语言模型(language model, LM)在自然语言处理中占有重要的地位,尤其在基于统计模型的语音识别、机器翻译、汉语自动分词和句法分析等相关研究中得到了广泛应用。目前主要采用的是n元语法模型(n-gram model),这种模型构建简单、直接,但同时也因为数据缺乏而必须采取平滑(smoothing)算法。
接下来主要介绍n元语法的基本概念和几种常用的数据平滑方法。
目录
n元语法
一个语言模型通常构建为字符串s的概率分布p(s),这里p(s)试图反映的是字符串s作为一个句子出现的频率。例如,在一个刻画口语的语言模型中,如果一个人所说的话语中每100个句子里大约有一句是Okay,则可以认为p(Okay)≈0.01。而对于句子“An apple ate the chicken”我们可以认为其概率为0,因为几乎没有人会说这样的句子。需要注意的是,与语言学中不同,语言模型与句子是否合乎语法是没有关系的,即使一个句子完全合乎语法逻辑,我们仍然可以认为它出现的概率接近为零。
对于一个由l个基元(“基元”可以为字、词或短语等,以后我们只用“词”来通指)构成的句子s=w1w2…wl,其概率计算公式可以表示为:

我们可以看到,产生第i(1≤i≤l)个词的概率是由已经产生的i-1个词w1w2…wi-1决定的。一般地,我们把前i-1个词w1w2…wi-1称为第i个词的“历史(history)”。在这种计算方法中,随着历史长度的增加,不同的历史数目按指数级增长。如果历史的长度为i-1,那么,就有Li-1种不同的历史(假设L为词汇集的大小),而我们必须考虑在所有Li-1种不同的历史情况下,产生第i个词的概率。这样的话,模型中就有Li个自由参数p(wi|w1,w2,…,wi-1)。这使我们基本不可能从训练数据中正确地估计出这些参数。
因此,为了解决这个问题,可以将历史w1w2…wi-1按照某个法则映射到等价类E(w1w2…wi-1),而等价类的数目远远小于不同历史的数目。如果假定:
那么,自由参数的数目就会大大地减少。有很多方法可以将历史划分成等价类,其中,一种比较实际的做法是,将两个历史Wi-n+2…Wi-1Wi和V、Vk-n+2…Vk-1Vk映射到同一个等价类,当且仅当这两个历史最近的n-1(1≤n≤l)个词相同,即如果E(w1w2…wi-1wi)=E(v1v2…vk-1vk),当且仅当(Wi-n+2…Wi-1Wi)=(Vk-n+2…Vk-1Vk)。
满足上述条件的语言模型称为 n 元语法或 n 元文法(n-gram)。通常情况下,n 的取值不能太大,否则,等价类太多,自由参数过多的问题仍然存在。在实际应用中,取n=3的情况较多。当n=1时,即出现在第i位上的词wi独立于历史时,一元文法被记作unigram,或uni-gram,或monogram;当n=2时,即出现在第i位上的词wi仅与它前面的一个历史词wi-1有关,二元文法模型被称为一阶马尔可夫链(Markov chain),记作bigram或bi-gram;当n=3时,即出现在第i位置上的词wi仅与它前面的两个历史词wi-2wi-1有关,三元文法模型被称为二阶马尔可夫链,记作trigram或tri-gram。
以二元语法模型为例,根据前面的解释,我们可以近似地认为,一个词的概率只依赖于它前面的一个词,那么,
![]()
为了使得p(wi|wi-1)对于i=1有意义,我们在句子开头加上一个句首标记〈BOS〉,即假设w0就是〈BOS〉。另外,为了使得所有的字符串的概率之和等于1,需要在句子结尾再放一个句尾标记EOS〉,并且使之包含在等式(5-3)的乘积中(如果不做这样的处理,所有给定长度的字符串的概率和为1,而所有字符串的概率和为无穷大)。例如,要计算概率p(Mark wrote a book),我们可以这样计算:
![]()
为了估计p(wi|wi-1)条件概率,可以简单地计算二元语法wi-1wi在某一文本中出现的频率,然后归一化。如果用c(wi-1wi)表示二元语法wi-1wi在给定文本中的出现次数,我们可以采用下面的计算公式:
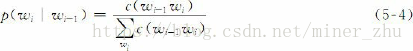
用于构建语言模型的文本称为训练语料(training corpus)。对于n元语法模型,使用的训练语料的规模一般要有几百万个词。公式(5-4)用于估计p(wi|wi-1)的方法称为p(wi|wi-1)的最大似然估计(maximum likelihood estimation, MLE)。
语言模型性能评价
评价一个语言模型最常用的度量就是根据模型计算出的测试数据的概率,或者利用交叉熵(cross-entropy)和困惑度(perplexity)等派生测度。
对于一个平滑过的概率为p的n元语法模型,用公式(5-5)计算句子p(s)的概率。对于句子(t1,t2,…,tlT)构成的测试集T,可以通过计算T中所有句子概率的乘积来计算测试集的概率p(T)
交叉熵的测度可以利用预测和压缩的关系来进行计算。当给定一个语言模型,文本T的概率为p(T),可以给出一个压缩算法,该算法用-log2p(T)个比特位来对文本T编码。模型p的困惑度PPT(T)是模型分配给测试集T中每一个词汇的概率的几何平均值的倒数。显然,交叉熵和困惑度越小越好,这是我们评估一个语言模型的基本准则。
数据平滑
在上面的例子中,如果依据给定的训练语料S计算句子DAVID READ A BOOK的概率,有p(DAVID READ A BOOK)=0。显然,这个结果不够准确,因为句子DAVID READ A BOOK总有出现的可能,其概率应该大于0。如果p(s)=0,那么, p(s|A)也必然是0,这个结果意味着在语音识别中,不管给定的语音信号多么清晰,字符串s也永远不可能成为转写结果。这样,一旦出现使得p(s)=0的字符串s,就会导致识别错误。在其他自然语言处理任务中也会出现类似的问题。因而,必须分配给所有可能出现的字符串一个非零的概率值来避免这种错误的发生。
平滑(smoothing)技术就是用来解决这类零概率问题的。术语“平滑”指的是为了产生更准确的概率(在式(5-4)和式(5-6)中)来调整最大似然估计的一种技术,也常称为数据平滑(data smoothing)。“平滑”处理的基本思想是“劫富济贫”,即提高低概率(如零概率),降低高概率,尽量使概率分布趋于均匀。
例如,对于二元语法来说,一种最简单的平滑技术就是假设每个二元语法出现的次数比实际出现的次数多一次,不妨将该处理方法称为加1法。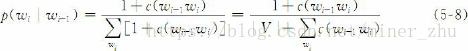
其中,V是所考虑的所有词汇的单词表,|V|为词汇表单词的个数。当然,如果V取无穷大,分母就是无穷大,所有的概率都趋于0。但实际上,词汇表总是有限的,可以大约固定在几万个或者几十万个。所有不在词汇表中的词可以映射为一个单个的区别于其他已知词汇的单词,通常将其称为未登录词或未知词。
数据平滑是语言模型中的核心问题。下面简要介绍一些主要的数据平滑方法。
1.加法平滑方法
在实际应用中最简单的平滑技术之一就是加法平滑方法(additive smoothing),这种方法在上个世纪前半叶由G.J.Lidstone, W.E.Johnson和H.Jeffreys等人提出和改进,其基本思想是使式(5-8)给出的方法通用化,不是假设每一个n元语法发生的次数比实际统计次数多一次,而是假设它比实际出现情况多发生δ次,0≤δ≤1,那么
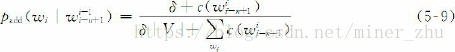
2.古德-图灵(Good-Turing)估计法
Good-Turing估计法是很多平滑技术的核心。这种方法是1953年由I.J.Good引用图灵(Turing)的方法提出来的,其基本思路是:对于任何一个出现r次的n元语法,都假设它出现了r*次,这里
其中,nr是训练语料中恰好出现r次的n元语法的数目。要把这个统计数转化为概率,只需要进行归一化处理:对于统计数为r的n元语法,其概率为
请注意:![]()
也就是说,N等于这个分布中最初的计数。这样,样本中所有事件的概率之和为
因此,有n1/N的概率剩余量可以分配给所有未见事件(r=0的事件)。
3.Katz平滑法
Katz平滑方法通过加入高阶模型与低阶模型的结合,扩展了Good-Turing估计方法。
我们首先来说明一下二元语法模型的Katz对于一个出现次数为r=c的二元语法,使用如下公式计算修正的计数:
![]()
也就是说,所有具有非零计数r的二元语法都根据折扣率dr被减值了,折扣率dr近似地等于,这个减值是由Good-Turing估计方法预测的。从非零计数中减去的计数量,根据低一阶的分布,即一元语法模型,被分配给了计数为零的二元语法。
折扣率dr可以按照如下办法计算:由于大的计数值是可靠的,因此它们不需要减值。尤其对于某些k,S.M.Katz取所有r>k情况下的dr=1,并且建议k=5。对于r≤k情况下的折扣率,减值率由用于全局二元语法分布的Good-Turing估计方法计算,即公式(5-10)中的nr表示在训练语料中恰好出现r次的二元语法的总数。dr的选择遵循如下约束条件:①最终折扣量与Good-Truing估计预测的减值量成比例;②全局二元语法分布中被折扣的计数总量等于根据Good-Turing估计应该分配给次数为零的二元语法的总数。
用类似的方法可定义高阶n元语法模型的Katz平滑算法。正如我们在式(5-12)中所看到的,二元语法模型是由一元语法模型定义的,那么,一般地,类似Jelinek-Mercer平滑方法,S.M.Katz的n元语法模型由Katz的n-1元语法模型定义。为结束递归,用最大似然估计的一元语法模型作为Katz的一元语法模型。
正如前面指出的,当使用Good-Turing估计时一般需要平滑nr,比如,对于那些值非常小的nr。然而,在Katz平滑方法中这种处理并不需要,因为只有当计数r≤k时才使用Good-Turing估计,而对于这些r值来说,nr一般是比较合理的。
Katz平滑方法属于后备(back-off)平滑方法。这种方法的中心思想是,当某一事件在样本中出现的频率大于k时,运用最大似然估计经过减值来估计其概率。当某一事件的频率小于k时,使用低阶的语法模型作为代替高阶语法模型的后备,而这种代替必须受归一化因子α的作用。对于这种方法的另一种解释是,根据低阶的语法模型分配由于减值而节省下来的剩余概率给未见事件,这比将剩余概率平均分配给未见事件要合理。
4.Jelinek-Mercer平滑方法
假定要在一批训练语料上构建二元语法模型,其中,有两对词的同
现次数为0:
c(SEND THE)=0
c(SEND THOU)=0
那么,按照加法平滑方法和Good-Turing估计方法可以得到:
p(THE|SEND)=p(THOU|SEND)
但是,直觉上我们认为应该有:
p(THE|SEND)>p(THOU|SEND)
因为冠词THE要比单词THOU出现的频率高得多。为了利用这种情况,一种处理办法是在二元语法模型中加入一个一元模型。我们知道一元模型实际上只反映文本中单词的频率,最大似然一元模型为

那么,可以按照下面的方法将二元文法模型和一元文法模型进行线性插值:
pinterp(wi|wi-1)=λpML(wi|wi-1)+(1-λ)pML(wi)
其中,0≤λ≤1。由于pML(THE|SEND)=pML(THOU|SEND)=0,根据假定pML(THE)≫pML(THOU),可以得到:
pinterp(THE|SEND)>pinterp(THOU|SEND)这正是我们希望得到的。
一般来讲,使用低阶的n元模型向高阶n元模型插值是有效的,因为当没有足够的语料估计高阶模型的概率时,低阶模型往往可以提供有用的信息。F.Jelinek和R.L.Mercer曾于1980年提出了通用的插值模型,而Peter F.Brown等人给出了实现这种插值的一种很好的办法:![]()
式(5-13)的含义是:第n阶平滑模型可以递归地定义为n阶最大似然估计模型和n-1阶平滑模型之间的线性插值。为了结束递归,可以用最大似然分布作为平滑的1阶模型,或者用均匀分布作为平滑的0阶模型,给定一个固定的pML,可以使用Baum-Welch算法有效地搜索出![]() ,使某些数据的概率最大。为了得到有意义的结果,估计的语料应该与计算pML的语料不同。在留存插值方法(held-out interpolation)中,保留一部分训练语料来达到这个目的,这部分留存语料不参与计算pML。而F.Jelinek和R.L.Mercer提出了一种叫做删除插值法(deleted interpolation)或删除估计法(deleted estimation)的处理技术,训练语料的不同部分在训练pML或
,使某些数据的概率最大。为了得到有意义的结果,估计的语料应该与计算pML的语料不同。在留存插值方法(held-out interpolation)中,保留一部分训练语料来达到这个目的,这部分留存语料不参与计算pML。而F.Jelinek和R.L.Mercer提出了一种叫做删除插值法(deleted interpolation)或删除估计法(deleted estimation)的处理技术,训练语料的不同部分在训练pML或![]() 时作变换,从而使结果平均。
时作变换,从而使结果平均。
需要注意的是,对于不同的历史![]() ,最优的
,最优的![]() 也不同。例如,对于出现过几千次的一段上下文,较高的λ值是比较合适的,因为高阶的分布是非常可靠的。而对于一个只出现过一次的历史,λ的值应较低。独立地训练每一个参数
也不同。例如,对于出现过几千次的一段上下文,较高的λ值是比较合适的,因为高阶的分布是非常可靠的。而对于一个只出现过一次的历史,λ的值应较低。独立地训练每一个参数![]() 是不合适的,因为需要巨大规模的语料来精确地训练这么多独立的参数。为此,建议把
是不合适的,因为需要巨大规模的语料来精确地训练这么多独立的参数。为此,建议把![]() 划分成适当数量的几部分并令同一部分中所有的 具有相同的值,从而减少需要估计的独立参数的数量。根据分布
划分成适当数量的几部分并令同一部分中所有的 具有相同的值,从而减少需要估计的独立参数的数量。根据分布 中每个非零元素的平均统计值来分段,比使用
中每个非零元素的平均统计值来分段,比使用![]() 值分段获得的效果要好。
值分段获得的效果要好。
5.Witten-Bell平滑方法
Witten-Bell平滑方法可以认为是Jelinek-Mercer平滑算法的一个实例。特别地,n阶平滑模型被递归地定义为n阶最大似然模型和n-1阶平滑模型的线性插值,就像式(5-13)所描述的:
![]()
为了引出Witten-Bell平滑方法,可以将式(5-13)解释为:使用高阶模型的概率为,使用低阶模型的概率为1-
,如果在训练语料中对应的n元文法出现次数大于1,则使用高阶模型;否则,后退到低阶模型。这样处理似乎是合理的。
6.绝对减值法
绝对减值法(absolute discounting)类似于Jelinek-Mercer平滑算法,涉及高阶和低阶模型的插值问题。然而,这种方法不是采用将高阶最大似然分布乘以因子 的方法,而是通过从每个非零计数中减去一个固定值D≤1的方法来建立高阶分布。

为使概率分布之和等于1,取
其中,n1和n2是训练语料中分别出现一次和两次的n元语法模型的总数, n是被插值的高阶模型的阶数。
实际上,可以通过Good-Turing估计推导到绝对减值算法。Church and Gale(1991)根据实验指出,对于具有较大计数(r≥3)的n元语法模型,其Good-Turing减值(r-r*)的均值在很大程度上是关于r的常数。而且,等式(5-19)中的比例因子类似等式(5-16)中为Witten-Bell平滑算法给出的模拟因子,可以看作是对同一个值的近似,即出现在一个历史后面的新词的概率。
7.Kneser-Ney平滑方法
R.Kneser和H.Ney提出了一种扩展的绝对减值算法,用一种新的方式建立与高阶分布相结合的低阶分布。在前面的算法中,通常用平滑后的低阶最大似然分布作为低阶分布。然而,只有当高阶分布中具有极少的或没有计数时,低阶分布在组合模型中才是一个重要的因素。因此,在这种情况下,应最优化这些参数,以得到较好的性能。
例如,要在一批语料上建立一个二元文法模型,有一个非常普通的单词FRANCISCO,这个单词只出现在单词SAN的后面。由于
c(FRANCISCO)较大,因此,一元文法概率p(FRANCISCO)也会较大,像绝对减值算法等这类平滑算法就会相应地为出现在新的二元文法历史后面的单词FRANCISCO分配一个高的概率值。然而,从直观上说,这个概率值不应该很高,因为在训练语料中单词FRANCISCO只跟在唯一的历史后面。也就是说,单词FRANCISCO应该接受一个较小的一元文法概率,因为只有上一个词是SAN时这个单词才会出现。在这种情况下,二元文法概率模型可能表现更好。
以此类推,使用的一元文法的概率不应该与单词出现的次数成比例,而是与它前面的不同单词的数目成比例。我们可以设想按顺序遍历训练语料,在前面语料的基础上建立二元文法模型来预测现在的单词。那么,只要当前的二元文法没有在前面的语料中出现,一元文法的概率将会是影响当前二元文法概率的较大因素。如果一旦这种事件发生,就要给相应的一元文法分配一个计数,那么,分配给每个一元文法计数的数目就是它前面不同单词的数目。实际上,在Kneser-Ney平滑方法中,二元文法模型中的一元文法概率就是按这种方式计算的。然而,在文献中这种计算方法却是以完全不同的方式提出来的,其推导过程是,选择的低阶分布必须使得到的高阶平滑分布的边缘概率与训练语料的边缘概率相匹配。例如,对于二元文法模型,选择一个平滑的分布pKN,使其对所有的wi,满足一元文法边缘概率的约束条件:
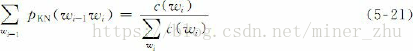
等式(5-21)左边是平滑的二元文法分布pKN中wi的一元文法边缘概率,等式右边是训练语料中wi的一元文法频率。
Chen and Goodman(1998)提出了一种不同的推导方法。他们假设模型具有式(5-18)的形式:

这与R.Kneser和H.Ney在论文[Kneser and Ney,1995]中使用的形式不同,原文中使用的形式是:

这里,选择γ( )使分布之和等于1。也就是说,S.F.Chen等人对所有单词的低阶分布进行插值,而不是只对那些高阶分布中计数为零的单词插值。这样做的原因是因为它不但可以得到比原公式更清晰的推导过程,而且不需要近似。
算法总结
大多数平滑算法可以用下面的等式表示:
![]()
也就是说,如果n阶语言模型具有非零的计数,就使用分布α(wi|);否则,就后退到低阶分布psmooth(wi|
),选择比例因子γ(
)使条件概率分布之和等于1。通常称符合这种框架的平滑算法为后备模型(back-off model)。前面介绍的Katz平滑算法是后备平滑算法的一个典型例子。
有些平滑算法采用高阶和低阶n元文法模型的线性插值,表达成等式,这些模型都可以写成公式(5-24)的形式。这种形式的模型称为插值模型(interpolated model)。
后备模型和插值模型的根本区别在于,在确定非零计数的n元文法的概率时,插值模型使用低阶分布的信息,而后备模型却不是这样。但不管是后备模型还是插值模型,都使用了低阶分布来确定计数为零的n元语法的概率。
Chen and Goodman(1998)使用等式(5-24)的符号概括了该式所代表的所有后备平滑算法,归纳成表5-2。

平滑方法的比较
前面介绍了语言模型中常用的一些平滑方法,包括加法平滑、Jelinek-Mercer平滑、Katz平滑、Witten-Bell平滑、绝对减值平滑和Kneser-Ney平滑,以及Church-Gale平滑和修正的Kneser-Ney平滑方法等。那么,现在的问题是这些平滑方法在实现效果上有什么差异?其平滑效果与数据量和参数设置有怎样的关系?对此,S.F.Chen和J.Goodman做了大量的对比实验,利用布朗语料、北美商务新闻语料、Switchboard语料和广播新闻语料,以测试语料的交叉熵和语音识别结果的词错误率(word error rate)为评价指标,对平滑方法做了全面系统的对比测试,得到了若干重要的结论,对实用语言模型的开发具有重要的参考价值。
在S.F.Chen和J.Goodman的对比实验中,采用留存插值方法(held-out interpolation)的Jelinek-Mercer平滑方法作为对比的基线算法(baseline)。根据他们的对比测试,不管训练语料规模多大,对于二元语法和三元语法而言,Kneser-Ney平滑方法和修正的Kneser-Ney平滑方法的效果都好于其他所有的平滑方法。一般情况下,Katz平滑方法和Jelinek-Mercer平滑方法也有较好的表现,但与Kneser-Ney平滑方法和修正的Kneser-Ney平滑方法相比稍有逊色。在稀疏数据的情况下,Jelinek-Mercer平滑方法优于Katz平滑方法;而在有大量数据的情况下,Katz平滑方法则优于Jelinek-Mercer平滑方法。插值的绝对减值平滑方法和后备的Witten-Bell平滑方法的表现最差。除了对于很小的数据集以外,插值的绝对减值平滑方法一般优于基线算法,而Witten-Bell平滑方法则表现较差,对于较小的数据集,该方法比基线算法差得多。对于大规模数据集而言,这两种方法都比基线算法优越得多,甚至可以与Katz平滑方法和Jelinek-Mercer平滑方法相匹敌。
S.F.Chen和J.Goodman的实验还表明,平滑方法的相对性能与训练语料的规模、n元语法模型的阶数和训练语料本身有较大的关系,其效果可能会随着这些因素的不同而出现很大的变化。例如,对于较小规模的训练语料来说,后备的Witten-Bell平滑方法表现很差,而对于大规模数据集来说,其平滑效果却极具竞争力。
根据S.F.Chen和J.Goodman的实验和分析,下列因素对于平滑算法的性能有一定的影响:
- 影响最大的因素是采用修正的后备分布,例如Kneser-Ney平滑方法所采用的后备分布。这可能是Kneser-Ney平滑方法及其各种版本的平滑算法优于其他平滑方法的基本原因。
- 绝对减值优于线性减值。正如前面指出的,对于较低的计数来说,理想的平均减值上升很快,而对于较大的计数,则变得比较平缓。 Good-Turing估计可以用于预测这些平均减值,甚至比绝对减值还好。
- 从性能上来看,对于较低的非零计数,插值模型大大地优于后备模型,这是因为低阶模型在为较低计数的n元语法确定恰当的减值时提供了有价值的信息。
- 增加算法的自由参数,并在留存数据上优化这些参数,可以改进算法的性能。
修正的Kneser-Ney平滑方法之所以获得了最好的平滑效果,就是得益于上述各方面因素的综合。
语言模型自适应方法
在自然语言处理系统中,语言模型的性能好坏直接影响整个系统的性能。尽管语言模型的理论基础已比较完善,但在实际应用中常常会遇到一些难以处理的问题。其中,模型对跨领域的脆弱性(brittlenessacross domains)和独立性假设的无效性(false independence assumption)是两个最明显的问题。也就是说,一方面在训练语言模型时所采用的语料往往来自多种不同的领域,这些综合性语料难以反映不同领域之间在语言使用规律上的差异,而语言模型恰恰对于训练文本的类型、主题和风格等都十分敏感;另一方面,n元语言模型的独立性假设前提是一个文本中的当前词出现的概率只与它前面相邻的n-1个词相关,但这种假设在很多情况下是明显不成立的。另外,香农实验(Shannon-style experiments)表明,相对而言,人更容易运用特定领域的语言知识、常识和领域知识进行推理以提高语言模型的性能(预测文本的下一个成分)。因此,为了提高语言模型对语料的领域、主题、类型等因素的适应性,提出了自适应语言模型(adaptive language model)的概念。在随后的这些年里,人们相继提出了一系列的语言模型自适应方法,并进行了大量实践。
本节主要介绍三种语言模型自适应方法:基于缓存的语言模型(cache-based LM)、基于混合方法的语言模型(mixture-based LM)和基于最大熵的语言模型。
1.基于缓存的语言模型
基于缓存的语言模型自适应方法针对的问题是,在文本中刚刚出现过的一些词在后边的句子中再次出现的可能性往往较大,比标准的n元语法模型预测的概率要大。针对这种现象,cache-based自适应方法的基本思路是,语言模型通过n元语法的线性插值求得:
插值系数λ可以通过EM算法求得。
常用的方法是,在缓存中保留前面的K个单词,每个词wi的概率(缓存概率)用其在缓存中出现的相对频率计算得出:
![]()
其中,Iε为指示器函数(indicator function)。如果ε表示的情况出现,则Iε=1;否则,Iε=0。
然而,这种方法有明显的缺陷。例如,缓存中一个词的重要性独立于该词与当前词的距离,这似乎是不合理的。人们希望越是临近的词,对缓存概率的贡献越大。研究表明,缓存中每个词对当前词的影响随着与该词距离的增大呈指数级衰减,因此,式(5-27)可以写成:
![]()
文献将式(5-27)称为“正常的基于缓存的语言模型(regular cache-based LM)”,而将式(5-28)称为“衰减的基于缓存的语言模型(decaying cache-based LM)”的实验表明,cache-based自适应方法减低了语言模型的困惑度,式(5-28)比式(5-27)对降低语言模型的困惑度效果更好。
黄非等(1999)提出了利用特定领域中少量自适应语料,在原词表中通过分离通用领域词汇和特定领域词汇,并自动检测词典外领域关键词实现词典自适应,然后结合基于缓存的方法实现语言模型的自适应方法。曲卫民等(2003)通过采用TF-IDF公式代替原有的简单频率统计法,建立基于记忆的扩展二元模型,并采用权重过滤法以节省模型计算量,实现了对基于缓存记忆的语言模型自适应方法的改进。张俊林等(2005)也对基于记忆的语言模型进行了扩展,利用汉语义类词典,将与缓存中所保留词汇语义上相近或者相关的词汇也引入缓存,在一定程度上提高了原有模型的性能。
2.基于混合方法的语言模型
基于混合方法的自适应语言模型针对的问题是,由于大规模训练语料本身是异源的(heterogenous),来自不同领域的语料无论在主题(topic)方面,还是在风格(style)方面,或者同时在这两方面都有一定的差异,而测试语料一般是同源的(homogeneous),因此,为了获得最佳性能,语言模型必须适应各种不同类型的语料对其性能的影响。
基于混合方法的自适应语言模型的基本思想是,将语言模型划分成n个子模型M1,M2,…,Mn,整个语言模型的概率通过下面的线性插值公式计算得到:
![]()
其中,0≤λj≤1,![]() 。λ值可以通过EM算法计算出来。
。λ值可以通过EM算法计算出来。
基于这种思想,该适应方法针对测试语料的实现过程包括下列步骤:
(1) 对训练语料按来源、主题或类型等(不妨按主题)聚类;
(2) 在模型运行时识别测试语料的主题或主题的集合;
(3) 确定适当的训练语料子集,并利用这些语料建立特定的语言模型;
(4) 利用针对各个语料子集的特定语言模型和线性插值公式(5-29),获得整个语言模型
根据实验,基于二元模型和110万词的语料进行训练,基于混合方法的自适应方法使语言模型的困惑度降低了10%。
3.基于最大熵的语言模型
上面介绍的两种语言模型自适应方法采用的思路都是分别建立各个子模型,然后,将子模型的输出组合起来。基于最大熵的语言模型却采用不同的实现思路,即通过结合不同信息源的信息构建一个语言模型。每个信息源提供一组关于模型参数的约束条件,在所有满足约束的模型中,选择熵最大的模型。
由于最大熵模型能够较好地将来自不同信息源的模型结合起来,获得性能较好的语言模型,因此,有些学者研究将基于主题的语言模型(topic-based LM)(主题条件约束)与n元语法模型相结合,用于对话语音识别、信息检索和隐含语义分析等 。
综上所述,语言模型的自适应方法是改进和提高语言模型性能的重要手段之一。由于语言模型广泛地应用于自然语言处理的各个方面,而其性能表现与语料本身的状况(领域、主题、风格等)以及选用的统计基元等密切相关,因此,其自适应方法也要针对具体问题和应用目的(机器翻译、信息检索、语义消歧等)综合考虑。