数据写入内存时包含的信息有:measurement、timestamp、tags、fields的值。
写入内存
首先根据measurement和tag的值生成seriesKey
然后逐个field处理,写入内存中存储数据的数据结构:Map<seriesKey+field,List<Timestamp|Value>>
写入磁盘
当内存中的数据量达到一定限制(默认25M)或时间达到限制(默认10分钟),内存中的数据将会flush到磁盘。
将内存中的Map<seriesKey+field,List<Timestamp|Value>>,逐个key处理(即按照field逐个flush,flush完一个field,再处理下一个)
首先根据时间确定数据flush到哪个shardgroup
根据seriesKey进行hash,确定数据flush到shardgroup下的哪个shard
生成data block及index block,并写入TSMFile(当一个field的值超过一个block的大小,则生成多个block并按顺序写入文件。详细文件结构将在下文讲述)
一个shard可能会包含多个TSM文件,每个TSM文件最大为2G。结合上一篇文章中所说到的,可以知道一个shardgroup包含多个shard,一个shard包含多个TSM文件。
TSM文件是InfluxDB中实际存储数据的文件,包含数据和数据的索引两部分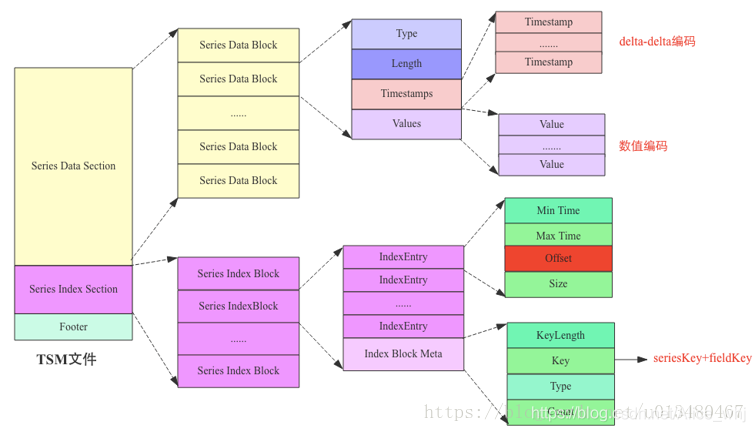
eries Data section
这部分的组成是data block, data block是存储数据的快,时间戳和field存在data block中,tags不会存储在data block中。
细看data block的结构,包含四个部分:
type:记录存储的value的类型
length:记录时间戳存储段的长度。
timestamps: 数据对应的所有时间戳
values: field的值
可以发现数据是按列存储的,时间戳和field的值分别存储,这有利于数据压缩,InfluxDB对时间戳采用了Facebook开源的Geringei系统中对时序时间的压缩算法:delta-delta编码。其他数据类型,不同数据类型对应不同的编码算法。
这部分由一个个index block组成,每个index block是一个field的数据的索引。
index block由一个index meta和多个index entry组成
index meta中的key记录了数据的seriesKey和field,表示这个index block内所有IndexEntry所索引的时序数据块都是该Key对应的时序数据。
index entry指向对应的data block。offset和size记录了对应data block在文件中的偏移量和长度,通过offset和size即可读取对应的datablock。max time和min time记录了所指向的data block中的时间戳的最大最小值,用户在根据时间范围查找时可以根据这两个字段进行过滤,而不需要读取整个data block进行扫描。
Rentention Policy
简称RP,数据保留策略。用来指定数据的保留时间、副本数量以及每个shardgroup的时间跨度。
shardgroup
shardgroup是InfluxDB中一个重要的逻辑概念,它负责指定时间跨度的数据存储,这个时间跨度就由上文提到的创建RP时指定。如果没有指定,系统将通过RP的数据保留时间来计算:
将数据按照时间分割成小的粒度会使得数据过期实现非常简单,InfluxDB中数据过期删除的执行粒度就是Shard Group,系统会对每一个Shard Group判断是否过期,而不是一条一条记录判断。
Shard是InfluxDB中真正存储数据以及提供读写服务的概念,Shard是InfluxDB的存储引擎实现,具体称之为TSM(Time Sort Merge Tree) Engine,负责数据的编码存储、读写服务等。
sharding
Shard Group对数据按时间进行了分区,那落在一个Shard Group中的数据又是如何映射到哪个Shard上呢?
这里我们就要说要InfluxDB的sharding策略。InfluxDB的sharding策略,在确定数据应该写入哪个shardgroup之后,会根据series进行hash,决定数据写入shardgroup下的哪个shard。