欢迎阅读第 3 篇文章,这是揭秘 Hyperledger Fabric系列的最后一篇文章。 在第一篇文章中,已经解释了 Hyperledger Fabric 的底层架构。 第 2 篇文章描述了称为私有数据集合的 Fabric 的重要特性之一。
我想用这篇文章来讨论 Hyperledger Fabric 中的一些辅助补充服务,包括以下主题:网络流量处理(Network Traffic Handling)、服务发现(Service Discovery)和运营服务(Operations Service)。
本文目录:
- 网络流量处理(Network Traffic Handling)
- 服务发现(Service Discovery)
- 运营服务(Operations Service)
- 运营指标:基于 Prometheus 的拉取模型
- 运营指标:基于 StatsD 的推送模型
- 总结
网络流量处理(Network Traffic Handling)
由于多个参与组织加入通道,网络流量堵塞可能是 Fabric 通道上最潜在的问题之一。此外,每个组织可以拥有多个节点。让我们想象一下,如果参与组织和相关节点的数量随着时间的推移而增加,则 排序节点(Orderer)将因将交易块分发给每个通道上的每个节点的任务而负担过重。因此,排序节点(Orderer)容易出现单点故障。
为了向排序节点(Orderer) 提供崩溃容错 (Crash Fault Tolerance, CFT),Hyperledger Fabric 目前支持 CFT 排序服务的两种实现,即 Kafka 和 Raft。此外,几种类型的拜占庭容错(Byzantine Fault Tolerant,BFT)排序服务也在开发中。请参阅此链接了解更多信息。
除了减轻(Orderer) 的区块分配开销之外,还向所有参与组织引入了领先节点(Leading Peers)。每个组织都可以选择性地授权哪些节点成为领先节点。如下图 1 所示,Org1 的#2节点和 Org2 的@#2节点被指定为领先节点。

图 1 描述了使用领先节点的 Fabric 区块传播方案的工作流程:
- 客户端向选定的背书节点发送交易提议。
- 每个背书节点生成一个交易响应并将已背书的响应发送回客户端。
- 客户端将附有背书响应的交易提交给排序节点(Orderer)。
- 排序节点(Orderer)创建一个有序交易区块,然后将创建的区块分发给与组织关联的每个 领先节点。
- 每个领先节点通过八卦数据传播协议(gossip data dissemination protocol)将接收到的区块传播给属于同一组织的其他节点。
前面讨论的 Fabric 区块传播方案可以显著减少排序节点(Orderer)的开销。因此,这个方案对于 Hyperledger Fabric 是必要的。每个组织都可以静态定义哪些节点成为领先节点。但是,如果没有静态指定节点,Fabric 系统还具有自动运行的动态领先节点选择算法。
服务发现(Service Discovery)
为了调用交易来更改账本的状态,客户端应用程序(client application)必须知道背书交易提议所需的一组背书节点。在 Fabric 1.2 版之前,此信息被静态编码到特定通道的 Fabric 系统链码中。
但是,这种静态配置不能适应网络变化。例如,当新组织加入频道或更改链码背书策略时。此外,静态配置也是不灵活的,以防有背书节点暂时离线。
在 Fabric 1.2 版中,引入了发现服务(discovery service)以方便客户端应用程序发现成员和背书配置、所有活动节点以及其他可用服务。请参阅此链接以了解发现服务的功能。发现服务在 Fabric SDK 方面提供 API 接口,供客户端向属于同一组织的节点查询所需的信息(例如,列出通道上的所有活动节点)。反过来,被查询的节点动态计算所需的信息并将可消费信息返回给客户端。
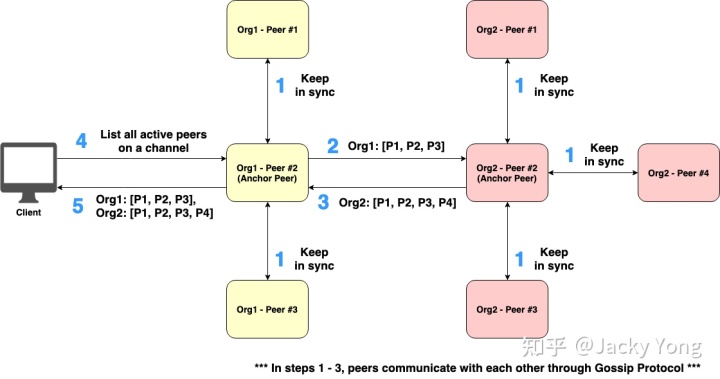
为了使发现服务(discovery service)有效工作,必须为每个组织配置称为锚点节点(Anchor Peer) 的特殊类型 Fabric节点。 锚点节点的主要作用之一是节点发现。更具体地说,所有节点都可以查询属于同一组织的锚点节点,以动态发现通道上属于其他组织的所有其他节点。为了防止单点故障,一个组织可以有多个锚点节点。如图 2 所示,Org1 的节点#2和 Org2 的节点#2被配置为锚点节点。
图 2 说明了在锚点节点支持下的节点发现的工作流程:
- 普通节点通过八卦协议(gossip protocol)定期与属于同一组织的锚点节点保持同步。
- Org1 的锚点节点使用八卦协议定期将 Org1 的活动节点列表更新为 Org2 的锚点节点。
- Org2 的锚点节点还通过八卦协议定期将 Org2 的活动节点列表更新为 Org1 的锚点节点。
- 一旦客户端需要知道通道上所有活动节点的列表,客户端会使用 Fabric SDK 发出查询请求,并将请求发送到属于同一组织的节点之一。
- 查询节点向客户端响应所有活动节点的列表。
运营服务(Operations Service)
在 1.4 版本的发布中,Hyperledger Fabric 主要着眼于完善其稳定性和生产运营。运营服务是主要更新之一。运营服务可以帮助系统运营商确定排序节点(Orderer)、节点(Peers)和Fabric CA 的活跃度和健康状况。这项服务还可以帮助运营商更好地了解 Fabric 系统如何随着时间的推移而执行。
每个节点(包括 Orderer 节点、节点(Peers) 和 Fabric CA)通过向系统操作员公开 HTTP RESTful API 来提供操作服务。为了限制对任何敏感信息的访问,该 API 与 Fabric 区块链服务隔离,该 API 旨在仅用于操作员操作和监控 Fabric 系统组件的健康状况。
API 公开了以下功能:
在本节中,我想重点关注运营指标。 Hyperledger Fabric 提供了两种模型来暴露运营指标,即基于 Prometheus 的拉模型和基于 StatsD 的推模型。
运营指标:基于 Prometheus 的拉取模型
我们可以设置 Prometheus,通过连接到检测目标节点公开的 /metrics API 端点(endpoint),定期从节点(包括 排序节点(Orderer)、节点(Peers)和 Fabric CA)抓取运营指标。 Prometheus 通常配备 WebUI 用于指标可视化以及警报和通知服务。
要使 Fabric 节点支持 Prometheus,请查看此文档。 以下是 Prometheus 当前导出以供使用的指标列表。
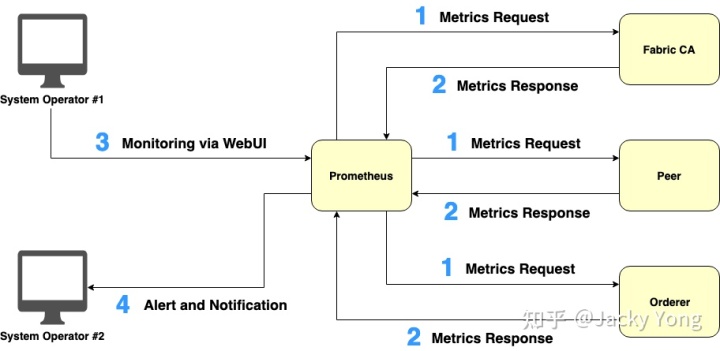
图 3 描述了利用 Prometheus 从不同类型的节点提取运营指标的工作流程:
- Prometheus 会定期发出拉取请求以将指标抓取到 Fabric 目标节点。
- 每个 Fabric 目标节点都会向 Prometheus 响应其相关指标。
- 系统操作员通过 Prometheus 的 WebUI 监控聚合指标。
- Prometheus 根据操作员设置的条件向系统操作员发送警报和通知。
运营指标:基于 StatsD 的推送模型
除了利用 Prometheus 作为拉取运营指标的引擎,Hyperledger Fabric 还支持基于 StatsD 的推送模型。 我们可以配置 Fabric 节点(包括 排序节点(Orderer)、节点(Peers)和 Fabric CA)来定期向 StatsD 守护程序提交运营指标。 然后可以将 StatsD 聚合的指标推送到一个或多个可插拔后端服务,例如 Graphite,用于指标可视化和警报。
要配置 Fabric 节点以将指标提交给 StatsD,请遵循此文档。 以下是 StatsD 当前为使用而发出的指标列表。
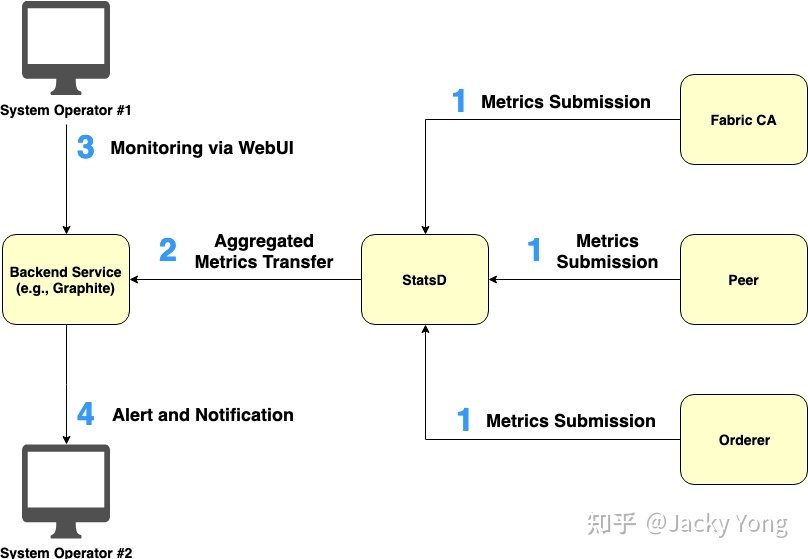
将运营指标从不同类型的节点推送到 StatsD 的工作流程如图 4 所示:
- 每个 Fabric 节点定期向 StatsD 提交其相关指标。
- StatsD 将汇总的指标提交给后端服务,例如 Graphite,用于指标可视化和警报。
- 系统操作员通过后端服务的 WebUI 监控聚合指标。
- 后端服务根据操作员设置的条件向系统操作员发送警报和通知。
总结:
这是揭秘Hyperledger Fabric 系列的最后一篇文章。 您已经学习了 Hyperledger Fabric 中的多项服务,这些服务为区块链开发人员、区块链架构师和系统运营商提供了便利。
实际上,还有几个有趣的话题需要讨论,包括:
- Hyperledger Fabric 中的多版本并发控制
- Hyperledger Fabric 中的身份、身份验证和授权
- 通道级访问控制和策略
- 高级链码开发
- 链码级基于属性的访问控制
- 链码级加密
- Fabric排序服务
- Hyperledger Fabric 中的零知识证明
- 高级Fabric性能优化和高可用性