1. 创建普通 RDD
1.1 设置日志级别
sc.setLogLevel("WRAN")
sc.setlogLevel("INFO")
1.2创建 RDD 的快捷方式
1.2.1 从集合中创建 RDD( parallelize() 可以指定分区)
val list = List("A", "B", "C", "D")
val rdd1 = sc.parallelize(list)
// _.partitions.size 分区数
rdd1.partitions.size
> 2
val rdd2 = sc.parallelize(list, 3)
// _.partitions.size 分区数
rdd1.partitions.size
> 3
1.2.2 从集合中创建 RDD (makeRDD() 不可以指定分区)
val list = sc.makeRDD(List("A", "B", "C", "D"))
list.partitions.size
> 2
val list = sc.makeRdd(List("A", "B", "C", "D"), 3)
list.partitions.size
> 3
1.2.3 从外部储存创建 RDD
// 通过textFlie()直接加载数据文件为 RDD
val localdata = sc.textFile("file:///opt/words.text")
localdata.partitions.size
> 2
val hdfsdata = sc.textFile("user/root/a.text")
hdfsdata.partitions.size
> 2
1.3 将数据上传到 HDFS 文件系统
// 上传
hdfs dfs -put student.txt /user/root
hdfs dfs -put result_bigdata /user/root
hdfs dfs -put result_math /user/root
//读取
val bigdata = sc.textFile("result_bigdata")
val math = sc.textFile("result_math")
2. map
作用: 将原来 RDD 的每个数据项通过 map 中用户自定义函数转换为一个新的 RDD ,map 的操作不会影响 RDD 的分区数目
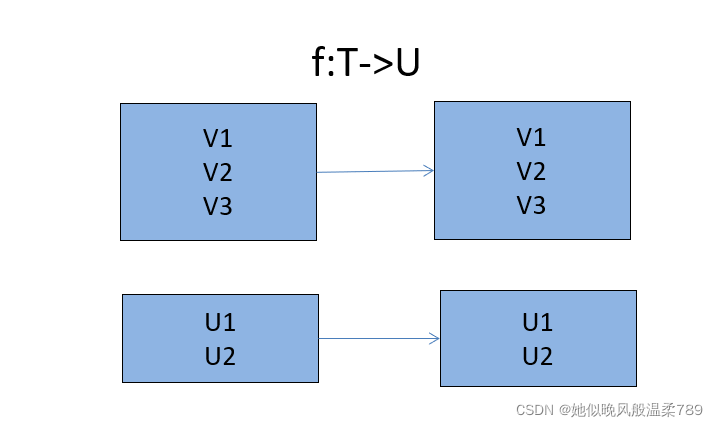
2.2 map 的基本操作
2.2.1 使用 map 函数对 RDD 中每个元素进行倍数操作
val list = sc.parallelize(List(1,2,3,4,5))
val square = list.map(x => x * x)
square.collect
> res5: Array[Int] = Array(1, 4, 9, 16, 25)
2.2.2 使用 map 函数产生键值对 RDD
val list = sc.parallelize(List("zhong", "hong", "xiong"))
val dicts = list.map(x => (x,1))
dicts.collect
> res8: Array[(String, Int)] = Array((zhong,1), (hong,1), (xiong,1))
2.2.3 使用 flatmap 对集合中的每个元素进行操作再扁平化
val list = sc.parallelize(List("hello word", "we are coming"))
list.foreach(x => println(x.makSting))
>hello word
>we are comeing
3. mapPartitions
mapPartitions: 和 map 功能类似,但是输入的元素是整个分区,即传入函数的操作对象是每个分区的 Iterator 集合,该操作不会导致 Partitions 数量的变化
object hello {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("hello").setMaster("local")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(1 to 10)
val mapp = rdd.mapPartitions(iter => iter.filter(_>3))
mapp.foreach(print)
println()
}
}
> 45678910
4. sortBy 对标准的 RDD 排序
sortBy() 是对标准的 RDD 进行排序的方法
sortBy() 可以接受三个参数:
1.一个函数 f:(T) => k,左边是要被排序对象中的每一个元素,右边返回的值是进行元素排序的值。
2. ascending 决定排序后的 RDD 是升序还是降序,默认是 ture 也就是升序
3. numPartitions 决定排序后的 RDD 的分区个数,默认排序前后 RDD 分区个数不变
val data = sc.parallelize(List(5,10,40))
println(data)
val sort_data = data.sortBy(x => x, false)
sort_data.foreach(println)
> 40
> 10
> 5
5. filter 对元素进行过滤
filter 对元素进行过滤,对每个元素应用给定函数,返回值为 ture 的元素在 RDD 中保留,为 false 的则被过滤。
val data = sc.parallelize(1 to 10 by 2)
val result = data.filter(x => x > 5)
result.foreach(println)
> 7
> 9
6. distinct 对 RDD 进行去重
distinct 针对 RDD 重复的元素只保留一个 (去重)
val data = sc.parallelize(List(1,2,2,5,5,7,2,11,1))
val dis_data = data.distinct()
dis_data.foreach(println)
> 11
> 1
> 7
> 5
> 2
7. union 合并两个相同元素类型的 RDD
合并 RDD 需要保证两个 RDD 元素类型一致
val rdd1 = sc.parallelize(1 to 10 by 2)
val rdd2 = sc.parallelize(1 to 10 by 3)
val unions = rdd1.union(rdd2)
unions.foreach(println)
> 1
> 3
> 5
> 7
> 9
> 1
> 4
> 7
> 10
8. subtract 取差集
subtract A.subtract(B) 返回在 B 中 A和B 不共有的部分
val rdd1 = sc.parallelize(List("A", "B", "C"))
val rdd2 = sc.parallelize(List("B", "C", "E"))
val sub1 = rdd1.subtract(rdd2)
for( i <- sub1)println("rdd1 to rdd2: " + i)
val sub2 = rdd2.subtract(rdd1)
sub2.foreach(x => println("rdd2 to rdd1: " + x))
> rdd1 to rdd2: A
> rdd2 to rdd1: E
9. instersection 取交集
instersection A.instersection(B) 返回在 B 中 A和B共有的部分
val rdd1 = sc.parallelize(List("A", "B", "C"))
val rdd2 = sc.parallelize(List("B", "C", "E"))
val inter1 = rdd1.intersection(rdd2)
for(i <- inter1)println("rdd1 in rdd2: " + i)
val inter2 = rdd2.intersection(rdd1)
inter2.foreach(x => println("rdd2 in rdd1: " + x))
> rdd1 in rdd2: B
> rdd1 in rdd2: C
> rdd2 in rdd1: B
> rdd2 in rdd1: C
10. cartesian 两个集合中的元素两两组合成一组
cartesian 笛卡尔积就是将两个集合的元素两两组合成一组
在这里插入代码片
val rdd1 = sc.parallelize(List("A", "B", "C"))
val rdd2 = sc.parallelize(List("B", "C", "E"))
val cart = rdd1.cartesian(rdd2)
cart.foreach(println)
> (A,B)
> (A,C)
> (A,E)
> (B,B)
> (B,C)
> (B,E)
> (C,B)
> (C,C)
> (C,E)
2 键值对 PairRDD
键值对 RDD 由一组组的键值对组成,这些 RDD 被称为 PairRDD
PairRDD 提供了并行操作各个键跨节点重新进行数据分组的操作接口
2.1 mapValues 对键值对的 vlaue 进行 map 操作
mapValues 是针对键值对(key, value)类型的数据中的 value 进行 map 操作,而不对 key 进行处理

val sc = new SparkContext(new SparkConf().setAppName("mapValueTest").setMaster("local"))
.textFile("./data/1.txt").flatMap(_.split("")).map((_, 1)).reduceByKey(_ + _)
.mapValues((_, 10)).foreach(println(_))
> (spark,(1,10))
> (hadoop,(2,10))
> (word,(1,10))
> (hello,(5,10))
> (kafka,(1,10))
2.2 groupBy 将 RDD 的各个元素根据这个 key 分组
new SparkContext(new SparkConf().setMaster("local").setAppName("groupByTest"))
.parallelize(1 to 10).groupBy(x => if (x % 2 == 0) "even" else "odd")
.foreach(println)
> (even,CompactBuffer(2, 4, 6, 8, 10))
> (odd,CompactBuffer(1, 3, 5, 7, 9))
2.3 reduceByKey 对相同 key 的 value 值进行操作
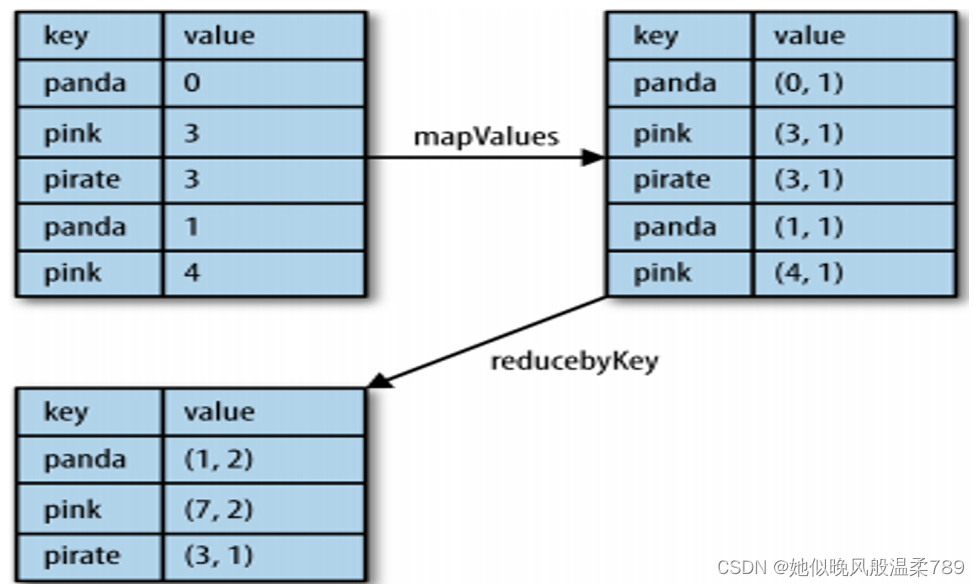
val sc = new SparkContext(new SparkConf().setAppName("reduceByTest").setMaster("local"))
val value = sc.parallelize(List(("a", 18), ("b", 11), ("a", 12), ("b", 5), ("c", 1), ("d", 2)))
val value1 = value.mapValues((_, 5))
value1.foreach(println(_))
println("*************")
value1.reduceByKey((x,y) => (x._1 + y._1, x._2 + y._2))
.foreach(println(_))
> (a,(18,5))
> (b,(11,5))
> (a,(12,5))
> (b,(5,5))
> (c,(1,5))
> (d,(2,5))
> *************
> (d,(2,5))
> (a,(30,10))
> (b,(16,10))
> (c,(1,5))
2.4 jion 把键值对相同键的值整合起来
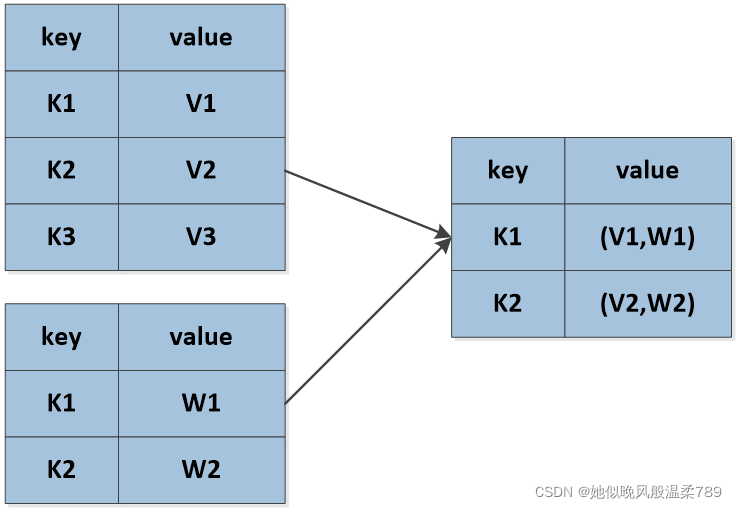
val sc = new SparkContext(new SparkConf().setMaster("local").setAppName("joinTest"))
val value1 = sc.parallelize(List(("k1", "v1"), ("k2", "v2"), ("k3", "V3")))
val value2 = sc.parallelize(List(("k1", "w1"), ("k2", "w2")))
value2.join(value1).foreach(println(_))
> (k2,(w2,v2))
> (k1,(w1,v1))
2.5 zip 将两个相同长度且 partition 数量相同的 RDD 组成 (key, value) 的形式
val sc = new SparkContext(new SparkConf().setAppName("zipTest").setMaster("local"))
val name = sc.parallelize(List("张三", "李四", "王五"),2)
val age = sc.parallelize(List(18, 20, 10),2)
name.zip(age).foreach(println(_))
> (张三,18)
> (李四,20)
> (王五,10)
2.6 combineByKey 聚合相同 key 的 value 值并可以重新指定 value 值的类型
val sc = new SparkContext(new SparkConf().setMaster("local").setAppName("Combine"))
val value = sc.parallelize(Array((1, "dog"), (1, "eat"), (1, "rice"), (2, "bord"), (2, "can"), (2, "fill"), (3, "no say word")))
value.combineByKey(List(_),(x: List[String], y: String) => y :: x,(x: List[String], y: List[String]) => x ::: y)
.foreach(println(_))
> (1,List(rice, eat, dog))
> (3,List(no say word))
> (2,List(fill, can, bord))
2.7 lookup 查找指定 key 的所有 value 值
val sc = new SparkContext(new SparkConf().setMaster("local").setAppName("lookupTest"))
val value1 = sc.parallelize(List("张三", "李四","王麻子"))
val value2 = sc.parallelize(List((10, 55), 99,888))
println("张三的 value" + value1.zip(value2).lookup("张三"))
println("李四的 value" + value1.zip(value2).lookup("李四"))
> 张三的 valueWrappedArray((10,55))
> 李四的 valueWrappedArray(99)
2.8 saveAsTextFile 将 RDD 保存至 HDFS 中
val sc = new SparkContext(new SparkConf().setMaster("local").setAppName("groupByTest"))
val data = sc.parallelize(List("张三", "李四", "王五"))
// .repartition(1)
data.saveAsTextFile("E:/bigdata/data")
2.9 take(num) 返回 RDD 前 num 条数据
val sc = new SparkContext(new SparkConf().setAppName("zipTest").setMaster("local"))
val ints = sc.parallelize(1 to 10 by 2).take(3)
for (a <- ints)println(a)
> 1
> 3
> 5
2.a count() 计算 RDD 中所有元素的个数
val sc = new SparkContext(new SparkConf().setAppName("zipTest").setMaster("local"))
val data = sc.parallelize(1 to 10 by 2)
println(data.count())
> 5