Flink
第二部分Flink快速应用
通过一个单词统计的案例,快速上手应用Flink,进行流处理(Streaming)和批处理(Batch)
1、单词统计案例(批处理)
1.1需求
统计一个文件中各个单词出现的次数,把统计结果输出到文件
1.2代码实现
引入依赖
<dependencies> <!--flink核心包--> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.14.4</version> </dependency> <!--flink流处理包--> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.14.4</version> <scope>provided</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.12</artifactId> <version>1.14.4</version> </dependency> </dependencies>Java程序
package com.sugar.test; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.AggregateOperator; import org.apache.flink.api.java.operators.DataSource; import org.apache.flink.api.java.operators.FlatMapOperator; import org.apache.flink.api.java.operators.UnsortedGrouping; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; public class BatchDemo { public static void main(String[] args) throws Exception { // 1、获取flink的执行环境 ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment(); // 2、获取待分析数据 String input = "E:\\hello.txt"; String output = "E:\\out.txt"; DataSource<String> dataSource = executionEnvironment.readTextFile(input); // 3、处理数据 FlatMapOperator<String, Tuple2<String, Integer>> flatMapOperator = dataSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { //3、1 将文本内容打散成一个个单词 String[] split = s.split(" "); for (String word : split) { Tuple2<String, Integer> tuple2 = new Tuple2<>(word, 1); collector.collect(tuple2); } } }); // 3、2 将相同的单词聚在一起 UnsortedGrouping<Tuple2<String, Integer>> group = flatMapOperator.groupBy(0); // 3、3 将聚合到的数据累加操作 AggregateOperator<Tuple2<String, Integer>> sum = group.sum(1); DataSet<Tuple2<String, Integer>> result = sum; // 4、保存处理结果 result.writeAsText(output); // 5、触发程序进行 executionEnvironment.execute("wordCount batch process"); } }结果
2、单词统计案例(流数据)
使用nc监听端口并持续发送数据(netcat)
yum install nc -y
nc -lp 7777
2.1需求
Socket模拟实时发送单词,使用Flink实时接收数据,对指定时间窗口内(如5s)的数据进行聚合统计,每隔1s汇总计算一次,并且把时间窗口内计算结果打印出来。
2.2代码实现
package com.sugar.test;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamDemo {
public static void main(String[] args) throws Exception {
// 获取流的执行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
String hostname = "192.168.13.10";
int port = 7777;
// 获取数据源
DataStreamSource<String> dataStreamSource = streamExecutionEnvironment.socketTextStream(hostname, port);
// 打散
SingleOutputStreamOperator<Tuple2<String, Integer>> singleOutputStreamOperator = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word : s.split(" ")) {
collector.collect(Tuple2.of(word, 1));
}
}
});
// 分组统计
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = singleOutputStreamOperator.keyBy(0).sum(1);
// 打印
sum.print();
// 触发任务执行
streamExecutionEnvironment.execute("wordCount stream process");
}
}
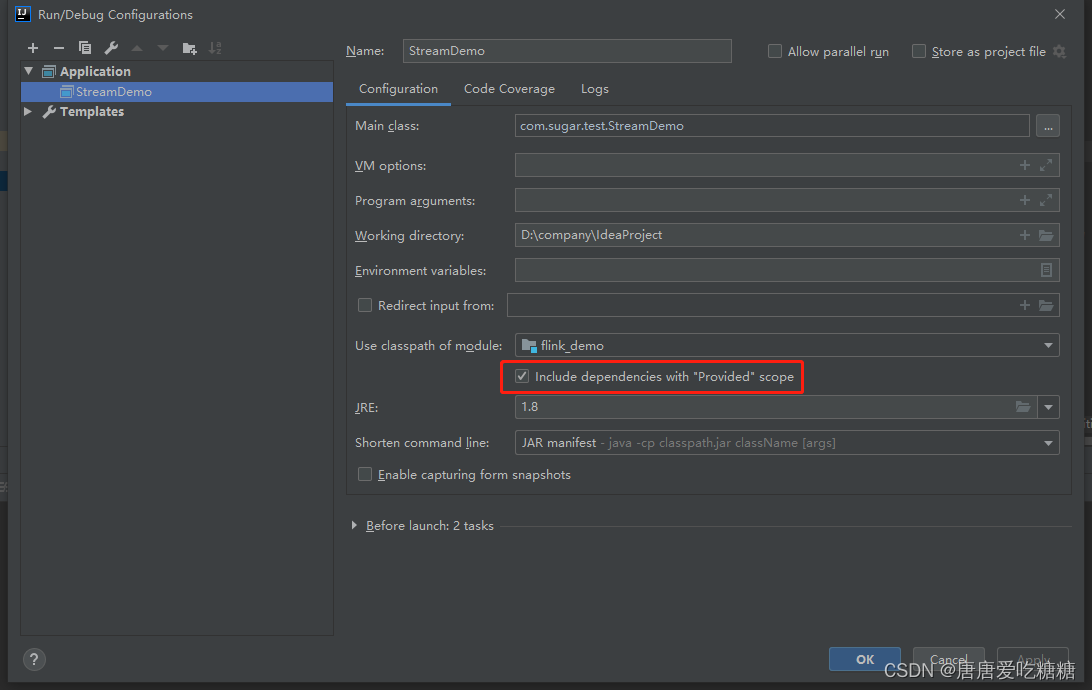
问题解决:
Flink程序开发的流程总结如下:
1)获得一个执行环境
2)加载/创建初始化数据
3)指定数据操作的算子
4)指定结果数据存放位置
5)调用execute()触发执行程序
注意:Flink程序是延迟计算的,只有最后调用execute()方法的时候才会真正触发执行程序
版权声明:本文为qq_45420103原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。