前言:
为何写此篇?
最近搞毕设,需要用到Attenion去学习时间序列,同性交友网(github)和CSDN也有很多文章,但是由于 Tensorflow迭代比较快,而很多历程使用的是旧版本,这让我们这种CV掏粪男孩很难受。而且由于大佬们的版本都是涉及到多通道的注意力值,我也就进行了简化,只处理单通道数据。所以写下此篇方便大家愉快CV,也顺便记录一下自己的感悟吧。
参考文献
https://github.com/philipperemy/keras-attention-mechanism.
https://blog.csdn.net/jinyuan7708/article/details/81909549.
正文
运行环境
| Name | Version | 备注 |
|---|---|---|
| python | 3.8.8 | |
| tensorflow | 2.4.1 | |
| numpy | 1.19.5 | 这个tensorflow版本不要升级np! |
| matplotlib | 3.4.1 |
代码
import numpy as np
np.random.seed(1337) # for reproducibility
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import LSTM,Dense,Permute,Input,Reshape,Multiply
import matplotlib.pyplot as plt
准备数据
- 创建
n条长度为time_stpes的时序数据集 - 这个数据集里的数据x都是随机的,而数据集的标签y也是随机生成(0,1)
- 把数据x中的其中一步
attention_column全替换为和标签相同的值
也可以这么理解
- 生成的数据x尺寸是
n行time_stpes列,内容是完全随机的 - 生成的标签y是
n行随机的0和1 - 把y的值赋给x中的第
attention_column列
这就意味着,标签y只与x中的attention_column这一列有关,与其他数据没有任何关系。
代码
"""
产生一组尺寸为(n,timesteps,input_dim)的随机数据,其中第attention_column个时间序列的值与标签相同,相当于标签只取决于该行(个,行,列)数据
"""
def get_data(n, time_steps, input_dim, attention_column=10):
x = np.random.standard_normal(size=(n, time_steps, input_dim)) #标准正态分布随机特征值
y = np.random.randint(low=0, high=2, size=(n, 1)) #二分类,随机标签值
x[:, attention_column, :] = np.tile(y[:], (1, input_dim)) #将第attention_column列的值赋值为标签值
return x, y
在这里设置了步长为64的时间序列,把第10步赋值为与标签列相同
n = 60000 #样本数
time_stpes = 64 #时序时长
input_dim = 1 #通道数
attention_column = 10 #把该行设置为与标签一致
x,y = get_data(n,time_stpes,input_dim) #生成数据
模型建立
attention层
attention模型本质上就是一个全连接层,计算输入序列各个时间点的权重,并和输入按位相乘作为新的输入。训练完成后,可以把它看成一个自控里的能观器吧,可以读取这个权重得到注意力值,权重越高说明对输出的贡献越大。
def attention_3d_block(inputs,SINGLE_ATTENTION_VECTOR = False):
input_dim = int(inputs.shape[2]) # shape = (batch_size, time_steps, input_dim)
a = Permute((2, 1))(inputs) # shape = (batch_size, input_dim, time_steps)
a = Reshape((input_dim, time_stpes))(a) # this line is not useful. It's just to know which dimension is what.
a = tf.keras.layers.Dense(time_stpes, activation='softmax')(a)# 为了让输出的维数和时间序列数相同(这样才能生成各个时间点的注意力值)
a_probs = Permute((2, 1), name='attention_vec')(a) # shape = (batch_size, time_steps, input_dim)
output_attention_mul = Multiply()([inputs, a_probs]) #把注意力值和输入按位相乘,权重乘以输入
return output_attention_mul
定义模型
def model_attention_applied_before_lstm(inputs):
attention_mul = attention_3d_block(inputs)
attention_mul = LSTM(32, return_sequences=False)(attention_mul)
outputs = Dense(1, activation='sigmoid')(attention_mul)
return outputs
input_data = Input(shape=(time_stpes,input_dim))
label_data = model_attention_applied_before_lstm(input_data)
model = Model(input_data,label_data)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
from tensorflow.keras.utils import plot_model
plot_model(model, to_file='.\model.png') #保存模型结构图片
模型结构图
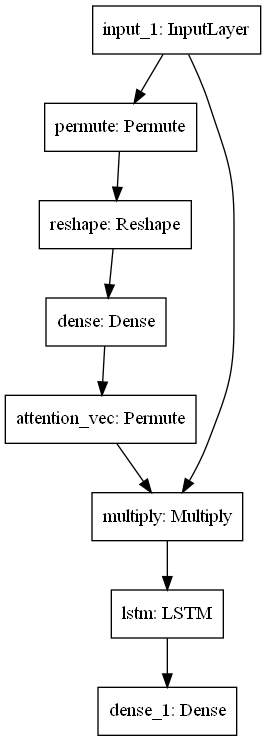
模型训练
用tensorboard记录训练数据,开始训练
hist = tf.keras.callbacks.TensorBoard(log_dir = './hist',histogram_freq = 0 , write_graph = True,write_images = True)
model.fit(x,y,batch_size = 256,epochs=20,validation_split=0.1,verbose=2,callbacks = [hist])
训练效果,
Epoch 1/20 211/211 - 7s - loss: 0.6932 - accuracy: 0.5004 - val_loss: 0.6930 - val_accuracy: 0.5027
Epoch 2/20 211/211 - 6s - loss: 0.6352 - accuracy: 0.6069 - val_loss: 0.4977 - val_accuracy: 0.7533
Epoch 3/20 211/211 - 6s - loss: 0.3382 - accuracy: 0.8504 - val_loss: 0.2163 - val_accuracy: 0.9142
Epoch 4/20 211/211 - 6s - loss: 0.1476 - accuracy: 0.9439 - val_loss: 0.1129 - val_accuracy: 0.9592
Epoch 5/20 211/211 - 6s - loss: 0.0753 - accuracy: 0.9731 - val_loss: 0.0662 - val_accuracy: 0.9743
Epoch 6/20 211/211 - 6s - loss: 0.0405 - accuracy: 0.9861 - val_loss: 0.0502 - val_accuracy: 0.9822
Epoch 7/20 211/211 - 6s - loss: 0.0231 - accuracy: 0.9926 - val_loss: 0.0378 - val_accuracy: 0.9868
Epoch 8/20 211/211 - 6s - loss: 0.0129 - accuracy: 0.9960 - val_loss: 0.0291 - val_accuracy: 0.9903
Epoch 9/20 211/211 - 6s - loss: 0.0078 - accuracy: 0.9979 - val_loss: 0.0228 - val_accuracy: 0.9923
Epoch 10/20 211/211 - 6s - loss: 0.0044 - accuracy: 0.9988 - val_loss: 0.0229 - val_accuracy: 0.9928
Epoch 11/20 211/211 - 6s - loss: 0.0034 - accuracy: 0.9991 - val_loss: 0.0197 - val_accuracy: 0.9938
Epoch 12/20 211/211 - 6s - loss: 0.0049 - accuracy: 0.9984 - val_loss: 0.0113 - val_accuracy: 0.9958
Epoch 13/20 211/211 - 6s - loss: 8.9616e-04 - accuracy: 0.9998 - val_loss: 0.0105 - val_accuracy: 0.9965
Epoch 14/20 211/211 - 6s - loss: 4.5989e-04 - accuracy: 0.9999 - val_loss: 0.0111 - val_accuracy: 0.9968
Epoch 15/20 211/211 - 6s - loss: 1.8766e-04 - accuracy: 1.0000 - val_loss: 0.0108 - val_accuracy: 0.9970
Epoch 16/20 211/211 - 6s - loss: 1.2927e-04 - accuracy: 1.0000 - val_loss: 0.0114 - val_accuracy: 0.9967
Epoch 17/20 211/211 - 6s - loss: 8.2761e-05 - accuracy: 1.0000 - val_loss: 0.0111 - val_accuracy: 0.9968
Epoch 18/20 211/211 - 6s - loss: 6.1741e-05 - accuracy: 1.0000 - val_loss: 0.0118 - val_accuracy: 0.9967
Epoch 19/20 211/211 - 6s - loss: 5.4057e-05 - accuracy: 1.0000 - val_loss: 0.0114 - val_accuracy: 0.9968
Epoch 20/20 211/211 - 6s - loss: 4.0670e-05 - accuracy: 1.0000 - val_loss: 0.0112 - val_accuracy: 0.9970
<tensorflow.python.keras.callbacks.History at 0x211f52ffbb0>
读取注意力值(权重值)
tf.keras想输出中间层(隐藏层)的输出,就需要新建一个模型
activate_output_modle = Model(inputs = model.input,outputs = model.get_layer('attention_vec').output) #新建一个从注意力层直接输出的模型,用于输出注意力的值
activate_value = np.zeros([1,time_stpes,input_dim])
每次生成一组新数据输入到新建的activate_output_modle模型中,得到输出的注意力值,循环1000次并取平均
test_items = 1000
for i in range(test_items):
testing_inputs_1, testing_outputs_1 = get_data(1, time_stpes, input_dim)
activate_output = activate_output_modle.predict(testing_inputs_1)
activate_value = activate_output + activate_value
activate_value = activate_value/test_items
得到的注意力值如图所示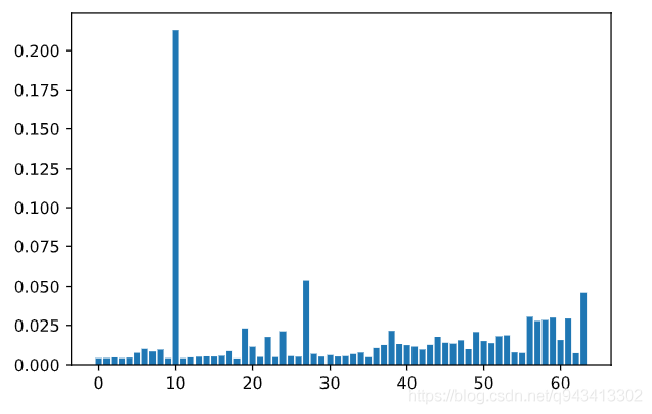
显然,注意力层已经学习到了10这步时间点的重要性了
版权声明:本文为q943413302原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。