
关注【搜狐技术产品】,第一时间获取技术干货
作者丨大个女
摘要:如果你是第一次开始要使用redis,那么请阅读该篇文章。该篇文章系统性的介绍redis的特点及常见使用场景,通过实际操作着重介绍了String、Set、Hash、SortedSet、List常见数据结构命令的使用,以及在实际开发中如何更好更高效的使用redis。
概述
Redis是一个开源的、基于内存的结构化存储媒介,可用作数据库、缓存、消息中间件。
它支持strings、hash、set、list、sorted set、bitmaps、hyperloglogs、geo数据结构。
另外,Redis还提供了如下的功能:
- 支持键过期,可以用来实现缓存系统
- 提供发布订阅功能,用来实现消息系统
- 提供简单的事务功能,在一定程度上保证事务特性
- 提供pipeline,支持一次将多个命令请求发送到服务端,相比较一个命令一个命令执行,减少了网络开销的时间
- 支持内存数据持久化至硬盘(RDB或者AOF)
- 1主N(N>=1)从模式下的高可用解决方案Sentinel
- 3.0+ 以上版本提供的分布式redis cluster
Redis使用场景
- 缓存
几乎所有的大型系统都会用到缓存,合理地使用缓存不仅可以加速数据的访问速度,同时也可以降低后端数据源的压力。
- 计数器应用
比如说某些网站需要对一篇文章的阅读量需要进行计数,参照数据结构:incr/incrby(原子性).
- 获取最新N条数据
比如获取某用户最新发布的N条文章,这个时候就可以考虑使用redis,参照数据结构:List(lpush+ltrim).
- 排行榜
基于不同维度的数据的排序,参照数据结构sortedset和list .
- 队列系统
Redis高性能揭秘
- 单线程结构,避免了多线程环境下的线程间切换(当然单线程也有弊端,自己思考下)
- 基于epoll的IO多路复用模型,将网路上的可读、可写等事件转化成了内部的FileEvent事件
- 纯内存访问
数据结构及常用命令
首先,Redis 针对 strings、list、set、zset、hash 这5种数据结构每种结构底层都对应有至少2种以上的内部编码实现,这样做一来是为了方便内部编码重构时不会影响外部数据结构的操作,另一方面是在键对应的数据量较小时节省内存。
redis 有0~15 个数据库,默认为db.
以下操作在redis-server:V3.2.8 ,客户端:redis-cli上执行.
基础命令
- 查看当前db的所有键
keys *

时间复杂度O(n),该命令不建议在生产环境使用,当key较多的时候会阻塞redis,建议使用替代命令scan、hscan、sscan、zscan。
2.查看当前db键总数
Dbsize

3、检查键是否存在,存在返回1、不存在返回0
exists $key
存在则返回1、不存在返回0

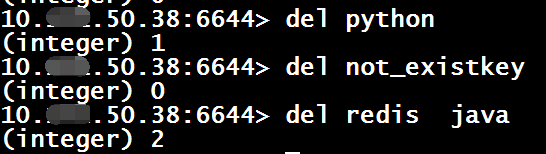
4、删除键
del $key
通用命令返回结果为删除成功的键个数,删除不存在的key返回0,支持一次删除多个键
5、键过期
Expire $key $seconds
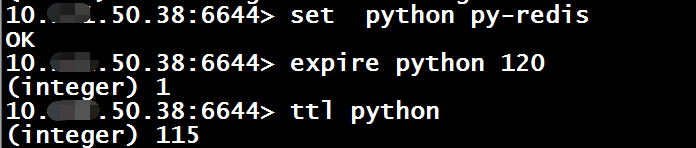
当为key设置了过期时间,超过过期时间后,键会被删除;另可使用ttl命令查看对应的剩余过期时间,返回值有以下3种:
- -2 键不存在
- -1 键未设置过期时间
- 自然数,键的剩余过期时间
类似的为key设置过期时间的命令还有pexpire、expireat、pexpireat.
6、键的类型
Type $key

当键不存在时,返回none.
7、查看键对应的内部编码
object encoding $key

字符串
Redis里键都是字符串类型,官方给出的值最大不超过512MB,但是实际使用中建议字符串长度最好不超过1K。
这里,重点介绍下常用的几个命令.
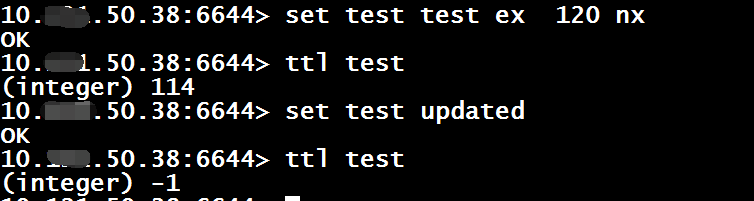
1、设置一个字符串
Set $key $value [expiration EX seconds |PX milliseconds] [NX|XX]
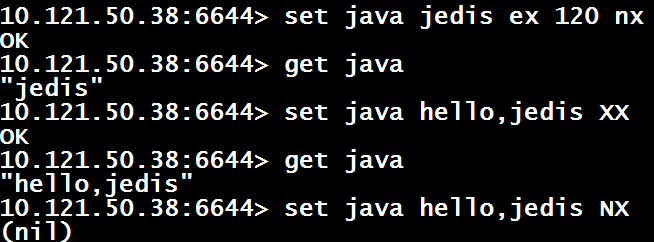
NX表示键不存在时,写入该key,XX表示键存在时写入(实际就是更新操作).
这里要注意下,如果第一次set了一个key并设置了过期时间,那么再次针对该key执行set操作的话,该key之前的过期时间会被清空.
2、获取键的值
Get $key
返回对应键的值,返回nil如果键不存在

3、批量SET
Mset $key $val [$key $val …]
该操作是原子性的.
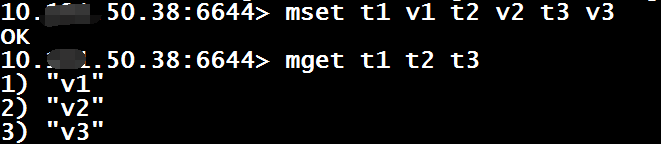
这里同样要注意,如果mset中的某个键存在于当前DB中的话,会用新的值替换掉旧的值,过期时间也会被清除(如果存在的话);如果想要在键不存在的情况下,批量写入,请使用msetnx 命令.
4、批量get
Mget $key [$key …]
当给定的键不存在或者键类型不是字符串的话,对应键返回特殊值nil.

使用批量操作,可以提高开发效率,节省来回的网络时间,但是要注意,批量操作的命令数不宜过多,过多会阻塞redis.
5、计数
Incr/incrby/incrbyfloat、decr/decrby
当键对应的val为整数时,执行成功.
哈希
- 写入值
Hset $key $field $val
当新增一个field时,返回结果为1,当更新了一个已经存在的field时,返回0.

2、获取field值
hget $key $field
field存在,返回对应的值,反之返回nil.

3、批量设置或者获取field
hmset $key $field $val [$field $val …]
hmget $key $field [$field …]

4、删除field
hdel $key $field

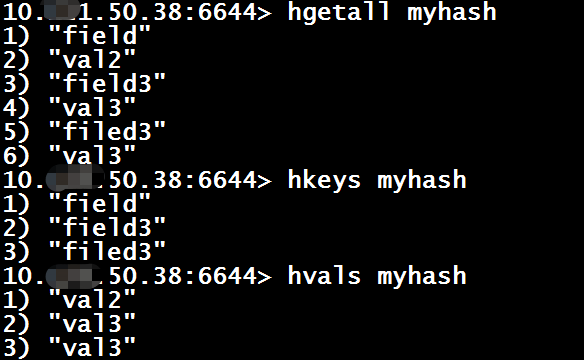
5、获取键的所有键值对/键/值
hgetall $key
hkeys $key
hvals $key
6、field是否存在
hexists $key $field
键不存在或者field不存在时,返回0.

列表
redis的列表是双端链表,可以再两端进行push、pop操作,一个列表最多可以存2^32-1 个元素。
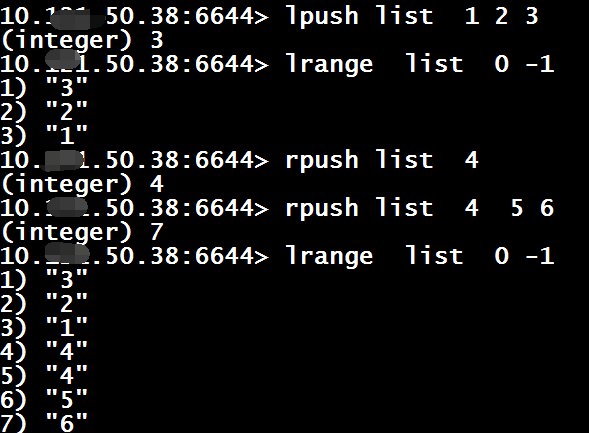
- 插入元素
lpush $key val [val …] 向列表左侧(头部)插入元素
rpush $key val [val …] 向列表右侧(尾部)插入元素
2、删除元素
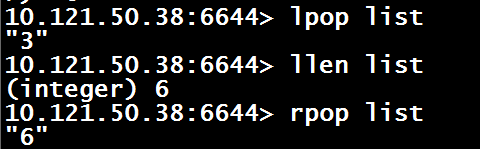
lpop $key 从列表头部删除一个元素
rpop $key 从列表尾部删除一个元素
3、获取列表元素个数
llen $key
4、获取指定范围内的元素
lrange $key $start $end
$start、$end额外说明:0表示列表的第一个元素、1表示第2个元素,-1表示列表的最后一个元素,-2表示倒数第二个元素等等。
5、清空列表
ltrim $key $start $end
严格满足 $start、$end >0 && $start >$end.
6、阻塞式的删除列表元素
blpop $key [$key …] $timeout
brpop $key [ $key …] $timeout
如果超时,则返回nil.
7、列表间的移除增加操作
rpoplpush $source $destination
将$source列表的最后一个元素从source移除后添加到destination的头部,若$source为空,则不进行任何操作.
该命令也有阻塞式的操作brpoplpush,详情参见https://redis.io/commands/brpoplpush.
基于列表以上操作,我们可以通过列表的命令组合来实现一些常用数据结构,例如:lpush+lpop 实现栈,lpush+rpop实现队列等.
集合
- 添加元素
sadd $key $member [ $member …]
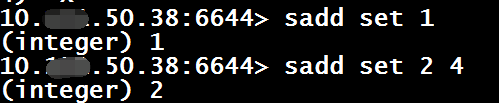
2、获取集合中元素个数
scard $key

3、获取集合中的所有元素
smembers $key

4、判断一个元素是否在集合内
sismember $key $member

5、删除集合中的元素
spop $key [$count]
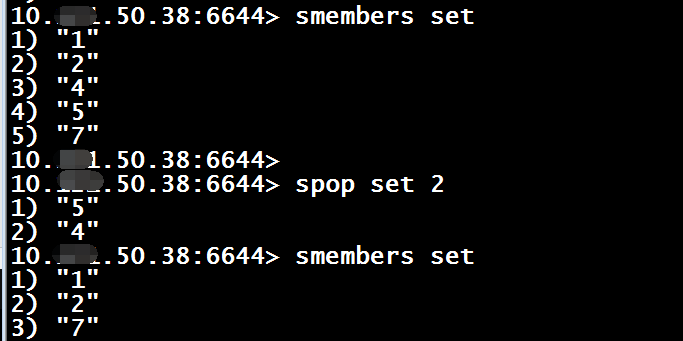
6、集合间求交集、并集等
sinter $key [$key …]
sinterstore $destination $key [$key …]
sunion $key [$key …]
sunionstore $destination $key [$key …]
sdiff $key [$key …]
sdiffstore $destination $key [$key …]
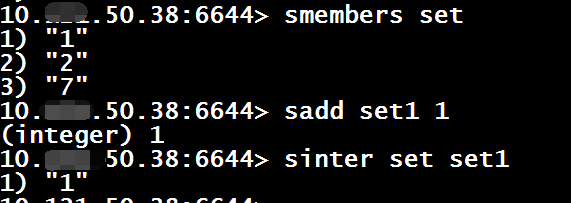
有序集合
有序集合中的每一个元素有一个score作为排序依据,切记有序集合中的元素不能重复,但是score可以重复。
- 添加元素
zadd $key [nx|xx] [ch] [incr] $score $member [$score $member …]

2、返回有序集合内元素个数
zcard $key

3、计算某个成员的分数
zscore $key $member

4、计算某个成员的排名
zrank $key $member 分数从低到高排名
zrevrank $key $member 分数从高到低排名

5、指定排名范围内的成员
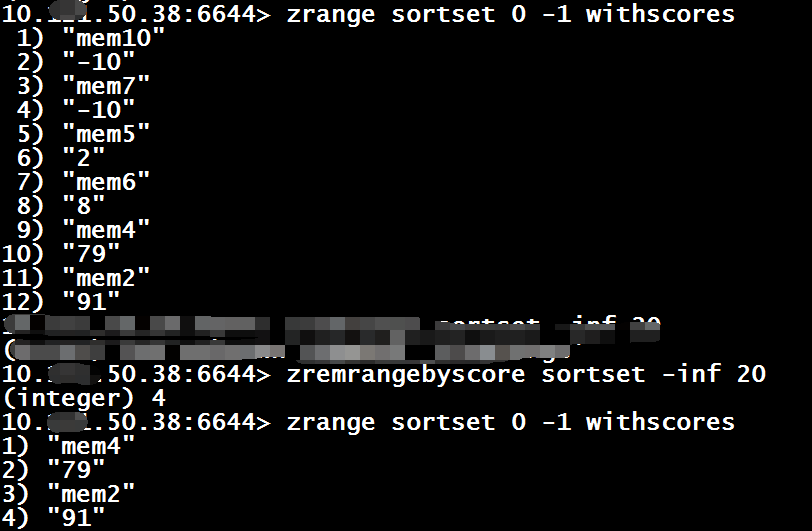
zrange $key $start $end [withscores]
zrevrange $key $start $end [withscores]
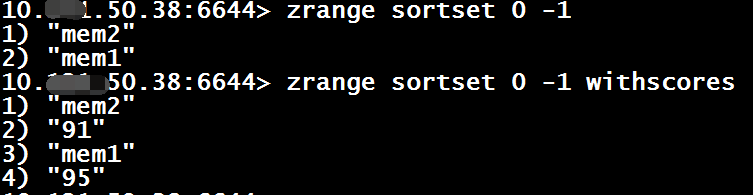
6、有序集合内的元素删除
zrem $key $member [$member …]

7、删除指定分数范围内的元素
zremrangebyscore $key $min $max
常用配置项(config)
- 慢查询相关
slowlog-log-slower-than 定义当命令处理时间超过多少,该命令会被记录在慢查询列表中
slowlog-max-len 定义慢查询列表的大小

2、连接空闲多久会被server关闭回收掉
timeout 定义当前连接空闲多久会被server主动关闭掉。

3、输出缓冲区配置
client-output-buffer-limit:该配置项定义了针对不同类型的客户端的输出缓冲区的大小(hard limit 和 soft limit 两部分),例如:normal 0 0 0 slave 268435456 67108864 60 pubsub 33554432 8388608 60 :对于normal节点来说,输出缓冲区没有限制;对slave节点来说,当输出缓冲区大于256MB或在60s内持续大于64MB,该连接会被server端主动关闭掉,这个在线上使用的时候一定要注意根据业务量进行修改。这里额外说下,这里的输出缓冲区指的是输出缓冲区的变长缓冲区即动态链表部分。

4、最大连接数
maxclients:定义redis server 允许的最大客户端连接数,当连接数超过该值时,会报类似 ‘-ERR max number of clients reached’ 错误.

性能测试
Redis-server所在服务器参数:Rhel 6.5 ,内存 256G,CPU: Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz
此处只是为了测试Redis的处理性能,所以redis-benchmark与redis server 运行在同一台服务器上,测试结果如下:
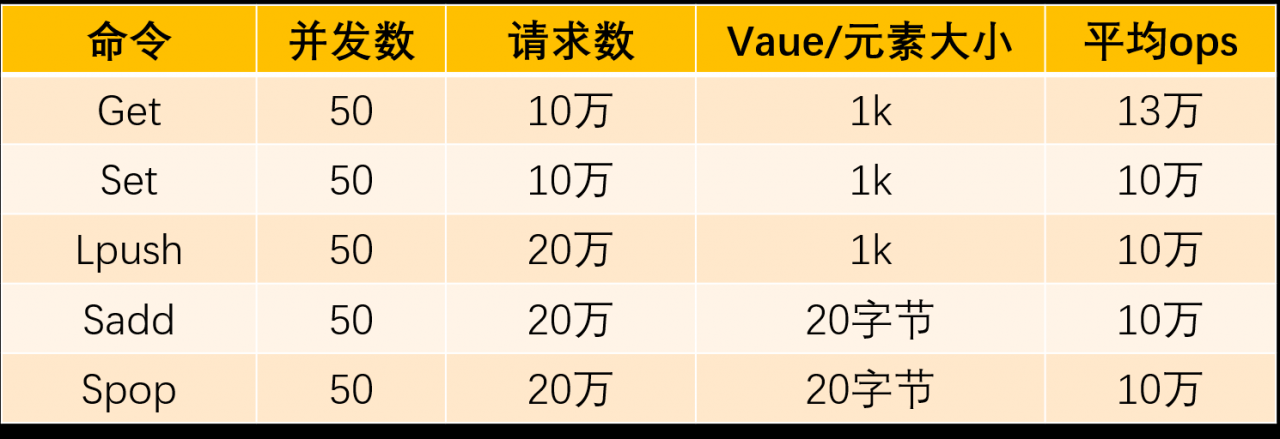

set操作压测

get操作压测
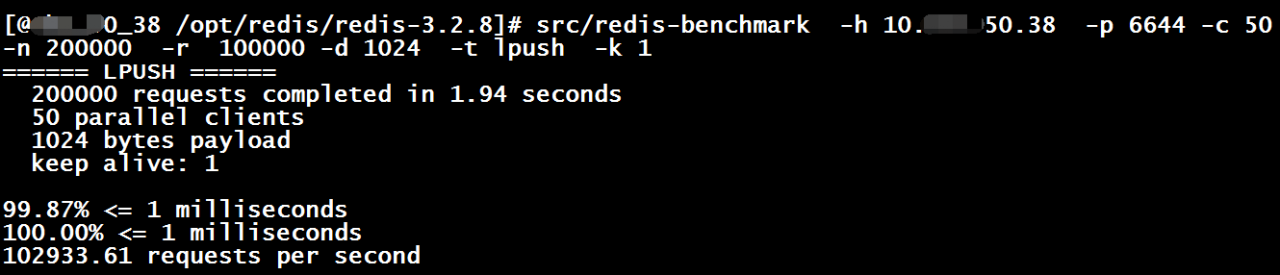
lpush操作压测

sadd操作压测
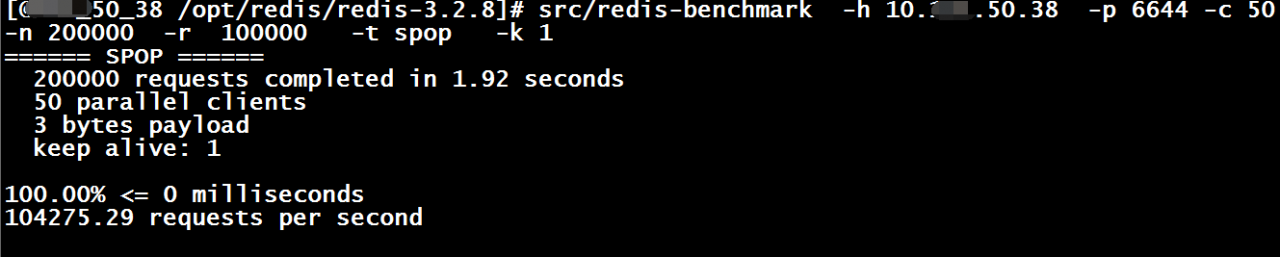
spop操作压测
实际环境中,ops不会高于上述测试结果,除了server端的命令处理时间外,还有网络时间和请求排队时间(一次请求的耗时=网络时间+请求排队时间+服务端的命令处理时间)
使用建议
键命名规范化
关于键命名的定义,大众推荐使用“[业务名]:对象名:id:[属性]’’,切勿盲目遵守该约定导致键名太长,在该约定基础上,保证键名含义清晰的情况下尽可能的短。
冷热数据分离
建议将高频热数据存储在Redis中,对于一些不太经常访问的数据可以存储在mysql等使用硬盘的存储媒介中。
不同业务的数据分开存储
redis默认有16个db,可以将不同业务的数据存储在不同的db中,或者部署多组不同的redis来提供给不同业务使用。
当缓存用时设置过期时间
redis做缓存用时,给key设置过期时间,过期时间根据实际业务进行评估,切勿随意给一个很长的时间。
大value建议压缩后存储
实际使用中,如果碰到一些无法进行数据结构拆分的大key不得不存储在redis中时,建议对这类value进行压缩后存储。
避免生产环境使使用keys等耗时命令
在数据量keys比较多的情况下,执行keys命令会在一段时间内阻塞redis,这样导致其他命令的请求处理超时,尤其是在高OPS的情况下更要避免使用该类操作。
谨慎使用Hash、Set、SortedSet数据结构的全量操作
例如,对于hgetall操作,当hash中只有几十个或者几百个field的时候,hgetall的响应时间很快,完全可以满足业务低延迟的需求,但是当field数增长到到几万个或者几十万个的时候,这个时候再去执行hgetall响应时间势必会增加。
合理使用pipeline
一次set操作的响应时间=请求网络传输时间+请求排队时间+server处理时间+响应网络传输时间,那么10次set的响应时间则为10次请求网络传输时间+请求排队时间+server端命令处理时间+10次响应网络传输时间,但是当使用pipeline时,10次set请求封装成一次网络请求到server端,同理响应也是一次网络传输,节省了大量的RTT(这里只是举例,多个值的set 操作redis默认有支持,可自己查看官方文档)。
关注【搜狐技术产品】公众号,第一时间获取技术干货!