一、语言入门基础
1.输出函数说明
printf函数
头文件:stdio.h
原型:int printf(const char *format, …);
format:格式控制字符串
…:可变参数列表
返回值:成功输出字符的数量
2.输入函数说明
scanf函数
头文件:stdio.h
原型:int scanf(const char *format, …);
format:格式控制字符串
…:可变参数列表
返回值:成功读入的参数个数
int a = scanf("hello"); //a = 0
循环读入:【EOF==-1】
while(scanf(...) != EOF){} //CTRL+C:强制结束一个进程;CTRL+Z:-1/EOF
使用printf函数,循环读入数字,求解一个数字n的十进制表示的数字位数
#include<stdio.h>
int main(){
int n;
while(scanf("%d", &n) != EOF){
printf(" has %d digits!\n", printf("%d", n));
}
return 0;
}
读入一行字符串,可能包含空格,输出这个字符串中字符的数量
#include<stdio.h>
int main(){
char str[1000] = {0};
//正则表达式:^\n:除了换行符以外的字符
while(scanf("%[^\n]s", str) != -1){//str:字符数组首地址
getchar();//强制吞掉输入流中的一个字符
printf(" has %d chars!\n", printf("%s", str));
}
return 0;
}
输入输出家族的常用操作
#include<stdio.h>
int main(){
//stdin ==> 0
//stdout ==> 1
//stderr ==> 2
int a, b, c, d;
char str[1000] = {0};
int ans[4] = {0};
scanf("%d%d%d%d", &a, &b, &c, &d);
sprintf(str, "%d.%d.%d.%d", a, b, c, d);//字符串拼接
printf("str = %s\n", str);
sscanf(str, "%d.%d.%d.%d", &ans[0], &ans[1], &ans[2], &ans[3]);
for(int i = 0; i < 4; i++){
printf("%d ", ans[i]);
}
printf("\n");
FILE *fin = fopen("./output", "w");
fprintf(fin, "str = %s\n", str);
fclose(fin);
char str_out[1000] = {0};
FILE *fout = fopen("./output", "r");
fscanf(fout, "%[^\n]s", str_out);
printf("%s\n", str_out);
fclose(fout);
return 0;
}
w+知识点补充:
#include<stdio.h>
int main(){
char str[100] = "hello kaikeba 123@qq.com";
char temp[100] = {0};
FILE *fp = fopen("./output", "w+");//w+:先清空内容,如有写入操作再写入,后读取
fprintf(fp, "%s", str);
fseek(fp, 0, SEEK_SET);//调整指针光标到首位,因为写入的时候光标已经到最后面了
fscanf(fp, "%[^\n]s", str);
fclose(fp);
printf("%s\n", str);
return 0;
}
二、数学运算
1.C语言基本运算符
类型转换:
显式类型转换——强制转换
隐式类型转换——自动类型转换
2.位运算:效率最高【&、|、^、~ 优先级同级】
①二进制下进行的计算
&:
①单目运算符:取地址;
②双目运算符:按位与
%2 == &1
%4 == &3
%6 =X= 不等于任何值
%8 == &7
%16 == &15
|:按位或(有1则为1,全0才为0)
^:异或(相同为0,不同为1)
逆运算:满足交换律(a+b <==> b+a)
a + b = c ==> c - b = a | c - a = b ==> -是+的逆运算
a - b = c ==> c + b = a | c + a != b ==> +不是-的逆运算
也是一类逆运算,运算符是^运算符的逆运算
a ^ b = c ==> c ^ b = a | c ^ a = b
a ^ a = 0 //相同为0
n ^ 0 = n //不同为1
面试题:有一串数字,每个数字都出现了两次,其中只有一个值x只出现了一次,请快速查找处这个值
将每个值之间做异或,最后的答案就是这个值
12323
1 ^ 2 ^ 3 ^ 2 ^ 3 = 1
进阶:有一串数字,每个数字都出现了两次,其中有n个值x只出现了一次,请快速查找处这个值
先排序后异或即可
~:按位取反(二进制每一位取反,符号位为1是负数)
原码:
正数是其二进制本身;
负数是符号位为1,数值部分取X绝对值的二进制。
反码:
正数的反码和原码相同;
负数是符号位为1,其它位是原码取反。
补码:
正数的补码和原码,反码相同;
负数是符号位为1,其它位是原码取反,未位加1。(反码末尾减1)(或者说负数的补码是其绝对值反码未位加1)
取反就是简单的 0变1,1变0 ;
而按位取反需要涉及以上概念。要弄懂这个运算符的计算方法,首先必须明白二进制数在内存中的存放形式,二进制数在内存中是以补码的形式存放的。
下面以计算正数 9 的按位取反为例,计算步骤如下(注:前四位为符号位):
- 原码 : 0000 1001
- 算反码 : 0000 1001 (正数反码同原码)
- 算补码 : 0000 1001 (正数补码同反码)
- 补取反 : 1111 0110 (全位0变1,1变0)
- 算反码 : 1111 0101 (末位减1)
- 算原码 : 1111 1010 (其他位取反)
总结规律: ~x = -(x+1)
补码=~原码+1
-1:
原码: 1000 0000 .... 0001
~原码:1111 1111 .... 1110 (除了符号位按位取反)
+1
补码: 1111 1111 .... 1111
3.左移和右移
左移:低位补0【相当于乘2】
右移:高位补符号位【相当于除2】
总结:
1.%是速度最慢的 %2 == &1
2.整型值、字符类型才能进行位运算
4.C语言中的数学函数库
头文件:math.h
常用函数:
pow(a, n) fabs(n) sqrt(n) log(n) ceil(n) log10(n) floor(n) acos(n) abs(n)(stdlib.h)
pow函数:指数函数
头文件:math.h
原型:double pow(double a, double b);
a:底数
b:指数
返回值:返回a的b次方的结果
例子:pow(2, 3) = 8 [这里的8是一个double类型值]
sqrt函数:开平方函数
头文件:math.h
原型:double sqrt(double x);
x:被开方数
返回值:返回根号x的结果
例子:sqrt(16) = 4 [这里的4是一个double类型值]
ceil函数:上取整函数(天花板函数)
头文件:math.h
原型:double ceil(double x);
x:某个实数
返回值:返回x向上取整的结果
例子:ceil(4.1) = 5 [这里的5是一个double类型值]
floor函数:下取整函数(地板函数)
头文件:math.h
原型:double floor(double x);
x:某个实数
返回值:返回x向下取整的结果
例子:floor(4.9) = 4
abs函数:整数绝对值函数
头文件:stdlib.h
原型:int abs(int x);
x:某个整数
返回值:返回x的绝对值的结果
例子:abs(-4) = 4
fabs函数:实数绝对值函数
头文件:math.h
原型:double fabs(double x);
x:某个实数
返回值:返回x的绝对值的结果
例子:fabs(-4.5) = 4.5
log函数:以e为底对数函数
头文件:math.h
原型:double log(double x);
x:某个实数
返回值:返回log以e为底的x的结果
例子:log(9) = 2.197225…
log10函数:以10为底的对数函数
头文件:math.h
原型:double log10(double x);
x:某个实数
返回值:返回log以10为底的x的结果
例子:log10(1000) = 3
acos函数:反三角函数(反余弦)
头文件:math.h
原型:double acos(double x);
x:角度的弧度值
返回值:返回arccos(x)的结果
例子:acos(-1) = 3.1415926… [sin(90°)要写sin(Π/2)]
int类型使用32个bite去存储,其中最左边的为从右往左数的第32位,是符号位,用于存储符号
有符号位:int:[-2^31, 2^31 - 1]
无符号为:int:[0, 2^32 - 1]
#include<stdio.h>
int main(){
int a, b;
/*scanf返回值为-1时,二进制的-1为32个1,按位取反得到32个0,结果为0*/
while(~scanf("%d%d", &a, &b)){
printf("a = %d, b = %d\n", a, b);
//一般使用异或运算时要先判断a与b是否相等,否则容易出现交换错误
a ^= b;
b ^= a;
a ^= b;
printf("a = %d, b = %d\n", a, b);
}
return 0;
}
三、流程顺序控制方法
a = 3, b = -3, c = 0; ==> 逻辑表达式返回的是最后一个逗号表达式的值,0
!!(x) ==> 逻辑归一化 (真值有很多:1 2 3 4... 假值也有:0 null 空地址 '\0')将真假归一为0和1
1.分支结构
1.If语句
if(表达式){ //判断表达式的逻辑返回值是否为真
代码段;
}
if(表达式){
代码段1;
} else {
代码段2;
}
if(表达式1){
代码段1;
} else if(表达式2){
代码段2;
} else {
代码段3;
}
if(表达式) + 一条语句:
①空语句
②单语句 (以分号表示结尾)
③复合语句(以{}表示)
2.switch语句
swithc(a){ //a只能是整数值。(字符型==>ASCII码)
//case条件入口,程序进入case所对应的代码段
//依次执行后续代码知道遇到break或者switch结构结尾
case 1:代码块1;
case 2:代码块2;
......
default: 代码块n; //相当于else语句,如果以上情况都没有就执行这里
}
3.三目运算符
#include<stdio.h>
int main(){
int n;
scanf("%d", &n);
if(n >= 0) printf("非负数");
else printf("负数");
printf("%s\n", n >= 0 ? "非负数" : "负数");
return 0;
}
四、循环结构
1.while语句
while(表达式){ //每当表达式为真,代码块就会被执行一次
代码块;//最少执行0次
}
do{
代码块; //最少执行1次
} while(表达式); //每当代码块执行一次,就会判断一次表达式是否为真
在进行浮点数的判断时,不建议直接使用==。浮点数之间其实是没有绝对的相等的。解决浮点数判等问题——设置精度(epl),当|a - b| < epl的时候,可以理解为是相等的
2.for语句
//①初始化,只在第一次被执行
//②循环条件判断,为真才循环
//③执行代码块
//④执行后操作
//跳转到②
for(初始化;循环条件;执行后操作){
代码块;
}
3.练习题
(1)回文整数
bool isPalindrome(int x){
//使用__builtin_expect()有可能加速
if(__builtin_expect(!!(x < 0), 0)) return false; //判断x是否小于0
int y = 0, z = x;
while(x){
y = y * 10 + x % 10;
x /= 10;
}
return z == y;
}
CPU的分支预测
早期:串行执行指令(①外存 ②内存) 问题:CPU要等待执行
1条指令需要5个时钟周期,五条指令需要5 * 5 = 25个时钟周期
现在:并行执行指令 车间流水线
并行:五条指令需要5 + 4 = 9个时钟周期
CPU的分支预测会根据以往执行的经验去进行预测该加载哪一项,如果发现不对,CPU有的容错机制会将预测的情况全部推翻,重新加载,重新计算,这个操作相当于CPU执行了一次串行执行。
if(yes) seg1 //如果以前走的大多数情况是这条路,预测也会走这条路
else seg2
在不影响代码可读性的情况下尽可能的减少分支结构
以下代码为帮助CPU进行分支预测:
#define likely(x) __builtin_expect(!!(x), 1) //likely代表x经常成立
#define unlikely(x) __builtin_expect(!!(x), 0) //unlikely代表x不经常成立
拓展:
__builtin_ffs(x): 返回x中最后一个为1的位是从后向前的第几位
__builtin_popcount(x): x中1的个数
__builtin_ctz(x): x末尾0的个数。x = 0时结果未定义
__builtin_clz(x): x前导0的个数。x = 0时结果未定义
__builtin_prefetch(const void *addr, ...): 怼数据手工预取的方法
__builtin_types_compatible_p(type1, type2): 判断type1和type2是否是相同的数据类型
__builtin_expect(long exp, long c): 用来引导gcc进行条件分支预测
__builtin_constant_p(exp): 判断exp是否在编译时就可以确定其为常量
__builtin_parity(x): x中1的奇偶性
__builtin_return_address(n): 当前函数的第n级调用者的地址
(2)分支结构代码演示
#include<stdio.h>
#include <time.h>
#include <stdlib.h>
int main(){
int a = 0, b = 0;
if((a++) && (b++)){ //&&的短路运算规则:第一个逻辑表达式返回值如果为假不再执行后面的表达式
printf("true\n");
} else {
printf("false\n");
}
printf("a = %d, b = %d\n", a, b);
//随机生成n个整型值,打印n个值
//控制输出格式:判断第一个值
//统计其中有多少个奇数值
srand(time(0)); //初始化一个随机种子,一直变化的值,不断累加
printf("%ld\n", time(0));//当前Linux系统的时间戳,从1970年1月1日开始至今
int n, cnt = 0;
scanf("%d", &n);
for(int i = 0; i < n; i++){
int val = rand() % 100; //在计算机中目前无法真正生成随机数字。(伪随机)
//if(i) printf(" ");
i && printf(" ");
printf("%d", val);
//if(val & 1) ++cnt;
cnt += (val & 1);
}
printf("\ncnt: %d\n", cnt);
return 0;
}
(3)循环结构代码演示
#include<stdio.h>
int reverse_num(int n){
int x = n, temp = 0;
while(x){
temp = temp * 10 + x % 10;
x /= 10;
}
return temp == n;
}
int main(){
int n;
scanf("%d", &n);
for(int i = 1; i <= n; i++){
if(!reverse_num(i)) continue;
printf("%d\n", i);
}
return 0;
}
五、函数
1.基本函数定义与用法
int functionName(int); //函数的声明:说明
//函数的定义:具体的实现
int functionName(int x){ //int:返回值 functionName:函数名 int x:参数声明列表
//实现代码
return (int)x; //返回函数调用
}
#include<stdio.h>
void func();//函数声明
int main(){ //主函数:默认情况下的程序入口
//func();
printf("main: test!\n");
return 0; // 对操作系统来说,0表示真值
}
__attribute__((constructor)) //预处理命令。会让此函数先于主函数执行
void func(){
int a = 2, b = 3;
printf("func: %d * %d = %d\n", a, b, 2 * 3);
return ;
}
__attribute__((constructor)) //顺序执行
void test(){
printf("hello world!\n");
}
2.K&R风格的函数定义
int is_prime(x);
int x;{
for(int i = 2; i * i <= x; i++){
if(x % i == 0) return 0;
}
return 1;
}
3.递归函数
程序调用自身的编程技巧叫做【递归】,而不是算法(递推)
递归程序的组成部分:
(1)给予合理的语义信息
(2)边界条件处理
(3)针对问题的 处理过程 和 递归过程(分治思想)
(4)结果返回 ①return ②全局变量 ③传出参数(指针)
递归需要更多的额外时间开销
系统栈:(函数内部调用的空间都占用系统栈)
Linux:8MB
Window:2-8MB
函数内部的局部变量只有在调用的时候才分配空间
4.函数指针
指针变量也是变量,用于接收地址
//前三个参数就是函数指针变量。*可以理解为指针变量的标志。int: 函数返回值,(*f1):f1为函数指针变量(int):函数的参数列表
int g(int (*f1)(int), int (*f2)(int), int (*f3)(int), int x){
if(x < 0) return f1(x);
if(x < 100) return f2(x);
return f3(x);
}
函数是压缩的数组,数组是展开的函数
#include<stdio.h>
#include <inttypes.h>
int64_t Triangle(int64_t n){//三角形
return n * (n + 1) / 2;
}
int64_t Pentagonal(int64_t n){//五边形
return n * (3 * n - 1 ) >> 1;
}
int64_t Hexagonal(int64_t n){//六边形
return n * (2 * n - 1);
}
//函数式
int64_t binary_search1(int64_t (*arr)(int64_t), int64_t n, int64_t x){
int64_t head = 1, tail = n, mid;
while(head <= tail){
mid = (head + tail) >> 1;
if(arr(mid) == x) return 1;
if(arr(mid) < x) head = mid + 1;
else tail = mid - 1;
}
return 0;
}
//数组式
int64_t binary_search(int64_t *arr, int64_t n, int64_t x){
int64_t head = 0, tail = n - 1, mid;
while(head <= tail){
mid = (head + tail + 1) >> 1;
if(arr[mid] == x) return mid;
if(arr[mid] < x) head = mid + 1;
else tail = mid - 1;
}
return -1;
}
int64_t main(){
int64_t n = 143;
while(1){
//int64_t temp = Triangle(++n);
int64_t temp = Hexagonal(++n);
if(!binary_search1(Pentagonal, temp, temp)) continue; //判断五边形
printf("%ld\n", temp);
break;
}
return 0;
}
5.欧几里得算法
辗转相除法。
用于快速计算两个数字的最大公约数
还可以用于快速求解a * x + b * y = 1的方程的一组整数解
定理:a和b两个整数的最大公约数等于b与a % b的最大公约数。
形式化表示:假设a,b != 0, 则gcd(a, b) = gcd(b, a % b)
证明1:
1.设c = gcd(a, b),则a = cx, b = cy
2.可知a % b = r = a - k * b = cx - kcy = c(x - ky)
3.可知c也是r的因数
4.其中x - ky与y互素。见证明2
所以可知:gcd(a, b) = gcd(b, r) = gcd(b, a % b)
证明2:
1.假设gcd(x = ky, y) = d
2.则y = nd, x - ky = md, 则x = knd + md = d(kn + m)
3.重新表示a, b,则有a = cd(kn + m),b = cdn
4.则可得gcd(a, b) >= cd, 又因为gcd(a, b) = c,所以d = 1
最大公约数:b == 0 ? a : gcd(b, a % b)
最小公倍数:a * b / gcd(a, b)
#include<stdio.h>
int gcd(int , int);
int lcm(int a, int b){
return a * b / gcd(a, b);
}
int gcd(int a, int b){
// if(!b) return a;
// return gcd(b, a % b);
return b == 0 ? a : gcd(b, a % b);
}
int main(){
int a, b;
while(~scanf("%d%d", &a, &b)){
printf("gcd(%d, %d) = %d\n", a, b, gcd(a, b));
printf("lcm(%d, %d) = %d\n", a, b, lcm(a, b));
}
return 0;
}
6.变参函数
实现可变参数max_int,从若干个传入的参数中返回最大值。
int max_int(int a, ...); //至少要知道一个参数的名字
如何获得a往后的参数列表?va_list类型的变量
如何定位a后面第一个参数的位置?va_start “函数” (初始化)
如何获取下一个可变参数列表中的参数?va_arg “函数” (指明了类型)
如何结束整个获取可变参数列表的动作?va_end函数 (释放)
#include<stdio.h>
#include <inttypes.h>
#include <stdarg.h>
int max_int(int n, ...){
int ans = INT32_MIN;//32位整型极小值
va_list arg;
va_start(arg, n); //n后面的值赋值给arg(不包括n,n代表一共有几个数)
while(n--){
int temp = va_arg(arg, int); //int表示下一个参数必须是整型的
if(temp > ans) ans = temp;
}
va_end(arg);
return ans;
}
int main(){
printf("%d\n", max_int(3, 2, 0, 3));
printf("%d\n", max_int(5, 20, 10, -3));//少传几个数不影响
printf("%d\n", max_int(3, 2, 0, 3, 8, 9, 10)); //多传几个数,只会取前n个
return 0;
}
六、数组与预处理命令
1.数组声明与初始化
int a[2]; //声明
//初始化
int a[2] = {1};
int a[2] = {1, 2};
数组是具有相同类型变量的集合。
数组下标从0开始。
数组的地址在内存上是连续的。
数组本身是支持随机访问的。
2.素数筛
1.标记一个范围内的数字是否是合数,没有被标记的则为素数
2.算法的空间复杂度为O(n),时间复杂度为O(n*loglogn) ~= O(n)
3.总体思想是用素数去标记掉不是素数的数字,例如知道了i是素数,那么2i、3i、4i...就都不是素数
(1)基本方法判断素数
#include<stdio.h>
#include <math.h>
int is_prime(int n){
for(int i = 2, ans = sqrt(n); i <= ans; i++){
if(n % i == 0) return 0;
}
return 1;
}
int main(){
for(int i = 2; i < 100001; i++){
if(!is_prime(i)) continue;
printf("%d\n", i);
}
return 0;
}
(2)素数筛
#include<stdio.h>
#define MAX_N 1000
int prime[MAX_N + 10] = {0, 1, 0};
void init_prime(){
for(int i = 2; i <= MAX_N; i++){
if(prime[i]) continue;
prime[++prime[0]] = i; //节约空间,存储目前已知的素数,prime[0]用于计数
for(int j = i, J = MAX_N / i; j <= J; j++){//从i开始枚举减少重复标记
prime[i * j] = 1;
}
}
return ;
}
int main(){
init_prime();
for(int i = 1; i <= prime[0]; i++){
printf("%d\n", prime[i]);
}
return 0;
}
3.折半查找(二分查找)
【要满足单调性】
#include<stdio.h>
int binary_search(int *arr, int n, int x){
int head = 0, tail = n - 1, mid = 0;
while(head <= tail){
mid = (head + tail) >> 1;
if(arr[mid] == x) return mid;
if(arr[mid] < x) head = mid + 1;
else tail = mid - 1;
}
return -1;
}
int main(){
int n, x, arr[100] = {0};
scanf("%d", &n);
for(int i = 0; i < n; i++) scanf("%d", &arr[i]);
while(~scanf("%d", &x)){
printf("%d\n", binary_search(arr, n, x));
}
return 0;
}
#include<stdio.h>
#include <math.h>
//O(logn)
double my_sqrt(double n){
//当n < 1,sqrt(n) > n,所以要加上1.0
double head = 0, tail = n + 1.0, mid = 0;
#define EPSL 1e-8 //1*10^-8 定义精度值
while(tail - head > EPSL){
mid = (head + tail) / 2.0;
if(mid * mid < n) head = mid;
else tail = mid;
}
#undef EPSL //结束宏定义
return head;
}
int main(){
double n;
while(~scanf("%lf", &n)){
printf("sqrt(%lf) = %lf\n", n, sqrt(n)); //用的牛顿迭代法,更优
printf("my_sqrt(%lf) = %lf\n", n, my_sqrt(n));
}
return 0;
}
4.数组的相关代码讲解
#include<stdio.h>
//void func(int num[]){
void func(int *num){ //num为指针变量,而不是数组
num[0] = 1234;
printf("func: num = %p\tnum+1 = %p \n"); //表现形式一致性,外部调用和内部的地址一致(表现 形式一致)
}
//void func1(int num[][20]){ //只能省略一个维度
void func1(int (*num)[20]){
num[0][0] = 1234;
printf("func: num = %p, num + 1 = %p\n", num, num + 1);
}
int main(){
int arr[100];
double num[100];
printf("%lu\n", sizeof(arr));
printf("arr = %p\tarr[0] = %p\n", arr, &arr[0]);
printf("arr + 1 = %p\n", arr + 1);
printf("num = %p\tnum[0] = %p\n", num, &num[0]);
printf("num + 1 = %p\n", num + 1);
func(arr);
printf("arr[0] = %d\n", arr[0]);
printf("==========================================================\n");
int arr1[100][20]; //100行20列
printf("arr = %p, arr + 1 = %p\n", arr, arr + 1);
int **p; //指针p指向的是另一个指针变量
printf("p = %p, p + 1 = %p\n", p, p + 1); //在64位操作系统中一个指针变量默认8字节
func1(arr1);
return 0;
}
5.字符串(字符数组)
C语言中不存在字符串这个类型变量,只有字符数组
定义字符数组:
char str[size];
初始化字符数组:
char str[] = "hello world"; //12个字节,最后结尾是:'\0'(ASCII码值是0)
char str[size] = {'h', 'e', 'l', 'l', 'o'};
#include<stdio.h>
int main(){
char str[] = "hello world"; //自动添加'\0'
char str1[] = {'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '\0'}; //不会自动添 加'\0'
printf("%s\n", str);
printf("sizeof(str) = %lu\n", sizeof(str));
printf("%s\n", str1);
printf("sizeof(str1) = %lu\n", sizeof(str1));
return 0;
}
字符串的相关操作
头文件:string.h
strlen(str); //计算字符串长度,以'\0'作为结束符
strcmp(str1, str2); //字符串比较
strcpy(dest, src); //字符串拷贝
strncmp(str1, str2, n); //安全的字符串比较
strncpy(str1, str2, n); //安全的字符串拷贝
memcpy(str1, str2, n); //内存拷贝,n的单位是字节
memcmp(str1, str2, n); //内存比较,n的单位是字节
memset(str1, c, n); //内存设置,n的单位是字节
头文件:stdio.h
sscanf(str1, format, ...); //从字符串str1读入内容
sprintf(str1, format, ...); //将内容输出到str1中
使用字符串相关操作方法,计算一个整型值16进制的表示的位数
#include<stdio.h>
#include <string.h>
int main(){
char str[11];
int n;
while(scanf("%d", &n) != EOF){
sprintf(str, "%X", n);
printf("%d(%s) has %lu digits\n", n, str, strlen(str));
}
return 0;
}
6.预处理命令——宏定义
宏定义只进行符号替换,不进行相关计算
//定义符号常量:
#define PI 3.1415926
#define MAX_N 10000
//定义傻瓜表达式
#define MAX(a, b) (a) > (b) ? (a) : (b)
#define S(a, b) a * b //S(2+3, 5+6) = 2 + 3 * 5 + 6 = 23
//定义代码段
#define P(a){\
printf("%d\n", a);\
}
7.预处理命令——预定义的宏
__DATE__ //日期:M mm dd yyyy
__TIME__ //时间:hh:mm:ss
__LINE__ //行号 (int)
__FILE__ //文件名 (xxx.c)
__func__ //函数名/非标准
__FUNC__ //函数名/非标准
__PRETTY_FUNCTION__ //更详细的函数信息/非标准
8.预处理命令——条件式编译
#ifdef_DEBUG //是否定义了DEBUG宏
#ifndef_DEBUG //是否没定义DEBUG宏
#if_MAX_N == 5 //宏MAX_N是否等于5
#elif MAX_N == 4 //否则宏MAX_N是否等于4
#else
#endif
C源码—预处理阶段(替换所有预处理命令)—>编译源码(编译期)------>对象文件(中间文件linux: xx.o | window: xx.obj)—链接中间文件—>可执行程序(linux: a.out | windows: .exe)
请实现一个没有BUG的宏(判断a的大小),需要通过如下测试:
1.MAX(2, 3)
2.5 + MAX(2, 3)
3.MAX(2, MAX(3, 4))
4.MAX(2, 3 > 4 ? 3 : 4)
5.MAX(a++, 6) a的初始值为7,函数返回值为7,a的值变为8
使用gcc xxx.c -E 能看到预编译期宏替换之后的代码
#include<stdio.h>
//typeof()替换变量,这里相当于int。__a只是一个名字,可以为其他
#define MAX(a, b) ({ \
typeof(a) __a = a; \
typeof(b) __b = b; \
__a > __b ? __a : __b; \
})
// ((a) > (b) ? (a) : (b))
//#是字符串化,将传进来的func原封不动地转化为字符串
#define P(func){ \
printf("%s = %d\n", #func, func); \
}
int main(){
int a = 7;
P(MAX(2, 3));
P(5 + MAX(2, 3));
P(MAX(2, MAX(3, 4)));
P(MAX(2, 3 > 4 ? 3 : 4));
P(MAX(a++, 6));
P(a);
// printf("MAX(2, 3) = %d\n", MAX(2, 3));
// printf("5 + MAX(2, 3) = %d\n", 5 + MAX(2, 3));
// printf("MAX(2, MAX(3, 4)) = %d\n", MAX(2, MAX(3, 4)));
// printf("MAX(2, 3 > 4 ? 3 : 4) = %d\n", MAX(2, 3 > 4 ? 3 : 4));
// printf("MAX(a++, 6) = % d\ta = %d\n", MAX(a++, 6), a);
return 0;
}
实现一个打印LOG函数,输出所在函数及行号等信息。
注:
__FILE__ //以字符串形式返回所在文件名称
__func__ //以字符串形式返回所在函数名称
__LINE__ //以整数形式返回代码行号
可以在编译时使用:gcc xxx.c -D DEBUG 加上一个宏定义
#include<stdio.h>
#define DEBUG //也可以直接定义
#ifdef DEBUG
//变参宏
//##:连接。将两个部分作为一个整体取看待,就允许args为空
#define LOG(frm, args...){ \
printf("[%s : %s : %d] ", __FILE__, __func__, __LINE__); \
printf(frm, ##args); \
printf("\n"); \
}
#else
#define LOG(frm, args...){}
#endif
int main(){
int a = 123, b = -34;
char str[100] = "Hello world!";
printf("[%s : %s : %d] a = %d, b = %d\n",__FILE__, __func__, __LINE__, a, b);
LOG("a = %d, b = %d\n", a, b);
LOG("str = %s\n", str);
LOG("hello world");
return 0;
}
七、复杂结构和指针
1.结构体(类型)
一个结构体所占用的内存为其字段的总字节数,而结构体中存在对齐方式,操作系统在内存上给相关单元申请空间时,有一个默认的对齐方式,先扫描这个结构里面的基本字段类型,会取占用字节最大的类型的字节数进行对齐
struct node1{ //占用8字节
char a; //先申请4字节,自用1字节
char b; //不申请,直接用a剩下的字节。已用2,剩2
int c; //剩下的2字节不够,申请4字节
}
struct node2{ //占用12字节
char a; //申请4,用1
int c; //不够,申请4
char b; //不够,申请4
}
#include<stdio.h>
struct node1{
char a;
char b;
int c;
} a;
struct node2{
char a;
int c;
char b;
} b;
struct node3{
char a;
char b;
int c;
} c[10];
int main(){
//在c语言中一定要保留strcut关键字
printf("sizeof(node1) = %lu\n", sizeof(struct node1)); //8
printf("sizeof(node2) = %lu\n", sizeof(b)); //12
printf("sizeof(c) = %lu\n", sizeof(c)); //80
return 0;
}
2.共用体(类型)
//共用体的内部字段共同利用一片存储单元
//根据字段所占空间最大的申请内存
union register{
struct{ //匿名结构体,仅能使用一次(bytes初始化了一次)
unsigned char byte1;
unsigned char byte2;
unsigned char btye3;
} bytes; //3字节
unsigned int number; //4字节 ---> register就占用4字节
}
使用共用体,实现ip转整数的功能【0~255,256个数字,2^8 = 256,即8位,1字节即可,但注意是无符号型,因为符号位也要用来存值】
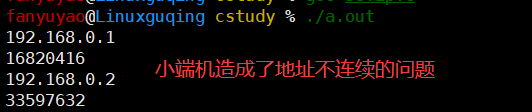
大端机:字节的低位—>高地址位
小端机:字节的低位—>低地址位(会造成地址不连续的问题)
#include<stdio.h>
union IP{
struct {
unsigned char a;
unsigned char b;
unsigned char c;
unsigned char d;
} ip;
unsigned int num;
};
int main(){
char str[100] = {0};
int arr[4];
union IP ip;
while(~scanf("%s", str)){
sscanf(str, "%d.%d.%d.%d", &arr[0], &arr[1], &arr[2], &arr[3]);
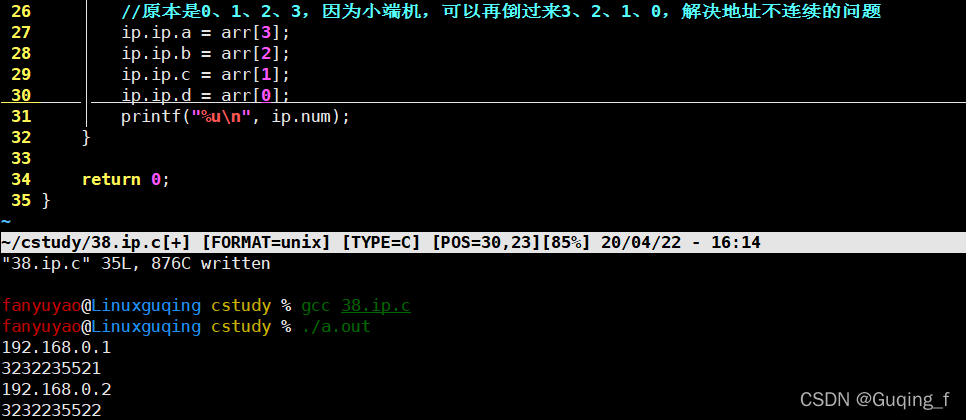
//原本是0、1、2、3,因为小端机,可以再倒过来3、2、1、0,解决地址不连续的问题
ip.ip.a = arr[3];
ip.ip.b = arr[2];
ip.ip.c = arr[1];
ip.ip.d = arr[0];
printf("%u\n", ip.num);
}
return 0;
}
3.变量的地址
操作系统会给内存进行一个连续的编址行为,对应的内存条每一个的字节都会对应成为一个地址,单位是字节。
指针变量就是一种特殊的变量,指针
(32/64位就是说计算机系统是用32/64个bit去表示一个地址)
在32位操作系统中,一个指针变量占4字节
在64位操作系统中,一个指针变量占8字节
用32个2进制位表示一个地址,也就是说它能表示2^32个地址 ==> 4GB
同理,64位操作系统能表示2^64个地址 ==> 理论上是有上限的,实际上是无上限的(很大)
无论是什么类型的地址,在实际上是可以互相存储的,因为在同一个操作系统中指针变量所占用的内存都相同。但是直接这么做是不合适的,应该进行类型转换。
指针变量的类型主要是支持指针变量的计算(只支持+、-)
int a = 0; //占4个字节
&a; //每次取地址取第一个字节的地址,一个int类型的变量有4个地址,一个字节占一个地址。
int *p = &a; //在定义指针变量时,*是一个标志,表示是一个指针变量。p本身也有地址,&a传值时只取了它的第一个字节的地址
int t = *p; //*是一个取值符号。t = 0
p + 1; //向后跳跃了四个字节,每次+1是跳跃一个类型的字节数
int **q = &p; //二级指针变量,指向指针的指针。只要p本身的地址不改变,q的值也不会改变。
*p = 5; //即使p中的值,p中存的是a的地址,所以a = 5
4.等价形式转换
*p == a //a是原始变量
p + 1 == *p[1]
p->filed == (*p).filed == a.filed
#include<stdio.h>
#define P(func){\
printf("%s = %d\n", #func, func);\
}
struct Data{
int x, y;
};
int main(){
struct Data a[2], *p = a;
//用尽可能多的形式表示a[1].x
a[0].x = 0, a[0].y = 1;
a[1].x = 2, a[1].y = 3;
P(a[1].x);
P((a + 1)->x);
P((&a[1])->x);
P(p[1].x);
P((p + 1)->x);
P((&p[1])->x);
P((&a[0] + 1)->x);
P((&p[0] + 1)->x);
P((p + 1)->x);
P((*(&a[1])).x);
P((*(&p[1])).x);
P((*(a + 1)).x);
P((*(p + 1)).x);
P(*((int *)p + 2)); //将p所指向的类型指向整型,p + 1就是向后跳跃4个字节
return 0;
}
5.typedef的用法
//内建类型的重命名
typedef long long lint; //lint就是long long
typedef char *pchar;
//结构体类型的重命名
typedef struct __node{
int x, y;
} Node, *PNode; //Node n就是struct __node n,*PNode p就是strcut __node *p
//函数指针命名
typedef int(*func)(int); //将当前的func提升为类型
int (*add)(int, int); //变量
typedef int (*add)(int, int); //类型
6.函数指针
Main函数参数(只有操作系统可以调用主函数)
int main();
int main(int argc, char *argv[]); //argc: 命令行参数个数;*argv[]: 二维的字符数组,存储若个行字符串
int main(int argc, char *argc[], char **env); //**env: 二维字符数组,环境变量
#include<stdio.h>
int main(int argc, char *argv[], char **env){
printf("argc = %d\n", argc);
for(int i = 0; i < argc; i++){
printf("argv[%d] = %s\n", i, argv[i]);
}
for(int i = 0; env[i]; i++){
printf("env[%d] = %s\n", i, env[i]);
}
return 0;
}
八、工程项目开发
1.函数声明与函数定义的区别
函数未声明:暴露在编译期【g++ -c xx.cpp : 只完成编译期的工作】
函数未定义:暴露在链接期【g++ xx.o:链接编译期生成的文件】
//41.function.cpp
#include <stdio.h>
void funcA(int); //声明
void funcB(int);
//定义
void funcA(int n){
if(n == 0) return ;
printf("funcA: %d\n", n);
funcB(n - 1);
return ;
}
int main(){
funcA(5);
return 0;
}
xxx.c —> C语言源文件
xxx.cpp / xxx.cc —>C++源文件
//41.unite.cc
#include <stdio.h>
void funcA(int n);
void funcB(int n){
if(n == 0) return ;
printf("funcB: %d\n", n);
funcA(n - 1);
return ;
}
使用:
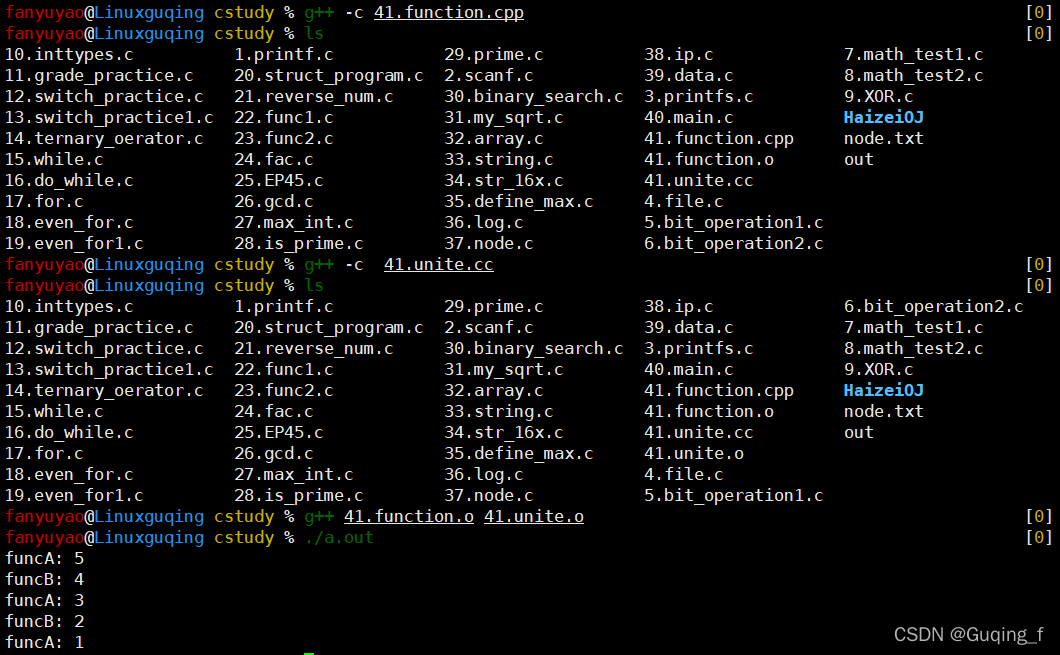
g++ -c 41.function.cpp -->41.function.o
g++ -c unite.cc --> 41.unite.o
多文件链接编译:
2.头文件与源文件
头文件:xxx.h
源文件:xxx.c / xxx.cpp / xxx.cc
#include <head.h> //从系统库查找
#include "head.h" //从当前目录下开始一层层进行查找
头文件里不可以既放声明又放定义。
规范:头文件里放声明,源文件里放定义。

也可以使用:
//-I :将目录映射到库路径下
#include <head.h> //gcc -I./ -c xx.c
3.实现简版的printf函数
首先要创建目录:
src —— 标准的工程项目开发的名字,里面存放源文件
include —— 存放头文件
bin —— 存放a.out
lib —— 存放链接库的库文件

makefile 【脚本语言(文本脚本/工具)类似于 markdown文档】:方便工程项目开发的多文件链接编译过程
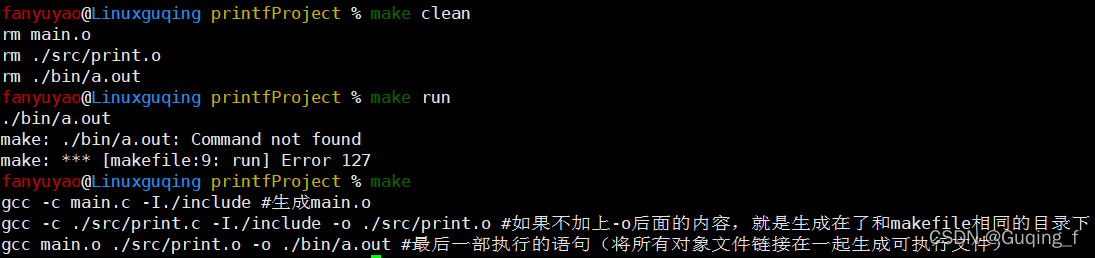
创建名为makefile的文件【touch makefile / touch MAKEFILE】(每次修改文件就重新编译相关的文件):
.PHONY: clean #相当于在一个虚拟路径下创建了一个命令clean,即使当前目录下有名为clean的文件或目录,也不影响
all: main.o ./src/print.o #最后一步需要依赖的文件
gcc main.o ./src/print.o -o ./bin/a.out #最后一部执行的语句(将所有对象文件链接在一起生成可执行文件)
main.o: main.c ./include/print.h #确定main.o的来源
gcc -c main.c -I./include #生成main.o
./src/print.o: ./src/print.c ./include/print.h
gcc -c ./src/print.c -I./include -o ./src/print.o #如果不加上-o后面的内容,就是生成在了和makefile相同的目录下
run: #直接执行可执行程序
./bin/a.out
clean: #清空
rm main.o
rm ./src/print.o
rm ./bin/a.out
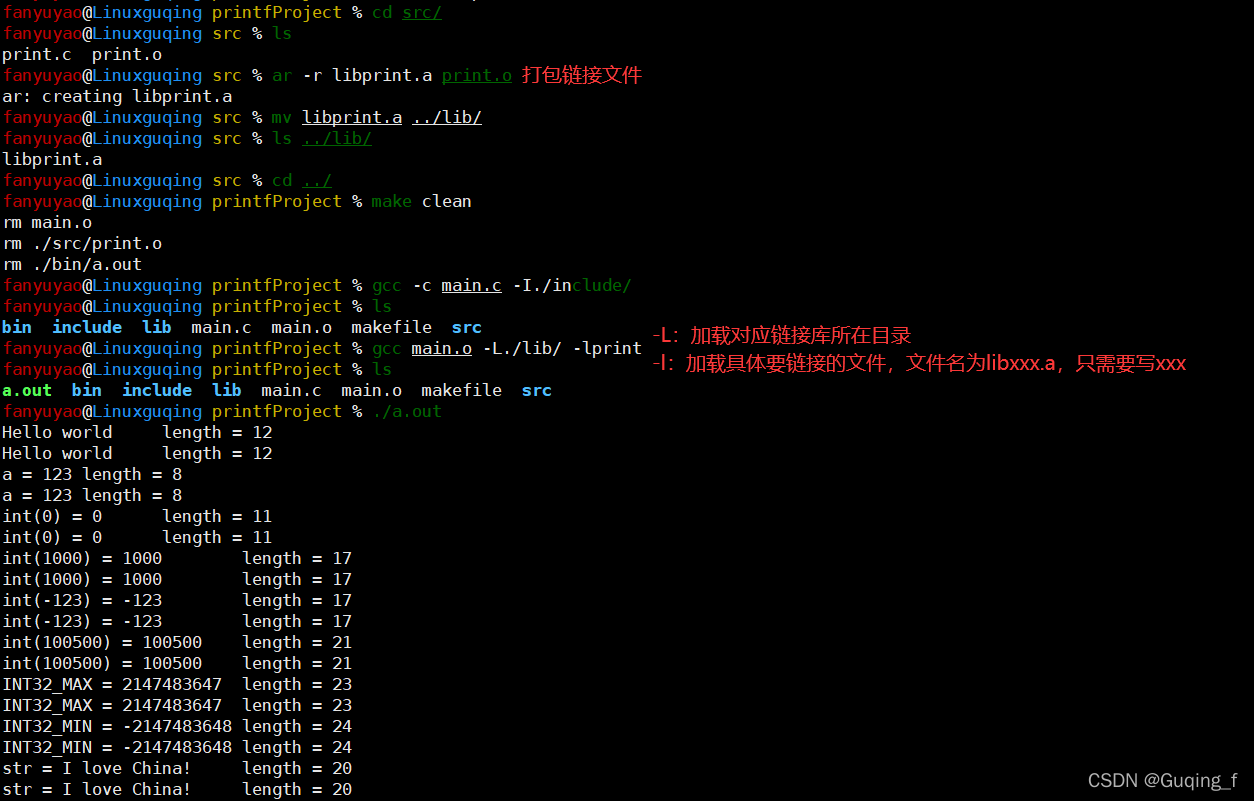
简版printf函数实现:
(1)include/print.h
#ifndef _PRINT_H
#define _PRINT_H
int print(const char *format, ...);
#endif
(2)src/print.c
#include <stdio.h>
#include <stdarg.h>
#define PUTC(a) putchar(a), ++cnt;
int output(char *num, int n){
int cnt = 0;
for(int i = n - 1; i >= 0; i--){
PUTC(num[i]);
}
return cnt;
}
int put_d(int n){
char num[20] = {0};
unsigned int x; //极小值比极大值多1,int直接存存不下
int i = 0, cnt = 0;
if(n < 0) {
x = -n, PUTC('-');
}
else x = n;
do {
num[i++] = x % 10 + '0'; //取整型的最后一位,然后转换成字符
x /= 10;
} while(x);
return cnt += output(num, i);
}
do {
num[i++] = x % 10 + '0'; //取整型的最后一位,然后转换成字符
x /= 10;
} while(x);
return cnt += output(num, i);
}
int put_s(char *str){
int cnt = 0;
for(int i = 0; str[i]; i++){
PUTC(str[i]);
}
return cnt;
}
int print(const char *format, ...){
int cnt = 0;
va_list arg;
va_start(arg, format);
for(int i = 0; format[i]; i++){
//PUTC(format[i]);
switch(format[i]){
case '%':{
switch(format[++i]){
case '%': PUTC(format[i]); break;
case 'd': cnt += put_d(va_arg(arg, int)); break;
case 's': cnt += put_s(va_arg(arg, char *)); break;
}
}
break;
default: PUTC(format[i]);
}
}
va_end(arg);
return cnt;
}
#undef PUCT
(3)main.c
#include<stdio.h>
#include <inttypes.h>
#include <print.h>
int main(){
int a = 123;
printf("length = %d\n", printf("Hello world\t"));
print("length = %d\n",print("Hello world\t"));
printf("length = %d\n", printf("a = %d\t", a));
print("length = %d\n", print("a = %d\t", a));
printf("length = %d\n", printf("int(0) = %d\t", 0));
print("length = %d\n", print("int(0) = %d\t", 0));
printf("length = %d\n", printf("int(1000) = %d\t", 1000));
print("length = %d\n", print("int(1000) = %d\t", 1000));
printf("length = %d\n", printf("int(-123) = %d\t", -123));
print("length = %d\n", print("int(-123) = %d\t", -123));
printf("length = %d\n", printf("int(100500) = %d\t", 100500));
print("length = %d\n", print("int(100500) = %d\t", 100500));
printf("length = %d\n", printf("INT32_MAX = %d\t", INT32_MAX));
print("length = %d\n", print("INT32_MAX = %d\t", INT32_MAX));
printf("length = %d\n", printf("INT32_MIN = %d\t", INT32_MIN));
print("length = %d\n", print("INT32_MIN = %d\t", INT32_MIN));
char str[100] = "I love China!";
printf("length = %d\n", printf("str = %s\t", str));
print("length = %d\n", print("str = %s\t", str));
printf("length = %d\n", printf("str = %s\t", "Hello World!"));
print("length = %d\n", print("str = %s\t", "Hello World!"));
return 0;
}
链接库
①动态链接库【xxx.so】
②静态链接库(重点)【xxx.a】
要生成的静态链接库的名字规范:libxxx.a【前后缀必须是lib和.a】
要是对您有帮助,点个赞再走吧~ 欢迎评论区讨论~