一、 获取并处理环境图像
本文所刨析的代码是“pytorch官网的DQN示例”(页面),用卷积层配合强化训练去学习小车立杆,所使用的环境是“小车立杆环境”(CartPole)(源码)。先剧透个悲观的结果,官网的这个示例,并不能解决小车问题。单好消息是,一个简单的改动,就可以让结果好很多。
小车立杆环境
先import 各种:
import gym
import math
import random
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple
from itertools import count
from PIL import Image
from IPython import display
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as T
创建环境:
env = gym.make('CartPole-v0')
返回的这个env其实并非CartPole类本身,而是一个经过包装的环境:
env<TimeLimit<CartPoleEnv<CartPole-v0>>>
据说gym的多数环境都用TimeLimit(源码)包装了,以限制Epoch,就是step的次数限制,比如限定为200次。所以小车保持平衡200步后,就会失败。
env._max_episode_steps200
用env.unwrapped可以得到原始的类,原始类想step多久就多久,不会200步后失败:
env.unwrappedgym.envs.classic_control.cartpole.CartPoleEnv
环境 env 的 state 返回有4个变量:
env.statearray([0.00884328, 0.04488215, 0.00412898, 0.0128024 ])
它们分别是: (位置x,x加速度, 偏移角度theta, 角加速度)
初值值是4个[-0.05,0.05)的随机数:
from gym.utils import seeding
np_random, seed = seeding.np_random(None)
np_random.uniform(low=-0.05, high=0.05, size=(4,))
其实就是:numpy.random.RandomState.uniform(low=-0.05, high=0.05, size=(4,))。uniform distribution是均匀分布,各个数的出场次数都大致相等。对应的还有标准正态分布randn(),耿贝尔分布gumbel()等等。
这个环境的action有两个 : 0 和 1
env.action_space.n2
env.step(0) :小车向左
env.step(1) :小车向右
小车的世界,就一条x轴,变量env.x_threshold里存放着小车坐标的最大值(=2.4),超过这个数值,世界结束,每step()一次,就会奖励 1,直到上次done为True。这样可以观看到小车移动动画:
env.reset()
for t in count():
env.render()
leftOrRight = random.randrange(env.action_space.n)
_, reward, done, _ = env.step(leftOrRight)
if done:
break

有效世界的范围是:[-x_threshold, x_threshold]。有效世界的总长度为4.8:
world_width = env.x_threshold * 2
可以用env.render()来绘制出这个有效世界,对应的屏幕尺寸为高400、宽600:
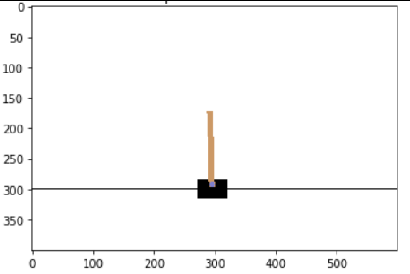
400X600小车有效世界
世界坐标0,是屏幕的中点(300处),世界转屏幕系数为:
scale = screen_width / world_width
目前小车世界坐标x,可以用state[0]取出,这样通过scale,我们就可以计算出目前小车的屏幕坐标了。用 x * scale 得到屏幕坐标。
def get_cart_location(screen_width):
#世界的总长度
world_width = env.x_threshold * 2
#世界转屏幕系数 : world_unit * scale = screen_unit
scale = screen_width / world_width
#世界中点在屏幕中间,所以偏移屏幕一半
return int(env.state[0] * scale + screen_width / 2.0)
环境有个render函数,可以绘制当前场景。
- env = gym.make() 每个env有自己的绘制窗口
- 环境需要初始化env.reset()
- env.render()会打开一个绘制窗口,绘制当前状态
- 每次env.step()会更新状态
- 用完以后需要调用env.close()关闭绘制窗口
render有一个参数,如果指定为 mode='rgb_array'时,不但弹窗渲染,还会返回当前窗口的像素值。整个开发过程,env自己的窗口都会一只存在,不用管它,每次render()它就会刷新,刷新完又“死”了。如果想随时关掉,可以用close(),下次render()会自动打开。
env.reset() screen = env.render(mode='rgb_array') screen.shape(400, 600, 3)
把screen画出来看看:
plt.title('init state') plt.imshow(screen)
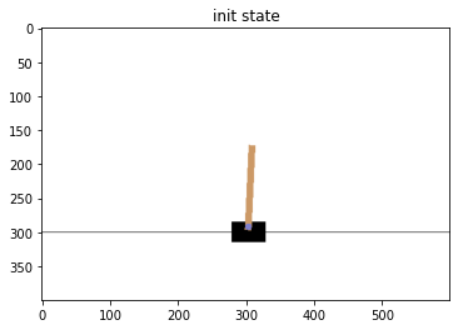
小车大概在高40%(400X0.4=160)到80%(400X0.8=320)之间,所以整个画面可以剪切一下。剪切前先调整一下图片数据的顺序,现在是 400高X600宽X3色,调整为 3色X400X600,便于后续往网络里传输。numpy.transpose()函数,可以指定新的维度顺序,如(2,0,1) 就是将 维度 Y0,X1,C2调整为 C2,Y0,X1。 在pytorch里也有对应的函数,叫torch.Tensor.permute()。
def CutScreen(screen):
Scr2 = screen.transpose((2, 0, 1))
再将高度按照160 - 320 截了:
ScrCut = Scr2[:, int(screen_height*0.4):int(screen_height * 0.8)]
宽度只截取60%,左右各截30%:
view_width = int(screen_width * 0.6)
half_view_width = view_width // 2
如果小车左右还有30%的空间,则从小车位置前后截30%,如果小车太靠左则(或右则)没有30%的空间,则从最左侧(或最右侧)截取60%:
cart_location = get_cart_location(screen_width)
if cart_location < half_view_width:
#太靠左了,左边没有30%空间,则从最左侧截取 [:half_view_width)
slice_range = slice(view_width)
elif cart_location > (screen_width - half_view_width):
#太靠右了,同理 [-half_view_width:)
slice_range = slice(-view_width, None)
else:
#左右两侧都有空间,则截小车在中间 [-half_view_width: +half_view_width)
slice_range = slice(cart_location - half_view_width, cart_location + half_view_width)
#最后将图像X轴截了
ScrCut = ScrCut[:, :, slice_range]
return ScrCut
这样截取函数就好了,看下截取出来的图像。因为plt接受的是 (Y,X,颜色)所以我们还得把顺序临时调整回来:
| C0 | Y1 | X2 |
|---|---|---|
| Y1 | X2 | C0 |
CS = CutScreen(screen) CS = CS.transpose((1, 2, 0)) plt.imshow(CS)
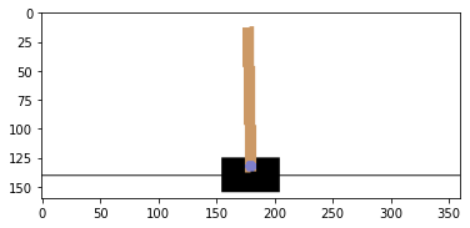
图像还是太大,需要把图片转换为高40的图片,可以用torchvision.transforms 的 Compose()和相关方法。
首先,目前为止,我们的screen都是numpy数组,需要用ToPILImage()转换为PIL,python自带图像格式,然后才可以用torchvision去处理图像,如 Resize(),最后记得转换为pytorch使用的tensor格式:
resize = T.Compose([T.ToPILImage(),
T.Resize(40, interpolation=Image.CUBIC),
T.ToTensor()])
接下来获取divice,以便pytorch可以使用显卡GPU:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") devicedevice(type='cuda')
定义我们的最终获取图像的处理过程:
def get_screen():
screen = env.render(mode='rgb_array')
screen = CutScreen(screen)
现在screen的格式是numpy数组,值范围[0, 255],int8。而PIL接受的是float32的tensor,值范围[0.0, 1.0],所以需要转换一下,可以这样:
screen = torch.from_numpy(np.float32(screen)/255)
但是这样会引起内存数据拷贝。有一种inplace转换数据类型的方法:
y = x.view('float32')
这样y的内存和x是一致的,修改y,也会修改掉x。但是这个函数有个要求,就是数据必须是contiguous的,而我们的screen,不是:
ValueError: To change to a dtype of a different size, the array must be C-contiguous
screen.flagsC_CONTIGUOUS : False
F_CONTIGUOUS : False
……
如果想要数据contiguous,就要用到ascontiguousarray()函数,可以将内存按照C方式对齐,这样python就可以inplace转换数据类了。所以示例用了这个方法,不用进行内存拷贝而达到同样的效果:
screen = np.ascontiguousarray(screen, dtype=np.float32) / 255
screen = torch.from_numpy(screen)
最后放入resize。
因为pytorch.nn.Conv2d() 的输入形式为(N, C, Y, X)
N表示batch数
C表示channel数
Y,X表示图片的高和宽。
所以需要再增加一个N,最后再放入GPU:
return resize(screen).unsqueeze(0).to(device)
unsqueeze()的作用是在n维之前增加一个维度,这里是在0维之前增加一个维度,增加前 screen尺寸是
torch.Size([3, 40, 90])
增加维度后,变为:
torch.Size([1, 3, 40, 90])
再来实际看一下这个,尺寸等比缩小,高为40的图片。想要plt get_screen()返回的东西,先要将其放回到CPU,然后去掉batch,调换方向把颜色放到后边,再转换为numpy:
scr = get_screen().cpu().squeeze(0).permute(1, 2, 0).numpy()
plt.figure()
plt.imshow(scr)
plt.title('Example extracted screen')
plt.show()
40 X 90
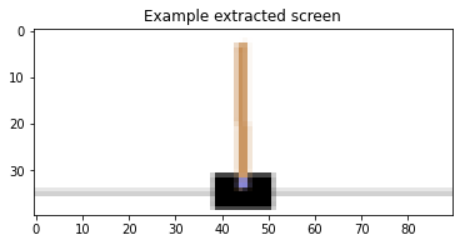
OK。图像处理完了,接下来要定义网络,训练网络了。
第二部分(连接)
二、 卷积网络和训练
接上回 处理环境图片。
python几处值得关注的用法(连接)
示例用卷积网络来训练动作输出:
def conv2d_size_out(size, kernel_size = 5, stride = 2):
return (size - (kernel_size - 1) - 1) // stride + 1
class DQN(nn.Module):
def __init__(self, h, w, outputs):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 32, kernel_size=5, stride=2)
self.bn3 = nn.BatchNorm2d(32)
convw = conv2d_size_out(conv2d_size_out(conv2d_size_out(w)))
convh = conv2d_size_out(conv2d_size_out(conv2d_size_out(h)))
linear_input_size = convw * convh * 32
self.head = nn.Linear(linear_input_size, outputs)
# Called with either one element to determine next action, or a batch
# during optimization. Returns tensor([[left0exp,right0exp]...]).
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
return self.head(x.view(x.size(0), -1))
还是比较直白的:
- Conv 3通道 16通道
- Conv 16通道 32通道
- Conv 32通道 32通道
- Linear 512节点 2节点
为何第2层最后转为512节点,用到了卷积形状计算公式:

conv 为某维度上卷积后的尺寸,X为卷积前的尺寸。
(W - kernel_size + 2 * padding ) // stride + 1
示例中的Conv层没有padding,所以公式变为:
(size - kernel_size) // stride + 1
但不知为何示例代码将 - kernel_size 写为 - (kernel_size - 1) - 1。因为两者完全相等:
def conv2d_size_out(size, kernel_size = 5, stride = 2):
return (size - (kernel_size - 1) - 1) // stride + 1
这只是某个维度的一次卷积变化,所以一张图,完整的尺寸应该是2个维度的乘积,再经过3层变化,乘上第三层通道数,就是最终全连接层的大小:convw * convh * 32。代码写作:
convw = conv2d_size_out(conv2d_size_out(conv2d_size_out(w)))
convh = conv2d_size_out(conv2d_size_out(conv2d_size_out(h)))
linear_input_size = convw * convh * 32
这个网络的输出为动作值,动作值为0或1,但0/1代表的是枚举类型,并不是值类型,也就是说,动作0并不意味着没有,动作1也不意味着1和0之间的某种数值度量关系,0和1纯粹是枚举,所以输出数为2个,而不是1个。应为将图像缩放到40 x 90,所以网络的参数就是(40, 90,2)。试一下这个网络:
net = DQN(40, 90, 2).to(device) scr = get_screen() net(scr)tensor([[-1.0281, 0.0997]], device='cuda:0', grad_fn=<AddmmBackward>)
OK,返回两个值。
行动决策采用 epsilon greedy policy,就是有一定的比例,选择随机行为(否则按照网络预测的最佳行为行事)。这个比例从0.9逐渐降到0.05,按EXP曲线递减:
EPS_START = 0.9 # 概率从0.9开始
EPS_END = 0.05 # 下降到 0.05
EPS_DECAY = 200 # 越小下降越快
steps_done = 0 # 执行了多少步
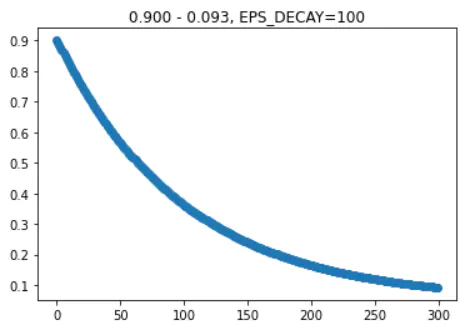
100时
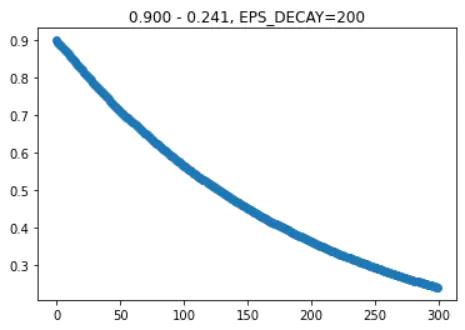
200时
随机行为是强化学习的灵魂,没有随机行动,就没有探索,没有探索就没有持续的成长。select_action() 的作用就是 选择网络输出的2个值中的最大值()或 随机数
def select_action(state):
global steps_done
sample = random.random() #[0, 1)
#epsilon greedy policy。EPS_END 加上额外部分,steps_done 越小,额外部分越接近0.9
eps_threshold = EPS_END + (EPS_START - EPS_END) * math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
#选择使用网络来做决定。max返回 0:最大值和 1:索引
return policy_net(state).max(1)[1].view(1, 1)
else:
#选择一个随机数 0 或 1
return torch.tensor([[random.randrange(n_actions)]], device=device, dtype=torch.long)
通常网络做枚举输出,是需要用到CrossEntropy的。(关于CrossEntropy的文章),示例代码在使用网络时,简单判断了一下,谁大就取谁的索引,所以就相当于做了一个CrossEntropy。
pytorch 的 tensor.max() 返回所有维度的最大值及其索引,但如果指定了维度,就会返回namedtuple,包含各维度最大值及索引 (values=..., indices=...) 。
max(1)[1] 只取了索引值,也可以用 max(1).indices。view(1,1) 把数值做成[[1]] 的二维数组形式。为何返回一个二维 [[1]] ? 这是因为后面要把所有的state用torch.cat() 合成batch(cat()说明连接)。
return policy_net(state).max(1)[1].view(1, 1)
# return 0 if value[0] > value[1] else 1
示例中,训练是用两次屏幕截图的差别来训练网络:
for t in count():
# 1. 获取屏幕 1
last_screen = get_screen()
# 2. 选择行为、步进
action = select_action(state)
_, reward, done, _ = env.step(action)
# 3. 获取屏幕 2
current_screen = get_screen()
# 4. 计算差别 2-1
state = current_screen - last_screen
# 5. 优化网络
optimize_model()
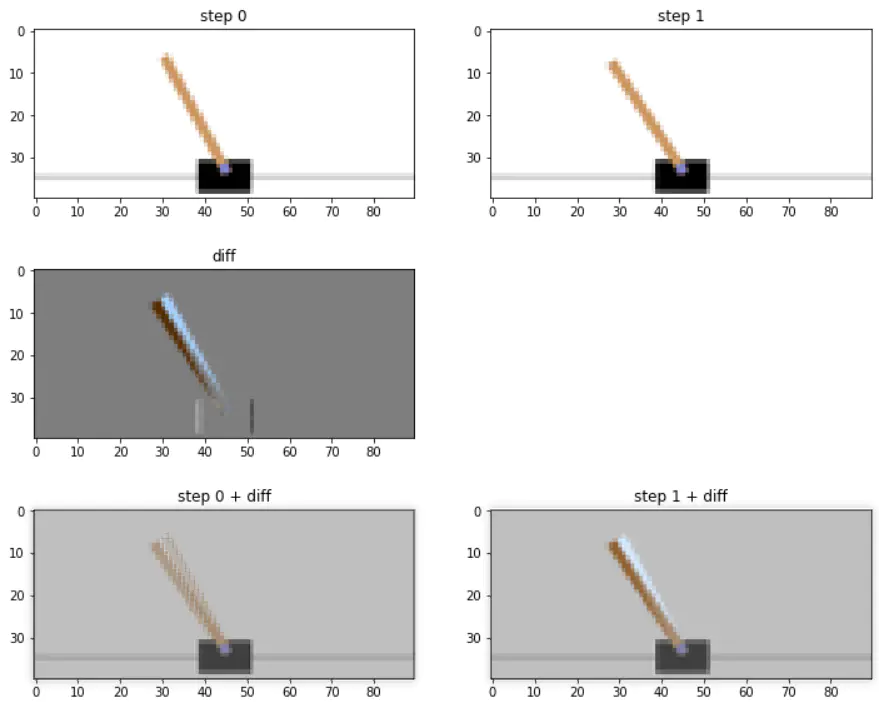
当前状态及两次状态的差,如下所示,
- 上边两个分别是step0和step1原图
- 中间灰色图是差值部分,蓝色是少去的部分,棕色是多出的部分
- 下面两图是原始图覆盖差值图,step0将完全复原为step1,step1则多出部分颜色加强
可以看出,差值是step0到step1的变化。
以下是关键训练循环代码,逻辑是一样的。只是有一处需要注意,在循环的时候,会将(state, action, next_state, reward)这四个值,保存起来,循环存放在一个叫memory的列表里,凑够批次后,才会用数据训练网络,否则optimize_model()直接返回。
num_episodes = 50
TARGET_UPDATE = 10
for i_episode in range(num_episodes):
env.reset()
last_screen = get_screen()
current_screen = get_screen()
state = current_screen - last_screen
# [0, 无限) 直到 done
for t in count():
action = select_action(state)
_, reward, done, _ = env.step(action.item())
reward = torch.tensor([reward], device=device)
last_screen = current_screen
current_screen = get_screen()
next_state = None if done else current_screen - last_screen
// 保存 state, action, next_state, reward 到列表 memory
state = next_state
optimize_model()
if done:
break
关于optimize_model(),大致过程是这样的:
- 从memory列表里选取n个 (state, action, next_state, reward)
- 用net获取state的 Y[0,1](net输出为2个值),再用action选出结果y
- 用net获取next_state获取Y'[0,1],取最大值y'。如果state没有对应的next_state,则y'=0
- 用公式算出期望y:
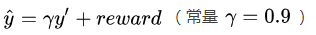
- 用smooth_l1_loss计算误差
- 用RMSprop 反向传导优化网络
期望y的计算方法很简单,就是把next_state的net结果,直接乘一个0.9然后加上奖励。如果有 next_state,就是1,如果next_state为None,奖励是0。因此,没有明天的state,期望y最小。
这里的关键是如何求期望y,用了Q learning:Q Learning解释
也就是遗忘率为1的Q learning求值函数。为何遗忘率是1呢?我的想法是,在NN optimize的时候,本身就是有一个learning rate的,就相当于 ![]() ,所以 Q Learning 公式中的
,所以 Q Learning 公式中的 ![]()
前面的部分就省掉了。
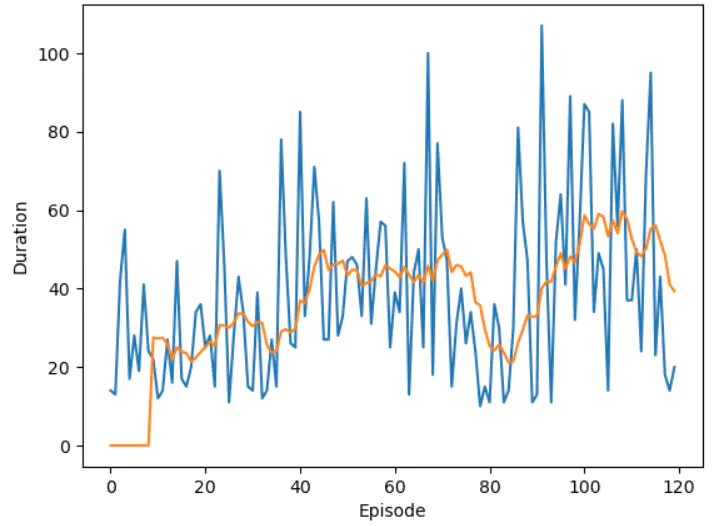
示例使用的gamma 为0.99,效果并不好,几乎不会学习。我改为0.7后,训练120次达到57步,总的来说,就小车环境而言,示例中的卷积网络,效果比128节点的全连接层网络差太多。128节点的全连接层网络,训练几十次就可以达到满分200步。
这是训练中持续时长统计,橙色为平均值,最高也就是50多,感觉示例代码的效果并不是很好。OpenAI官方的要求是,连续跑100次平均持续时长为195。这是gamma改为0.7后的训练结果。