异常点检测概述
这里常说的异常点,目前并没有具体的严格定义,大多数来讲,检测异常点都是按照数据分布与业务逻辑结合进行主观判断是否属于异常点。关注金科应用研院,回复“CSDN”,领取风控资料合集。更多关于量化风险管理、贷前策略、贷中管理、额度授信、定价等信息,请关注金科应用研院。
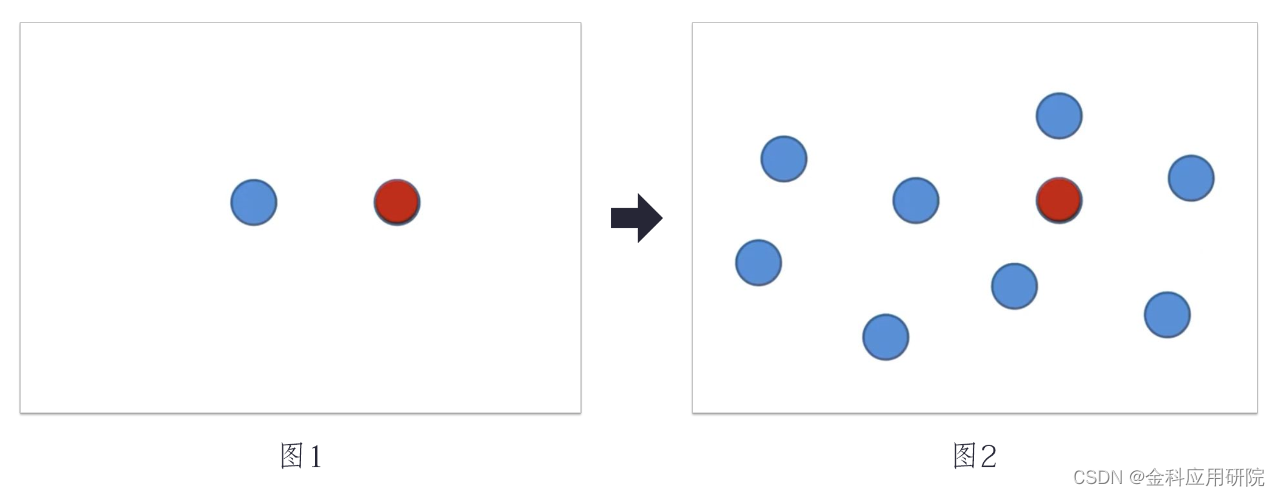
举一个例子,例如我们无法直接区分出图1中的蓝点和红点,哪一个点是异常点。但把它们放在图2的数据环境里面后,只有一个点是红色,其余的点都是蓝色,那么根据数据分布的规则,就能判断出的红点是一个异常点。
所以,数据集汇总的异常数据通常被认为是异常点、离群点或孤立点,特点是这些数据的特征与大多数数据不一致,呈现出"异常"的特点,检测这些数据的方法称为异常检测。识别如信用卡欺诈,工业生产异常,网络流里的异常(网络侵入)等问题,针对的是少数的事件。
异常点检测的应用
异常值/离群值检测的应用比较广泛,例如:
欺诈检测,即检测信用卡或电话卡的欺诈性事件;
贷款申请处理,检测欺诈性申请或潜在问题客户;
入侵检测,检测计算机网络中未经授权的访问;
活动监视,通过监视电话活动或股票市场中的可疑交易来检测手机欺诈;
网络性能,监视计算机网络的性能,例如检测网络瓶颈;
故障诊断,检测例如航天飞机上的电动机、发电机、管道或太空仪器中的故障;
结构缺陷检测,检测生产线中的缺陷瑕疵;
卫星图像分析,识别新颖特征或分类错误的特征;
检测图像中的新颖性,用于机器人整形或监视系统;
运动分割,检测独立于背景移动的图像特征;
时间序列监视,监视安全关键应用,例如钻孔或高速铣削;
医疗状况监控,例如心率监控器;
药物研究,确定新的分子结构;
检测文本中的新颖性,检测新闻事件的出现,进行主题检测和跟踪,或让交易者查明股票、商品、外汇交易事件,表现出色或表现不佳的商品;
检测数据库中的意外记录,用于数据挖掘以检测错误、欺诈或有效但异常的记录;
在训练数据集中检测标签错误的数据。
异常点检测算法使用场景
什么时候我们需要异常点检测算法呢?常见的有三种情况。
- 做数据预处理的时候需要对异常的数据做过滤,防止对归一化等处理的结果产生影响; 对没有标记输出的特征数据做筛选,找出异常的数据;
对有标记输出的特征数据做二分类时,由于某些类别的训练样本非常少,类别严重不平衡,此时也可以考虑做异常点检测。
检测异常点的方式
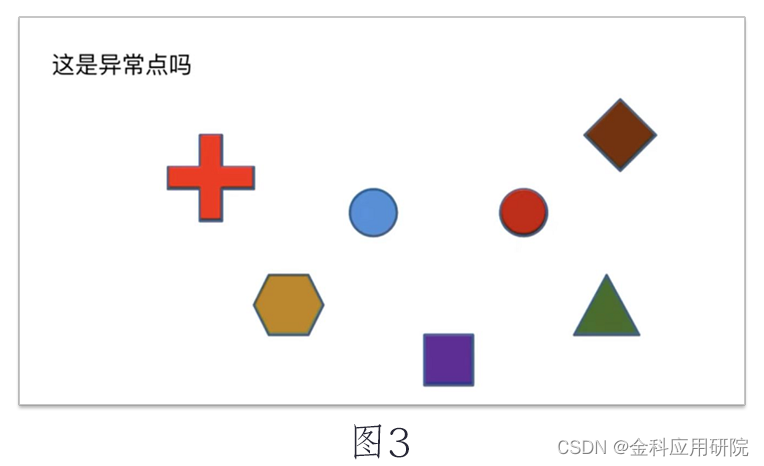
如果整体的数据环境变成图3,你还会认为红点是一个异常点吗?很明显不会,因为图3的每个点都都是由奇奇怪怪的形状构成的,反而是蓝点和红点都是圆形,那么我们极有可能会认为蓝点和红点是同一类别下的数据。
所以这时候数据的异常链检测,除了根据数据单个点的本身之外,还需要根据本身的数据环境与业务逻辑进行判断。我认为检测异常点,一定是从数据角度和业务角度两方面相结合,并且需要做大量的数据分析对其进行分类和总结,提取最有价值的信息,最终有效判断异常点。
如何从数据角度把异常点找出来,这里我给大家推荐一个我认为比较好的检测异常点方法:孤立森林 Isolation Forest(iForest)
孤立森林是用于异常检测的机器学习算法。这是一种无监督学习算法,巧妙的利用决策树分裂来寻找离群样本,通过隔离数据中的离群值识别异常,因为异常点和大多数的正常样本差距较大所以会被孤立出来。
孤立森林的算法公式:

孤立森林的代码示例:
数据集为同一个商品在不同商店的价格,共20个数据,看看其中哪些商品存在异常值。

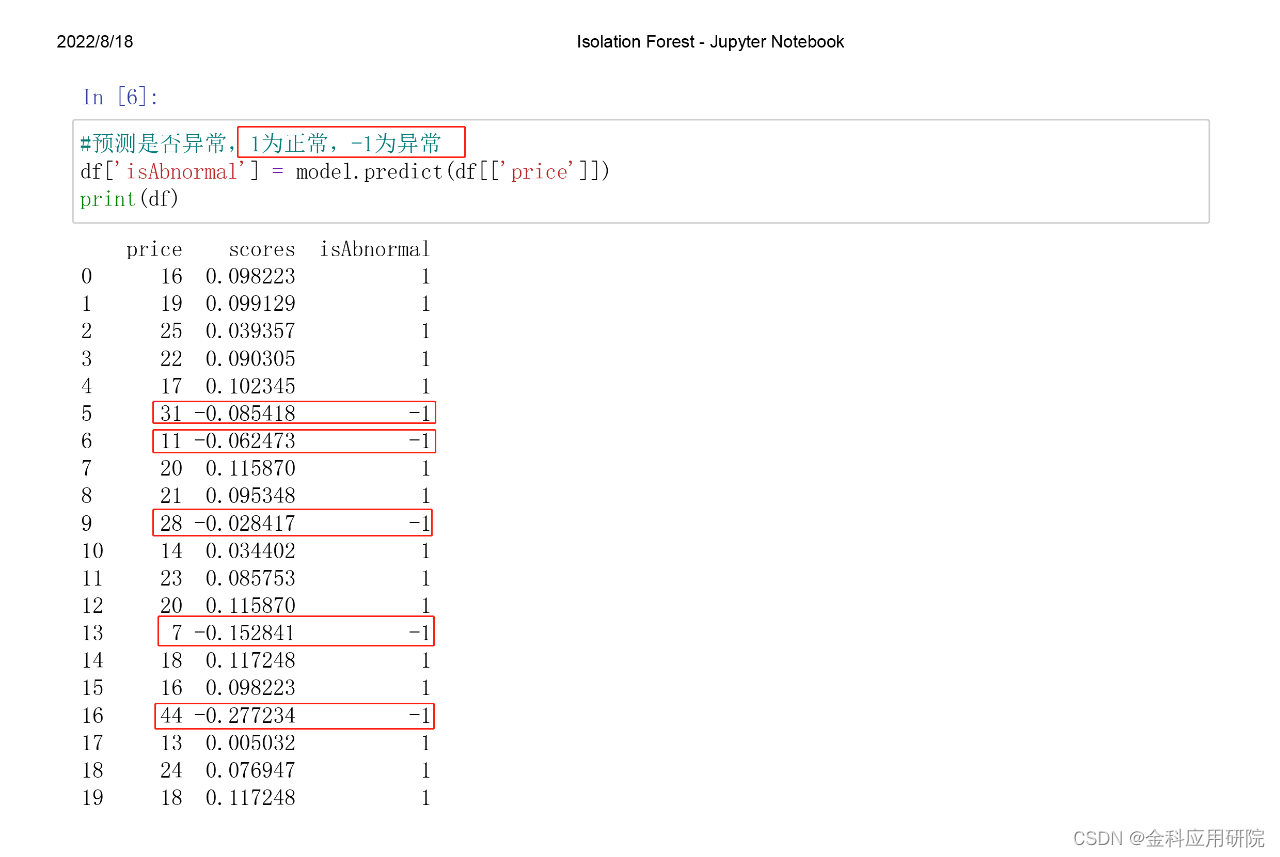
我们可以看到,发现了5个异常的数据。
孤立森林算法的有点在于海量数据处理的高效性,具有内存占用少、计算速度快的优势。同时,其参数数量少,因此易用性很强。
但是其适用条件苛刻,异常点少且需要特征明显,而且不适合高维数据。
