时间序列预测中的机器学习方法(一):移动平均(Moving Average)
1.背景介绍
如果可能的话,每个人都想成为先知,预测在未来会发生什么事。实际上,这种预测非常困难。试想某个人提前知晓了市场发展的方向,那么他将会成为一名亿万富翁。但人们总在不断朝这个方向努力,尤其是在科学技术迅速发展的今天,预测未来不再是虚无缥缈、不着边际的胡话。机器学习算法为我们进行预测提供了新的思路。基于时间序列的预测和建模在数据挖掘和分析中起着重要的作用。
我们希望通过基于时间序列模型的机器学习算法来预测股票、超市销售额、机票订购情况等的发展趋势。预测并不是盲目的,而是基于一定的历史数据。比如要预测某家超市接下来的销量情况为进货提供更好的指导,确保每天的销售货物充足。又或者预测某只股票的涨幅情况,让自己收益最大,损失最小,那么我们必须要对它们的历史数据进行分析。
本文及后续的五篇文章将会使用6种方法来进行数据预测分析。对于提到的这6种机器学习或深度学习算法,我会在以后的文章中详细介绍。这些文章的主要目的是介绍如何把这些方法运用到时间序列预测中,更加偏向解决实际问题。
2.数据集
数据集和文中代码放在了我的GitHub上,需要的朋友可以自行下载:https://github.com/Beracle/02-Stock-Price-Prediction.git
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#setting figure size
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 20,10
#for normalizing data
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
导入数据。
df = pd.read_csv('NSE-TATAGLOBAL11.csv')
df.head()
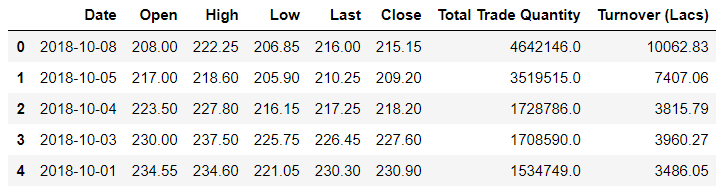
可以看到数据集中有多个变量:日期,开盘价,最高价,最低价,最后一笔,收盘价,总交易量和营业额。
- Open和Close代表该股票在某一天的交易开始和最终的价格。
- High,Low和Last代表当天股票的最高价,最低价和最后价。
- 总交易量(Total Trade Quantity)是当天购买或出售的股票数量,而Turnover是公司在当天的营业额。
需要注意的是周末和公共假期市场休市。在上表中,缺少某些日期值,如2018-10-02(国定假日),2018-10-06(周末),2018-10-07(周末)。
损益计算通常由当天股票的收盘价决定,因此我们将收盘价视为目标变量。
将日期作为索引。(这一步是时间序列预测技术的关键)
#setting index as date
df['Date'] = pd.to_datetime(df.Date, format = '%Y-%m-%d')
df.index = df['Date']
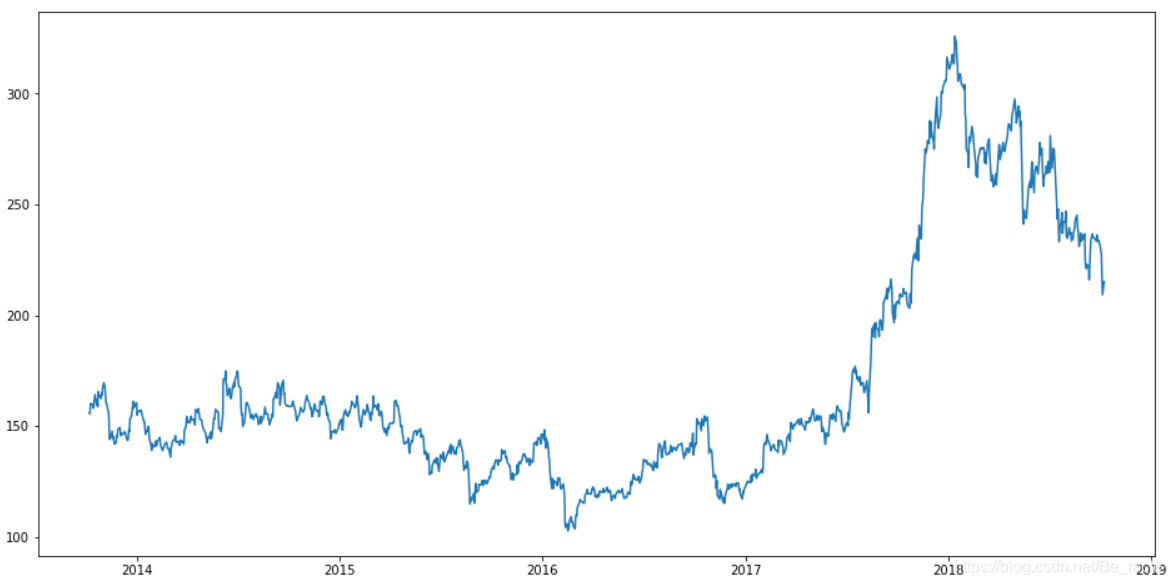
看一下原始数据的时间序列趋势图。
plt.figure(figsize=(16,8))
plt.plot(df['Close'], label='Close Price history')
3.移动平均(Moving Average)
“平均”是我们日常生活中最常见的事物之一。例如,计算平均分数以确定总体性能,或者找到过去几天的平均温度以了解当前的温度。
移动平均(Moving Average)是用来衡量当前趋势的方向。移动平均和一般意义下的平均概念是一致的,都是通过计算过去数据的平均值得到的数学结果。移动平均经常用于金融领域的预测,将计算出的平均值结果绘制成图标,以便于能够观测平滑的数据,而不是聚焦于所有金融市场固有的每日价格波动。移动平均可过滤高频噪声,反映出中长期低频趋势,辅助投资者做出投资判断。“移动”平均不是使用简单的平均值,而是使用移动平均技术,该技术为每个预测使用最新的一组值。换句话说,对于每个后续步骤,在从集合中删除最旧的观察值的同时考虑预测值。数据集在不断“移动”。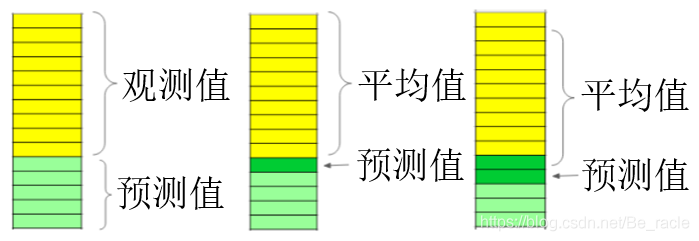
这种计算方法确保只对当前信息进行核算。事实上,任何移动平均算法都会呈现一定的滞后性。它以滞后性的代价换来了平滑性,移动平均必须在平滑性和滞后性之间取舍。
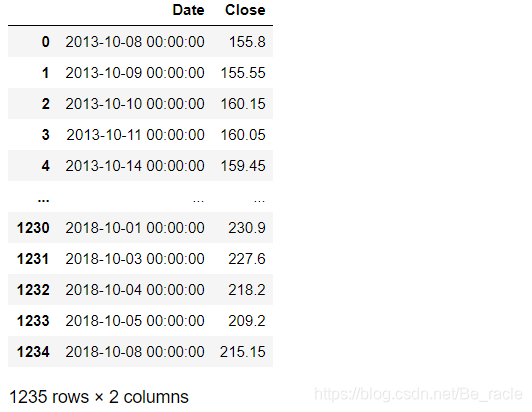
为了不破坏原数据集,我们重新定义一个DataFrame。
#creating dataframe with date and the target variable
data = df.sort_index(ascending=True, axis=0)
new_data = pd.DataFrame(index=range(0,len(df)),columns=['Date', 'Close'])
for i in range(0,len(data)):
new_data['Date'][i] = data['Date'][i]
new_data['Close'][i] = data['Close'][i]
new_data
将数据分为“训练集”和“测试集”。
# splitting into train and validation
train = new_data[:987]
valid = new_data[987:]
print('Shape of training set:')
print(train.shape)
print('Shape of validation set:')
print(valid.shape)

移动平均方法。移动窗口设置为248,所以要想得到第一个预测数据需要从原数据集第739个数开始进行求和平均。
# making predictions
preds = [] #移动平均求出的预测集
for i in range(0,valid.shape[0]):
a = train['Close'][len(train)-248+i:].sum() + sum(preds) #从739开始往后做移动平均
b = a/248 #移动窗口设置为248
preds.append(b)
通过均方根误差(RMSE,Root Mean Square Error)看一下效果。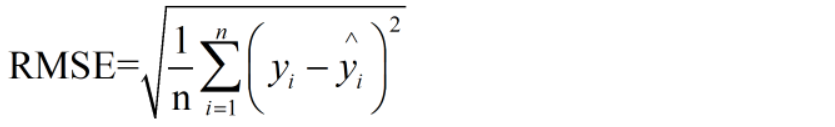
# checking the results (RMSE value)
# 比如RMSE=10,可以认为回归效果相比真实值平均相差10
rms=np.sqrt(np.mean(np.power((np.array(valid['Close'])-preds),2)))
print('RMSE value on validation set:')
print(rms)

通过图直观地看一下预测效果。
valid['Predictions'] = 0
valid['Predictions'] = preds
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
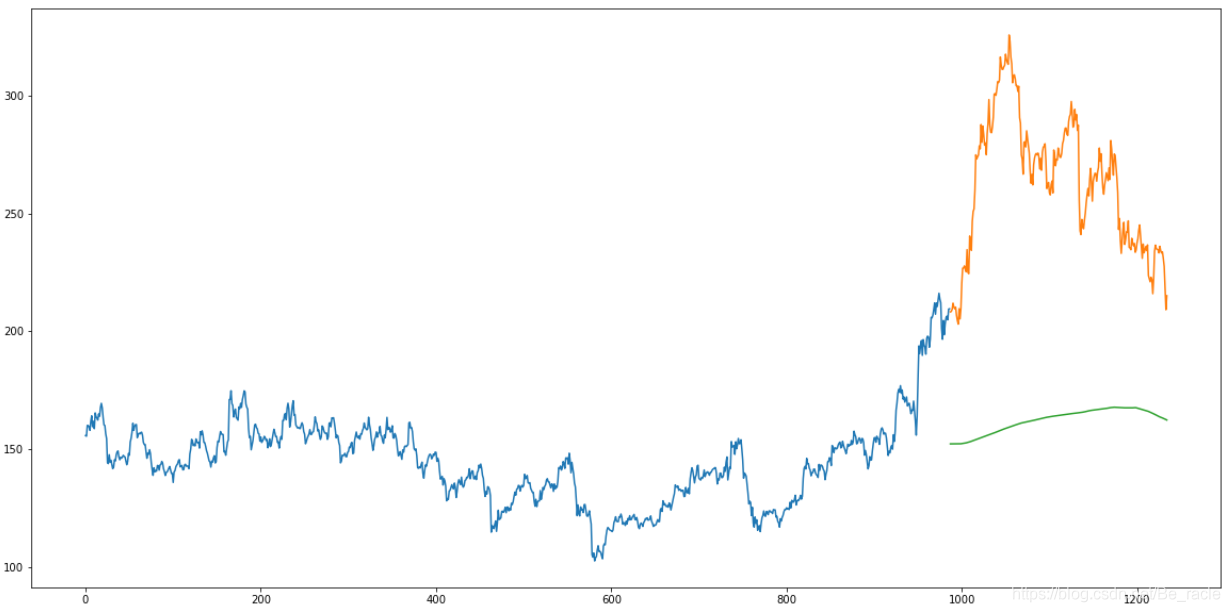
可以看到,移动平均算法对本文选取的数据的预测效果并不好。