激活函数
目前自己使用比较多的激活函数RELU, RELU6; LeakyReLU; SELU; Mish
;激活函数看:计算量;准确率;
大多数激活函数pytorch里有已经包装好了:
Non-linear Activations (weighted sum, nonlinearity)
Non-linear Activations (other)[https://pytorch.org/docs/stable/nn.html](https://pytorch.org/docs/stable/nn.html)
经典的激活函数
1. Sigmoid
该函数是将取值为 (−∞,+∞) 的数映射到(0,1)之间。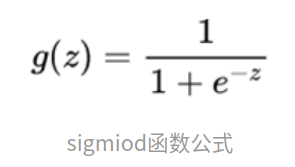
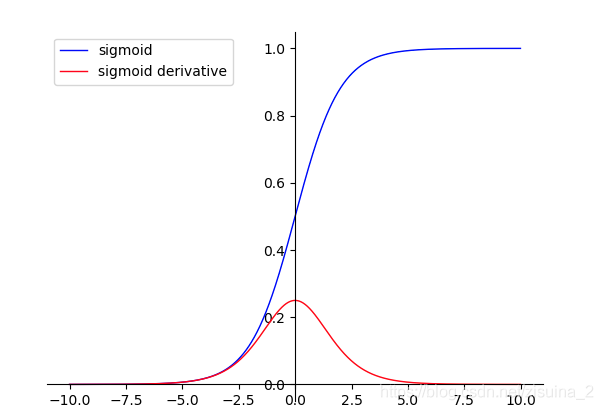
蓝色线是sigmoid函数;红色线是sigmoid的求导;
优点:平滑、易于求导。
缺点:
①梯度的消失;饱和区域变化的很慢,趋近于0
②输出的均值不为0,当输出大于0时,则梯度方向将大于0,也就是说接下来的反向运算中将会持续正向更新;
③幂函数还是比较难算的;计算量大
④Sigmoid函数并不是以(0,0)为中心点
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1.0/(1+np.exp(-x))
sigmoid_inputs = np.arange(-10,10,0.1)
sigmoid_outputs = sigmoid(sigmoid_inputs)
print("Sigmoid Function Input :: {}".format(sigmoid_inputs))
print("Sigmoid Function Output :: {}".format(sigmoid_outputs))
plt.plot(sigmoid_inputs,sigmoid_outputs)
plt.xlabel("Sigmoid Inputs")
plt.ylabel("Sigmoid Outputs")
plt.show()
2. tanh
tanh为双切正切曲线,过(0,0)点。相比Sigmoid函数,更倾向于用tanh函数;
公式为:
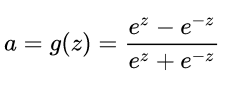
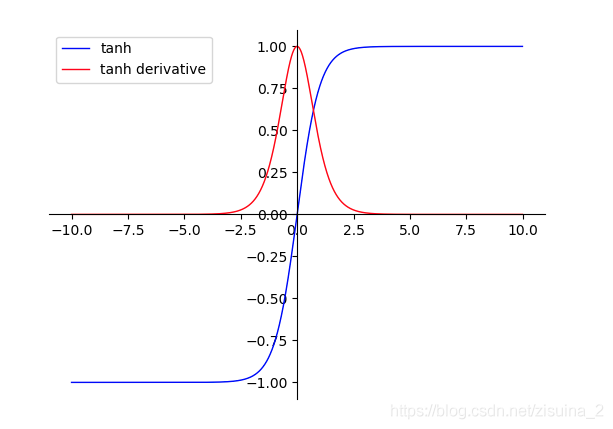
蓝色线是sigmoid函数;红色线是tahn的求导;
优点:
①函数输出以(0,0)为中心
②收敛速度相对于Sigmoid更快
缺点:
①梯度的消失;饱和区域变化的很慢,趋近于0;tanh并没有解决sigmoid梯度消失的问题
②幂函数还是比较难算的;计算量大
目前比较多的使用的
1. RELU && RELU6
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元;最近这几年很常用的激活函数。公式: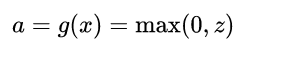
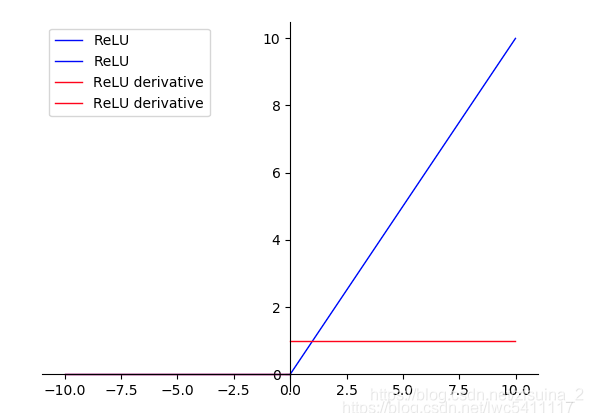
蓝色线是RELU函数;红色线是RELU的求导;如上图,是不是贼简单,AlexNet的论文对ReLu和普通Sigmoid系函数做的对比测试,可以看到,ReLu的使用,使得学习周期大大缩短。综合速率和效率,DL中大部分激活函数应该选择ReLu。
大大缩短。
优点:
- RELU中收敛速度要比Sigmoid和tanh快很多;计算量小啊,它不快谁快?
- 更加有效率的梯度下降以及反向传播:避免了梯度爆炸和梯度消失问题
- 对神经网络可以使用稀疏表达; 仿生物学原理:相关大脑方面的研究表明生物神经元的信息编码通常是比较分散及稀疏的(有兴趣再看吧(⊙o⊙))。
缺点:
- 在训练过程中容易出现神经元死亡,之后梯度永远为0的情况。在mobilenetv2系列中就分析了这玩意;
整体下来大家用了都说好!统治了很久的激活领域的top;
由relu为开始,PReLU,Leaky ReLU,CReLU等等各种变种相继登场;
relu6很好理解:
下图是relu6和relu之间的关系;主要是为了在移动端float16的低精度的时候,也能有很好的数值分辨率,如果对ReLu的输出值不加限制,那么输出范围就是0到正无穷,而低精度的float16无法精确描述其数值,带来精度损失。如果你是做移动端的,应该会很熟悉;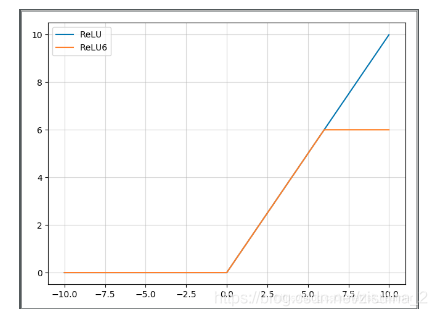
2.Mish
Mish: A Self Regularized Non-Monotonic Neural Activation Function
一种自正则的非单调神经激活函数,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。论文中提出,相比Swish有0.494%的提升,相比ReLU有1.671%的提升;该方法也在yolov4中得到了验证;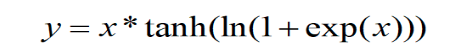
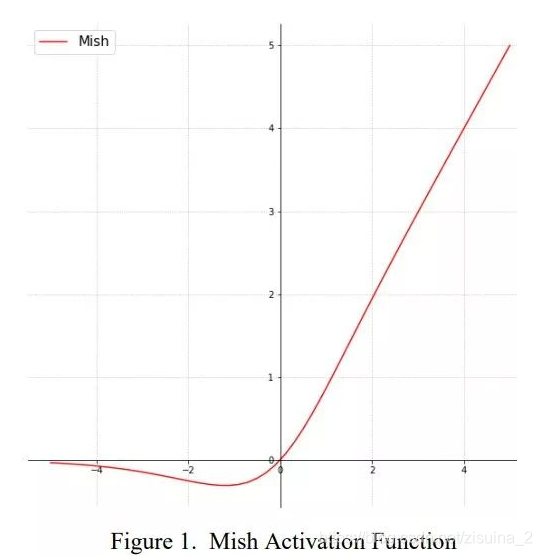
这个曲线好像完美的模拟了生物那方面的什么曲线;…
import torch
import torch.nn as nn
import torch.nn.functional as F
class Mish(nn.Module):
def __init__(self):
super().__init__()
print("Mish activation loaded...")
def forward(self,x):
x = x * (torch.tanh(F.softplus(x)))
return x
一开始没抱有太大希望,用了RELU6和MISH(自己目标检测的任务,非公开数据集)一对比;提升还是很明显的;博客也对MISH稳定性和精确度进行了多种任务的对比;整体下来,大多数任务都有了相应的提升;
| 激活函数 | RELU6 | MISH |
|---|---|---|
| coco得分 | 0.4976 | 0.5214 |
优点:
- 以上无边界(即正值可以达到任何高度)避免了由于封顶而导致的饱和。理论上对负值的轻微允许允许更好的梯度流,而不是像ReLU中那样的硬零边界。
- 平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
- 这个曲线好像完美的模拟了生物那方面的什么曲线; (有兴趣再看吧(⊙o⊙))。
缺点:
- 计算量肯定比relu大,占用的内存也多了不少;
3.Swish
(待验证,todo,写不动了)
Ohter
1. Leaky ReLU
公式: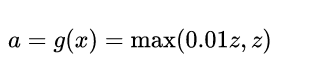
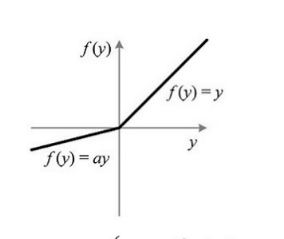
# 兄弟们,自己用吧
torch.nn.LeakyReLU(negative_slope: float = 0.01, inplace: bool = False)
SELU
(待验证,todo,写不动了)