前言
这篇文章主要围绕SQL语言中最常用的检索数据SELECT语句来讲。
正文
1. SELECT * FROM data_table; -->FROM子句
FROM 声明检索数据的数据源,就是数据表.
SELECT 关键字,后面跟要检索的列名,*代表 所有列,列数可以一个,也可以多个.多个列以逗号分隔,最后一个列名后不要有逗号.
2. 去重,注释和限制结果行数
DISTINCT 放在列名前面,对所有列有效.
# 行内注释,/* */ 多行注释
在MYSQL中限制结果列数用LIMIT
eg:
SELECT DISTINCT prod_name, prod_id
FROM products
LIMIT 10;
3. 排序和排序方向
ORDER BY column1 根据某列排序,也可以根据多行排序,先按第一个,第一个相同再通过第二个排序.
ORDER BY 默认是升序,通过DESC语句可实现降序排序, 这里有一点需要注意,DESC和DISTINCT不一样,它只能作用到直接位于它前边的列名,想要在多个列上降序,需要对每一列指定DESC
ORDER BY 要写在语句的最后,紧贴;,但更重要的一点是,ORDER BY排序操作是所有操作中最后执行的,是对结果的数据集合进行操作的,现在可能感觉不到这一点,后文会提到.
ORDER BY 排序列中存在 NULL 时,指定其出现在首行或者末行的方式.
4. 过滤数据的WHERE子句
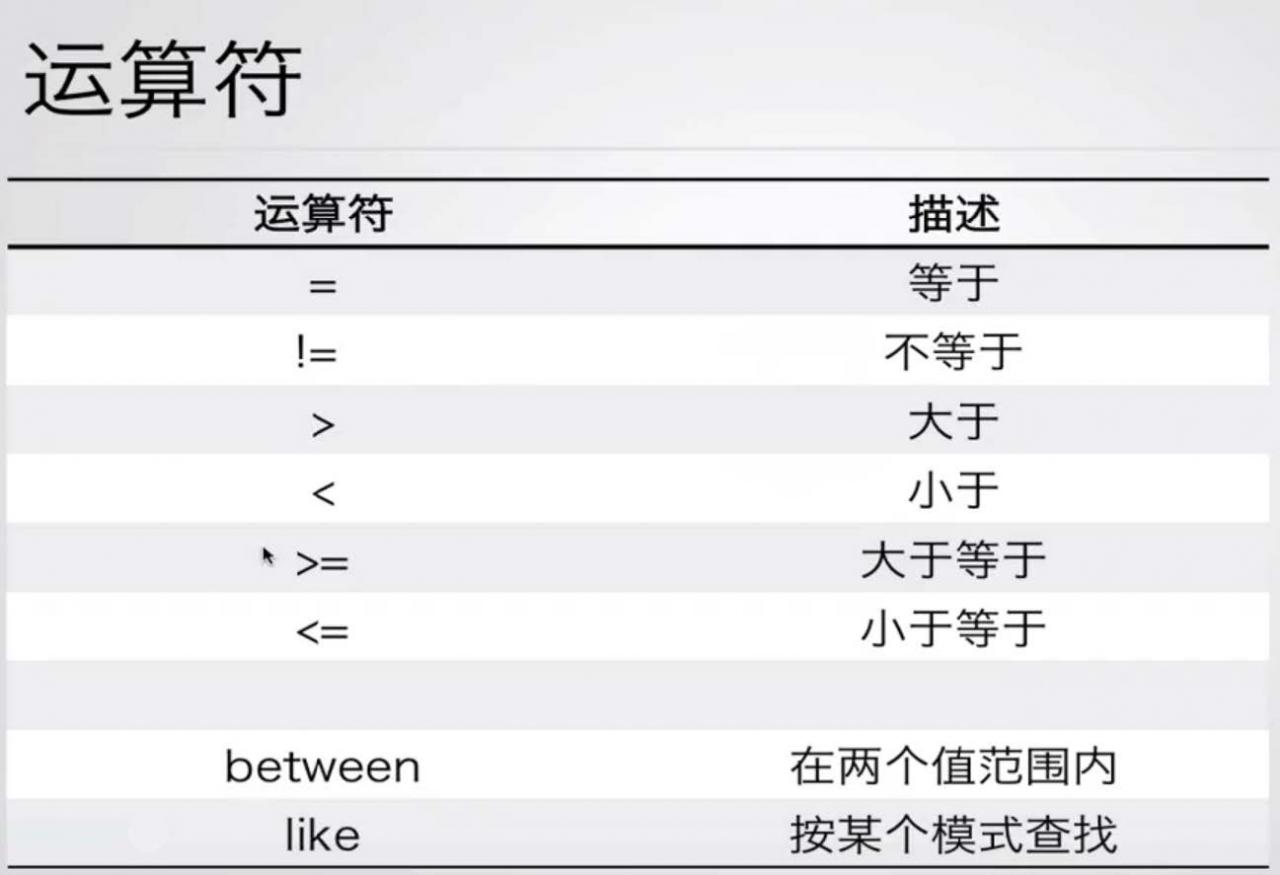
WHERE子句内设定过滤条件,提取出表数据的一个子集.以下为可选的子句操作符
(1) 子句运算符:
四则运算符:
| 含义 | 运算符 |
|---|---|
| 加法 | + |
| 减法 | - |
| 乘法 | * |
| 除法 | / |
(2) NULL值的判断 is / is not
select * from [表名] where 字段名 运算符 is null
select * from [表名] where 字段名 运算符 is not null
(3) 组合条件 AND OR NOT ()
AND,NOT,OR含义不用解释了,AND比OR优先级高,用圆括号确定优先级.消除歧义
SELECT prod_name,prod_price,quantity
FROM products
WHERE prod_price <= 100 AND quantity >= 1000;
(4) IN操作符
指定条件范围,范围内的每个条件都可以匹配,IN操作符 可以实现SELECT语句的嵌套,后文会讲.
(5) LIKE操作符和通配符
利用通配符搜索文本字段(字符串),字符串的模糊匹配
%通配符 表示任何字符出现任意多次数.
select * from [表名] where [列名] like pattern;
select * from [表名] where [列名] not like pattern;
pattern ; 匹配模式 , 比如 ‘abc' '%abc' 'abc%' '%abc%' 单引号一定要加
# 查找以'Fish'开头的产品
SELECT prod_id, prod_name
FROM products
WHERE prod_name LIKE 'Fish%';
关于区分大小写 windows是不区分大小写的,而linux是区分大小写的.
_下划线通配符 只能匹配单个字符
关于通配符要注意,通配符搜索要耗费更长的时间,不要过度使用通配符,有其他的能够完成用其他的最好.
5. 计算字段和别名
字段,基本与列的意思相同,这里的计算字段,多指通过计算或其他方式得到的列
(1)拼接得到
MYSQL需要使用Concat 函数,关于函数后边会介绍.
eg:
SELECT Concat(vend_name,' (', vend_country,')')
FROM vendors
ORDER BY vend_name;
(2)算术计算得到
对检索出的数据进行算术计算,支持基本的加减乘除,圆括号同样可以区分运算顺序.
SELECT prod_id, quantity, item_price
FROM orderitems
WHERE order_num = 20008;
起别名
SQL支持起别名,这里的计算字段的结果没有名字,只是一个值.但是,一个未命名的列不能用于客户端应用中,因为客户端没有办法引用它.
别名用关键字 AS 赋予.
起别名的用处不仅仅用于计算字段,还有对列名和表名,更大的用处是为了后续操作执行的方便,比如自联结处,后续会讲.
eg:
SELECT prod_id, quantity, item_price, quantity*item_price AS total_price
FROM orderitems
6. SQL函数(MYSQL)
sql 自带了各种各样的函数,极大提高了 sql 语言的便利性。
所谓函数,类似一个黑盒子,你给它一个输入值,它便按照预设的程序定义给出返回值,输入值称为参数。
函数大致分为如下几类:
- 算术函数 (用来进行数值计算的函数)
- 字符串函数 (用来进行字符串操作的函数)
- 日期函数 (用来进行日期操作的函数)
- 转换函数 (用来转换数据类型和值的函数)
- 聚集函数 (用来进行数据聚合的函数,后文提)
函数总个数超过200个,不需要完全记住,常用函数有 30~50 个,其他不常用的函数使用时查阅文档即可。
(1)算术函数
+ - * /- ABS () 绝对值
- MOD – 求余数
- ROUND – 四舍五入
(2) 字符串函数
- CONCAT – 拼接
语法:CONCAT(str1, str2, str3)
MySQL中使用 CONCAT 函数进行拼接。
- LENGTH – 字符串长度
语法:LENGTH( 字符串 )
- LOWER – 小写转换
LOWER 函数只能针对英文字母使用,它会将参数中的字符串全都转换为小写。该函数不适用于 英文字母以外的场合,不影响原本就是小写的字符。
类似的, UPPER 函数用于大写转换。
- REPLACE – 字符串的替换
语法:REPLACE( 对象字符串,替换前的字符串,替换后的字符串 )
- SUBSTRING – 字符串的截取
语法:SUBSTRING (对象字符串 FROM 截取的起始位置 FOR 截取的字符数)
使用 SUBSTRING 函数 可以截取出字符串中的一部分字符串。截取的起始位置从字符串最左侧 开始计算,索引值起始为1。
(3) 日期函数
因DBMS而易.
- CURRENT_DATE – 获取当前日期
SELECT CURRENT_DATE;
+--------------+
| CURRENT_DATE |
+--------------+
| 2020-08-08 |
+--------------+
1 row in set (0.00 sec)
- CURRENT_TIME – 当前时间
SELECT CURRENT_TIME;
+--------------+
| CURRENT_TIME |
+--------------+
| 17:26:09 |
+--------------+
1 row in set (0.00 sec)
- CURRENT_TIMESTAMP – 当前日期和时间
SELECT CURRENT_TIMESTAMP;
+---------------------+
| CURRENT_TIMESTAMP |
+---------------------+
| 2020-08-08 17:27:07 |
+---------------------+
1 row in set (0.00 sec)
- EXTRACT – 截取日期元素
语法:EXTRACT(日期元素 FROM 日期)
使用 EXTRACT 函数可以截取出日期数据中的一部分,例如“年” “月”,或者“小时”“秒”等。该函数的 返回值并不是日期类型而是数值类型
(4) 转换函数
“转换”这个词的含义非常广泛,在 SQL 中主要有两层意思:一是数据类型的转换,简称为类型转换,在英语中称为cast;另一层意思是值的转换。
- CAST – 类型转换
语法:CAST(转换前的值 AS 想要转换的数据类型)
-- 将字符串类型转换为数值类型
SELECT CAST('0001' AS SIGNED INTEGER) AS int_col;
+---------+
| int_col |
+---------+
| 1 |
+---------+
1 row in set (0.00 sec)
-- 将字符串类型转换为日期类型
SELECT CAST('2009-12-14' AS DATE) AS date_col;
+------------+
| date_col |
+------------+
| 2009-12-14 |
+------------+
1 row in set (0.00 sec)
- COALESCE – 将NULL转换为其他值
语法:COALESCE(数据1,数据2,数据3……)
COALESCE 是 SQL 特有的函数。该函数会返回可变参数 A 中左侧开始第 1个不是NULL的值。参数个数是可变的,因此可以根据需要无限增加。
在 SQL 语句中将 NULL 转换为其他值时就会用到转换函数。
(4) CASE 表达式
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
.
.
.
ELSE <表达式>
END ## 不能省略!!!
用法1: 根据不同分支得到不同列值
SELECT product_name,
CASE WHEN product_type = '衣服' THEN '1'
WHEN product_type = '办公用品' THEN '2'
WHEN product_type = '厨房用具' THEN '3'
ELSE NULL
END AS product_ww
FROM product;
用法2: 行转列
-- CASE WHEN 实现数字列 score 行转列
SELECT name,
SUM(CASE WHEN subject = '语文' THEN score ELSE null END) as chinese,
SUM(CASE WHEN subject = '数学' THEN score ELSE null END) as math,
SUM(CASE WHEN subject = '外语' THEN score ELSE null END) as english
FROM score
GROUP BY name;
+------+---------+------+---------+
| name | chinese | math | english |
+------+---------+------+---------+
| 张三 | 93 | 88 | 91 |
| 李四 | 87 | 90 | 77 |
+------+---------+------+---------+
2 rows in set (0.00 sec)
7. 用来汇总数据的聚集函数
在实际查询中,我们往往需要汇总数据,而不用把它们实际检索出来,所以SQL提供了聚集函数.
聚集函数是对列操作的 , 有以下几个:
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值(忽略NULL) |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值(忽略NULL) |
| MIN() | 返回某列的最小值(忽略NULL) |
| SUM() | 返回某列值之和(忽略NULL) |
COUNT(*) 不忽略NULL,COUNT(column)指定列忽略NULL
在聚集函数的参数中使用DISTINCT,可以删除重复数据。
SELECT COUNT(*) AS num_items,
MIN(prod_price) AS price_min,
MAX(prod_price) AS price_max,
AVG(prod_price) AS price_avg
FROM products;
8. 分组数据
分组是用SELECT语句的GROUP BY 子句建立的.WHERE是将数据表过滤产生一个子集,而GROUP BY是通过某一列产生多个逻辑组(集合),每个组有共同的特征,数量不定,GROUP BY 必须出现在WHERE子句之后,ORDER BY 子句之前.
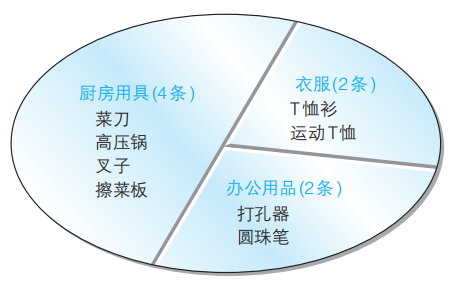
就像这样,GROUP BY 子句就像切蛋糕那样将表进行了分组.注意,分组条件中有NULL,NULL会作为一组特殊数据进行处理.
eg:
SELECT vend_id, COUNT(*) AS num_prods
FROM products
GROUP BY vend_id;
HAVING 根据过滤分组, WHERE过滤指定的行.HAVING 在数据分组后进行过滤, WHERE在数据分组前过滤的.
显然而且理所当然的一点是,GROUP BY根据某列,聚合函数分的组,HAVING过滤组时自然也要根据分组条件去过滤分组.
eg:
-- 数字
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type
HAVING COUNT(*) = 2;
-- 错误形式(因为product_name不包含在GROUP BY聚合键中)
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type
HAVING product_name = '圆珠笔';
9. SELECT 子句的语法顺序和执行顺序(灰常重要)
语法顺序(严格)
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
执行顺序(记在心中)
FROM 确定数据源
WHERE 过滤行
GROUP BY 分组
HAVING 过滤分组
SELECT 去不检索的列
ORDER BY 排序
注意一点,汇集函数不固定环节,只要掌握好执行函数就能处理好汇集函数和分组易出的问题.
eg:
USE course;
SELECT order_num, SUM(item_price*quantity) AS total
FROM orderitems
GROUP BY order_num
HAVING SUM(item_price*quantity) >= 1000
ORDER BY total;
这个例子里的SELECT处起了别名total,HAVING不能使用这个别名,而ORDER BY能够使用这个别名,其原因就是来自于执行顺序.
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY。
别名问题 这里在SELECT 时起的别名,比它执行早的不能用,晚的能够用.FROM 同理.
10. 子查询 – 查询的嵌套
每次SELECT 语句检索后返回的都是一个数据表,同样这个数据表也可以作为另一个SELECT语句的数据源.用到IN操作符.
eg:
SELECT cust_id
FROM orders
WHERE order_num IN (SELECT order_num
FROM orderitems
WHERE prod_id = 'RGAN01')
子查询总是从内到外处理.由于IN操作符的缘故(猜测),作为子查询的SELECT语句只能查询单个列.
子查询也可以作为计算字段
eg:
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM orders
WHERE orders.cust_id = customers.cust_id) AS orders
FROM customers
ORDER BY cust_name;
这里出现的需要完全限定列名,原因来自处理多个数据表时,多个表有相同的一列名,需要区分,避免歧义,所以要完全限定列名,这一点在后文的联结表现得更为明显.
eg:
USE course;
SELECT cust_id, (SELECT SUM(item_price*quantity)
FROM orderitems
WHERE orders.order_num = orderitems.order_num) AS total_ordered
FROM orders
ORDER BY total_ordered DESC;
11. 联结表(本质笛卡儿积)
相信大家看到这里已经有些累了或者早走了,我写的确实并没有那么通俗易懂,主要是作为资料以后遗忘查阅.
联结表是SQL最强大的功能之一
前一篇文章提到过,相同数据在一个出现多次绝不是好事.根据关系数据库设计的三大范式,往往会出现关系表,一类数据一个表,各个表通过某些共同的值相互关联.
所以SQL必定必须提供多数据表联结查询,就是联结表
(1) 内联结
SELECT vend_name, prod_name, prod_price
FROM vendors, products
WHERE vendors.vend_id = products.vend_id;
SELECT vend_name, prod_name, prod_price
FROM vendors
INNER JOIN products ON vendors.vend_id = products.vend_id;
这里又用到了完全限定列名,这里的vendors和products都有一列叫做vend_id,必须要区分.
FROM 这里有两个数据表作为数据源,其实是两个表做笛卡尔积,出现n*m行数据,然后通过WHERE过滤一定的行.
两种不同的写法都可以.
不要联结不必要的表,联结的表越多,性能下降越厉害.要明确联结表之间哪些是相同的,要完全限定
eg:
SELECT cust_name, orders.order_num, SUM(quantity*item_price) AS ordertotal
FROM customers, orders, orderitems
WHERE customers.cust_id = orders.cust_id
AND orders.order_num = orderitems.order_num
GROUP BY cust_name, orders.order_num
ORDER BY cust_name, order_num;
SELECT SP.shop_id
,SP.shop_name
,SP.product_id
,P.product_name
,P.product_type
,P.sale_price
,SP.quantity
FROM ShopProduct AS SP
INNER JOIN Product AS P
ON SP.product_id = P.product_id;
(2) 自联结
这个其实就是通过对表名起别名来,自己和自己联结(做笛卡尔积)
SELECT c1.cust_id, c1.cust_name, c1.cust_contact
FROM customers AS c1, customers AS c2
WHERE c1.cust_name = c2.cust_name
AND c2.cust_contact = 'jim jones';
(3) 自然联结
无论何时对表进行联结,应该至少有一列不止出现在一个表中(被联结的列).标准的联结返回所有数据,相同的列甚至多次出现,自然联结排除多次出现,使每一列只返回一次.通过对一个表使用通配符(SELECT *),而对其他表的列使用明确的子集来完成.
SELECT C.*, O.order_num, O.order_date,
OI.prod_id, OI.quantity, OI.item_price
FROM customers AS C, orders AS O,
orderitems AS OI
WHERE C.cust_id = O.cust_id
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01';
或者
SELECT * FROM shopproduct NATURAL JOIN Product
(4) 外联结
外联结包含了那些相关表中没有关联行的行;
譬如,一个表存顾客,一个表存订单,并不是所有的顾客有订单,也不是顾客只有一个订单,可能有多个,统计每个顾客的订单个数.
若使用内联结会使没有订单的顾客给过滤掉,外联结则不会.
SELECT customers.cust_id,
COUNT(orders.order_num) AS num_ord
FROM customers
LEFT OUTER JOIN orders ON customers.cust_id = orders.cust_id
GROUP BY customers.cust_id;
eg:
SELECT cust_name, COUNT(order_num) AS order_sum
FROM orders,customers
WHERE orders.cust_id = customers.cust_id
GROUP BY customers.cust_id;
# 对比 外联结
SELECT cust_name, COUNT(order_num) AS order_sum
FROM customers
LEFT OUTER JOIN orders ON orders.cust_id = customers.cust_id
GROUP BY customers.cust_id;
这个例子可以执行一下,可以明显看出外联结和内联结的不同.
12. 组合查询(集合并集)
通过UNION使多个SELECT语句查询的结果合并成一个结果集返回,要求每个查询必须包含相同的列,表达式或聚集函数.列的数据类型必须兼容.
eg:
SELECT cust_name, cust_contact, cust_email
FROM customers
WHERE cust_state IN ('IL','IN','MI')
UNION
SELECT cust_name, cust_contact, cust_email
FROM customers
WHERE cust_name = 'Fun4All';
关于集合交集等MYSQL并不支持 … …
13. 视图
视图是虚拟的表,它包含的不是数据而是更具需要检索数据的查询(SELECT语句),建立在真实表基础之上.视图提供了一种封装SELECT语句的层次,用来简化数据处理,重新格式化或保护基础数据,
视图将频繁使用的基础操作(只把表中需要的字段检索出来,降低数据冗余)封装起来多次调用,提高效率(毕竟子查询好麻烦~~)
通过定义视图可以不对外公开数据表全部字段,增强数据的保密性.
创建
CREATE VIEW <视图名>
AS <SELECT 语句(不能排序)>
删除
DROP VIEW <视图名>
注意: 视图本身不包含数据,因此返回的数据是从其他表中检索出来的.在添加或更改这些表中的数据时,视图将返回改变的数据.
总结
无论如何使用SELECT检索语句和如何设计数据库表,只要能够满足查询效率,可维护性和健壮性,满足 需求 就行.
SELECT语句博大精深,我好累啊,学了一天了,886~~