成一个计算。突破单机服务器的计算能力。
# 组成部分
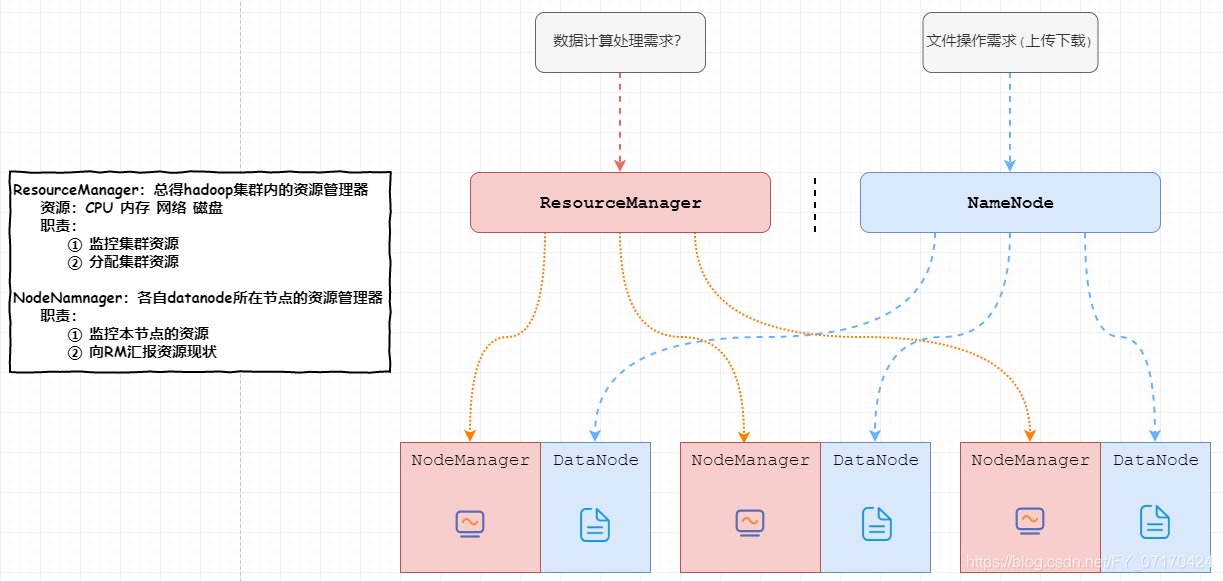
# 1. ResourceManager(包工头)
集群计算资源的管理器,也是yarn架构中的主节点。
功能:
1. 监控集群资源
2. 为计算分配资源。
# 2. NodeManager(干活的)
yarn集群计算资源的提供者,也是yarn架构中的从节点。
功能
1. 真正执行计算任务的节点。
2. 监控本节点的资源情况(CPU 内存 网络 硬盘),并通过心跳向RM汇报。
MapReduce特点
1. 易于编程:只需要使用hadoop接口进行编程,即可实现多台计算机分布式计算和分布式存储。
2. 高扩展性:存储空间不足或者计算能力不足,则可以添加计算机完成。
3. 容错性高:如果某个节点宕机,hadoop可以自动切换讲计算任务转移到其他节点上完成,不会影响计算结果。
4. 应用场景:PB级别以上海量数据的离线处理,无法实时处理和流失动态处理。(每日)
Yarn伪分布式搭建
# 准备单机的HDFS架构
验证:jps
[root@hadoop10 ~]# jps
2224 Jps
2113 SecondaryNameNode
1910 DataNode
1806 NameNode
关闭掉hdfs
stop-dfs.sh
# 初始化配置文件
1. mapred-site.xml
<!--配置yarn框架作为mapreduce的资源调度器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2. yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置resourcemanager的主机ip-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop10</value>
</property>
# 启动yarn集群
1. 启动HDFS集群
start-dfs.sh
2. 启动yarn集群
start-yarn.sh
# 验证
1. jps
[root@hadoop10 ~]# jps
6160 DataNode
6513 ResourceManager
6614 NodeManager
6056 NameNode
6349 SecondaryNameNode
6831 Jps
2. 访问yarn的资源调度器web网页。
http://ip:8088
Yarn集群搭建
# 0-1保证HDFS分布式集群搭建环境确保正确。
1. jps看到如下结果
NameNode
DataNode
SecondaryNameNode
2. 查看hadoop11:50070.
在datanode标签页看到3个正常的datanode节点信息。
# 0-2关闭所有NameNode节点和DataNode节点
stop-dfs.sh
# 1:初始化yarn相关配置
1. mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2. yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置resourcemanager的主机ip-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Hadoop</value>
</property>
# 2:同步该配置到其他节点服务器上。
scp -r /opt/install/hadoop2.9.2/etc/hadoop/mapred-site.xml root@hadoop12:/opt/install/hadoop2.9.2/etc/
scp -r /opt/install/hadoop2.9.2/etc/hadoop/mapred-site.xml root@hadoop12:/opt/install/hadoop2.9.2/etc/
# 3:启动yarn集群
1. 启动HDFS集群
start-dfs.sh
2. 启动yarn集群
start-yarn.sh
# 4:验证
1. jps
[root@hadoop11 ~]# jps
6160 DataNode
6513 ResourceManager
6614 NodeManager
6056 NameNode
6349 SecondaryNameNode
6831 Jps
2. 访问yarn的资源调度器web网页。
http://ip:8088
# 关闭集群
1. 先关闭yarn
stop-yarn.sh
2. 在关闭hdfs
stop-hdfs.sh
MapReduce编码
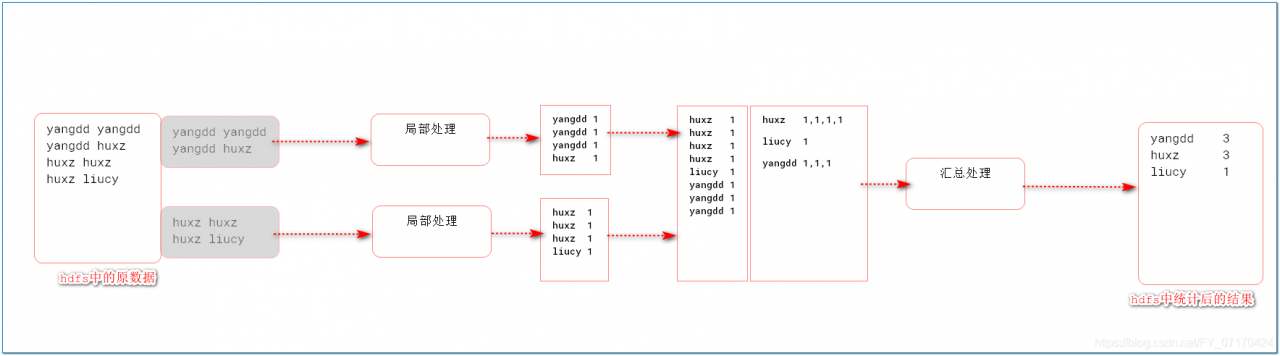
需求:统计该文件中,每个人名字出现多少次?(word count)

MapReduce2.0工作机制
# 数据变化(要干什么)
# 工作角色(谁来干)

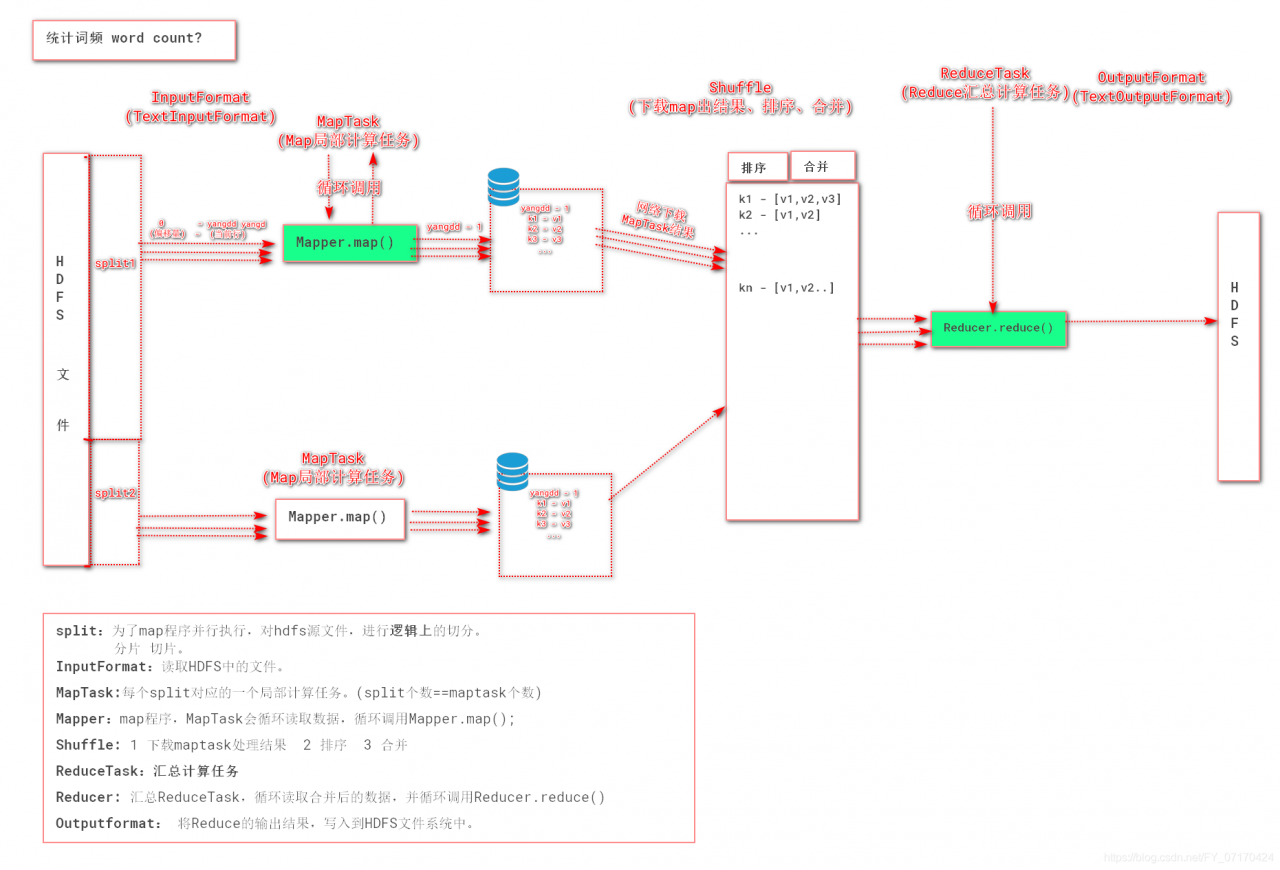
MapReduce-wordcount之工作流程详解

MapReduce数据流转机制!
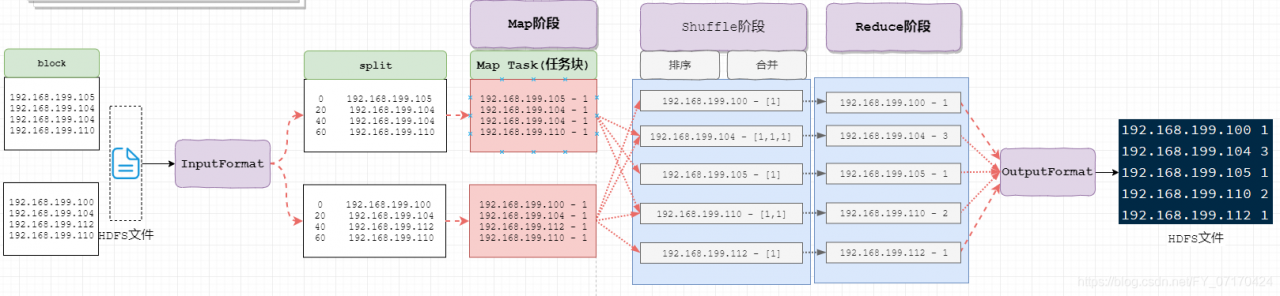
1. InputFormat(mr自动处理)
讲block文件转化成split,其中每条数据是key-value组成。
key是数据偏移量
value是每条数据
2. Map(程序员编码)
将split逐条输入给map,由map负责,对每条数据进行处理,转化为keyOut-valueOut
3. Shuffle(MR的默认处理器)
对map输出的每条数据的key-value进行排序,分组。
4. Reduce(程序员编码)
对Shuffle分组后的数据的key-value进行处理,转化为新的key-value。
5. OutputFormat
讲reduce产生的数据,存储HDFS文件系统中
MR编码准备
# 1.导入pom依赖
<!--hadoop公共依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<!--hadoop hdfs 依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--map reduce-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.9.2</version>
</dependency>
# 2.导入log4j配置文件
MR编码
# 编写map程序
package demo1.map;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
* KEYIN:map输入的key 偏移量
*VALUEIN:map输入的value 一行字符串即传入的一行数据
* KEYOUT:map输出的名字 name 由字符串分割而得到 str
* VALUEOUT:map输出的次数 name 由字符串分割而得到 int
* */
public class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable> {
/**
*
* @param key map输入的key 偏移量
* @param value map输入的value 一行字符串即传入的一行数据
* @param context 输出的keyout和 valueout
* @throws IOException
* @throws InterruptedException
*/
/*
map局部计算执行代码
context.write(keyout valueout)
* */
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.拆分字符串valuein
String[] names = value.toString().split(" ");
//这是只拆分两个的情况
//2.将name作为key,将1作为value
//String keyout1 = names [0];
//String keyout2 = names [1];
//3.context.write(name,value)
//context.write(new Text(keyout1),new IntWritable(1));
//2与3正确做法应该遍历
for (String name : names) {
context.write(new Text(name),new IntWritable(1));
}
}
}
# 编写reduce程序
package demo1.reduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
keyin:reduce输入的key name str
valuein:reduce输入的value,value的每个元素类型 ,次数 int
keyout:reduce输入的key name str
valueout:reduce输入的value,累加后的次数sum int
*/
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
*
* @param key reduce输入的name
* @param values reduce输入的次数的集合
* @param context
* @throws IOException
* @throws InterruptedException
*/
/*
汇总计算的代码
context.write(keyout,valueout)
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//1.将value集合中的值累加 int
int sum = 0;
for (IntWritable value : values) {
int v = value.get();
sum+=v;
}
//2.将 name-次数之和 输出
context.write(key,new IntWritable(sum));
}
}
# 编写job程序
ackage demo1.job;
import demo1.map.WordCountMap;
import demo1.reduce.WordCountReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/*
* 整合map-reduce过程
* */
public class WordCountJob {
public static void main(String[] args) throws Exception {
//1.配置hdfs的数据读取入口
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
//2.创建一个job=input -map -shuffle -reduce -output
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJob.class); //指定当前job类名
//3.设置map阶段(input map类 输出的key类型 输出的value类型)
job.setMapperClass(WordCountMap.class); //设置mapper类
job.setMapOutputKeyClass(Text.class); //设置mapper输出的key的类型
job.setMapOutputValueClass(IntWritable.class); //设置mapper输出的value的类型
TextInputFormat.addInputPath(job,new Path("/hdfs/wordcount.txt"));
//4.设置reduce阶段 (output reduce类 输出的key类型 输出的value类型 )
job.setReducerClass(WordCountReduce.class); //设置reducer类
job.setOutputKeyClass(Text.class); //设置reduce输出的key的类型
job.setOutputValueClass(IntWritable.class); //设置reduce输出的value的类型
//注意事项:输出的目录不允许存在,只能mr自己创建
TextOutputFormat.setOutputPath(job,new Path("/hdfs/mrout1"));
//5.启动job
boolean b = job.waitForCompletion(true);
System.out.println(b);
}
}
# 注意事项:本地直接运行(测试环境)
使用本地的方式提交任务,需要HDFS开启写入文件的权限。
hdfs dfs -chmod -R 777 /hdfs
MapReduce核心api
- Split:为了map程序并行执行,对hdfs源文件进行逻辑上的划分。分片 切片。
- InputFormat:读取HDFS中文件,(TextInputFormat)逐行读取(k-v,偏移量-内容)。
- MapTask:每个Split对应的一个Map局部计算任务。(循环调用map方法,split个数==maptask个数)。
- Mapper:map程序,MapTask会循环读取数据,循环调用Mapper.map();
- Shuffle:下载多个MapTask处理结果、排序、合并
- ReduceTask:Reduce汇总计算任务。
- Reduce:汇总ReduceTask,循环读取合并后的数据,并循环调用Reduce.reduce方法)直至读完。
- OutputFormat:将Reduce的输出结果,写入到HDFS文件系统中。
Mapreduce补充细节
Hadoop的MapReduce适合做大数据的离线处理,不适合做实时处理。
mapreduce的sort排序,无法取消。
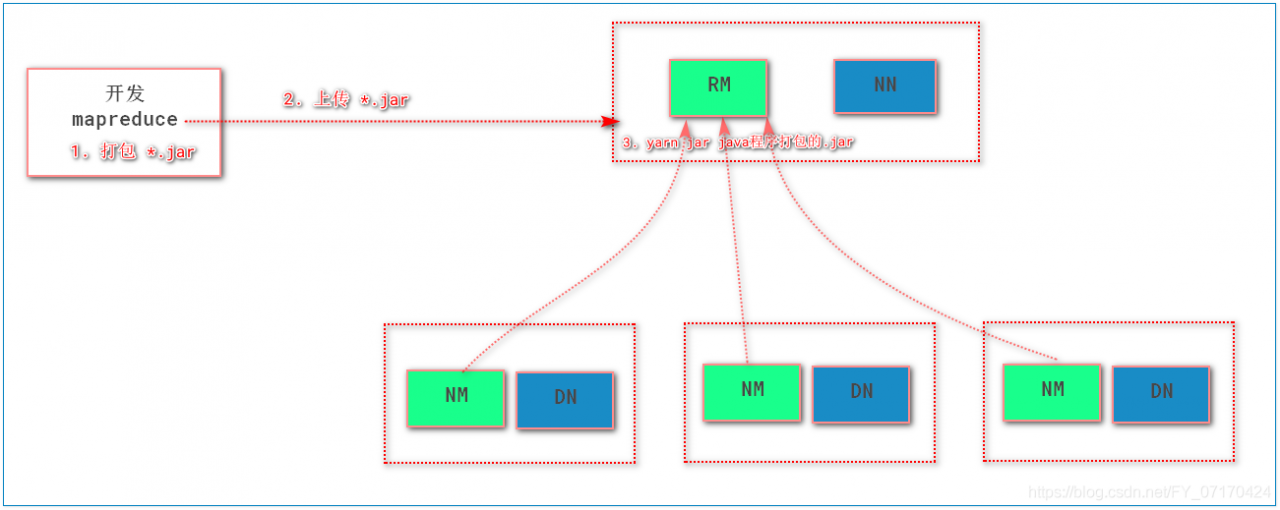
生产中提交MR任务1(生产环境中)
# 1.打包
# 设置maven的打包的环境
①指定打包方式
<packaging>jar</packaging>
②指定maven使用的编码格式
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
③配置maven的plugin
指定jar的主函数的类
指定编译的jar的文件名
<configuration>
<archive>
<!--指定入口主函数所在的类名-->
<manifest>
<mainClass>demo1.job.WordCountJob</mainClass>
</manifest>
</archive>
</configuration>
<!--指定编译的文件名-->
<finalName>wordcount1</finalName>
<properties>
<!--解决编码的GBK的问题-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<build>
<!--指定打包的jar的名字-->
<finalName>mr1</finalName>
<!--指定打包的信息-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<!--指定入口主函数所在的类名-->
<manifest>
<mainClass>demo1.job.WordCountJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
# 2. 执行打包
在当前项目所在的目录下执行如下命令
> mvn clean 清空缓存
> mvn package 打包
# 3. 上传jar到hadoop的ResourceManager所在的机器
# 4. 执行程序
> yarn jar mr1.jar
注意事项:此次运行遇到一个小问题,jdk版本运行错误。
windows的jdk版本与linux的jdk版本最好一样无差别,可能会报错。
maven自动化部署插件wagon-远程上传(自动上传jar包)
1. 配置maven远程提交插件
a. 添加maven的ssh扩展
b. 添加maven的远程拷贝插件wagon(货车)
<!--加入maven的扩展ssh-->
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<!--maven的远程拷贝插件-->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<!--上传的本地jar的位置-->
<fromFile>target/${project.build.finalName}.jar</fromFile>
<!--远程拷贝的地址-->
<url>scp://root:root@192.168.153.10:/opt/app</url>
</configuration>
</plugin>
2. 添加远程执行命令,和参数。
# 清空
mvn clean
# 打包本地jar
mvn package
# 远程上传jar
mvn wagon:upload-single
3. 远程执行命令
# 如下内容在wagon的插件中添加
<!--maven的远程拷贝插件-->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<!--上传的本地jar的位置-->
<fromFile>target/${project.build.finalName}.jar</fromFile>
<!--远程拷贝的地址-->
<url>scp://root:root@192.168.153.10:/opt/app</url>
<!--上传后执行的linux命令-->
<commands>
<!--执行的命令-->
<command>nohup /opt/installs/hadoop2.9.2/bin/yarn jar /opt/app/${project.build.finalName}.jar > /opt/logs/mr.out 2>&1 &</command>
</commands>
<!--是否显示命令执行结果-->
<displayCommandOutputs>true</displayCommandOutputs>
</configuration>
</plugin>
4. 执行命令
a. 清空
mvn clean
b. 打包
mvn package
c. 上传
mvn wagon:upload-single
d. 执行
mvn wagon:sshexec
nohup命令简介
| 命令参数 | 含义 |
|---|---|
| nohup | no hang up 命令执行后,要持续一段时间,不要挂断。 |
| &(结尾) | 最后的&表示nohup命令的结尾。 |
| 2>&1 | 错误和输出都重定向写入到前面的文件中。 |

其中&要用(&)来替换转义
# maven和wagon 命令汇总
`注意,mvn命令需要在项目的pom.xml所在的目录执行`
1. 清空
mvn clean
2. 打包
mvn package
3. 上传
mvn wagon:upload-single
4. 执行
mvn wagon:sshexec
配置Mapreduce的历史日志服务器
HistoryServer:
专门自动记录每个job运行产生的日志信息。
会将日志文件放在hdfs文件系统中。
总结:集中管理hadoop集群中job的执行日志
注意:yarn集群的启动不会自动启动historyserver。
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录
比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。
默认未启动。
配置HistoryServer:
# 1. 配置mapred-site.xml,指定历史日志服务器的服务地址(接受日志信息)
<!--job历史日志服务器的服务地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop10:10020</value>
</property>
<!--job的历史日志服务器的web地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop10:19888</value>
</property>
# 2. 配置yarn-site.xml,指定开启日志聚合和日志保留时间
<!--开启日志聚合-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保存时间 单位秒 这里是7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
启动historyserver
1.启动hdfs
2.启动yarn
3.启动historyserver
如果启动了需要重启yarn,重新加载mapred和yarn的配置文件
# 3. 启动历史日志服务器
1. 重启yarn
[root@hadoop10 ~]# stop-yarn.sh
[root@hadoop10 ~]# stop-dfs.sh
[root@hadoop10 ~]# start-dfs.sh
[root@hadoop10 ~]# start-yarn.sh
2. 启动
[root@hadoop10 ~]# mr-jobhistory-daemon.sh start historyserver
如果需要关闭执行如下命令
[root@hadoop10 ~]# mr-jobhistory-daemon.sh stop historyserver
# 4. 查看日志
1. 访问http://ip:8088(访问yarn集群,看到执行过的job信息)
2. 点击"Applications"找到刚才执行的job的"history"
3. 点击logs


MapReduce详解
JAVA序列化:
保存java对象:数据+描述信息(类,方法,继承关系…)
1.JVM内存中java对象通过IO输出流,输出到硬盘上。(对象的序列化)
2.JVM从硬盘上,通过IO输入流,读取对象信息,并形成一个java对象。(对象的反序列化)
结论:通过流传输对象时候,对象需要经过序列化。将对象–>字节–>对象
JAVA序列化(重量级):数据+描述信息【校验信息、继承关系、语法】
Hadoop序列化
ReduceTask汇总MapTask的处理结果的key-value,需要使用网络从MapTask节点机器,下载key-value数据。
key-value从MapTask-->ReduceTask需要经过序列化和反序列化的过程。
序列化方案:
1.Java序列化,重量级,除了数据还有大量其他的描述信息。
导致较大的网络开销。
2.Hadoop序列化:序列化、反序列化仅关注属性值(数据)
轻量级,网络开销小,性能好。
reduce在反序列化数据的时候,只创建一次对象即可。
结论:MapReduce中所有key-value都要支持序列化(即传输的数据)
# hadoop序列化
mapreduce执行过程中,被处理的key-value数据,需要在网络中传输,就需要对象转化为字节,字节转化为对象,这就是序列化和反序列化过程;
key和value都要经过序列化传输。
1. Java序列化(序列化数据+对象描述信息)
序列化会包含java的继承关系,验证信息,验证信息。(重量级)
不便于在网络中传输。
2. Hadoop序列化(仅关注数据序列化)
空间紧凑
传输快速,网络开销小。
对象重用(反序列化的时候,只创建一个)
结论:
mapreduce中所有key-value都要支持序列化。

hadoop内置可序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| long | LongWritable |
| float | FloatWritable |
| double | DoubleWritable |
| string | Text |
| array | ArrayWritable |
| map | MapWritable |
| null | NullWritable |
案例数据
手机使用的流量数据,每次手机上网记录一条信息。
需求:统计每个手机号的 上传总流量 下载总流量 总流量
分析核心点:
希望那些数据相同的合并在一起,map端就以它为key输出即可。
# 案例数据
id 手机号 ip地址 上传 下载 状态码
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
# 期望结果
13726230503 上传流量:4962 下载流量:49362 总数据流量: 54324
13826544101 上传流量:528 下载流量:0 总数据流量: 528
13926251106 上传流量:480 下载流量:0 总数据流量: 480
13926435656 上传流量:264 下载流量:3024 总数据流量: 3288
# 自定义序列化类型
自定义一个类实现WritableComparable
1. 可以被hadoop序列化传输。
2. 可以支持排序。
public class XxxxWritable implements WritableComparable<XxxxWritable> {
private String id;
private String name;
private String date;
有参数和无参构造方法 //反序列化要调用无参构造方法。
get和set方法
toString方法 //输出到文件的时候,默认按照tostring形式输出。
compareTo方法 //接口必须实现,在shuffle排序阶段要使用。
write方法 //接口方法,map和reduce中间需要通过网络发送该对象数据。
readField方法 //接口方法,讲网络输出来的对象数据读取到,并复制给该对象。
注意序列化和反序列化的属性操作顺序要完全一致
//序列化示例代码
package demo2;
import org.apache.hadoop.io.WritableComparable;
import org.apache.log4j.Logger;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class PhoneLogWritable implements WritableComparable<PhoneLogWritable> {
private Logger log = Logger.getLogger(PhoneLogWritable.class);
private int upload;
private int download;
private int sum;
public PhoneLogWritable(){
log.info("---------对象创建-----------");
}
public PhoneLogWritable(int upload, int download, int sum) {
this.upload = upload;
this.download = download;
this.sum = sum;
}
@Override
public int compareTo(PhoneLogWritable o) {
//比较对象大小
return 0;
}
/**
* 将对象转换为字节进行传输,需要调用
* @param dataOutput
* @throws IOException
*/
@Override
public void write(DataOutput dataOutput) throws IOException {
log.info("---------write-----------");
//将对象属性交给dataoutput写出
dataOutput.writeInt(upload);
dataOutput.writeInt(download);
dataOutput.writeInt(sum);
}
/**
* 将从网络读取到的字节,转换为对象的数据
*
* 注意:
* 1.反序列化的顺序要和序列化顺序完全一致
* 2.反序列化回的数据赋值给对象的属性
* @param dataInput
* @throws IOException
*/
@Override
public void readFields(DataInput dataInput) throws IOException {
log.info("---------readFields-----------");
upload = dataInput.readInt();
download = dataInput.readInt();
sum = dataInput.readInt();
}
public int getUpload() {
return upload;
}
public void setUpload(int upload) {
this.upload = upload;
}
public int getDownload() {
return download;
}
public void setDownload(int download) {
this.download = download;
}
public int getSum() {
return sum;
}
public void setSum(int sum) {
this.sum = sum;
}
}
数据清洗
# 数据清洗:
思路:将数据交给mapTask,逐条验证,将符合条件的数据输出。
不需要做任何合并和汇总(取消reduce,输出数据作为value,map输出的key设计为null)
# mapreduce中可以没有reduce
map阶段首先判断是否符合要求
如果不符合,则不输出
若符合就获取手机号、上传量、下载量
清洗后的数据:key-value
null-value(清洗后的数据)
不需要reduce清洗后直接输出
效果:之进行map阶段的执行。执行完毕后即输出到文件中。
# 代码实现
1. 取消mapreduce的job有关reduce的所有设置
2. 保留并设置如下
job.setNumReduceTasks(0);//取消reduce
TextOutputFormat.setOutputPath(job,new Path("hdfs路径"));
# 原数据
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157995052 13826544109 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0
1363157995052 null 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 240 0 200
1363157991076 13926435659 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 null null null
# 案例结果
删除其中手机号不符合要求,上传流量确实和下载流量确实的数据,并仅保留手机号 上传流量 下载流量。(效果如下)
13726230503 2481 24681
13826544101 264 0
13926435656 132 1512
13926251106 240 0
13726230503 2481 24681
13826544101 264 0
13926435656 132 1512
13926251106 240 0
代码如下:
package demo3;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogCleanMap extends Mapper<LongWritable, Text, NullWritable,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// map阶段首先判断是否符合要求
String[] lines = value.toString().split("\t");
boolean ok = checkLinne(lines);
// 如果不符合,则不输出
// 若符合就获取手机号、上传量、下载量
if(ok){
//获取手机号 上传 下载
String mobile = lines[1];
String upload = lines[6];
String download = lines[7];
context.write(NullWritable.get(),new Text(mobile+"\t"+upload+"\t"+download));
} else{
//不符合要求的行数据 不需要处理不写就可以
}
// 清洗后的数据:key-value
// null-value(清洗后的数据)
// 不需要reduce清洗后直接输出
}
private boolean checkLinne(String[] lines) {
//1.判断lines数组长度是否小于9
if (lines.length < 9) {
return false;
}
//2.判断手机号是否不是是11位
if (lines[1].equals("") || lines[1].equals("null") || lines[1].trim().length() != 11) {
return false;
}
//3.判断上传流量是否是“” null
if (lines[6].equals("") || lines[6].equals("null")) {
return false;
}
//4.判断上传流量是否是“” null
if (lines[7].equals("") || lines[7].equals("null")) {
return false;
}
return true;
}
}
package demo3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Job3 {
public static void main(String[] args) throws Exception {
//1.创建hdfs入口
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
//2.创建job
Job job = Job.getInstance(conf);
job.setJarByClass(Job3.class);
//3.设置Map程序相关信息(InputFormat读取文件路径 mapper类 输出的key value 类型)
job.setMapperClass(LogCleanMap.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
TextInputFormat.addInputPath(job,new Path("/hdfs/clean.log"));
//4.设置跳过reduce
//设置reduce为0
job.setNumReduceTasks(0);
//设置输出文件
TextOutputFormat.setOutputPath(job,new Path("/hdfs/mrout6"));
//5.启动job
job.waitForCompletion(true);
}
}
计数器Counter
用来记录hadoop执行过程的工具,可以理解为hadoop的日志。
# 形式 group1 name1 数量# 代码 context.getCounter("map阶段","map输出").increment(1L); context.getCounter("map阶段","map输出").increment(1L); # 效果如下

测试案列:
package demo3;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogCleanMap extends Mapper<LongWritable, Text, NullWritable,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// map阶段首先判断是否符合要求
String[] lines = value.toString().split("\t");
boolean ok = checkLinne(lines);
// 如果不符合,则不输出
// 若符合就获取手机号、上传量、下载量
if(ok){
//获取手机号 上传 下载
String mobile = lines[1];
String upload = lines[6];
String download = lines[7];
context.write(NullWritable.get(),new Text(mobile+"\t"+upload+"\t"+download));
context.getCounter("map清洗","有效数据").increment(1L);
} else{
//不符合要求的行数据 不需要处理不写就可以
context.getCounter("map清洗","无效数据").increment(1L);
}
// 清洗后的数据:key-value
// null-value(清洗后的数据)
// 不需要reduce清洗后直接输出
}
private boolean checkLinne(String[] lines) {
//1.判断lines数组长度是否小于9
if (lines.length < 9) {
return false;
}
//2.判断手机号是否不是是11位
if (lines[1].equals("") || lines[1].equals("null") || lines[1].trim().length() != 11) {
return false;
}
//3.判断上传流量是否是“” null
if (lines[6].equals("") || lines[6].equals("null")) {
return false;
}
//4.判断上传流量是否是“” null
if (lines[7].equals("") || lines[7].equals("null")) {
return false;
}
return true;
}
}
测试结果: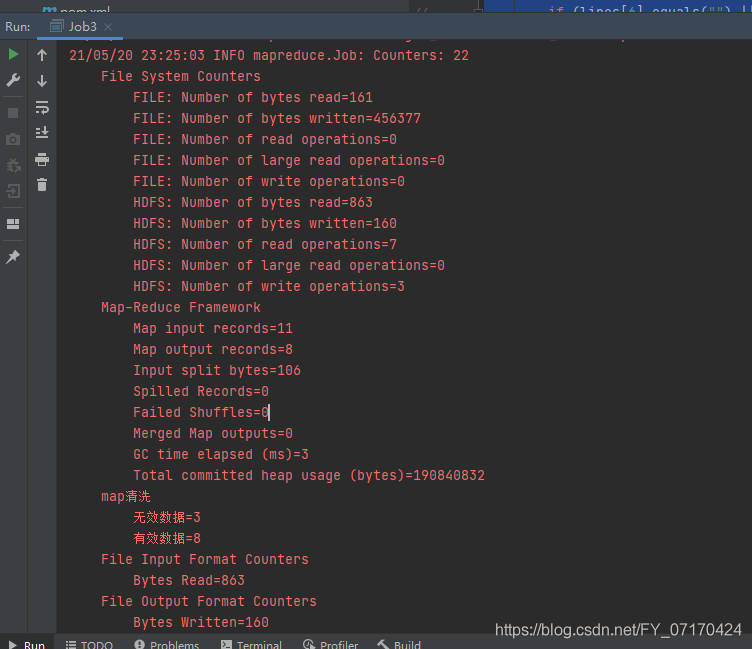
直播数据案列
源文件:
1001 2020年4月7日 234 100 20000 12341
1002 2020年4月7日 345 200 1234 34568
1003 2020年4月7日 897 300 23456 67894
1003 2020年4月9日 null null null 13457
1001 2020年4月8日 923 784 567 10000
1003 2020年4月8日 456 213 1234 57134
1004 2020年4月8日 453 345 56789 45684
1005 2020年4月9日 null null 23456
1001 2020年4月9日 567 456 23457 74123
1002 2020年4月9日 958 567 8975 785634
null 2020年4月9日
1003 2020年4月9日 null null 8778
输出文件:
id 热度 人数 总时间 总时长
1001 234 100 20000 12341
1002 345 200 1234 34568
1003 897 300 23456 67894
1001 923 784 567 10000
1003 456 213 1234 57134
1004 453 345 56789 45684
1001 567 456 23457 74123
1002 958 567 8975 785634
代码如下:
package demo1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CleanMapper extends Mapper<LongWritable, Text, NullWritable,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.接收数据
String[] vs = value.toString().trim().split("\t");
//2.验证value是否符合条件
boolean b = check(vs);
//3.将符合条件的输出(k--null v-清洗后的数据)
if(b){
String v = vs[0]+"\t"+vs[2]+"\t"+vs[3]+"\t"+vs[4]+"\t"+vs[5];
context.write(NullWritable.get(),new Text(v));
}
}
private boolean check(String[] vs) {
//0.验证是否有6个字段
if(vs.length<6){
return false;
}
//1.验证主播ID是否是“” ”null“
if(vs[0].equals("") || vs[0].equals("null")){
return false;
}
//2.验证热度、观众人数 打赏金额 时长
if(vs[2].equals("") || vs[2].equals("null")){
return false;
}
if(vs[3].equals("") || vs[3].equals("null")){
return false;
}
if(vs[4].equals("") || vs[4].equals("null")){
return false;
}
if(vs[5].equals("") || vs[5].equals("null")){
return false;
}
//3.符合条件的数据返回true
return true;
}
}
package demo1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class CleanTestJob1 {
public static void main(String[] args) throws Exception {
//1.连接hdfs
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
//2.创建job
Job job = Job.getInstance(conf,"");
job.setJarByClass(CleanTestJob1.class);
//3.设置mapper
job.setMapperClass(CleanMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
//TextInputFormat.addInputPath();
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job,new Path("/hdfs/liveplay.log"));
//4.设置跳过reduce
job.setNumReduceTasks(0);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job,new Path("/hdfs/livemrout"));
//5.启动job
boolean q = job.waitForCompletion(true);
System.out.println(q);
}
}
直播案列排序
要求输出:
1001 1724 1340 96464 71
1002 1303 767 820202 1069
1003 1353 513 125028 243
1004 453 345 45684 132
案列代码:
package demo2;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LivePlayMapper extends Mapper<LongWritable, Text,Text,LivePlayWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] vs = value.toString().trim().split("\t");
//1.获得主播id作为key
String id = vs[0];
//2.获得主播的hot viewer length 作为value封装成一个对象
LivePlayWritable lpw = new LivePlayWritable(Integer.parseInt(vs[1].trim()), Integer.parseInt(vs[2].trim()), Integer.parseInt(vs[4].trim()));
//3.输出
context.write(new Text(id),lpw);
}
}
package demo2;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Objects;
public class LivePlayWritable implements WritableComparable<LivePlayWritable> {
private int hot;
private int viewer;
private long length;
//无参
public LivePlayWritable(){
}
//有参
public LivePlayWritable(int hot, int viewer, long length) {
this.hot = hot;
this.viewer = viewer;
this.length = length;
}
//排序
@Override
public int compareTo(LivePlayWritable o) {
return 0;
}
// 热度 人数 总时长
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(hot);
dataOutput.writeInt(viewer);
dataOutput.writeLong(length);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
hot = dataInput.readInt();
viewer = dataInput.readInt();
length = dataInput.readLong();
}
//equals
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
LivePlayWritable that = (LivePlayWritable) o;
return hot == that.hot && viewer == that.viewer && length == that.length;
}
@Override
public int hashCode() {
return Objects.hash(hot, viewer, length);
}
//getter setter
public int getHot() {
return hot;
}
public void setHot(int hot) {
this.hot = hot;
}
public int getViewer() {
return viewer;
}
public void setViewer(int viewer) {
this.viewer = viewer;
}
public long getLength() {
return length;
}
public void setLength(long length) {
this.length = length;
}
}
package demo2;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LivePlayReducer extends Reducer<Text,LivePlayWritable,Text,Text> {
@Override
protected void reduce(Text key, Iterable<LivePlayWritable> values, Context context) throws IOException, InterruptedException {
//1.获得key 主播id
String id = key.toString();
//2.获得合并后的values,遍历累加hot viewer length
int hotsum = 0;
int viewersum = 0;
long lengthsum = 0L;
for (LivePlayWritable value : values) {
hotsum+=value.getHot();
viewersum+=value.getViewer();
lengthsum+=value.getLength();
}
//3.计算平均时长 lengthsum/viewersum
long avglength = lengthsum/viewersum;
//4.输出结果
String v = hotsum+"\t"+viewersum+"\t"+lengthsum+"\t"+avglength;
context.write(new Text(id),new Text(v));
}
}
package demo2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class LiveJob {
public static void main(String[] args) throws Exception {
//1.hdfs
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
//2.job
Job job = Job.getInstance(conf);
job.setJarByClass(LiveJob.class);
//3.map
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(LivePlayMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LivePlayWritable.class);
FileInputFormat.addInputPath(job,new Path("/hdfs/livemrout/part-m-00000"));
//4.reduce
job.setReducerClass(LivePlayReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job,new Path("/hdfs/mrout8"));
//5.启动
boolean b = job.waitForCompletion(true);
System.out.println(b);
}
}
默认排序
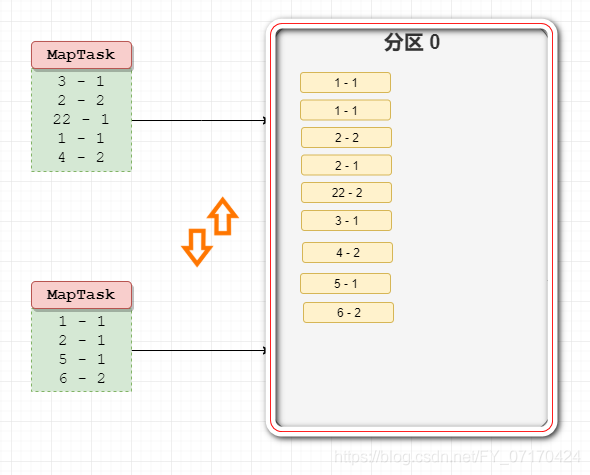
Mapreduce排序:
# 简介
在Shuffle阶段,对map输出的key进行排序。(map输出的key会排序)
# 发生时机
a.MapTask到其输出会有一个局部排序。会在map输出后,存在结果到本地临时位置之前,就会对局部mapTask处理的数据的key提前进行排序。(为了减轻shuffle压力提高合并效率)。
b.shuffle汇总所有map输出结果,会进行归并排序(合并多个mapTask)。(为了合并效率高)
ReduceTask接受数据交给reducer之前,会对数据进行排序。
# 3. 规则:
1. key如果是Text类型按照字典顺序,进行字符串排序。
2. key如果是IntWritable LongWritable 则按照数字大小进行升序排序。
# 测试数据
用户id 观众人数
团团 300
小黑 200
哦吼 400
卢本伟 100
八戒 250
悟空 100
唐僧 100
# 需求:按照观众人数升序排序?
# 结果如下
唐僧 100
悟空 100
卢本伟 100
小黑 200
八戒 250
团团 300
哦吼 400
代码如下:
package demo4;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//给谁排序就以谁为key
public class SortMap1 extends Mapper<LongWritable, Text, IntWritable,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将接受的value中的人数作为key 名字作为value
String[] vs = value.toString().trim().split("\t");
String name = vs[0];
int viewers = Integer.parseInt(vs[1]);
context.write(new IntWritable(viewers),new Text(name));
}
}
package demo4;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* map输出key (人数) -value(名字)
*
* reduce接收
* 输入:人数-[name1 name2]
* 输出:name1 - 人数
* name2 - 人数
*
*/
public class SortReduce1 extends Reducer<IntWritable, Text,Text,IntWritable> {
/**
*
* @param key 100 200
* @param values [卢本伟 唐僧 悟空] 小黑
* @param context 卢本伟 100
* 唐僧 100
* 悟空 100
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
//value-当前已经拍好序的key 对应的人名
String name = value.toString();
int viewers = key.get();
context.write(new Text(name),new IntWritable(viewers));
}
}
}
package demo4;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Job4 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(Job4.class);
job.setMapperClass(SortMap1.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
TextInputFormat.addInputPath(job,new Path("/test/sort.txt"));
job.setReducerClass(SortReduce1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("/test/mtsor"));
job.waitForCompletion(true);
}
}
自定义排序
# 自定义排序
用户id 观众人数 直播时长
团团 300 1000
小黑 200 2000
哦吼 400 7000
卢本伟 100 6000
八戒 250 5000
悟空 100 4000
唐僧 100 3000
# 需求:按照观众人数降序排序,如果观众人数相同,按照直播时长降序
结果如下:
哦吼 400 7000
团团 300 1000
八戒 250 5000
小黑 200 2000
卢本伟 100 6000
悟空 100 4000
唐僧 100 3000
# 自定义排序核心思路:
1. 排序所依据的字段,要作为key。
2. 因为根据两个值,所以实现hadoop的序列化。
# 重写WritableComparable的compareTo方法
# 代码如下
package demo5;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1.可序列化 (write readFiled)
* 2.可排序 (compareTo)
*/
public class LivePlayLog implements WritableComparable<LivePlayLog> {
private int viewers;
private long length;
public LivePlayLog(){}
public LivePlayLog(int viewers, long length) {
this.viewers = viewers;
this.length = length;
}
/**
* 此次的排序做的事情
* 作用:1.mapreduce执行过程中,排序时候回调用该方法 排序的字段必须将对象作为输出的key
* 2.默认在合并操作时,会将key相同的value合并在一起
* 返回值为1 升序排序(this -> o)
* 返回值为-1 降序排序
* 返回值为0 相同的
* @param o
* @return
*/
@Override
public int compareTo(LivePlayLog o) {
if(this.viewers!=o.viewers){
return -(this.viewers-o.viewers);
} else if (this.length!=o.length) {
return -(int)(this.length-o.length);
}else {
return 0;
}
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(viewers);
dataOutput.writeLong(length);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
viewers = dataInput.readInt();
length = dataInput.readLong();
}
public int getViewers() {
return viewers;
}
public void setViewers(int viewers) {
this.viewers = viewers;
}
public long getLength() {
return length;
}
public void setLength(long length) {
this.length = length;
}
// 如梭该对象输出到文件中,会调用toString方法
@Override
public String toString() {
return viewers+"\t"+length;
}
}
package demo5;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* keyout LivePlayLog
* valueout 主播idText
*/
public class SortMap2 extends Mapper<LongWritable,Text,LivePlayLog,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] vs = value.toString().trim().split("\t");
String id = vs[0];
String viewers = vs[1];
String length = vs[2];
//封装key(viewers+length)
LivePlayLog livePlayLog = new LivePlayLog(Integer.parseInt(viewers.trim()), Long.parseLong(length.trim()));
context.write(livePlayLog,new Text(id));
}
}
package demo5;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
*keyin:liveplaylog(viewer length)
* valuein:id
* keyout:id
* valueout:viewer length
*/
public class SortReduce2 extends Reducer<LivePlayLog, Text,Text,LivePlayLog>{
@Override
protected void reduce(LivePlayLog key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
//将主播id viewers length输出到文件中
context.write(value,key);
}
}
}
package demo5;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class Job5 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
Job job = Job.getInstance(conf);
job.setMapperClass(SortMap2.class);
job.setMapOutputKeyClass(LivePlayLog.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job,new Path("/test/sort.txt"));
job.setReducerClass(SortReduce2.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LivePlayLog.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job,new Path("/test/sort2"));
job.waitForCompletion(true);
}
}
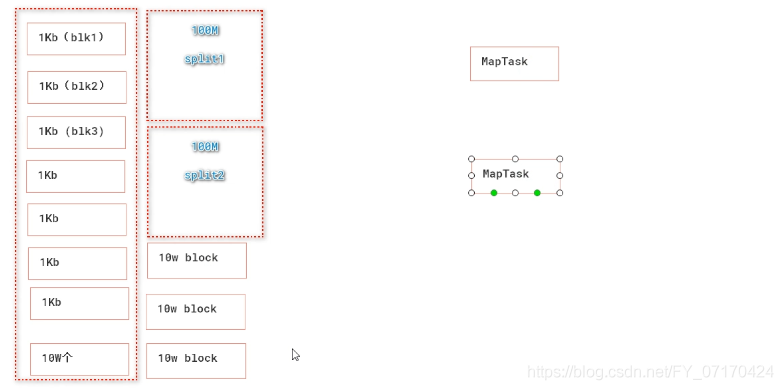
MapTask局部计算并行度(优化1)
MapTask局部计算并行度初识
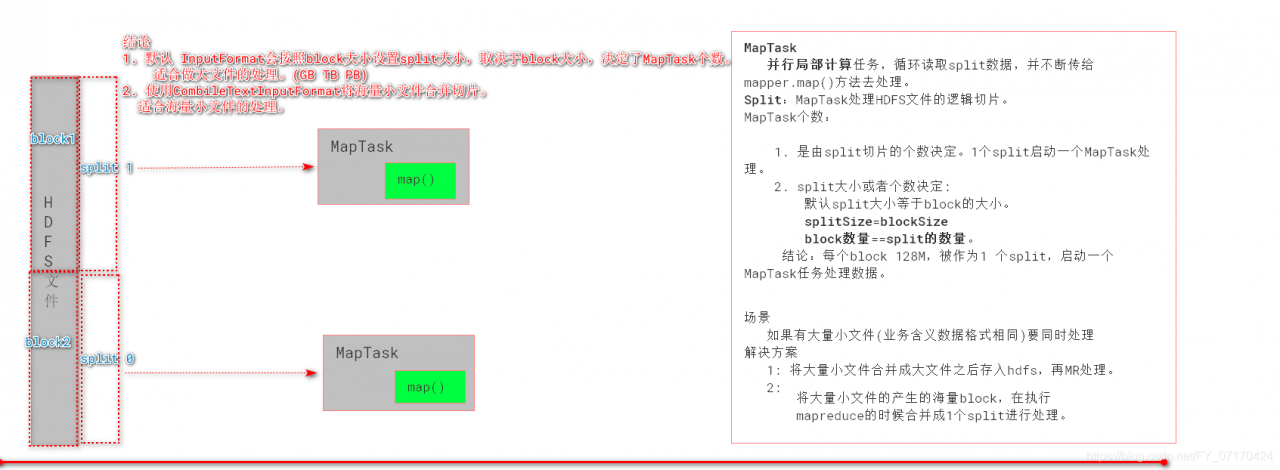
# MapTask:
局部计算任务,循环读取split数据,并不断地传给mapper.map()方法去处理。
# Split:
MapTask处理HDFS文件的逻辑切片。
# MapTask个数:
默认情况下MapTask个数应该和split个数相等即
1.是由split切片的个数决定。一个split启动一个MapTask处理。
# split大小或者个数由谁决定?
2.默认split大小等于block大小。
3.splitSize==blockSize。
4.block数量==split的数量。
# 结论:
MapTask个数由split个数和splitSize决定。
每个block 128M,被作为一个split,启动一个MapTask人数处理数据。
MapTask局部计算并行度介绍
# 0. 问题:
MapTask并行度,是不是越大越好?
# 1. MapTask的并行度的产生
1. inputformat根据配置信息,获得hdfs中文件的split大小和位置。
2. 每个split就会启动一个MapTask,进行处理。
# 2. 总结MapTask并行度决定机制
概念:
block:hdfs文件的最小单元。
split:文件切分信息,虚拟的文件切片。
1. 默认:blocksize的大小就是split的大小128M,也就是一个MapTask执行的任务。
这样能够减少多个节点的MapTask之间的网络IO。
2. 设置切片大小(了解):(配置信息在mapred-site.xml,最大值被写在代码中了)
计算方式:splitSize = Math.max(minSize, Math.min(maxSize, blockSize));
minSize:mapreduce.input.fileinputformat.split.minsize
maxSize:mapreduce.input.fileinputformat.split.maxsize
俗称:取中间。
# 3. 实战:
一般只会调整minsize,进而增大splitSize,增加每个MapTask处理的数据量。
对于大数据量:Hadoop官方建议一般每个节点上保持10-100个map任务数。
InputFormat数据输入(优化2)
# InputFormat作用
1. 读取hdfs中的文件,讲读入的结果交给MapTask进行处理。
2. 负责执行对hdfs文件的切片操作。
默认:1block==1个split
# TextInputFormat作用
1. 读取hdfs中的文件,讲读入的结果交给MapTask处理。
k(偏移量) - v(当前行数据)。
逐行读取。
2. 负责执行对hdfs文件的切片操作。
block size==split size
# CombineTextInputFormat作用
1. 读取hdfs中的文件,讲读入的结果交给MapTask处理。
k(偏移量) - v(当前行数据)。
逐行读取。
2. hdfs文件切片,将多个小文件合并成一个split来处理,可以减少MapTask数量(海量小文件)
# 1. CombineTextInputFormat使用
1. 设置使用作为hdfs文件输入工具。
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job,10*1024*1024); // 字节10M 设置最大切牌你文件大小 10M-100M
FileInputFormat.addInputPath(job,"目录"); //设置读入文件路径
# 2. API
接口:org.apache.hadoop.mapreduce.InputFormat
实现类:
org.apache.hadoop.mapreduce.lib.input.TextInputFormat
特点:逐行读入,并形成key-value,key是偏移量,value是当前行的数据。
# 3.结论
1. 默认InputFormat会按照block大小设置split大小,取决于block大小,决定了MapTask个数。
适合做大文件的处理(GB TB)
2. 使用CombineTextInputFormat将海量小文件合并切片。适合海量小文件的处理。
# 4. 读入hdfs文件的api
1. 指定一个输入文件
TextInputFormat.addInputPath(job,new Path("/hdfs文件"));
2. 指定一个输入目录
TextInputFormat.addInputPath(job,new Path("/hdfs目录"));
3. 指定多个输入文件
TextInputFormat.addInputPath(job,new Path("/dhfs文件1"));
TextInputFormat.addInputPath(job,new Path("/dhfs文件2"));
TextInputFormat.addInputPath(job,new Path("/dhfs文件3"));
# 案列
package demo1.map;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
* KEYIN:map输入的key 偏移量
*VALUEIN:map输入的value 一行字符串即传入的一行数据
* KEYOUT:map输出的名字 name 由字符串分割而得到 str
* VALUEOUT:map输出的次数 name 由字符串分割而得到 int
* */
public class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable> {
/**
*
* @param key map输入的key 偏移量
* @param value map输入的value 一行字符串即传入的一行数据
* @param context 输出的keyout和 valueout
* @throws IOException
* @throws InterruptedException
*/
/*
map局部计算执行代码
context.write(keyout valueout)
* */
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.拆分字符串valuein
String[] names = value.toString().split(" ");
/* 这是只拆分两个的情况
//2.将name作为key,将1作为value
String keyout1 = names [0];
String keyout2 = names [1];
//3.context.write(name,value)
context.write(new Text(keyout1),new IntWritable(1));
*/
//2与3正确做法应该遍历
for (String name : names) {
context.write(new Text(name),new IntWritable(1));
}
}
}
package demo1.reduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
keyin:reduce输入的key name str
valuein:reduce输入的value,value的每个元素类型 ,次数 int
keyout:reduce输入的key name str
valueout:reduce输入的value,累加后的次数sum int
*/
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
*
* @param key reduce输入的name
* @param values reduce输入的次数的集合
* @param context
* @throws IOException
* @throws InterruptedException
*/
/*
汇总计算的代码
context.write(keyout,valueout)
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//1.将value集合中的值累加 int
int sum = 0;
for (IntWritable value : values) {
int v = value.get();
sum+=v;
}
//2.将 name-次数之和 输出
context.write(key,new IntWritable(sum));
}
}
package demo1.job;
import demo1.map.WordCountMap;
import demo1.reduce.WordCountReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/*
* 整合map-reduce过程
* */
public class WordCountJob {
public static void main(String[] args) throws Exception {
//1.配置hdfs的数据读取入口
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
//2.创建一个job=input -map -shuffle -reduce -output
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJob.class); //指定当前job类名
//3.设置map阶段(input map类 输出的key类型 输出的value类型)
job.setMapperClass(WordCountMap.class); //设置mapper类
job.setMapOutputKeyClass(Text.class); //设置mapper输出的key的类型
job.setMapOutputValueClass(IntWritable.class); //设置mapper输出的value的类型
//设置输入文件
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job,10*1024*1024); //10M
FileInputFormat.addInputPath(job,new Path("/demo3"));
//4.设置reduce阶段 (output reduce类 输出的key类型 输出的value类型 )
job.setReducerClass(WordCountReduce.class); //设置reducer类
job.setOutputKeyClass(Text.class); //设置reduce输出的key的类型
job.setOutputValueClass(IntWritable.class); //设置reduce输出的value的类型
//注意事项:输出的目录不允许存在,只能mr自己创建
TextOutputFormat.setOutputPath(job,new Path("/demo3/mrout3"));
//5.启动job
boolean b = job.waitForCompletion(true);
System.out.println(b);
}
}
# 结果
demo3下的三个文件合并成一个文件输出
Combiner合并(优化3 可选项)
# Combiner :map本地对map结果执行的reduce操作。
# map端:完成map输出结果合并reduce
1.reduce端从map端通过网络拷贝数据时候,数据量大大减少。(提高了整体job的性能)
2.在map端提前并行执行了Reduce(局部),减轻了Reduce的执行压力,整体效率提升了。
# 总结:
1.提高job并行度。
2.减少了map向reduce传输的数据。
# 注意:
1.默认hadoop不会开启,需要手动开启。
开启方式:job.setCombinerClass(Reducer的类.class);
2.应用场景:(即优化手段不能影响最终结果)
Combine适合做累加(mr支持迭代性)、统计个数、最大值、最小值
不适合做平均值场景。
map端的局部reduce:对map输出的结果,进行一次reduce。
减少MapTask向ReduceTask通过网络传输的数据,减轻Reduce的工作压力。
默认不开启,开启方式
job.setCombinerClass(Reducer的类.class);
- 应用场景
仅适合统计支持迭代性的操作:适合累加,统计个数等操作,不适合平均值操作
# 测试案例(消费记录)
姓名 消费金额
张三 100
王五 200
李四 300
张三 400
王五 500
张三 600
# 期望结果
张三 1100
李四 300
王五 700
# 案列代码
package demo6;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MoneyMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] vs = value.toString().trim().split("\t");
context.write(new Text(vs[0]),new IntWritable(Integer.parseInt(vs[1])));
}
}
package demo6;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MoneyReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum+=value.get();
}
context.write(key,new IntWritable(sum));
}
}
package demo6;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class MoneyJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(MoneyJob.class);
job.setMapperClass(MoneyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job,new Path("/demo4/combine.txt"));
//设置combiner:map本地的reduce操作
job.setCombinerClass(MoneyReducer.class);
job.setReducerClass(MoneyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job,new Path("/demo4/combineout1"));
job.waitForCompletion(true);
}
}
ReduceTask汇总并行度(优化4)
# 提高ReduceTask的数量,提高Reduce的并行度,提高效率
1. 增加ReduceTask的并行度(数量) ,可以启动多个程序处理map的汇总结果,可以提高效率。
2. 每个ReduceTask输出结果,都会单独的输出到1个文件。
# ReduceTask的数量是可以在程序中手动指定
默认数量为: 1个 Reduce
可以通过: job.setNumReduceTasks(数字); 0 就是没有 数字是几就是几个
# 测试案例
2020年3月3日 www.baizhiedu.com /product/detail/10001.html iphoneSE 10001 30
2020年3月3日 www.baizhiedu.com /product/detail/10001.html iphoneSE 10001 60
2020年3月3日 www.baizhiedu.com /product/detail/10001.html iphoneSE 10001 100
2020年3月3日 www.baizhiedu.com /product/detail/10002.html xps15 10002 10
2020年3月3日 www.baizhiedu.com /product/detail/10003.html thinkpadx390 10003 200
2020年3月3日 www.baizhiedu.com /product/detail/10004.html iphoneX 10004 100
2020年3月3日 www.baizhiedu.com /product/detail/10003.html thinkpadx390 10003 100
2020年3月3日 www.baizhiedu.com /product/detail/10001.html iphoneSE 10001 120
2020年3月4日 www.baizhiedu.com /product/detail/10001.html iphoneSE 10001 200
2020年3月5日 www.baizhiedu.com /product/detail/10001.html iphoneSE 10001 25
2020年3月6日 www.baizhiedu.com /product/detail/10001.html iphoneSE 10001 20
# 期望结果
# 输出两个文件
10001 7
10002 1
10003 2
10004 1
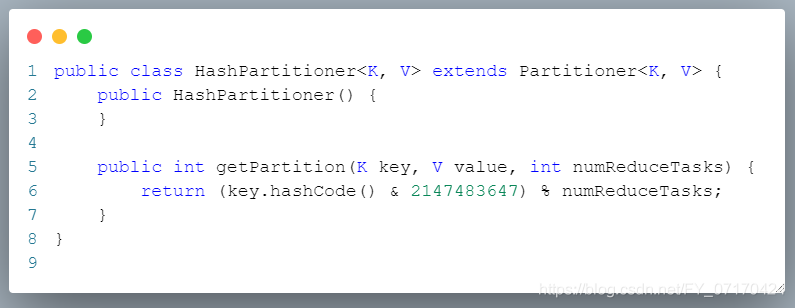
默认分区规则(详情参考源码:HashPartitioner Ctrl+n)
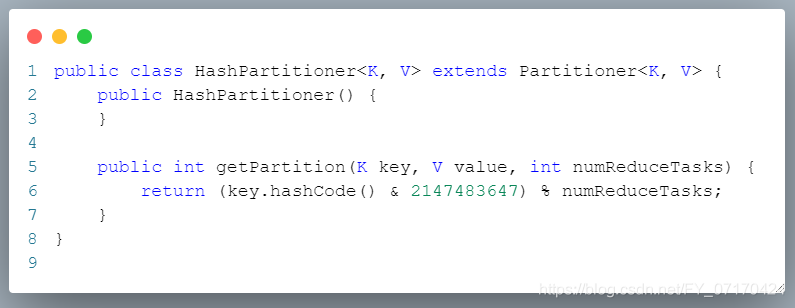
# 默认分区规则
key % reduceTask数量
key.hashcode() % 2
# 分区规则(默认)
1. key % numreduceTask取模。(0~n)
2. 取模结果有几个值,就会产生几个分区。
3. 有几个分区,就会有几个reduceTask,以及产生几个输出文件。
4. 分区partion方法返回值0~n,分别对应分区号
返回值0 分区0
返回值1 分区1
返回值2 分区2
返回值的n,就是分区号,分区号从0开始。
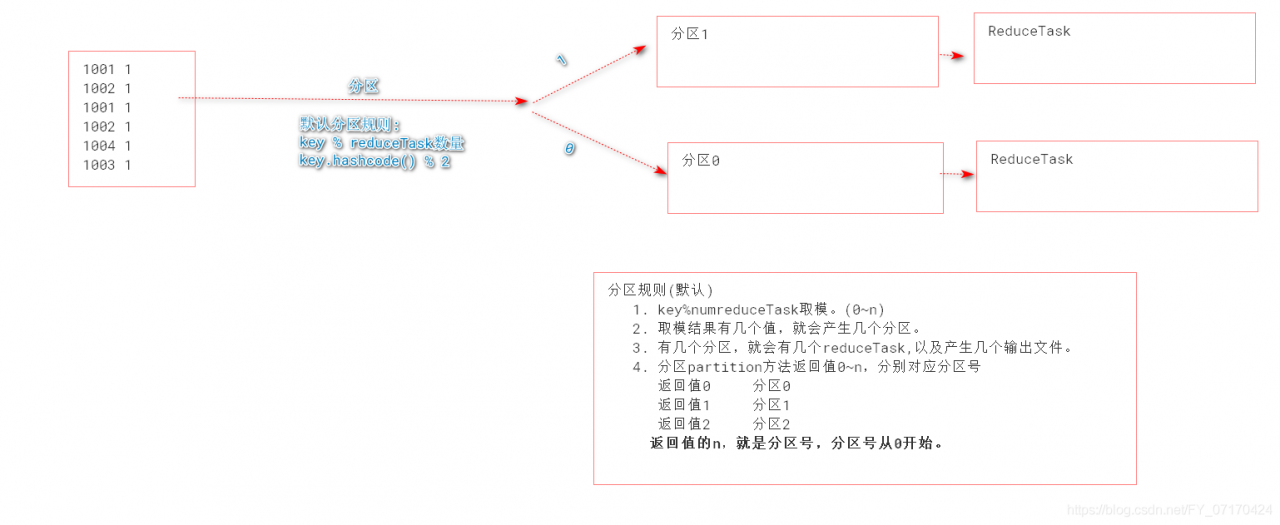
# 分区流程(发生时机)
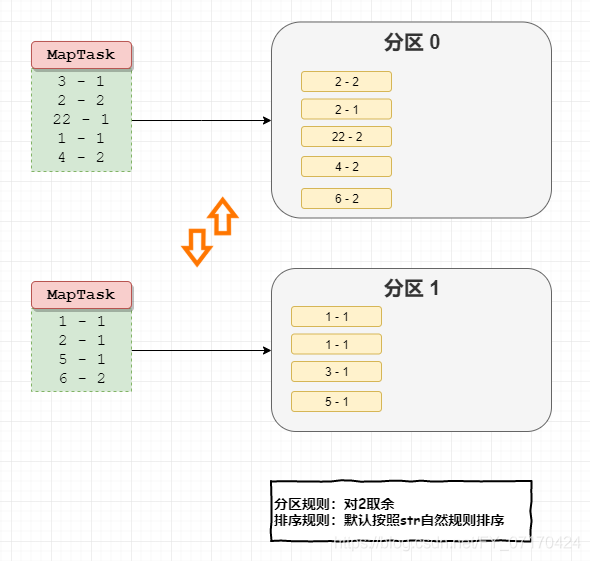
# MapReduce分区的整个流程
1. 当MapTask任务中的mapper.map()输出结果后,会先根据map输出的key判断分区。(默认按照key.hashcode%reduceTasks)
不同的key-value进入不同的分区。(从此分道扬镳)
2. 对分区后数据各自做排序。(免去了分区之间数据的比较交换排序操作)
3. 如果设置Combiner,会自动对各自分区做本地reduce汇总操作。
4. 将结果输出mapTask机器本地。(分区存放:分区0、分区1)
5. ReduceTask阶段拷贝MapTask输出结果,按照分区拷贝。
a: ReduceTask0 从所有MapTask阶段拷贝所有的分区0的数据。(n多个分区0数据)
b: 合并所有远程拷贝到的分区0的文件数据,排序(归并排序)
c: 合并当前分区0中的key的value。(merge)[k-v1,v2,v3]
d: 启动1个执行ReduceTask,输出到文件中。
6. ReduceTask阶段拷贝MapTask输出结果,按照分区拷贝。
a: ReduceTask1 从所有MapTask阶段拷贝所有的分区1的数据。(n多个分区1数据)
b: 合并所有远程拷贝到的分区1的文件数据,排序(归并排序)
c: 合并当前分区1中的key的value。(merge)即[k-v1,v2,v3]
d: 启动1个执行ReduceTask,输出到文件中。
5和6同时reduce阶段各自处理各自分区的数据
自定义Partition
# 自定义partition
将下面数据分区处理:
张三 语文 10
李四 数学 30
王五 语文 20
赵6 英语 40
张三 数据 50
李四 语文 10
张三 英语 70
李四 英语 80
王五 英语 45
王五 数学 10
赵6 数学 10
赵6 语文 100
# 期望结果:
按照科目分区,并按照成绩降序排序
赵6 语文 100
李四 英语 80
张三 英语 70
李四 语文 60
张三 数据 50
王五 英语 45
赵6 英语 40
李四 数学 30
王五 语文 20
王五 数学 10
赵6 数学 10
张三 语文 10
# 思路:
1:分区依据要作为key
2:排序字段也要作为key。
3:避免合并,key要唯一,不重复(所有key都不一样,key - name,subject,score)
# 自定义分区思路:通过修改Reduce的个数,设置分区的个数。(仿照默认分区自己写一个分区类)
① 定义分区类
# 执行时机:
Map输出key-value,后,会调用getPartition方法,决定当前key-value进入哪个分区。
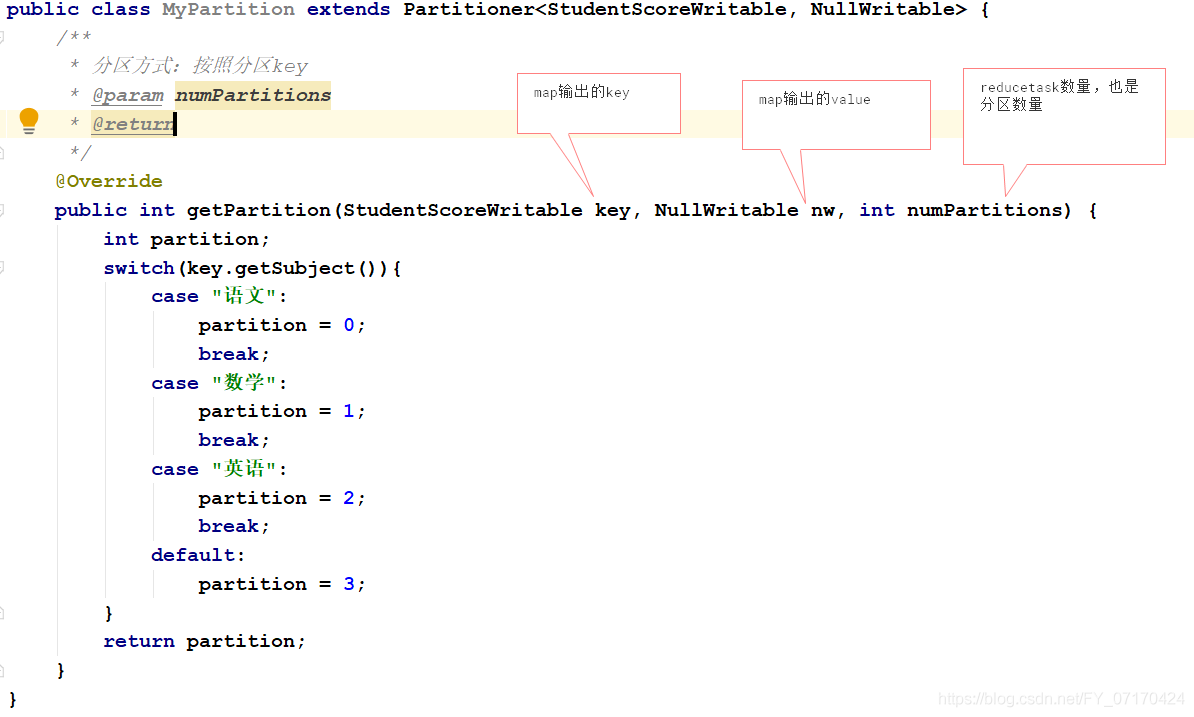
使用分区类
job.setPartitionerClass(自定义Partitioner.class);
③ 设定reducer个数
job.setNumReduceTasks(数字); //reduceTask数量要和分区数量一样。
# 实现代码
package demo8;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ScoreMapper1 extends Mapper<LongWritable, Text,ScoreWritable, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获得value中的属性----ScoreWritable.
String[] vs = value.toString().trim().split("\t");
ScoreWritable sw = new ScoreWritable(vs[0], vs[1], Integer.parseInt(vs[2]));
context.write(sw,NullWritable.get());
}
}
package demo8;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ScoreReducer1 extends Reducer<ScoreWritable, NullWritable, Text,NullWritable> {
@Override
protected void reduce(ScoreWritable key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//1.
context.write(new Text(key.getName()+"\t"+key.getSubject()+"\t"+key.getScore()),NullWritable.get());
}
}
package demo8;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class ScoreWritable implements WritableComparable<ScoreWritable> {
private String name;
private String subject;
private int score;
public ScoreWritable(){}
public ScoreWritable(String name, String subject, int score) {
this.name = name;
this.subject = subject;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
/**
* 调用时机: 排序时候
* 合并key-v1 v2 v3
* 规则:
* score降序
* 方法设计:
* 正数 升序 this<o
* 负数 降序 this>o
* 0 在shuffle发生key的合并。
* @param o
* @return
*/
@Override
public int compareTo(ScoreWritable o) {
if(this.score != o.score){
if(this.score>o.score){
return -1;
}else{
return 1;
}
}else{
// 将其他属性都比较一下,防止成绩相同的数据合并在一起。
if(!this.subject.equals(o.subject)){
return this.subject.compareTo(o.subject);
}else{
return this.name.compareTo(o.name);
}
}
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(name);
dataOutput.writeUTF(subject);
dataOutput.writeInt(score);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
name = dataInput.readUTF();
subject = dataInput.readUTF();
score = dataInput.readInt();
}
}
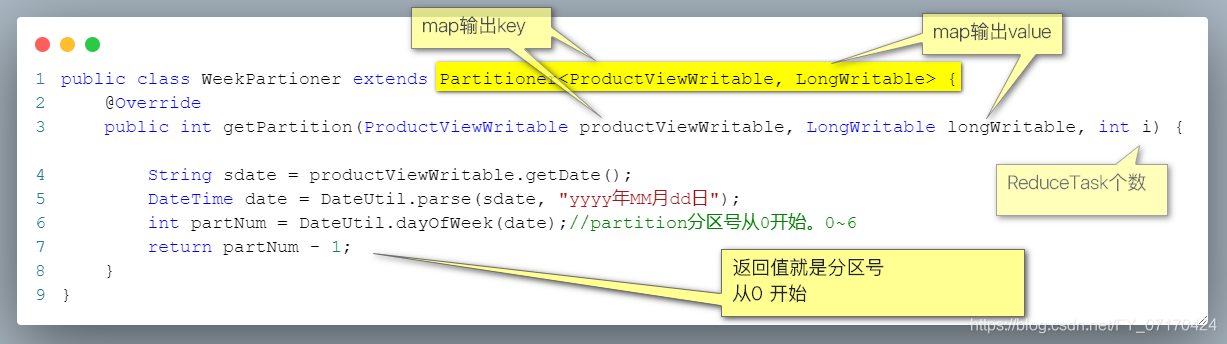
# 自定义分区*********
package demo8;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* 什么数据会交给该类做分区操作。
* 拿到map输出的key-value,
* 使用key进行分区操作。
*/
public class MyPartition extends Partitioner<ScoreWritable, NullWritable> {
/**
* 分区期望:
* 语文 0 return 0;
* 数学 1 return 1;
* 英语 2 return 2;
* 其他 3 return 3;
*/
@Override
public int getPartition(ScoreWritable scoreWritable, NullWritable nullWritable, int numPartitions) {
int partion;
switch (scoreWritable.getSubject()){
case "语文"://希望该key对应0分区。
partion=0;
break;
case "数学":
partion=1;
break;
case "英语":
partion=2;
break;
default:
partion=3;
}
return partion;
}
}
package demo8;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Job9 {
public static void main(String[] args)throws Exception {
//1. 配置hdfs的数据读取入口
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.153.10:9000");
//2. 创建一个job=input - map - shuffle -reduce - output
Job job = Job.getInstance(conf);
job.setJarByClass(Job9.class);//当前job的类名指定.
//3. 设置map阶段(input map类 输出的key类型 输出的value类型)
job.setMapperClass(ScoreMapper1.class);
job.setMapOutputKeyClass(ScoreWritable.class);
job.setMapOutputValueClass(NullWritable.class);
//设置输入文件
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job,new Path("/hdfs/demo5/partition.txt"));
//4. 设置reduce阶段(output reduce类 输出的key类型 输出的value的类型)
job.setReducerClass(ScoreReducer1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 输出的目录不允许存在,只能mr自己创建。
TextOutputFormat.setOutputPath(job,new Path("/hdfs/partitionout4"));
//*********指定job使用分区类**********
job.setPartitionerClass(MyPartition.class);//HashPartioner
job.setNumReduceTasks(4);
//5. 启动job
boolean ok = job.waitForCompletion(true);
System.out.println(ok);
}
}
# 结果四个分区对应科目各自降序排序
MapReduce工作原理
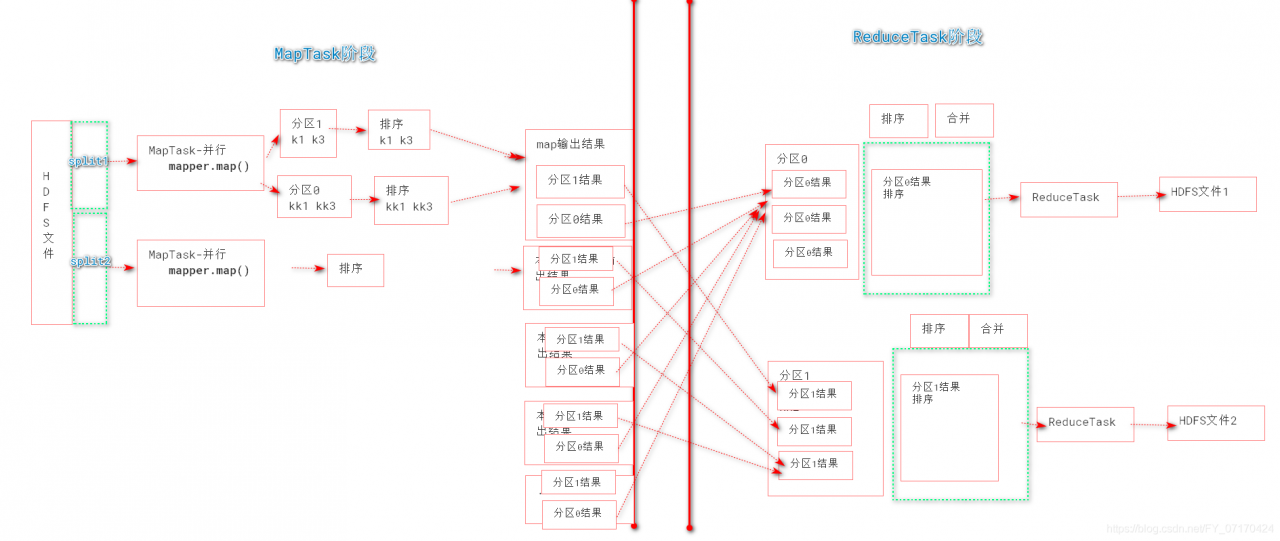
MapTask原理之环形缓冲区和溢写
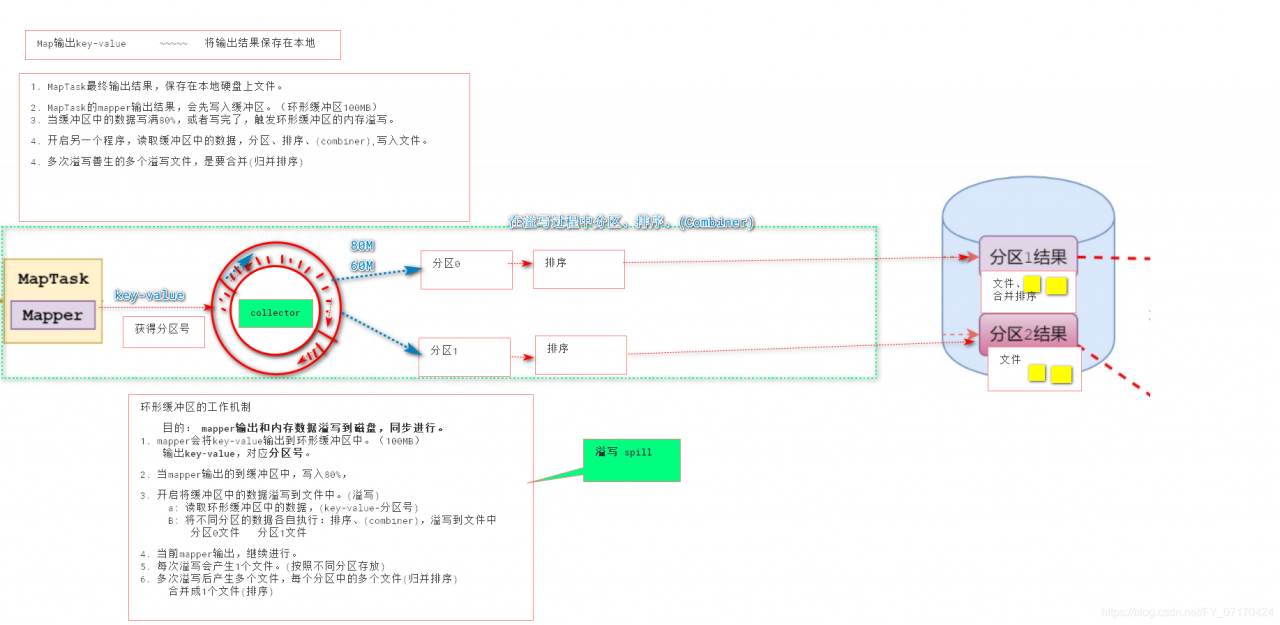
环形缓冲区工作机制(Spill溢写)
1. map输出的结果会存入环形缓冲区(从start下标开始写,写到80%,则启动溢写程序。环形缓冲区继续写入)
2. 当环形缓冲区中的数据,达到80%,则开始溢写。(每次写够80%,就开始溢写。)
3. 如果设置了分区,则对数据进行分区
4. 然后对分区后的数据各自做排序
5. 如果设置combiner,则执行map端的reduce合并处理
6. 将本次溢写的数据写入到本地的磁盘上。
7. 循环2~6,将多个文件溢写到磁盘上。
8. 将各个分区中,多次溢写的文件,再进行一次合并排序,然后将合并后的数据写入到对应的磁盘的分区上。
全局完整工作流程
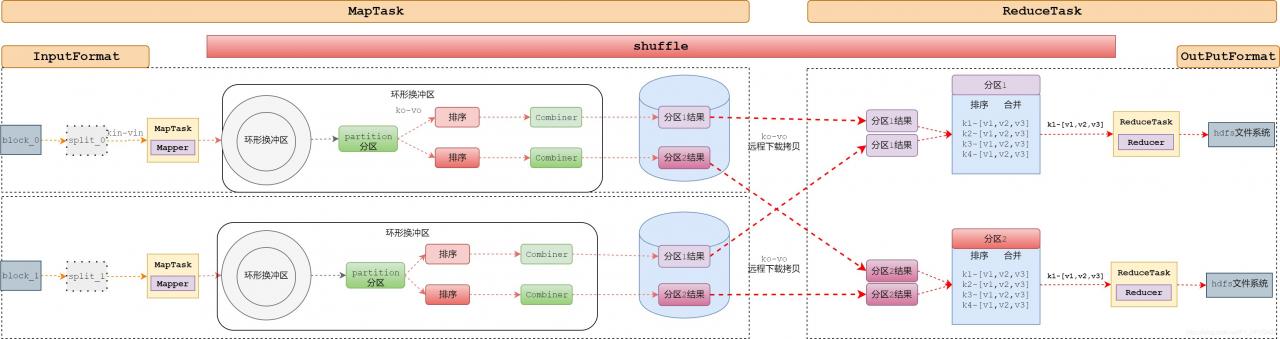
# mapreduce工作流程(终极版)
# MapTask过程
1. 创建InputFormat,读取数据
① 获得文件split
② 读取split范围内的数据,k-v。
2. Mapper.map()方法处理,InputFormat读取到k-v,
循环读取文件中k-v,每次读取,调用一次mapper.map();
while(读下一条){
mapper.map(k,v);
}
map执行结果context.write(ko,vo)
3. mapper输出结果
① 获得ko-vo获得分区号。(Partitioner.getpartion())
② 将ko-vo写出到环形缓冲区中。
4. 一旦环形缓冲区中数据达到溢写条件(80%,写完了)
① 读取环形缓冲区中的数据
② 根据分区号,分区排序、(Combiner)
③ 将处理结果溢写到磁盘中文件中。
④ 每次达到溢写条件(80%,写完了),执行1-3,在mapTask本地磁盘形成分区文件。
⑤ 最后在本地完成一次分区内多个溢写文件 归并排序,产生1个文件(maptask处理结果)。
# ReduceTask过程:
1. 根据分区号,启动ReduceTask,下载多个MapTask处理结果中的对应分区文件
MapTaskA(分区0)----ReduceTask0
MapTaskB(分区0)----ReduceTask0
2. 将当前分区中,来自不同MapTask的分区文件,归并排序。(为了reduce的merge操作效率)
产生1个大的本分区的文件,且内容key有序。
3. merge操作,将有序的结果,合并key的value。
4. 循环调用reducer的reduce方法,处理汇总的数据
while(xxx){
reduce.reduce(key,values);
context.write(k,v)
}
5. ReduceTask调用OutputFormat将结果写入到hdfs文件中。
# Shuffle:
# map阶段
1. mapper输出结果
① 获得ko-vo获得分区号。(Partitioner.getpartion())
② 将ko-vo写出到环形缓冲区中。
2. 一旦环形缓冲区中数据达到溢写条件(80%,写完了)
① 读取环形缓冲区中的数据
② 根据分区号,分区排序、(Combiner)
③ 将处理结果溢写到磁盘中文件中。
④ 每次达到溢写条件(80%,写完了),①~③,在mapTask本地磁盘形成分区文件。
⑤ 最后在本地完成一次分区内多个溢写文件 归并排序,产生1个文件(maptask处理结果)。
# reduce阶段
3. 根据分区号,启动ReduceTask,下载多个MapTask处理结果中的对应分区文件
MapTaskA(分区0)----ReduceTask0
MapTaskB(分区0)----ReduceTask0
4. 将当前分区中,来自不同MapTask的分区文件,归并排序。(为了reduce的merge操作效率)
产生1个大的本分区的文件,且内容key有序。
5. merge操作,将有序的结果,合并key的value。
源码分析
MapTask
public class MapTask{
// 1. 启动一个新的Mapper程序。
private <INKEY,INVALUE,OUTKEY,OUTVALUE> void runNewMapper(){
创建inputFormat
创建split
创建mapper
执行mapper处理数据。mapper.run(mapperContext);
context.write(key,value)---分区--放入环形缓冲区内。
关闭输出(NewOutputCollector),准备溢写。output.close(mapperContext);
1. 排序
2. combiner
3. 到文件
}
//2. 收集key-value进入环形缓冲区
public void collect(K key, V value)
先分区再进入缓冲区
//3. sortAndSpill() 溢写过程
}
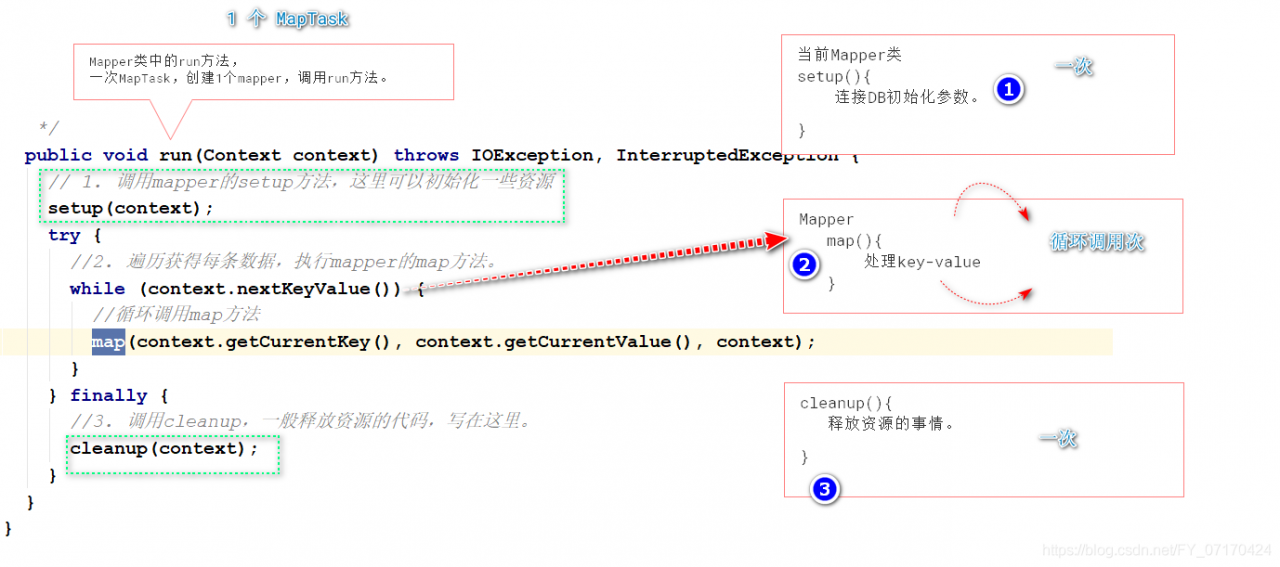
# mapper对象的代码机制
1. 每启动MapTask,执行一次runNewMapper方法,创建一个mapper类。
2. 每读取key-value,调用mapper.map();
InputFormat
public abstract class InputFormat<K, V>
//切片方法
public abstract List<InputSplit> getSplits()...
//根据split信息返回一个RecordReader(用来读取数据)
public abstract RecordReader<K,V> createRecordReader(InputSplit split...
public abstract class FileInputFormat<K, V> extends InputFormat<K, V>{
public List<InputSplit> getSplits(JobContext job){
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));//获得最小值 1
long maxSize = getMaxSplitSize(job);//获得最大值 LongMax
...
long splitSize = computeSplitSize(blockSize, minSize, maxSize);//获取split的切片大小。对应配置文件(split.minsize)
...
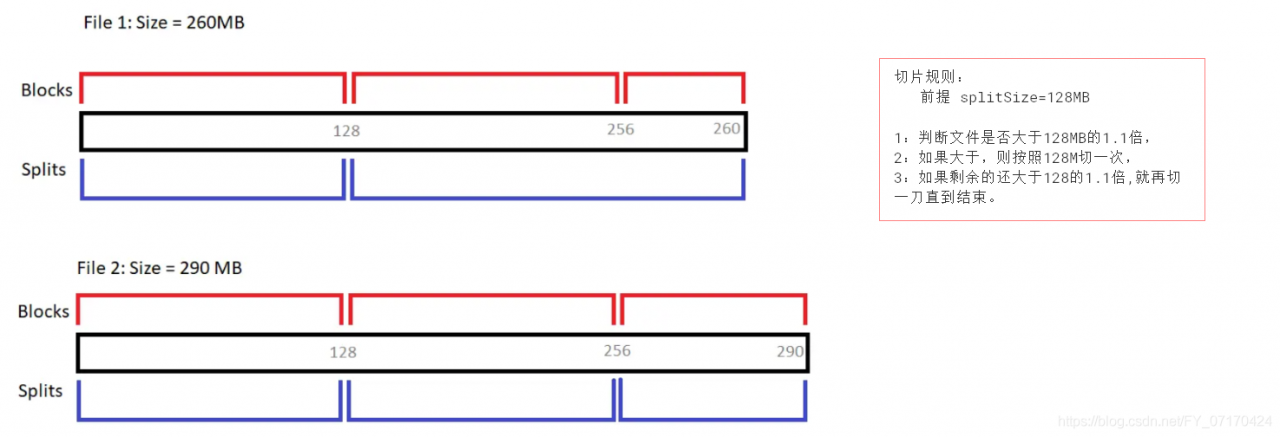
//当文件剩余大小大于split大小的1.1倍时,进行分片
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//获取block块的索引位置
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
//分片
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
//源文件减去已经分片大小
bytesRemaining -= splitSize;
}

ReduceTask
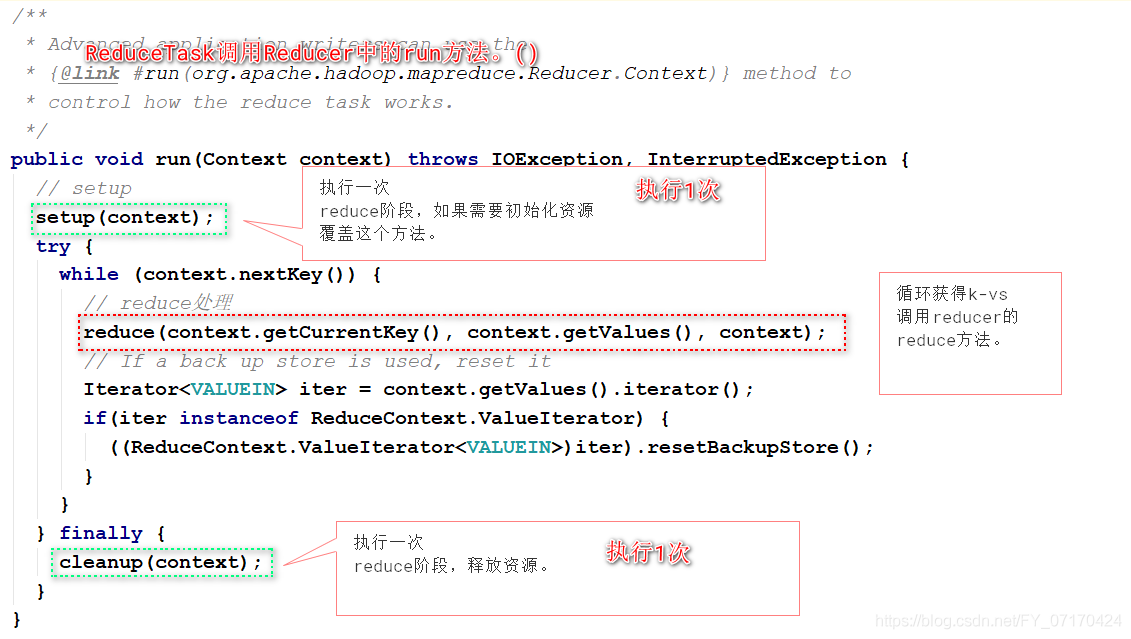
private <INKEY,INVALUE,OUTKEY,OUTVALUE> void runNewReducer(JobConf job...{
创建reducer
调用reducer的run
调用setup 循环调用reduce方法,cleanup
}
# 4. OutputFormat
public class TextOutputFormat{
// 将key-value写出到文件中。
public synchronized void write(K key, V value)
}
MapReduce项目实战
# 练习题
1. 完成分区代码任务:
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
要求:统计每个手机号的总上传流量,总下载流量 总流量。,按照手机区放在不同的文件内。
(只考虑手机号开头 137 138 139 其他)
2. 整理MapTask ReduceTask Shuffle执行流程===(MapReduce完整流程)
3. 思考题(非必做)
张三 10
李四 20
王五 30
悟空 15
八戒 90
沙僧 100
李旭 150
统计,其中的最大值?
结果:
李旭 150
案例1
统计各个商品一周内的访问量?
输入数据:
日期 域名 商品详情页url 商品名 商品id
输出数据:
商品id 访问量
导入依赖
案例2
需求:统计各个一周内各个商品每天的访问量信息?
输入:日期 域名 商品详情页url 商品名 商品id
输出:商品id 商品名 时间 访问次数
要求任务暴露http请求任务接口,以供定时任务调用。
技术选型
SpringBoot+HDFS+MapReduce
导入依赖
<!-- hadoop 依赖 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId></exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> <exclusion> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> </exclusion> </exclusions> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId></exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> <exclusion> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId></exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> <exclusion> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> </exclusion> </exclusions> </dependency> <!--mr依赖--> <!--mapreduce依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <artifactId>guice-servlet</artifactId> <groupId>com.google.inject.extensions</groupId> </exclusion> </exclusions> </dependency> <!--yarn依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-common</artifactId> <version>${hadoop.version}</version> <exclusions> <exclusion> <artifactId>servlet-api</artifactId> <groupId>javax.servlet</groupId> </exclusion> </exclusions> </dependency>
Mapreduce底层原理
0. MR细节补充
MapTask个数
概念
① split个数==MapTask个数
② split个数取决于split的大小,默认split.size=block.size;
查看
执行日志:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9WV7Zg9f-1623432421907)(C:/Users/yf/Desktop/学习/assets/1583388845180.png)]
ReduceTask个数
概念
并行reduce的处理个数,可以提高系统效率。
默认reduce个数为1.
ReduceTask个数等于输出文件的个数
代码
job.setNumReduceTasks(数字) //job.setReducerClass(MyReducer.class); //job.setOutputKeyClass(Text.class); //job.setOutputValueClass(NullWritable.class);设置Reduce Task个数的小狗
0个ReduceTask
概念
如果MapReduce中,只是对数据进行清洗,而不负责统计,去重的话,就没有Reduce
编码
job.setNumReduceTask(0);
1. MapTask
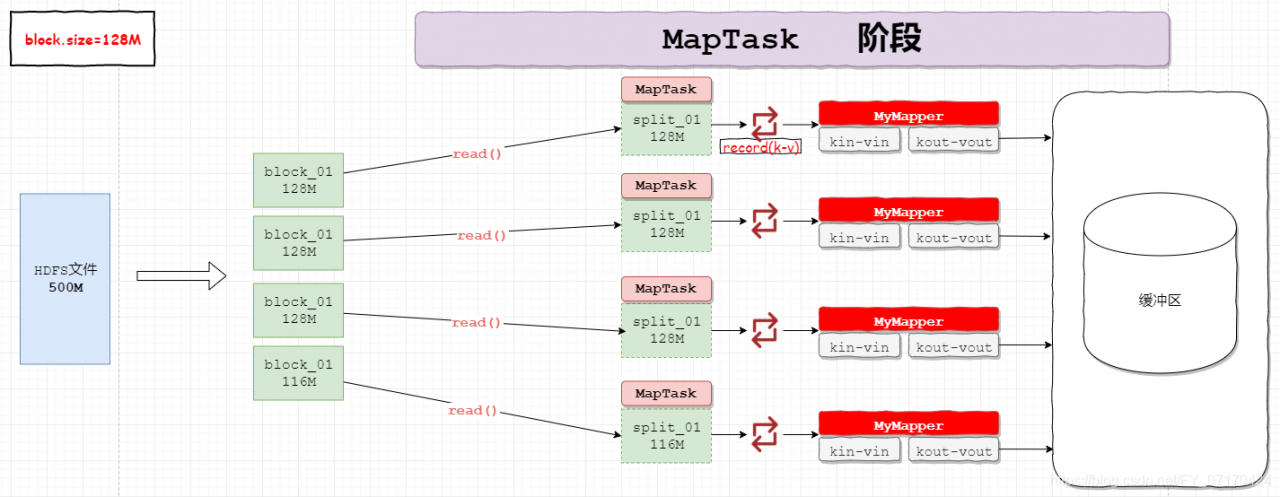
作用
MapTask,一个数据转化任务。
系统中可以同时有多个MapTask对多块数据进行处理。
具体转化代码由程序员决定。
工作原理步骤
原理
FileInputFormat切片机制
概念
① 一个文件如果小于等于blocksize,则被切片成一个split。
② 不同的block不会合并。
默认切片实现
默认使用
TextInputFormat:逐行处理。CombineTextInputFormat切片合并
场景
大量小文件的处理,默认多个split,多个maptask,增加网络io次数降低效率
办法:合并切片处理。
代码
job.setInputFormatClass(CombineTextInputFormat.class);//设置使用CombineTextInputFormat切片方式 CombineTextInputFormat.setMaxInputSplitSize(job,4194306);//设置合并小于4M的split,需要合并。
3. Shuffle
概念
发生在Map之后,Reduce之前。
俗称洗牌
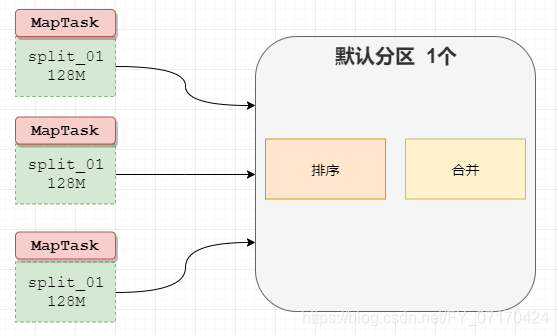
功能
- 分区
- 排序
- combiner合并
- 归并排序
- 数据压缩
流程图
概念
对map输出的key-value进行分区处理。
默认分区
默认说明
- 默认使用map的输出的key的hashcode对reduceTask进行取余。
- 默认ReduceTask是1
- partition个数=ReduceTask=输出文件个数
概念
大量MapTask如果只有一个分区的话,也就意味着后面的reduce节点只有一个reduce执行,会导致处理速度慢。
编码
思路:通过修改Reduce的个数,设置分区的个数。
① 定义分区类
② 使用分区类
job.setPartitionerClass(自定义Partitioner.class);③ 设定reducer个数
job.set实战案例
将一周内的商品浏览日志数据,统计各个商品每天的访问量,并按照日期放在不同的文件中?
概念
功能:对有MapTask输出的数据,根据key按照一定的规则进行排序。
时间:发生在maptask之后,reduce之前。
思路图
原理
- 按照MapTask输出的key,调用其compareTo方法进行排序
如果key是Text,则按照字符串规则排序
如果key是IntWritable,就按照数字大小升序排序。 - 默认使用快速排序方式进行排序。
- 按照MapTask输出的key,调用其compareTo方法进行排序
自定义排序(全排序)
案例1:将输出的年龄按照降序排序。

案例2:将输出的信息按照某个字段或者属性进行排序。
map输出key进行封装成对象,实现WritableComparable接口,并实现compareTo方法分区排序
概念
一个分区对应一个reducer对应一个输出文件。
在每个文件内是按照一定顺序进行排序的。
思路图
案例
将一周内的商品浏览日志数据,统计各个商品每天的访问量,并按照日期放在不同的文件中,并按照排序代码实现思想
在排序的同时增加分区即可。
代码和分区操作一样 partition
1. 开发一个实体类实现WritableComparable接口 public class ProductViewWritable implements WritableComparable<ProductViewWritable>{} 2. 开发一个partition分区类 public class WeekPartioner extends Partitioner<ProductViewWritable, LongWritable> { @Override public int getPartition(ProductViewWritable productViewWritable, LongWritable longWritable, int i) { //对输入的key和value,处理后。 //返回值是分区号。 } } 2. 设置分区类和reducerTask个数 job.setPartitionerClass(WeekPartioner.class); job.setNumReduceTasks(7);
概念
对输出的重复数据进行压缩
代码
job.setCombinerClass(XXxReducer.class);
4. ReduceTask
概念
- 拷贝:讲maptask的partition中的数据拷贝到ReduceTask计算区中。
- 合并排序:讲分区获取到的数据,合并成一个文件。一个reduce合并成一个
- reduce:讲key相同的数据,value装入集合传给Reducer
思路
设置ReduceTask的并行度
作用
提高reduce的并行度
直接手动
job.setNumReduceTask(n); //job.setReducerClass(MyReducer.class); //job.setOutputKeyClass(Text.class); //job.setOutputValueClass(NullWritable.class);
总结注意
- ReduceTask=0,则没有Reduce阶段,输出文件个数和map个数一致。
- ReduceTask默认个数为1.
- ReduceTask设置个数,需要考虑因素
- 业务数据处理结果的需要,影响业务结果的任何设置都是无意义的。
- 性能,需要实际花时间测试然后再决定
- 如果要做全局汇总,统计结果要在一个文件中。(1个ReduceTask)
5. OutputFormat
概念
是负责将ReduceTask的结果输出到HDFS文件系统中。
常见实现类
OutputFormat接口 TextOutputFormat 每条key-value输出到文件的一行。 输出的时候会自动调用key和value的toString方法,讲返回值以跳格隔开。 SequenceFileOutputFormat(了解) 自定义OutputFormat
6. 计数器
作用
统计mr过程中一些数据的统计个数
内置计数器
output map reduce 等等
自定义计数器编码
//在map和reduce阶段,只要能获得context context.getCounter("xx阶段名字","计数器名字").increment(1);数据清洗
过滤一些数据中的无效数据,统计各种情况的数据个数。