1.单机模式
这是个demo级别的,一般就是你本地启动了玩玩的,没人生产用单机模式
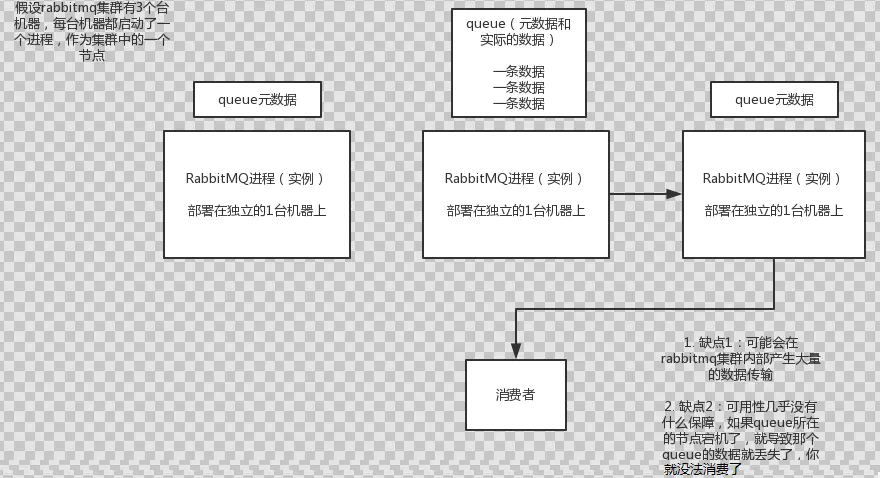
2.普通集群模式
在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是你创建的queue,只会放在一个rabbtimq实例上,但是每个实例都同步queue的元数据(存放真正实例位置)。消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从queue所在实例上拉取数据过来。
因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个queue所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。而且如果那个放queue的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让rabbitmq落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个queue拉取数据。所以这个普通集群比较尴尬了,这就没有什么所谓的高可用性可言了,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个queue的读写操作。
3.镜像集群模式
此模式才是所谓的RabbitMQ的高可用模式,跟普通集群模式不一样的是,创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。
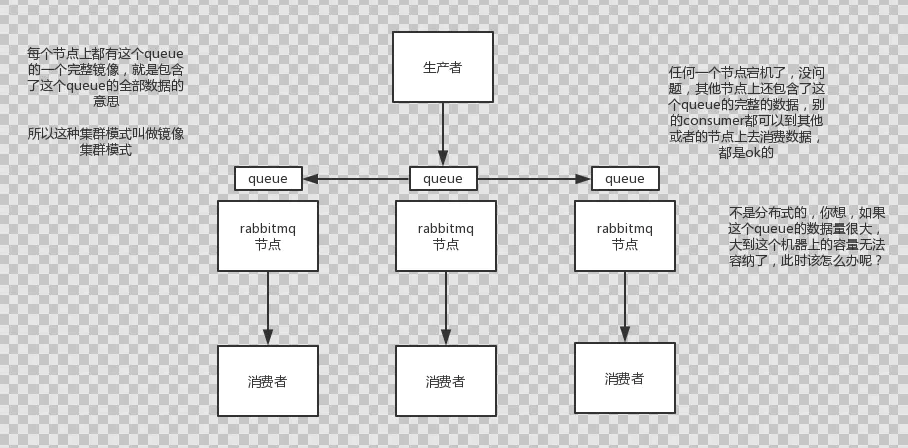
优点:
任何一个机器宕机了,没事儿,别的机器都可以用。
缺点:
1.这个性能开销也太大,消息同步所有机器,导致网络带宽压力和消耗很重!
2.没有扩展性可言,如果某个queue负载很重,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展queue。那么怎么开启这个镜像集群模式呢?其实很简单rabbitmq有很好的管理控制台,可以在后台新增一个策略,这个策略是镜像集群模式的策略,可以指定要求数据同步到所有节点,也可以要求同步到指定数量的节点,然后再次创建queue的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
谢谢阅读!!!
版权声明:本文为caozhengtao1213原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。