在与链表相关的诸多结构中,邻接表是相当重要的一个。它是树与图结构的一般化存储方式, 邻接表可以看成“带有索引数组的多个数据链表”构成的结构集合。在这样的结构中存储的数据被分成若干类,每一类的数据构成一个链表。每一类还有一个代表元素,称为该类对应链表的“表头”。所有“表头”构成一个表头数组,作为一个可以随机访问的索引,从而可以通过表头数组定位到某一类数据对应的链表。为了方便起见,本书将这类结构统称为“邻接表”结构。
如下图左侧所示,这是一个存储了6个数据节点v1~v6的邻接表结构。这6个数据节点被分成4类, 通过表头数组head可以定位到每一类所构成的链表进行遍历访问。
当需要插入新的数据节点时, 我们可以通过表头数组head定位到新的数据节点所属类别的链表表头,将新数据在表头位置插入。如下图右侧所示,在邻接表中插入了属于第5类的新数据节点V7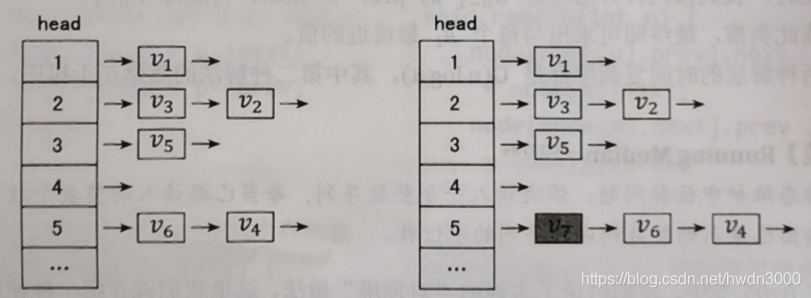
在一个具有n个点m条边的有向图结构中,我们可以把每条边所属的“类别”定义为该边的起点标号。这样所有边被分成n类,其中第x类就由“从x出发的所有边”构成。通过表头head[x] , 我们很容易定位到第x类对应的链表,从而访问从点x出发的所有边。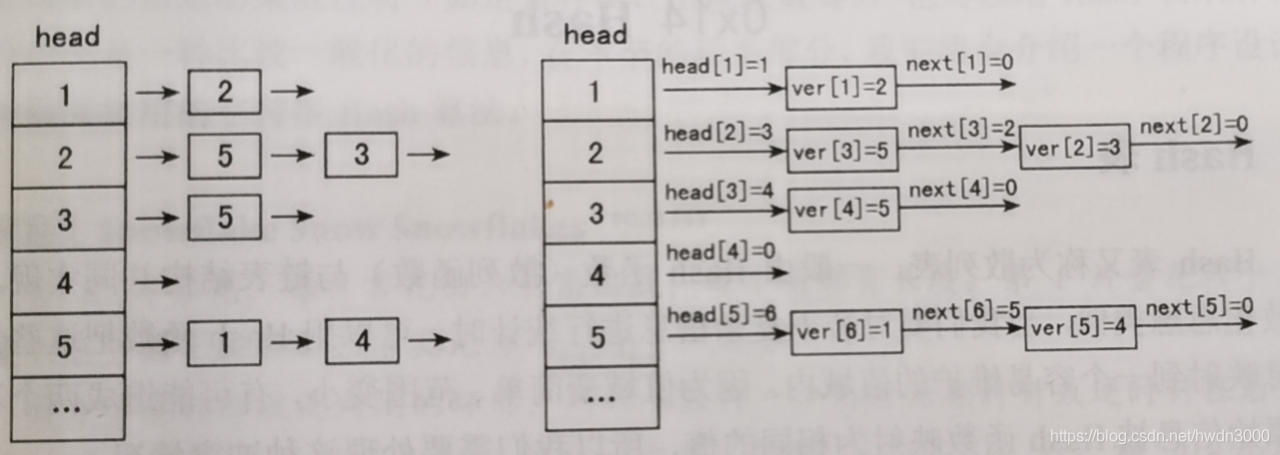
上图是在邻接表中插入一张5个点、6条边的有向图之后的状态。这6条边按照插入的顺序依次是(1,2),(2,3),(2,5),(3,5),(5,4),(5,1)。上页图左侧展示了这个邻接表存储的宏观信息,上页图右侧展示了采用“数组模拟链表”的实现方式时,内部数据的实际存储方式。head与next数组中保存的是“ver数组的下标”, 相当于指针, 其中0表示指向空。ver数组存储的是每条边的终点, 是真实的图数据。
部分代码:
int head[200010], ver[400010], edge[400010], Next[400010];
//加入有向边(x,y),权值为z
void add(int x, int y, int z) {
ver[++tot] = y, edge[tot] = z;//真实数据
Next[tot] = head[x], head[x] = tot;//在表头x处插入
}
//访问从x出发的所有边
for(int i=head[x] ; i ;i=next[i] ) {
in y=ver[i] , z=edge[i] ;
//找到了一条有向边(x,y),权值为z
}
也可以用结构体来存储邻接表:
完整代码:
#include<iostream>
using namespace std;
const int maxn=1001,maxm=100001;
struct Edge
{
int next,to,dis;
}edge[maxm];
int head[maxn],num,n,m,u,v,d;
void add(int from,int to,int dis)
{
edge[++num].next=head[from];
edge[num].to=to;
edge[num].dis=dis;
head[from]=num;
}
int main()
{
num=0;
cin>>n>>m;//m为边数 n为结点数
for(int i=1;i<=m;i++)
{
cin>>u>>v>>d;
add(u,v,d);
}
for(int i=1;i<=n;i++)
{
for(int j=head[i];j!=0;j=edge[j].next)
cout<<edge[j].to<<edge[j].dis<<endl;
}
return 0;
}
/*5 8
1 2 5
1 3 8
1 5 3
2 5 6
2 3 2
3 4 10
3 5 4
4 5 11
*/版权声明:本文为hwdn3000原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。