目录:
Redis从入门到精通(一):缓存
Redis从入门到精通(二):分布式锁以及缓存相关问题
Redis从入门到精通(三):Redis持久化算法以及内存淘汰策略
Redis从入门到精通(四):Redis常用数据结构以及指令
Redis从入门到精通(五):Redis6整合SpringBoot2.x+Mybatis+SpringCache
Redis从入门到精通(六):Redis高可用原理
Redis从入门到精通(七):跳跃表的简介与实现
Redis从入门到精通(八):Redis新特性
线程问题
新版本的Redis在对数据的操作时是单线程的,但是在处理网络传输的时候(读写以及网络协议)是多线程的,这样为了加快处理网络任务,同时保证数据安全。
而老版本的Redis在处理网络任务的时候也是单线程的。其实一些后台任务,无论新老Redis均是多线程处理,否则只能阻塞,这样就大大降低了它的速度。
所以,无论新老版本,无论开不开多线程都不会存在数据安全问题,因为数据操作不支持多线程。
默认不开启多线程模式,可以再配置文件中打开:
io-threads-do-reads yes
io-threads 5 #开启五个线程
权限问题
ACL(Access Control List)是Linux操作系统的安全核心,比如用户组,文件的权限等等。但是对于Redis来说,老版本的Redis是没有用户的概念的,新版本可以增加用户组。
这个新加的权限处理是否必要?不同的人有不同的看法吧,至少对于安全问题,肯定是更安全了,但是这个安全性能提高多少?比如redis服务一半部署在linux机器上,我直接用linux对文件的权限来控制redis,其实绝大部分问题已经解决了,毕竟能有linux物理机上权限的人,想要搞redis还不是轻轻松松。。。。
所以这块我想说啥了,和linux用户权限一样简单。随便找个文档都能解决。
管道
这个就是linux系统中的pipe,也就是 | 这个符号。
用于处理客户端的连接,Redis用它来进行非阻塞式的响应。比如每个客户端向redis更新数据,了解计算机网络的同学知道,这会有一个连接,还有一个名词叫做RTT,是客户端到redis,再从redis到客户端的响应时间。
通常来说,客户端到redis后,会等待redis给结果,redis再将结果给客户端。假设这个时间是250ms,也就是1s内,redis只能处理4条数据。
有了管道后,客户端可以一直发送数据,不必管消息是否被处理,这些消息先被传进管道,管道再将他们依次传给redis,redis只要在最后读取返回的消息就行。
管道不是新特性,但是之前我没说,所以这里补充一下。
客户端缓存
这玩意和上面的权限不同,这个是切切实实能大幅提升性能的方法,毕竟不需要通过网络进行数据访问,大大提升了用户端的反馈速度。
画一个不标准的数据流图: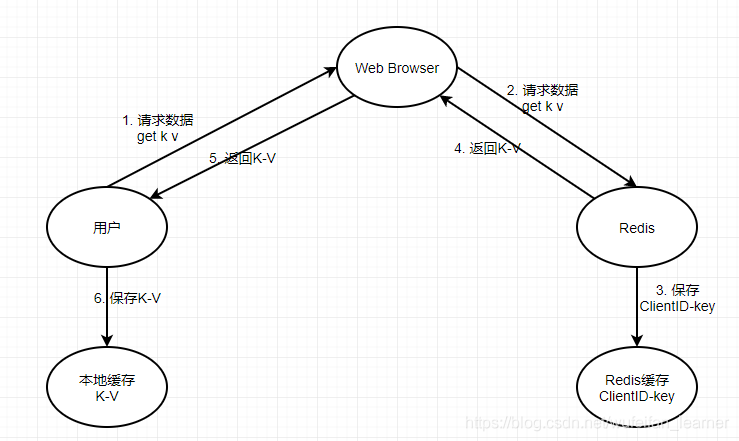
这是缓存的流程,当我们这个客户端第二次取值呢?流程如下: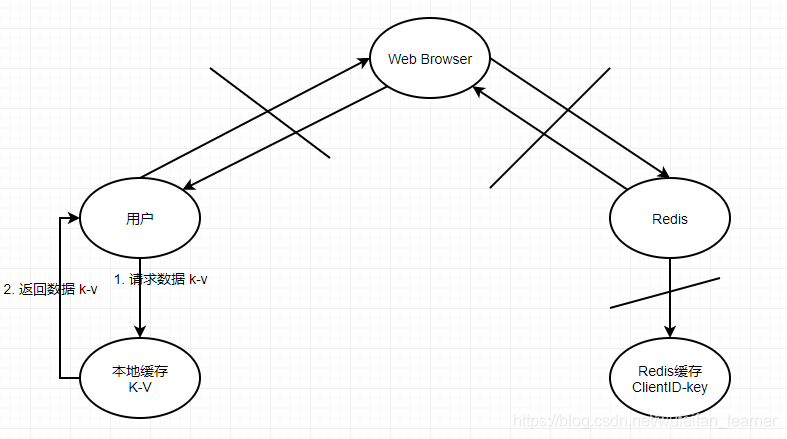
根本就不经过网络了。
如果key未找到,那再去Redis找。当然,如果数据有修改怎么办?
(他妈的,这里我原来以为很简单,但是稍微思考了一下,发现真的超出了我的能力范围。本来想很快结束redis的最后一个章节,现在看来还要多写好多东西了。咳,先说基础的吧,一会再说我的思考)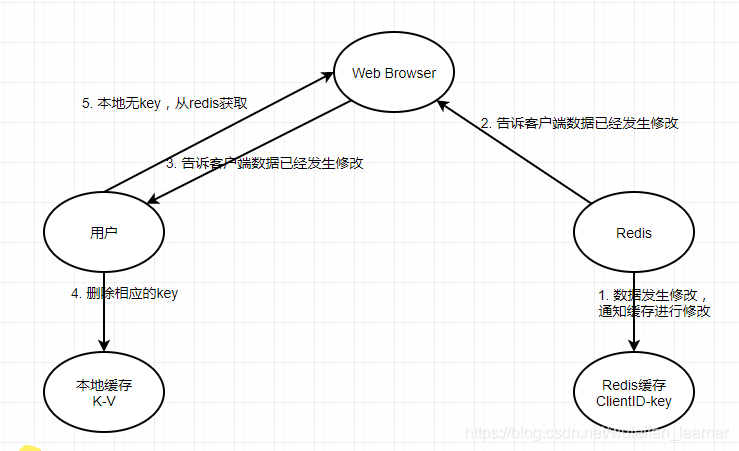
根据RESP3(Redis通信协议),这里有两种模式:
默认模式:
- Server记录所有的Client存储的key,发生变更再通知client
- Client需要缓存可能要增加
- Server端缓存数量也会增加(毕竟多了这么多的客户端存储了哪些key的信息)
广播模式:
- Client会在key更改时接收广播消息,收到消息后对本地缓存的key进行查验,看看自己有没有相关的key
- 该方法针对于key的前缀,不是精确匹配。为了使得服务端存储的 数据量变少,往往Server只会记录客户端存的key前缀。
- 举个例子:假设一个
key-value是这样的:
key:service1:name1 abc123
key:service1:name2 def456那么服务端只会存储
Client-id:123 key:service1
Client-id:345 key:service1那我现在对
key:service1:name1进行修改,服务端只会判断key:service1部分,不管key:service1:name2有没有修改,都会认为修改,因为他们前缀相同。所以所有客户端都会收到通知,然后判断自己有没有存储key:service1这个键值,然后做出相应动作。
到目前为止,一切顺利。接下来是重头戏,想要和我一起思考的童鞋可以看过来,如果只是为了了解Redis的普通原理,下一节可以忽略。
客户端缓存的相关问题
问题一: 假设在默认模式下,客户端一对Redis进行修改,然后Redis对客户端传消息通知修改,此时客户端二对Redis再进行修改,Redis进行下一步通知。但是呢,由于网络延迟的原因,明明客户端们应该先接收到客户端一的修改,但是实际上最后才收到修改命令,这样就造成了赃写赃读问题,这种情况下怎么办?
解答一: 我们认为Redis是永远值得信赖的,而网络是不值得信赖的。因此当Redis接收到更新key的命令后,我们往各个客户端传递的消息是删除缓存,而不是更新缓存。此时客户端需要用到key的话,需要重新从Redis拉去数据。这是惰性方法,和同步机制很像。
问题二: 假设在广播模式下,同样发生了上述的广播冲突,怎么办?
解答二: 同样的原理,我们只认为Redis是值得信赖的,所以一旦发生数据更改,就从Redis重新拉取数据。
问题三: 为了避免key的冲突,我们往往对key取很长的名字 (最长不超过512MB)。但是这么长的名字会对Redis资源造成一定的影响。并且通过网络传输这么长的key也会比传输短一些的key更慢(短到一定程度则没区别,关键看网络分片长度)。怎么解决这个问题?
解答三: 我们可以发送slot。回忆一下之前说到的Redis集群原理,会把key分成三个slot,每个slot存储一定的key。每个slot有自己的hash值。假设一个key在slot1里,这个key被修改了,那我们只需要广播slot1,每个客户端查看自己的key是否在这个slot里就行,如果在,就惰性获取新的key
问题四: 在解答三中,如果发送slot的hash值,每个客户端还要遍历所有的key,这样在客户端的时间复杂度有点高,怎么办?
解答四: 仍然可以利用惰性思想,存起来这个slot以及存slot的时间戳。每次用到key的时候就去判断是否在slot中,如果这个key的更新时间在slot的更新时间之后,那么不用更新key,直接取来用;如果key的更新时间在slot更新时间之前,去Redis取。
问题五: 在本地key更新的时候,又传来了新的slot,怎么办?
解答五: 总是认为key是旧的,出现这种情况直接去Redis取。如果slot时间略早于key的更新时间,但是slot才是最新的值,我们可以将key更新的时间减去一定的时间,我调表使得程序判断key总是旧的,就可以解决问题。
问题六: 在默认模式中,Redis缓存的方式是:
client-id key。这样的话我们找某个key是否在某个客户端中,需要遍历所有的client,再对所有的client通过hash值找到是否有相对应的key。就算hash方法得到key的时间复杂度为O ( 1 ) O(1)O(1),那么遍历一遍client的时间复杂度也有O ( n ) O(n)O(n),在大量修改数据的情况下,这种情况肯定是不好的,但是为什么要这么设计?为什么不能设计成key client-id的情形呢?解答六: 唉,实际上人家官方就是以
k-c形式存储的结构,所以我画的上图是有问题的。我太懒了,不想改了。大家看到这里就知道为啥了。最后,关于客户端缓存的源码在这个链接里:https://github.com/redis/redis/blob/unstable/src/tracking.c
现在还是unstable版本,不过应该很快就能加入stable里面了。
Redis相关到这就结束了。有什么新东西以后可能会加进来,但是以我的懒惰,期望不大,哈哈。后续我准备总结下消息队列(RabbitMQ,Kafka)和Netty组件。边学习边写博客吧,利用好假期学一些企业的东西,学校学的毕竟脱离实际开发,为以后拿到高级offer做准备!