简介
在这个项目中,我们将使用PyTorch框架实现一个神经网络,这个网络实现法文翻译成英文。这个项目是Sean Robertson写的稍微复杂一点的教程,但对学习PyTorch还是有很大的帮助。
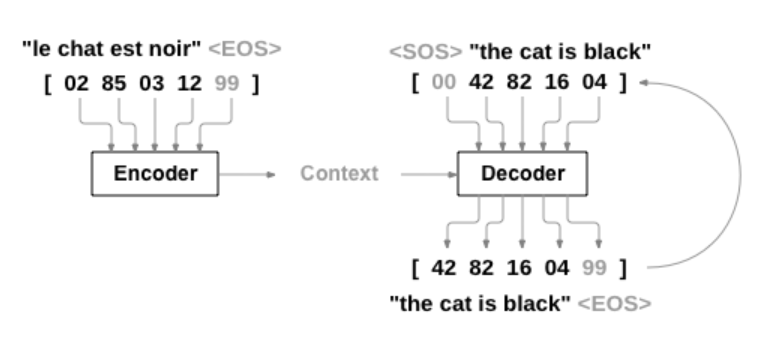
本文通过序列网络的这种简单而强大的思想来实现的,其中包括两个循环神经网络一起工作以将一个序列转换为另一个序列。 编码器网络(Encode)将输入序列压缩成矢量,解码器网络(Decode)将该矢量展开为新的序列。为了改进这个模型,我们将使用一个注意机制,让解码器学习把注意力集中在输入序列的特定范围上。
关于这些技术,更多的学习资料可以在下面网址学习:http://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
数据集
这个项目的数据是一组数以千计的英语到法语的翻译对。作者选取了其中部分数据构建本文的训练数据集(data / eng-fra.txt)。 该文件是一个制表符分隔的翻译对列表(下载地址:https://download.pytorch.org/tutorial/data.zip):

我们才有one-hot vector初始化词,与前面分类名词不同的是,这里把单词看作一个独立的语言粒度: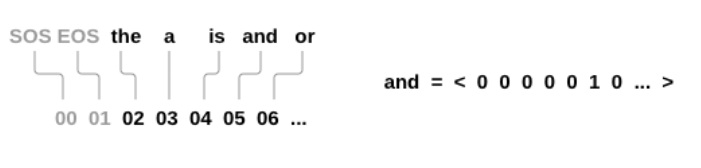
我们需要每个单词的唯一索引作为以后网络的输入(inputs)和目标(targets)。 为此,我们使用名为Lang的助手类,它具有词→索引(word2index)和索引→词(index2word)字典,以及每个单词word2count的计数以用于稍后替换罕见词语。
SOS_token = 0
EOS_token = 1
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
要读取数据文件,我们将文件分割成几行,然后将行分成两部分。 这些文件都是英文→其他语言,所以如果我们想从其他语言翻译→英文,我添加了reverse标志来反转对。
def readLangs(lang1, lang2, reverse=False):
print("Reading lines...")
# Read the file and split into lines
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
本文数据预处理过程是:
1.读取文本文件并拆分成行,将行拆分成对
2.使文本标准化,按照长度和内容进行过滤
3.从成对的句子中构建单词列表
Seq2Seq模型
Seq2Seq(Sequence to Sequence network or Encoder Decoder network)是由两个称为编码器和解码器的RNN组成的模型。 编码器读取输入序列并输出单个矢量,解码器读取该矢量以产生输出序列。
与单个RNN的序列预测不同,每个输入对应于一个输出,seq2seq模型无需考虑序列长度和顺序,这使得它成为两种语言之间翻译的理想选择。使用seq2seq模型,编码器会创建一个单一的矢量,在理想的情况下,将输入序列的“含义”编码为单个矢量 - 句子的N维空间中的单个点。
The Encoder
seq2seq网络的编码器是一个RNN,它为输入句子中的每个单词输出一些值。 对于每个输入单词,编码器输出一个向量和一个隐藏状态,这个隐藏状态和下一个单词构成下一步的输入。
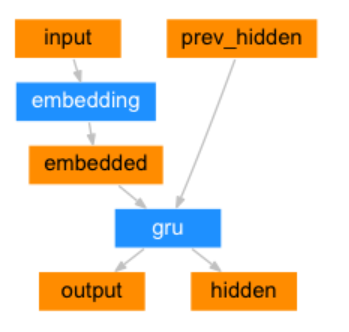
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
return result
The Decoder
解码器是另一个RNN,它接收编码器输出向量并输出一个字序列来创建翻译。
在最简单的seq2seq解码器中,我们只使用编码器的最后一个输出。 这个最后的输出有时被称为上下文向量,因为它从整个序列编码上下文。 该上下文向量被用作解码器的初始隐藏状态。如果仅在编码器和解码器之间传递上下文向量,则该单个向量承担编码整个句子的负担。注意力(Attention Decoder)允许解码器网络针对解码器自身输出的每一步“聚焦”编码器输出的不同部分。首先我们计算一组注意力权重。 这些将被乘以编码器输出矢量以创建加权组合。
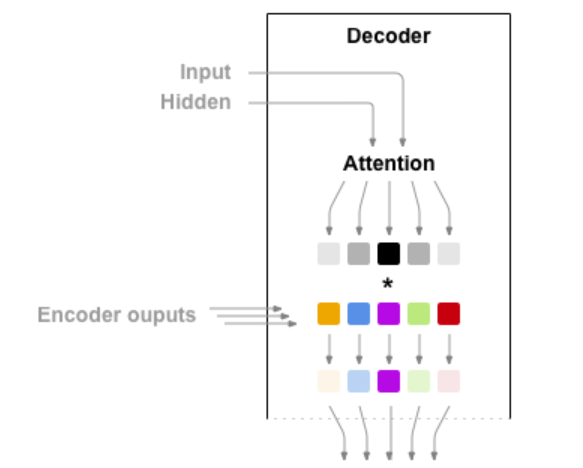
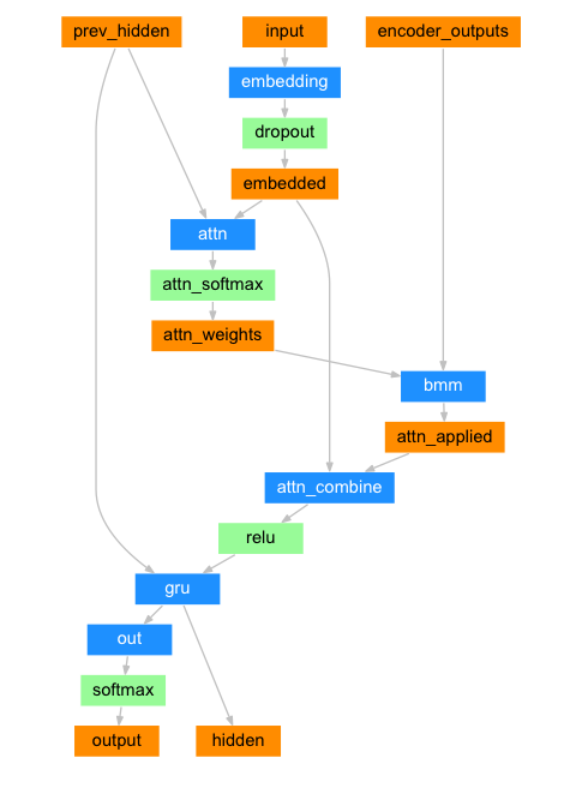
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
return result
训练和测试模型
loss 图: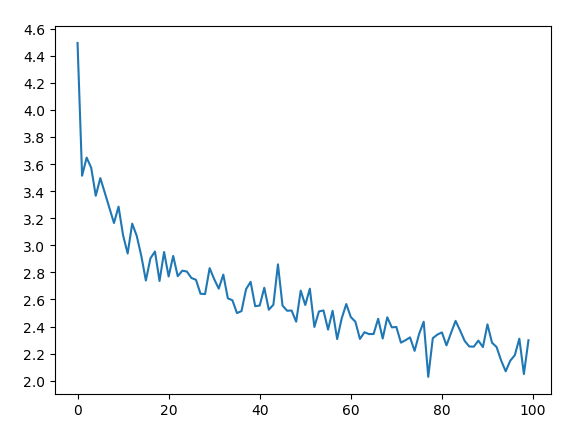
评估与训练大部分相同,但没有目标(target),因此我们只是将解码器的预测反馈给每一步的自身。 每当它预测到一个单词时,我们就会将它添加到输出字符串中,并且当生成EOS字符就停止。 我们还存储解码器的注意力输出以供稍后显示。
可视化Attention,这个机制的一个有用特性是其高度可解释的输出。 因为它用于对输入序列的特定编码器输出进行加权,所以我们可以想象在每个时间步骤中网络最集中的位置。这里将注意力输出显示为矩阵,其中列是输入步骤,行是输出步骤: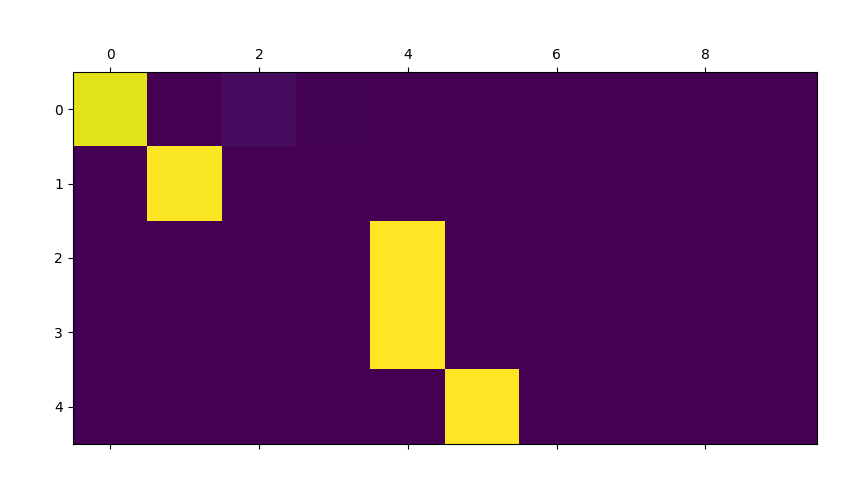
更好的观看体验,我们额外用了几个数据对: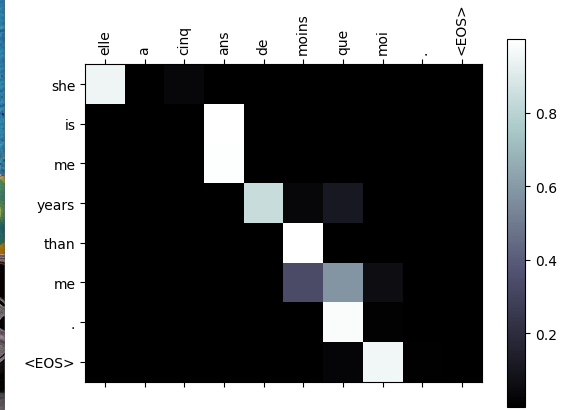
注意:所以的代码基本上为教程上的,我跑通的代码稍微会上传到github上。
参考:http://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
更多AI、ML、NLP干货资源请关注公众号:AI小白入门(ID: StudyForAI):