前不久从大数据局那里接到了一个任务,让我们做一个道路破损的目标检测,上网搜了一搜,发现资料并不是很多。
torch 1.11.0
torchvision 0.12.0
python 3.8
anaconda
2080Ti
数据集是大数据局的,不方便上传。
大部分长这样:图片有部分是带有破损的,可能是避开关键信息吧,我也不是很清楚,但是也是可以传入模型进行训练,精度肯定会收到影响,不过影响甚微。
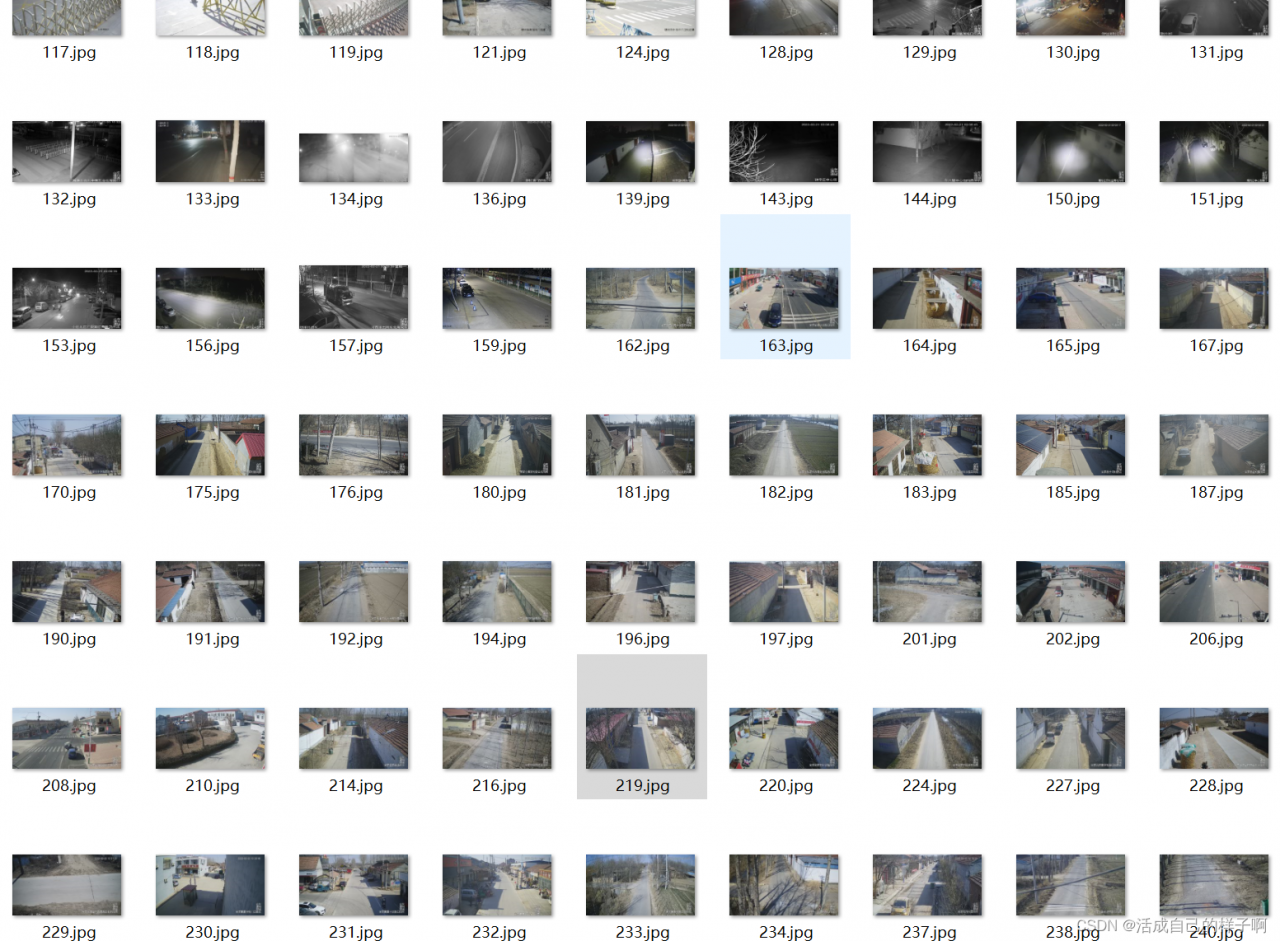
大数据的图片并不是很多,但是用于目标检测是足够了,由于道路破损相对于其他的物体检测显得更为困难,因为它没有固定的形状,大部分都是不规则的裂缝,所以我们又自己找了一些数据集来扩充训练:
下面是之前道路破损比赛的一个官网信息,里面可以下载到数据集。
Overview | 2020 IEEE International Conference on Big Data (sekilab.global)![]() https://rdd2020.sekilab.global/overview/该数据集包含不同国家的道路图像,它们是日本、印度、捷克。
https://rdd2020.sekilab.global/overview/该数据集包含不同国家的道路图像,它们是日本、印度、捷克。


导师建议使用yolov5模型进行训练:
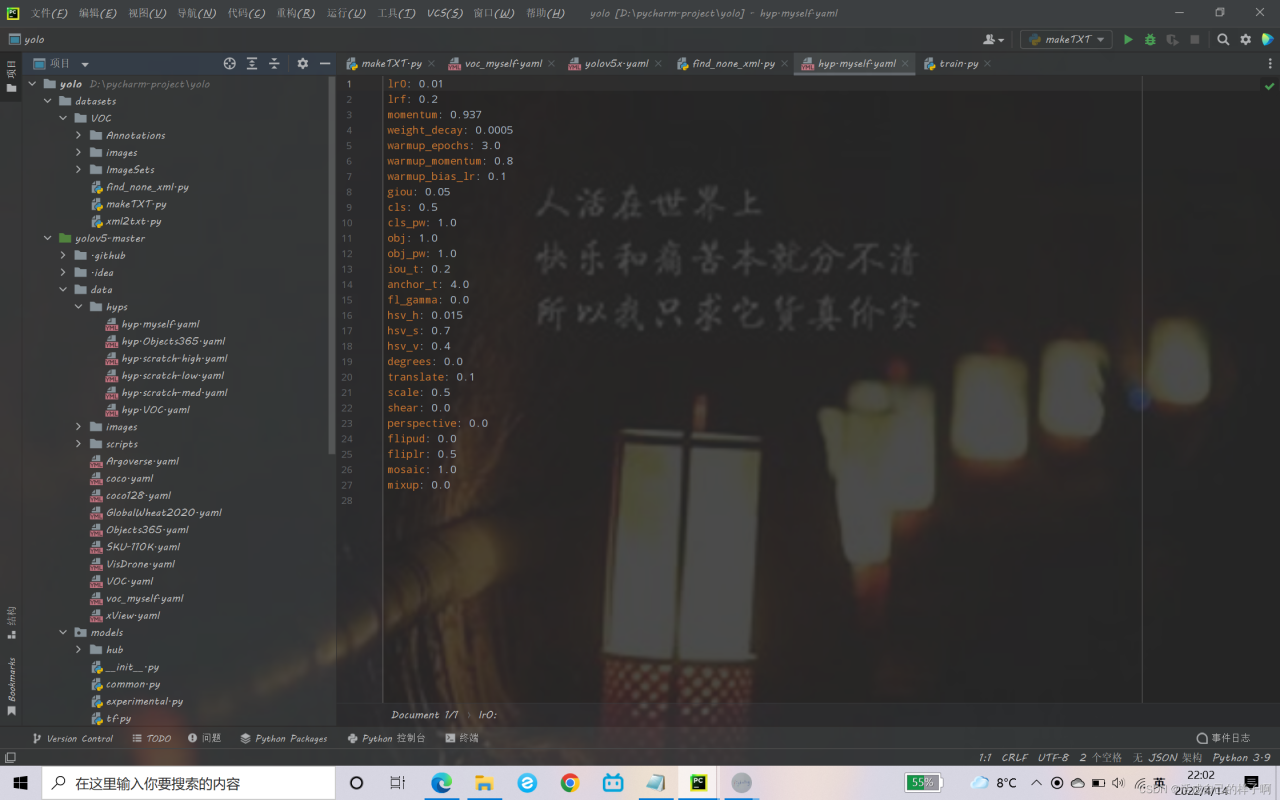
对于yolov5来说,超参数都配置在.\data\hyps\下面;模型都配置在.\models\的下面的yaml文件。
数据集需要如上图所示配置:
datasets--
voc--
Annotations--所有标注(voc)
images--所有图像
ImageSets--
Main--
yolov5-master--
上图VOC里面的3个py文件:
find_none_xml.py:找到所有没有标注框的xml文件
import os
import xml.etree.ElementTree as ET
xml_path = r"Annotations"
signed = 1
print('------------------无标签------------------')
for step, each_xml in enumerate(os.listdir(xml_path)):
if each_xml.split('.')[-1] == 'xml':
with open(xml_path + '/' + each_xml, encoding='utf8') as fp:
try:
tree = ET.parse(fp)
root = tree.getroot()
size = root.find('object')
if size is None:
signed = 0
print('| ', each_xml) # 打印没有框的xml文件
except:
print(each_xml)
if signed == 1:
print('| 所有标签均正常')
print('-----------------------------------------')
else:
print('--------请检查以上文件的标签是否正确!--------')
makeTXT.py:把所有数据划分成为训练集、验证集、测试集
"""生成Main里面的4个txt文件,对应每一个图片名称"""
import os
import random
traintest_percent = 0.9 # 测试集的比例(1-traintest_percent)
train_percent = 0.8 # 训练集和测试集的比例(训练集的占比)
xmlfilepath = 'Annotations' # xml
txtsavepath = 'ImageSets' # 训练集、验证集、测试集的路径
total_xml = os.listdir(xmlfilepath) # 所有xml的名称
num = len(total_xml)
list = range(num) # 【0, num - 1】
tv = int(num * traintest_percent) # 验证集和训练集的数量
tr = int(tv * train_percent) # 训练集数量
# sample(list, k)返回一个长度为k新列表,新列表存放list所产生k个随机唯一的元素
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
# [:-4]切掉后4位(.xml)
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
xml2txt.py:生成yolov5模型所必须的txt文件(最后一步)
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# sets设置的就是
sets = ['train', 'val', 'test']
# 类别
classes = ["0"] # 寻找类别(这里写自己标注的类别就行)
# 转换成yolo格式的标注【类别, x代表标注中心横坐标在图像中的比例,y代表标注中心纵坐标在图像中的比例,w表示标注框宽占比,h表示标注框高占比】
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % image_id, encoding='utf8')
out_file = open('labels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
# b是2个坐标的4个值
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
# 【类别, x代表标注中心横坐标在图像中的比例,y代表标注中心纵坐标在图像中的比例,w表示标注框宽占比,h表示标注框高占比】
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd() # D:\pycharm-project\yolo\datasets\VOC
# sets:train、val、test
for image_set in sets:
# 创建labels
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % image_set).read().strip().split()
list_file = open('%s.txt' % image_set, 'w')
# 对每一张进行操作
for image_id in image_ids:
list_file.write(wd + '\\images/%s.jpg\n' % image_id) # 写入每一个图片的路径
convert_annotation(image_id)
list_file.close()
同级目录下非必须脚本:
open_txt.py(将测试集单独分出)
import os
from shutil import copyfile
test_path = r'test.txt'
target_path = r'tests'
if not os.path.isdir(target_path):
os.mkdir(target_path)
with open(test_path) as fp:
all_img = fp.read()
each_img = all_img.split()
for images in each_img:
img_name = images.split('/')[-1]
copyfile(images, target_path + '/' + img_name)
print(img_name, '复制完毕')
fp.close()
之后不要忘记了配置一下环境:
pip install -r requirements.txt [-i 其他源]布置好我们的数据集,我们直接运行train.py即可!
注意:
这里我们不是分了4类(比赛根据不同的破损类型分了4类),而是只用了一个类别,即所有的道路破损。
我们需要对数据集配置文件进行修改:
voc_myself.yaml:
train: ../datasets/VOC/train.txt #此处是/而不是\
val: ../datasets/VOC/val.txt #此处是/而不是\
test: ../datasets/VOC/test.txt #此处是/而不是\
# Classes
nc: 1 # number of classes 数据集类别数量
names: ['0'] # class names 数据集类别名称,注意和标签的顺序对应终端运行进行训练:
python train.py --cfg .\models\yolov5n.yaml --data .\data\voc_myself.yaml --hyp .\data\hyps\hyp.VOC.yaml --epochs 200 --imgsz 416 --device 0 --single-cls --name first_train --optimizer AdamW --workers 4
经过一系列调参之后的预测结果:
注:
预测是使用的detect.py脚本,如果想看测试集的指标,可以使用val.py脚本(其他yolov5版本也叫test.py)。
作者使用的detect.py是自己微调过的。
为了进一步提高精度,我们之后使用了当时比赛冠军的开源代码:
GitHub - USC-InfoLab/rddc2020: road damage detection challenge 2020![]() https://github.com/USC-InfoLab/rddc2020注意:冠军使用的配置文件和最新版yolov5不一样。
https://github.com/USC-InfoLab/rddc2020注意:冠军使用的配置文件和最新版yolov5不一样。
冠军代码训练效果图预览:

通过Recall、Precision 和Ap指标可以得到冠军的参数配置更有利于道路破损的拟合。
冠军的超参数文件:
hyp.myself.yaml:
lr0: 0.01
lrf: 0.2
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
giou: 0.05
cls: 0.5
cls_pw: 1.0
obj: 1.0
obj_pw: 1.0
iou_t: 0.2
anchor_t: 4.0
fl_gamma: 0.0
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
mosaic: 1.0
mixup: 0.0
相较之下:
yolov5的新提出的一个数据增强未被使用:copy_paste(分割填补 )
边框回归,从最初的IoU到GIoU,随后yolov5又提出了DIoU到CIoU作为边框回归的指标,可以看到冠军的代码是较早的yolov5版本。
