留作记录,方便时常翻阅学习
一、关于Redis

最近阅读了《Redis开发与运维》,非常不错。这里对书中的知识整理一下,方便自己回顾Redis的整个体系,来对相关知识点查漏补缺。
按照五点把书中的内容进行一下整理:
1、为什么要选择Redis:介绍Redis的使用场景与使用Redis的原因;
2、Redis常用命令总结:包括时间复杂度总结与具体数据类型在Redis内部使用的数据结构;
3、Redis的高级功能:包括持久化、复制、哨兵、集群介绍;
4、理解Redis:理解内存、阻塞,这部分是非常重要的,前面介绍的都可以成为术,这里应该属于道的部分;
5、开发技巧:主要是一些开发实战的总结,包括缓存设计与常见坑点。
先来开启第一部分的内容,对Redis来一次重新打量。
Redis不是万金油
在面试的时候,常被问比较下Redis与Memcache的优缺点,个人觉得这二者并不适合一起比较,一个是非关系型数据库不仅可以做缓存还能干其他事情,一个是仅用做缓存。常常让我们对这二者进行比较,主要也是由于Redis最广泛的应用场景就是Cache,那么Redis到底能干什么?又不能干什么呢?
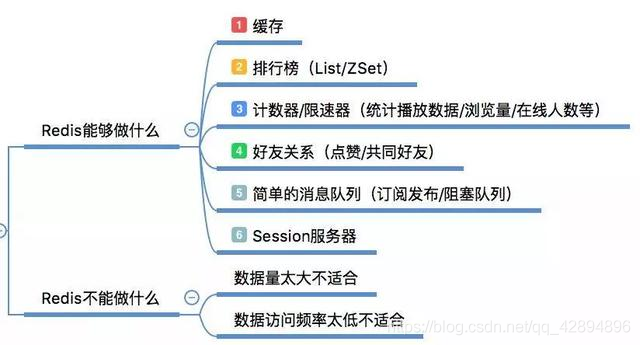
Redis都可以干什么事儿
缓存,毫无疑问这是Redis当今最为人熟知的使用场景,再提升服务器性能方面非常有效。
1.排行榜,如果使用传统的关系型数据库来做,非常麻烦,而利用Redis的SortSet数据结构能够非常方便搞定;
2.计算器/限速器,利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
3.好友关系,利用集合的一些命令,比如求交集、并集、差集等,可以方便搞定一些共同好友、共同爱好之类的功能;
4.简单消息队列,除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦;
5.Session共享,以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
Redis不能干什么事儿
Redis感觉能干的事情特别多,但它不是万能的,合适的地方用它事半功倍,如果滥用可能导致系统的不稳定、成本增高等问题。
1.比如,用Redis去保存用户的基本信息,虽然它能够支持持久化,但是它的持久化方案并不能保证数据绝对的落地,并且还可能带来Redis性能下降,因为持久化太过频繁会增大Redis服务的压力。
2.简单总结就是数据量太大、数据访问频率非常低的业务都不适合使用Redis,数据太大会增加成本,访问频率太低,保存在内存中纯属浪费资源。
选择总需要找个理由
上面说了Redis的一些使用场景,那么这些场景的解决方案也有很多其它选择,比如缓存可以用Memcache,Session共享还能用MySql来实现,消息队列可以用RabbitMQ,我们为什么一定要用Redis呢?
速度快,完全基于内存,使用C语言实现,网络层使用epoll解决高并发问题,单线程模型避免了不必要的上下文切换及竞争条件;
注意:单线程仅仅是说在网络请求这一模块上用一个请求处理客户端的请求,像持久化它就会重开一个线程/进程去进行处理。
丰富的数据类型,Redis有8种数据类型,当然常用的主要是 String、Hash、List、Set、 SortSet 这5种类型,他们都是基于键值的方式组织数据。每一种数据类型提供了非常丰富的操作命令,可以满足绝大部分需求,如果有特殊需求还能自己通过 lua 脚本自己创建新的命令(具备原子性);
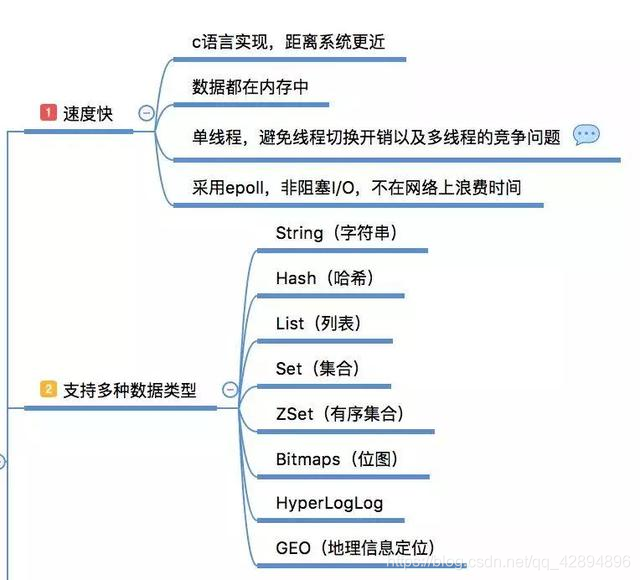
除了提供的丰富的数据类型,Redis还提供了像慢查询分析、性能测试、Pipeline、事务、Lua自定义命令、Bitmaps、HyperLogLog、发布/订阅、Geo等个性化功能。
Redis的代码开源在GitHub,代码非常简单优雅,任何人都能够吃透它的源码;它的编译安装也是非常的简单,没有任何的系统依赖;有非常活跃的社区,各种客户端的语言支持也是非常完善。另外它还支持事务(没用过)、持久化、主从复制让高可用、分布式成为可能。
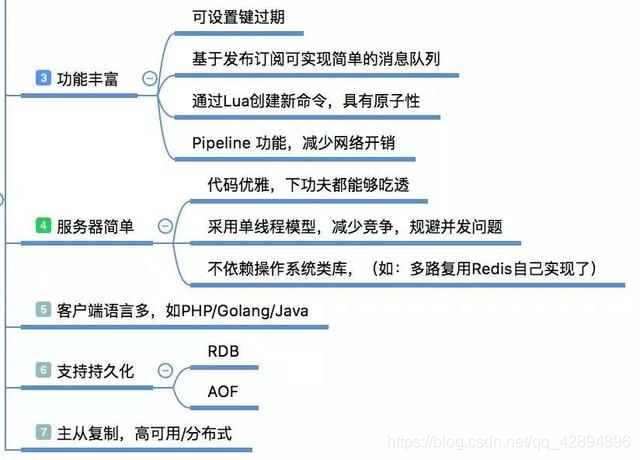
做为一个开发者,对于我们使用的东西不能让它成为一个黑盒子,我们应该深入进去,对它更了解、更熟悉,今天简单说了下Redis的使用场景,以及为什么选择了Redis而不是其他。
二、为什么选择Redis
首先,要知道缓存技术,这里主要说一下这两个的(memcached,Redis)区别。
缓存:
1)定义
缓存就是在内存中存储的数据备份,当数据没有发生本质变化的时候,我们避免数据的查询操作直接连接数据库,而是去 内容中读取数据,这样就大大降低了数据库的读写次数,而且从内存中读数据的速度要比从数据库查询要快很多。
2)缓存的形式
页面缓存(smarty静态化技术):页面缓存经常用在CMS(content manage system)内存管理系统里面。
数据缓存:经常会用在页面的具体数据里面。
1,memcached
协议简单、基于libevent的事件处理、内置内存存储方式、memcached不互相通信的分布式。 各个memcached不会互相通信以共享信息,分布策略由客户端实现。不会对数据进行持久化,重启memcached、重启操作系统会导致全部数据消失。
Memcached常见的应用场景是存储一些读取频繁但更新较少的数据,如静态网页、系统配置及规则数据、活跃用户的基本数据和个性化定制数据、准实时统计信息等。
2,Redis
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string、list、set、zset(有序集合)和hash。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序和算法。
与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件(RDB和AOF两种方式),并且在此基础上实现了master-slave(主从)同步,机器重启后能通过持久化数据自动重建内存,使用Redis作为Cache时机器宕机后热点数据不会丢失。
Redis丰富的数据结构也使其拥有更加丰富的应用场景。Redis的命令都是原子性的,可以简单地利用INCR和DECR实现计数功能。使用list可以实现获取最近N个数的操作。sort set支持对数据排序,可以应用在排行榜中。set集合可以应用到数据排重。Redis还支持过期时间设置,可以应用到需要设定精确过期时间的应用。只要可以使用Redis支持的数据结构表示的场景,就可以使用Redis进行存储。
Redis基于乐观锁
为什么选择Redis?
1)Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2)Redis支持master-slave(主-从)模式应用
3)Redis支持数据持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
4)Redis单个value的最大限制是1GB,memcached只能保存1MB的数据。
主要是从两个角度去考虑:性能和并发。当然,redis还具备可以做分布式锁等其他功能,但是如果只是为了分布式锁这些其他功能,完全还有其他中间件(如zookpeer等)代替,并不是非要使用redis。因此,这个问题主要从性能和并发两个角度去答。
一、Redis简介
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
二、支持的数据类型
Redis是Remote Dictionary Server(远程数据服务)的缩写,由意大利人antirez(Salvatore Sanfilippo)开发的一款内存高速缓存数据库,该软件使用C语言编写,它的数据模型为key-value。它支持丰富的数据结构(类型),比如string(字符串)、list(链表)、set(集合)、zset(sorted set –有序集合)和hash(哈希类型,类似于Java中的map)。
(一)性能
如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。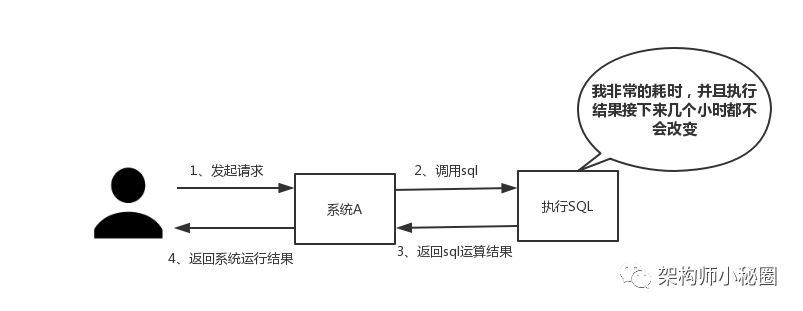
题外话:忽然想聊一下这个迅速响应的标准。其实根据交互效果的不同,这个响应时间没有固定标准。不过曾经有人这么告诉我:"在理想状态下,我们的页面跳转需要在瞬间解决,对于页内操作则需要在刹那间解决。另外,超过一弹指的耗时操作要有进度提示,并且可以随时中止或取消,这样才能给用户最好的体验。"
那么瞬间、刹那、一弹指具体是多少时间呢?
根据《摩诃僧祗律》记载
一刹那者为一念,二十念为一瞬,二十瞬为一弹指,二十弹指为一罗预,二十罗预为一须臾,一日一夜有三十须臾。
那么,经过周密的计算,一瞬间为0.36 秒,一刹那有 0.018 秒.一弹指长达 7.2 秒。
(二)并发
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问数据库。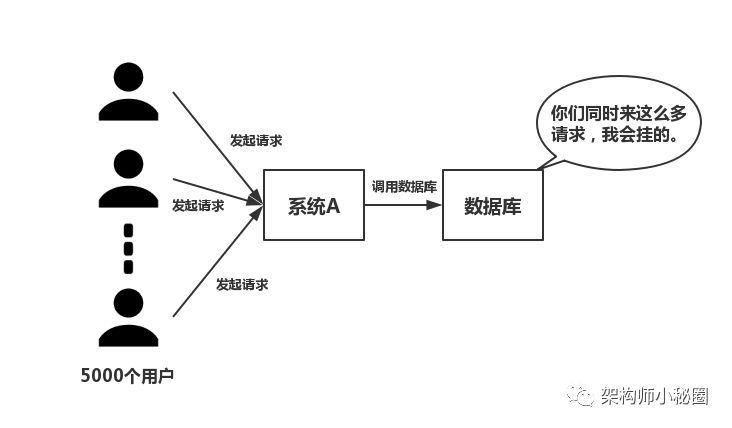
2、使用redis有什么缺点
分析:大家用redis这么久,这个问题是必须要了解的,基本上使用redis都会碰到一些问题,常见的也就几个。
回答:主要是四个问题
(一)缓存和数据库双写一致性问题
(二)缓存雪崩问题
(三)缓存击穿问题
(四)缓存的并发竞争问题
这四个问题,我个人是觉得在项目中,比较常遇见的,具体解决方案,后文给出。
3、单线程的redis为什么这么快
分析:这个问题其实是对redis内部机制的一个考察。其实根据博主的面试经验,很多人其实都不知道redis是单线程工作模型。所以,这个问题还是应该要复习一下的。
回答:主要是以下三点
(一)纯内存操作
(二)单线程操作,避免了频繁的上下文切换
(三)采用了非阻塞I/O多路复用机制
题外话:我们现在要仔细的说一说I/O多路复用机制,因为这个说法实在是太通俗了,通俗到一般人都不懂是什么意思。博主打一个比方:小曲在S城开了一家快递店,负责同城快送服务。小曲因为资金限制,雇佣了一批快递员,然后小曲发现资金不够了,只够买一辆车送快递。
经营方式一
客户每送来一份快递,小曲就让一个快递员盯着,然后快递员开车去送快递。慢慢的小曲就发现了这种经营方式存在下述问题
几十个快递员基本上时间都花在了抢车上了,大部分快递员都处在闲置状态,谁抢到了车,谁就能去送快递
随着快递的增多,快递员也越来越多,小曲发现快递店里越来越挤,没办法雇佣新的快递员了
快递员之间的协调很花时间
综合上述缺点,小曲痛定思痛,提出了下面的经营方式
经营方式二
小曲只雇佣一个快递员。然后呢,客户送来的快递,小曲按送达地点标注好,然后依次放在一个地方。最后,那个快递员依次的去取快递,一次拿一个,然后开着车去送快递,送好了就回来拿下一个快递。
对比
上述两种经营方式对比,是不是明显觉得第二种,效率更高,更好呢。在上述比喻中:
每个快递员---------->每个线程
每个快递------------>每个socket(I/O流)
快递的送达地点------>socket的不同状态
客户送快递请求------>来自客户端的请求
小曲的经营方式------>服务端运行的代码
一辆车--------------->CPU的核数
于是我们有如下结论
1、经营方式一就是传统的并发模型,每个I/O流(快递)都有一个新的线程(快递员)管理。
2、经营方式二就是I/O多路复用。只有单个线程(一个快递员),通过跟踪每个I/O流的状态(每个快递的送达地点),来管理多个I/O流。
下面类比到真实的redis线程模型,如图所示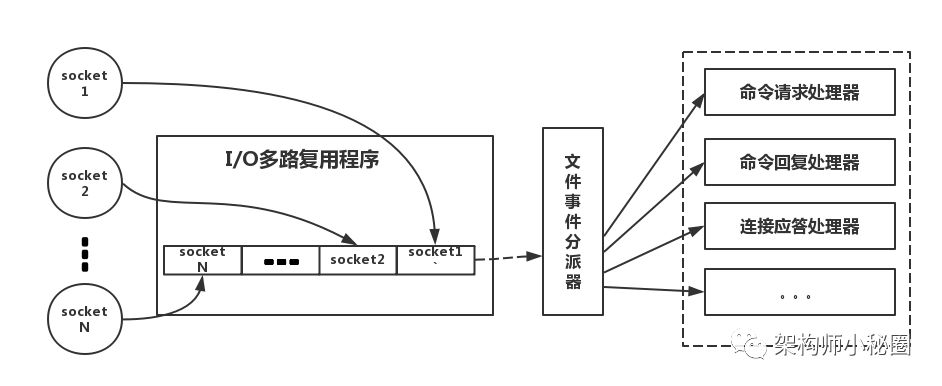
参照上图,简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
需要说明的是,这个I/O多路复用机制,redis还提供了select、epoll、evport、kqueue等多路复用函数库,大家可以自行去了解。
4、redis的数据类型,以及每种数据类型的使用场景
分析:是不是觉得这个问题很基础,其实我也这么觉得。然而根据面试经验发现,至少百分八十的人答不上这个问题。建议,在项目中用到后,再类比记忆,体会更深,不要硬记。基本上,一个合格的程序员,五种类型都会用到。
回答:一共五种
(一)String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。
(二)hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
(三)list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。
(四)set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
(五)sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
5、redis的过期策略以及内存淘汰机制
分析:这个问题其实相当重要,到底redis有没用到家,这个问题就可以看出来。比如你redis只能存5G数据,可是你写了10G,那会删5G的数据。怎么删的,这个问题思考过么?还有,你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,有思考过原因么?
回答:
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置
# maxmemory-policy volatile-lru
该配置就是配内存淘汰策略的(什么,你没配过?好好反省一下自己)
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
6、redis和数据库双写一致性问题
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
回答:首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
7、如何应对缓存穿透和缓存雪崩问题
分析:这两个问题,说句实在话,一般中小型传统软件企业,很难碰到这个问题。如果有大并发的项目,流量有几百万左右。这两个问题一定要深刻考虑。
回答:如下所示
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
(一)利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
(二)采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
(三)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
(一)给缓存的失效时间,加上一个随机值,避免集体失效。
(二)使用互斥锁,但是该方案吞吐量明显下降了。
(三)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
I 从缓存A读数据库,有则直接返回
II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
III 更新线程同时更新缓存A和缓存B。
8、如何解决redis的并发竞争key问题
分析:这个问题大致就是,同时有多个子系统去set一个key。这个时候要注意什么呢?大家思考过么。需要说明一下,博主提前百度了一下,发现答案基本都是推荐用redis事务机制。博主不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
回答:如下所示
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
9 总结
本文对redis的常见问题做了一个总结。大部分是博主自己在工作中遇到,以及以前面试别人的时候,爱问的一些问题。另外,不推荐大家临时抱佛脚,真正碰到一些有经验的工程师,其实几下就能把你问懵。最后,希望大家有所收获吧。
Redis的一些优点。
异常快 - Redis非常快,每秒可执行大约110000次的设置(SET)操作,每秒大约可执行81000次的读取/获取(GET)操作。
支持丰富的数据类型 -
Redis支持开发人员常用的大多数数据类型,例如列表,集合,排序集和散列等等。这使得Redis很容易被用来解决各种问题,因为我们知道哪些问题可以更好使用地哪些数据类型来处理解决。
操作具有原子性 - 所有Redis操作都是原子操作,这确保如果两个客户端并发访问,Redis服务器能接收更新的值。 多实用工具 -
Redis是一个多实用工具,可用于多种用例,如:缓存,消息队列(Redis本地支持发布/订阅),应用程序中的任何短期数据,例如,web应用程序中的会话,网页命中计数等。
三、 spring boot 集成Redis
1、添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.2</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-context</artifactId>
<version>2.1.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.5.0</version>
</dependency>
<!-- Spring Boot 2.0中spring-boot-starter-data-redis默认使用Lettuce方式替代了Jedis。使用Jedis的话先排除掉Lettuce的依赖,然后手动引入Jedis的依赖。 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
2、配置文件
spring.redis.host=127.0.0.1
#Redis服务器连接端口
spring.redis.port=6379
#Redis服务器连接密码(默认为空)
spring.redis.password=
#连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=8
#连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.pool.max-idle=8
#连接池中的最小空闲连接
spring.redis.pool.min-idle=0
#连接超时时间(毫秒)
spring.redis.timeout=30000
3、配置类RedisConfig
import java.lang.reflect.Method;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.databind.ObjectMapper;
@Configuration
@EnableCaching
@RefreshScope
public class RedisConfig extends CachingConfigurerSupport{
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Value("${spring.redis.timeout}")
private int timeout;
@Value("${spring.redis.password}")
private String password;
@Value("${spring.redis.pool.max-active}")
private int maxActive;
@Value("${spring.redis.pool.max-wait}")
private int maxWait;
@Value("${spring.redis.pool.max-idle}")
private int maxIdle;
@Value("${spring.redis.pool.min-idle}")
private int minIdle;
@RefreshScope
@Bean
public KeyGenerator wiselyKeyGenerator(){
return new KeyGenerator() {
@Override
public Object generate(Object target, Method method, Object... params) {
StringBuilder sb = new StringBuilder();
sb.append(target.getClass().getName());
sb.append(method.getName());
for (Object obj : params) {
sb.append(obj.toString());
}
return sb.toString();
}
};
}
@RefreshScope
@Bean
public JedisConnectionFactory redisConnectionFactory() {
JedisConnectionFactory factory = new JedisConnectionFactory();
factory.setHostName(host);
factory.setPort(port);
factory.setTimeout(timeout); //设置连接超时时间
factory.setPassword(password);
factory.getPoolConfig().setMaxIdle(maxIdle);
factory.getPoolConfig().setMinIdle(minIdle);
factory.getPoolConfig().setMaxTotal(maxActive);
factory.getPoolConfig().setMaxWaitMillis(maxWait);
return factory;
}
@RefreshScope
@Bean
public CacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheManager cacheManager = RedisCacheManager.create(connectionFactory);
// Number of seconds before expiration. Defaults to unlimited (0)
// cacheManager.setDefaultExpiration(10); // 设置key-value超时时间
return cacheManager;
}
@RefreshScope
@Bean
public RedisTemplate<String, String> redisTemplate(RedisConnectionFactory factory) {
StringRedisTemplate template = new StringRedisTemplate(factory);
setSerializer(template); //设置序列化工具,这样ReportBean不需要实现Serializable接口
template.afterPropertiesSet();
return template;
}
@RefreshScope
private void setSerializer(StringRedisTemplate template) {
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setValueSerializer(jackson2JsonRedisSerializer);
}
}
4、RedisUtils类
import java.io.Serializable;
import java.util.List;
import java.util.Set;
import java.util.concurrent.TimeUnit;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.HashOperations;
import org.springframework.data.redis.core.ListOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.SetOperations;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.data.redis.core.ZSetOperations;
import org.springframework.stereotype.Service;
@Service
public class RedisUtils {
@Autowired
private RedisTemplate redisTemplate;
/**
* 写入缓存
* @param key
* @param value
* @return
*/
public boolean set(final String key, Object value) {
boolean result = false;
try {
ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue();
operations.set(key, value);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 写入缓存设置时效时间
* @param key
* @param value
* @return
*/
public boolean set(final String key, Object value, Long expireTime ,TimeUnit timeUnit) {
boolean result = false;
try {
ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue();
operations.set(key, value);
redisTemplate.expire(key, expireTime, timeUnit);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 批量删除对应的value
* @param keys
*/
public void remove(final String... keys) {
for (String key : keys) {
remove(key);
}
}
/**
* 批量删除key
* @param pattern
*/
public void removePattern(final String pattern) {
Set<Serializable> keys = redisTemplate.keys(pattern);
if (keys.size() > 0){
redisTemplate.delete(keys);
}
}
/**
* 删除对应的value
* @param key
*/
public void remove(final String key) {
if (exists(key)) {
redisTemplate.delete(key);
}
}
/**
* 判断缓存中是否有对应的value
* @param key
* @return
*/
public boolean exists(final String key) {
return redisTemplate.hasKey(key);
}
/**
* 读取缓存
* @param key
* @return
*/
public Object get(final String key) {
Object result = null;
ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue();
result = operations.get(key);
return result;
}
/**
* 哈希 添加
* @param key
* @param hashKey
* @param value
*/
public void hmSet(String key, Object hashKey, Object value){
HashOperations<String, Object, Object> hash = redisTemplate.opsForHash();
hash.put(key,hashKey,value);
}
/**
* 哈希获取数据
* @param key
* @param hashKey
* @return
*/
public Object hmGet(String key, Object hashKey){
HashOperations<String, Object, Object> hash = redisTemplate.opsForHash();
return hash.get(key,hashKey);
}
/**
* 列表添加
* @param k
* @param v
*/
public void lPush(String k,Object v){
ListOperations<String, Object> list = redisTemplate.opsForList();
list.rightPush(k,v);
}
/**
* 列表获取
* @param k
* @param l
* @param l1
* @return
*/
public List<Object> lRange(String k, long l, long l1){
ListOperations<String, Object> list = redisTemplate.opsForList();
return list.range(k,l,l1);
}
/**
* 集合添加
* @param key
* @param value
*/
public void add(String key,Object value){
SetOperations<String, Object> set = redisTemplate.opsForSet();
set.add(key,value);
}
/**
* 集合获取
* @param key
* @return
*/
public Set<Object> setMembers(String key){
SetOperations<String, Object> set = redisTemplate.opsForSet();
return set.members(key);
}
/**
* 有序集合添加
* @param key
* @param value
* @param scoure
*/
public void zAdd(String key,Object value,double scoure){
ZSetOperations<String, Object> zset = redisTemplate.opsForZSet();
zset.add(key,value,scoure);
}
/**
* 有序集合获取
* @param key
* @param scoure
* @param scoure1
* @return
*/
public Set<Object> rangeByScore(String key,double scoure,double scoure1){
ZSetOperations<String, Object> zset = redisTemplate.opsForZSet();
return zset.rangeByScore(key, scoure, scoure1);
}
5、测试,编写controller
import java.util.concurrent.TimeUnit;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.chenqi.springboot.redis.RedisUtils;
import com.chenqi.springboot.service.TestService;
@RestController
......
@Autowired
private RedisUtils redisUtils;
@RequestMapping(value = "/hello/{deptNo}")
public Object hello(@PathVariable(value = "deptNo") String deptNo) {
// 查询缓存中是否存在
boolean hasKey = redisUtils.exists(deptNo);
Dept dept = null;
if (hasKey) {
// 获取缓存
Object object = redisUtils.get(deptNo);
log.info("从缓存获取的数据" + object);
dept = (Dept) object;
} else {
// 从数据库中获取信息
log.info("从数据库中获取数据");
dept = deptService.getDeptInfo(Integer.valueOf(deptNo));
// 数据插入缓存(set中的参数含义:key值,user对象,缓存存在时间10(long类型),时间单位)
redisUtils.set(deptNo, dept, 10L, TimeUnit.MINUTES);
log.info("数据插入缓存" + dept);
}
return dept;
}
......
6、启动项目,第一次访问:http://localhost:8002/hello/111
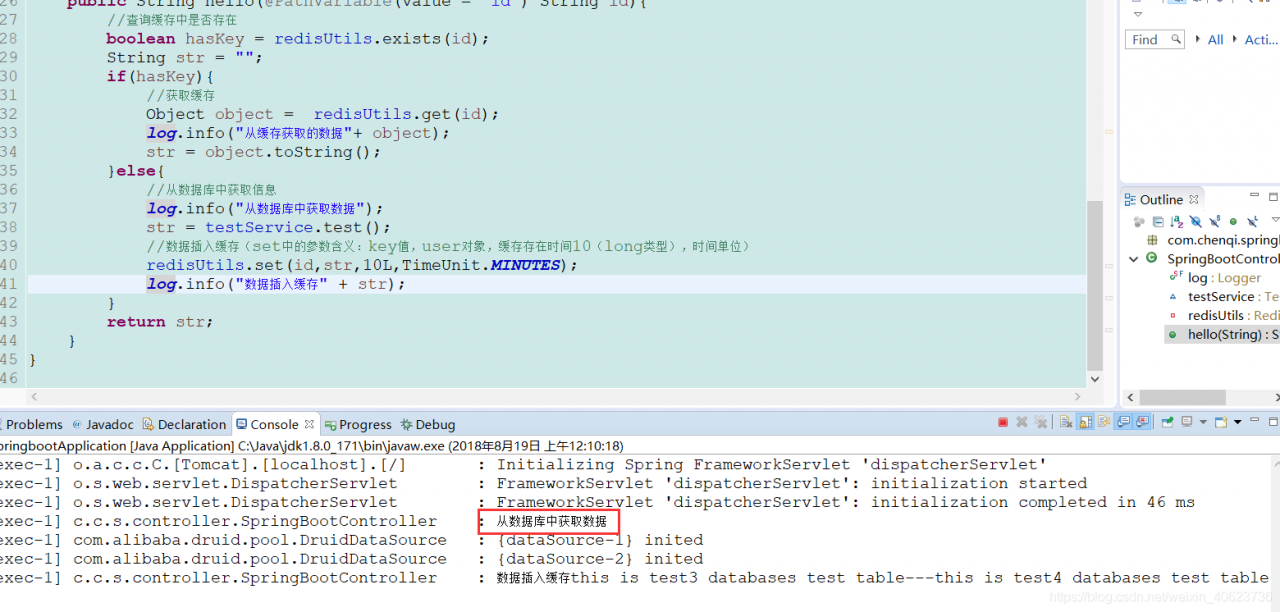
通过控制台输出,我们可以看到是从数据库中获取的数据,并且存入了redis缓存中。
7、我们再次刷新浏览器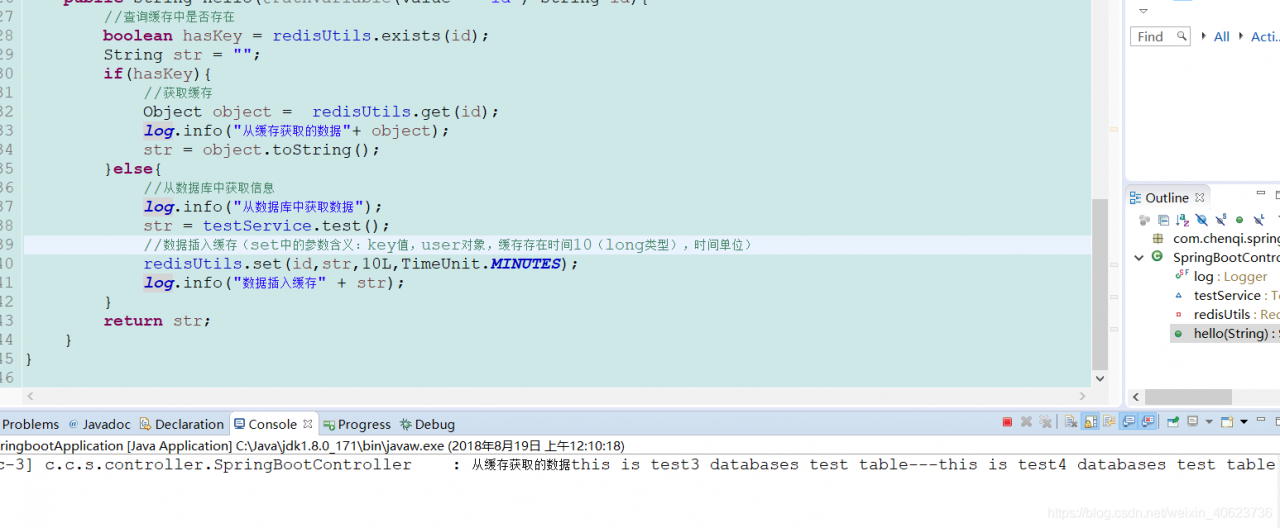
可以看到,第二次是从缓存中读取的,我们试试不断刷新浏览器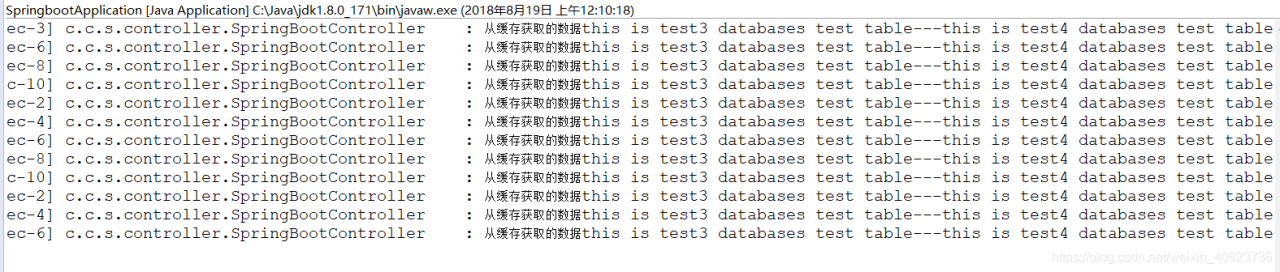
可以看到,之后都是从缓存中获取的。
8、测试Redis
测试输入命令:
redis-cli.exe -h 127.0.0.1 -p 6379
set userinfo zjl
get userinfo
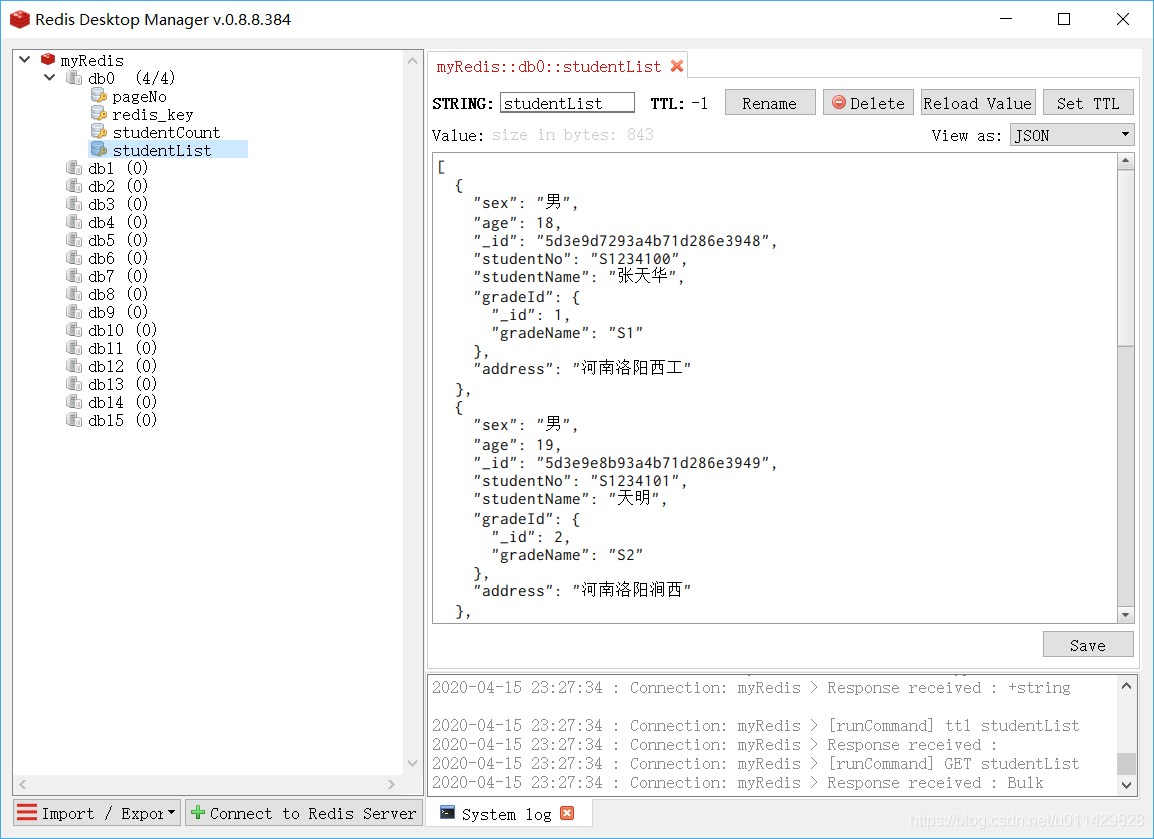
9、使用RedisDesktopManager可视化工具进行查看
四、SpringBoot 使用 Redis 实现 Session 共享
1、 什么是 Session
由于 HTTP 协议是无状态的协议,因而服务端需要记录用户的状态时,就需要用某种机制来识具体的用户。Session
是另一种记录客户状态的机制,不同的是 Cookie 保存在客户端浏览器中,而 Session
保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上,这就是
Session。客户端浏览器再次访问时只需要从该 Session 中查找该客户的状态就可以了。
2、 为什么需要同步session ?
当用户量比较大时候一个tomcat可能无法处理更多的请求,超过单个tomcat的承受能力,可能会出现用户等待,严重的导致tomcat宕机。
这时候我们后端可能会采用多个tomcat去处理请求,分派请求,不同请求让多个tomcat分担处理。
登录的时候可能采用的是tomca1,下单的时候可能采用的是tomcat2 等等等。
若没有session共享同步,可能在tomcat1登录了,下一次请求被分派到tomcat2上,这时候用户就需要重新登录。
在实际工作中我们建议使用外部的缓存设备来共享 Session,避免单个节点挂掉而影响服务,使用外部缓存 Session 后,我们的
共享数据都会放到外部缓存容器中,服务本身就会变成无状态的服务,可以随意的根据流量的大小增加或者减少负载的设备。
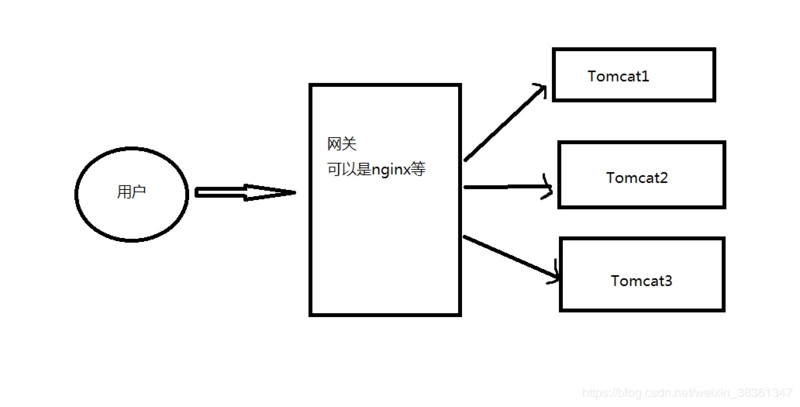
目前主流的分布式 Session 管理有两种方案。
1 Session 复制
部分 Web 服务器能够支持 Session 复制功能,如 Tomcat。用户可以通过修改 Web 服务器的配置文件,让 Web 服务器进行 Session 复制,保持每一个服务器节点的 Session 数据都能达到一致。
这种方案的实现依赖于 Web 服务器,需要 Web 服务器有 Session 复制功能。当 Web 应用中 Session 数量较多的时候,每个服务器节点都需要有一部分内存用来存放 Session,将会占用大量内存资源。同时大量的 Session 对象通过网络传输进行复制,不但占用了网络资源,还会因为复制同步出现延迟,导致程序运行错误。
在微服务架构中,往往需要 N 个服务端来共同支持服务,不建议采用这种方案。
2 Session 集中存储
在单独的服务器或服务器集群上使用缓存技术,如 Redis 存储 Session 数据,集中管理所有的 Session,所有的 Web 服务器都从这个存储介质中存取对应的 Session,实现 Session 共享。将 Session 信息从应用中剥离出来后,其实就达到了服务的无状态化,这样就方便在业务极速发展时水平扩充。
Spring Session
Spring Session 提供了一套创建和管理 Servlet HttpSession 的方案。Spring Session 提供了集群 Session(Clustered Sessions)功能,默认采用外置的 Redis 来存储 Session 数据,以此来解决 Session 共享的问题。
Spring Session 为企业级 Java 应用的 Session 管理带来了革新,使得以下的功能更加容易实现:
API 和用于管理用户会话的实现; HttpSession,允许以应用程序容器(即 Tomcat)中性的方式替换
HttpSession; 将 Session 所保存的状态卸载到特定的外部 Session 存储中,如 Redis 或
Apache Geode 中,它们能够以独立于应用服务器的方式提供高质量的集群; 支持每个浏览器上使用多个
Session,从而能够很容易地构建更加丰富的终端用户体验; 控制 Session ID
如何在客户端和服务器之间进行交换,这样的话就能很容易地编写 Restful API,因为它可以从 HTTP 头信息中获取
Session ID,而不必再依赖于 cookie; 当用户使用 WebSocket 发送请求的时候,能够保持
HttpSession 处于活跃状态。 需要说明的很重要的一点就是,Spring Session 的核心项目并不依赖于
Spring 框架,因此,我们甚至能够将其应用于不使用 Spring 框架的项目中。
3、spring boot中如何使用
首先新建一个springboot项目
1)、pom文件中除了引人redis外还需引入
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
2)、配置
server.port=8080
# Redis 配置
# Redis 数据库索引(默认为0)
spring.redis.database=0
# Redis 服务器地址
spring.redis.host=localhost
# Redis 服务器连接端口
spring.redis.port=6379
# Redis 服务器连接密码(默认为空)
spring.redis.password=
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=8
spring.redis.lettuce.pool.max-wait=-1
spring.redis.lettuce.shutdown-timeout=100
spring.redis.lettuce.pool.max-idle=8
spring.redis.lettuce.pool.min-idle=0
3)、新建一个初始化类
/**
*
* maxInactiveIntervalInSeconds: 设置 Session 失效时间
* 使用 Redis Session 之后,原 Spring Boot 中的 server.session.timeout 属性不再生效。
*
*/
@Configuration
@EnableRedisHttpSession(maxInactiveIntervalInSeconds = 86400*30)
public class SessionConfig {
}
4)、一个控制层
@RequestMapping(value = "/setSession")
public Map<String, Object> setSession (HttpServletRequest request){
Map<String, Object> map = new HashMap<>();
request.getSession().setAttribute("message", request.getRequestURL());
map.put("request Url", request.getRequestURL());
return map;
}
@RequestMapping(value = "/getSession")
public Object getSession (HttpServletRequest request){
Map<String, Object> map = new HashMap<>();
map.put("sessionId", request.getSession().getId());
map.put("message", request.getSession().getAttribute("message"));
return map;
}
@RequestMapping(value = "/login")
public String login (HttpServletRequest request,String userName,String password){
String msg="logon failure!";
if (userName!=null && "admin".equals(userName) && "123".equals(password)){
request.getSession().setAttribute("user",userName);
msg="login successful!";
}
return msg;
}
5)、同上再创建一个项目,该端口为8282
6)、分别启动并测试
在端口是8282 的项目中登录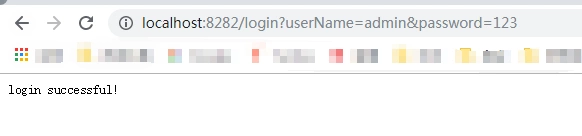 然后在端口是8282 和 8080的项目中获取session
然后在端口是8282 和 8080的项目中获取session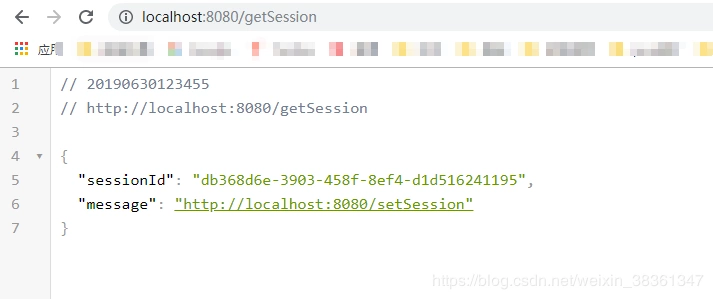
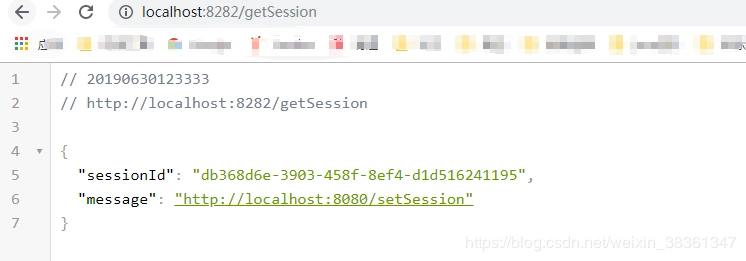
两个服务中session id 是一致的,说明我们的session管理成功。
使用Spring Session 可以将session单独的从每个服务总抽离出来,存储到redis中进行集中管理。
相对于每个服务复制session的方式可谓简便至极,也不需要在每个Tomcat中修改配置文件,添加jar包等操作。
有问题:316572403
原文出处1:http://mp.toutiao.com/preview_article/?pgc_id=6625563203793322503
原文出处2:https://blog.csdn.net/qq_43001609/article/details/82928798
原文出处3:https://blog.csdn.net/weixin_40623736/article/details/98097708