1. 混淆矩阵
对于二分类模型,预测值与真实值的组合情况,行成了混淆矩阵。
第一个字母表示是否预测正确(T/F),第二个表示预测为 P/1 还是 N/0。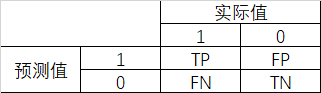
2. 准确率
预测正确的结果占总样本的百分比,准确率=(TP+TN)/(TP+TN+FP+FN)
样本不平衡时,该指标失效。
3. 精准率
Precision,也即查准率,在所有被预测为正的样本中实际为正样本的概率,精准率=TP/(TP+FP)
4. 召回率
Recall,也即查全率,在实际为正的样本中被预测为正样本的概率,查全率=TP/(TP+FN)
5. P-R曲线,F1 score,Fβ score
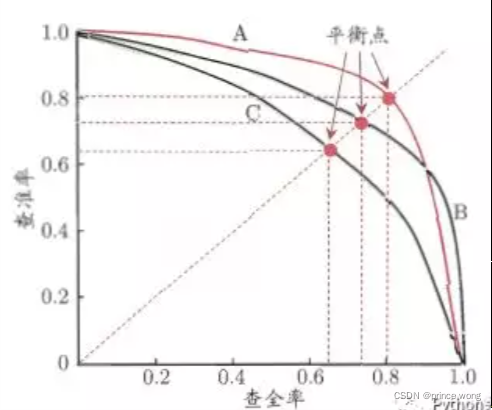
拿逻辑回归为例,用一个阈值去与回归概率相比来确定输出结果为0或者1,那么事前我们不知道这个阈值是否恰当,每一个阈值都对应一对Recall和Precision,通过遍历0-1之间所有阈值,我们就得到了P-R曲线。因为P与R是对立矛盾的,根据业务场景,需要P高,就要牺牲一些R,反之亦然。如果要兼顾,我们就定义了F1 score,F1 = 2PR/(P+R)。
升级版或者说一般来讲,Fβ score,Fβ=(1+β2)PR/(β2P+R)
可以看出,F1其实就是β等于1时的特例,通常使用的有F0.5,F2,F2:召回率权重大于精确率。
6. ROC/AUC
6.1 真正率,假正率,灵敏度,特异度
○ 真正率(TPR) = 灵敏度 = TP/(TP+FN) = 召回率
---实际为正样本,预测正确,预测为正样本的比率
○ 假正率(FPR)= 1- 特异度 = FP/(FP+TN)
---实际为负样本,预测错误,预测成正样本的比率
○ 灵敏度(Sensitivity) = TP/(TP+FN)
○ 特异度(Specificity) = TN/(FP+TN)
---实际为负样本,预测正确的比率
TPR和FPR分别是从实际的正样本和负样本的角度来观察相关概率的。因此,这哥俩可以无视样本是否均衡。
6.2 ROC(Receiver Operating Characteristic)
ROC,接受者操作特征曲线,主要两个指标就是真正率和假正率,横坐标为假正率(FPR),纵坐标为真正率(TPR)。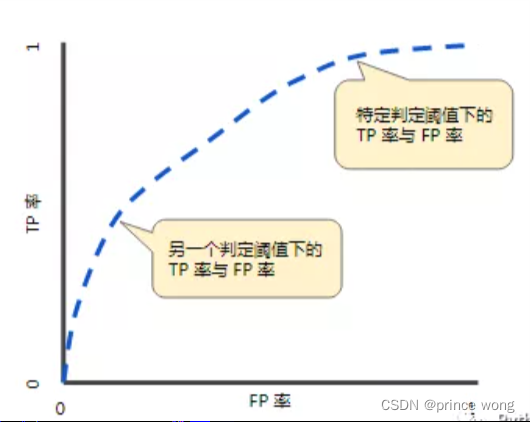
与前面P-R曲线类似,也是通过遍历阈值来形成ROC曲线。
FPR表示虚报,TPR表示正确响应,我们一般希望TPR大,FPR小。
这就引出了AUC的概念,Area Under Curve,即ROC曲线下面积,随机判断是否响应,正负样本覆盖都是50%,那么曲线下面积为0.5,此时为直线,也即baseline。AUC理想值为1,正方形,一般AUC介于0.5-1之间。
○ 0.5 - 0.7:效果较差
○ 0.7 - 0.85:效果一般
○ 0.85 - 0.95:效果很好
○ 0.95 - 1:效果非常好,不太可能
7. 代码实现
from sklearn import metrics
import numpy as np
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
metrics.auc(fpr, tpr)
metrics.roc_auc_score(y, scores)
如有错误,欢迎指正。