分类模型的评估指标
【传送门】
本文地址:一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC
本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
对于分类模型的评估指标,网上有太多的详细讲解,这里我们主要想如何去记忆!
首先要明白一点,任何评估指标都有好有坏啊!
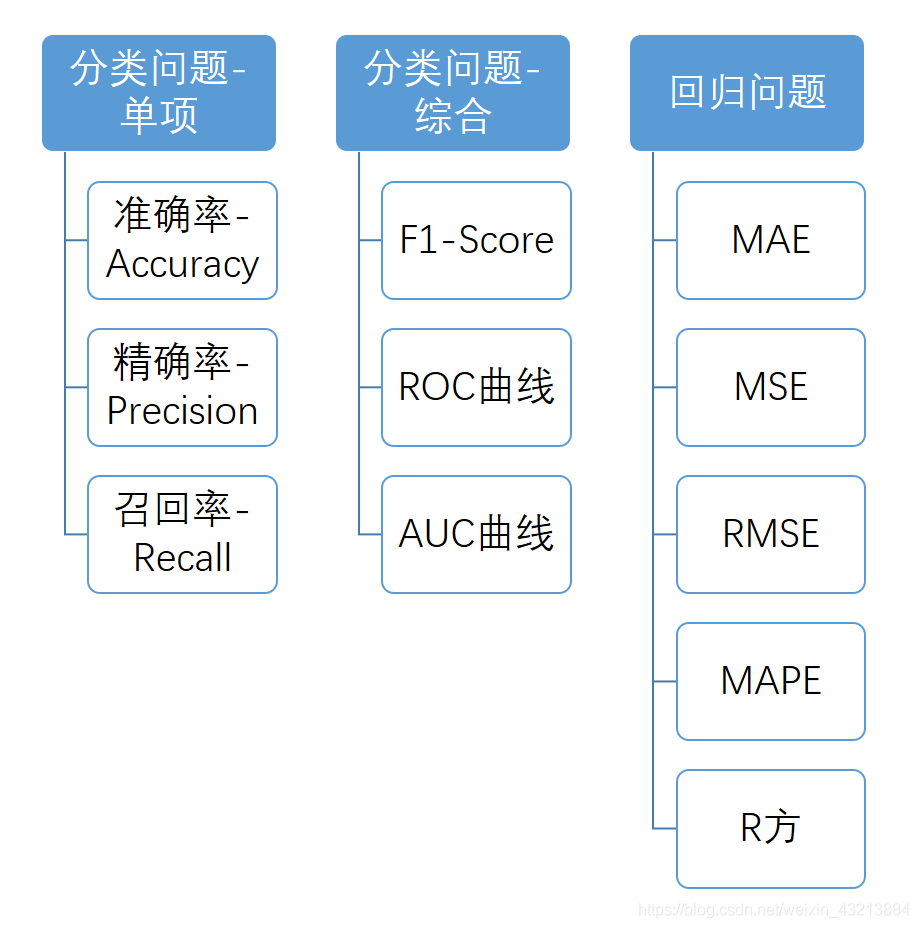
评估指标总览
混淆矩阵
最烦的TP、FN、FP、TN构成的混淆矩阵!!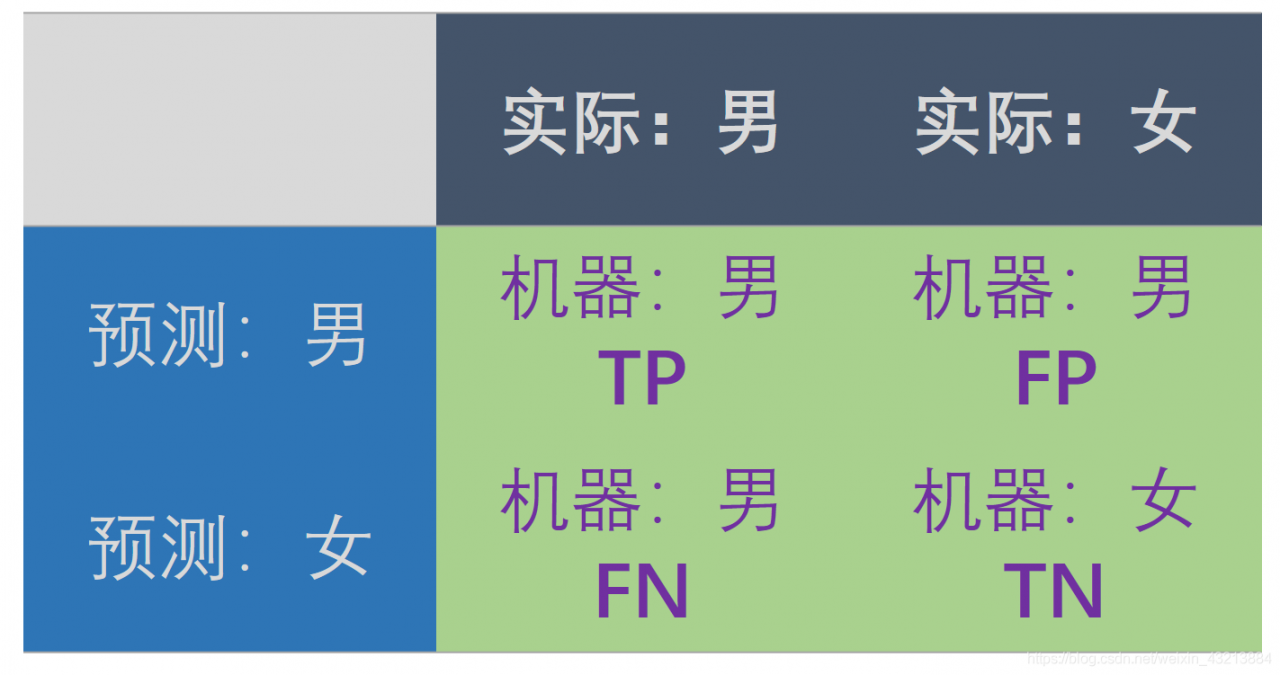
TP – True Positive:实际为男性,且判断为男性(正确)
FN – False Negative:实际为男性,但判断为女性(错误)
TN – True Negative:实际为女性,且判断为女性(正确)
FP – False Positive:实际为女性,但判断为男性(错误)
这里去理解要好一点,如果按照阴性or阳性整得人完全不好了!
准确率-Accuracy
预测正确的结果占总体样本百分比
【 ∗ ∗ 主 对 角 线 相 加 ∗ ∗ 】 / 总 样 本 量 【**主对角线相加**】/ 总样本量【∗∗主对角线相加∗∗】/总样本量
有局限
假设有:样本【0 0 0 0 0 0 0 0 0 1】
烂模型:预测【0 0 0 0 0 0 0 0 0 0】
就算模型什么也不做,也可以达到90%的ACC
get?
精确率-Precision
所有被预测为正的样本中实际为正的样本
P r e = T P / ( T P + F P ) Pre = TP/(TP+FP)Pre=TP/(TP+FP)
第一个元素/第一行和
精确率是代表正样本对结果的预测准确程度
召回率-Recall
实际为正的样本中被预测为正样本的概率
召回率=TP/(TP+FN)
F1-score
通常会画一条 P-R曲线,自古忠孝难两全,这里也是,我们只有找一个平衡点,通过下列同时,计算出F1-score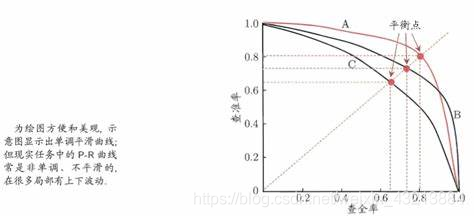
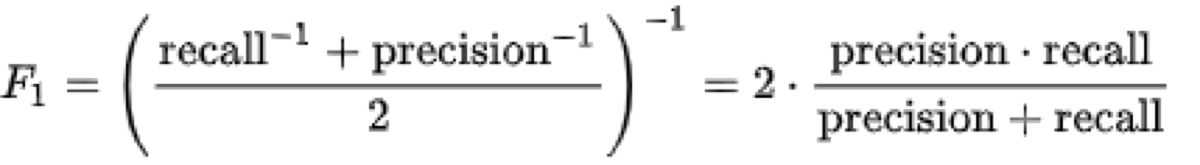
这是F1-score得分的变形,通过调节beta的大小实现不同的侧重
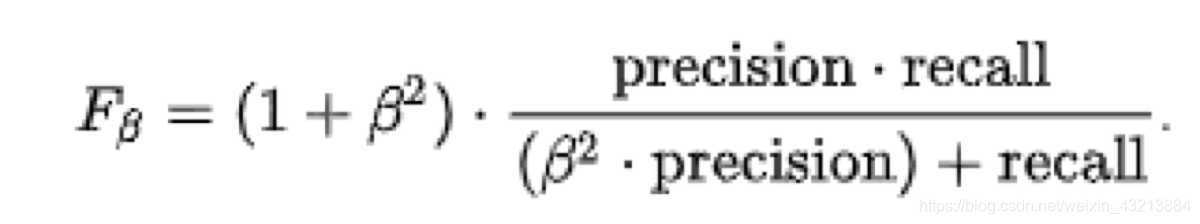
ROC曲线
receiver operating characteristic curve
拓展一下
- 真 正 率 ( T P R ) = 灵 敏 度 = 召 回 率 = T P / ( T P + F N ) 真正率(TPR)=灵敏度=召回率=TP/(TP+FN)真正率(TPR)=灵敏度=召回率=TP/(TP+FN)
- 特 异 度 = T N / ( F P + T N ) 特异度=TN/(FP+TN)特异度=TN/(FP+TN)
- 假 正 率 ( F R P ) = 1 − 特 异 度 = F P / ( F P + T N ) 假正率(FRP)=1-特异度=FP/(FP + TN)假正率(FRP)=1−特异度=FP/(FP+TN)

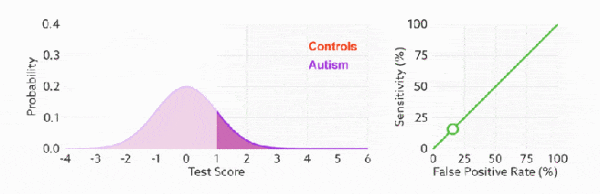
比较有意思的是,如果我们连接对角线,它的面积正好是 0.5。对角线的实际含义是:随机判断响应与不响应,正负样本覆盖率应该都是 50%,表示随机效果。 ROC 曲线越陡越好,所以理想值就是 1,一个正方形,而最差的随机判断都有 0.5,所以一般 AUC 的值是介于 0.5 到 1 之间的。
总结:
1.ROC曲线越陡越好
2.ROC曲线无视样本不平衡
AUC曲线
Area Under Curve
AUC 的一般判断标准
0.5 – 0.7: 效果较低,但用于预测股票已经很不错了
0.7 – 0.85: 效果一般
0.85 – 0.95: 效果很好
0.95 – 1: 效果非常好,但一般不太可能