1简介
1.1概述
大数据时代,数据的收集、处理、存储、分析、挖掘、检索、展示,环环相扣。其中数据处理环节是一个典型的批处理场景——定期对海量数据进行格式化,各种业务规范校验,复杂的业务逻辑处理,并通过事务的方式处理到自己的数据库中,同时还应该具备高效率,无人工干预能力。
Spring Batch的出现,很好的应对了该类需求。Spring Batch是一个轻量级的综合性批处理框架,可以应用于企业级大数据量处理系统。SpringBatch可以提供大量的,可重复的数据处理功能,包括日志/跟踪(tracing),事务管理,任务处理(processing)统计,任务重启,忽略(skip),和资源管理等功能。此外还提供了许多高级服务和特性,使之能够通过优化(optimization)和分片技术(partitioning techniques)来高效地执行超大型数据集的批处理任务。需要注意的是,Spring Batch并不提供定时之类的功能,那是quartz,Tivoli,Control-M等调度框架做的事情,它们是协作关系,而不是取代。
1.2背景
在微服务架构讨论的如火如荼之际,基于Java的批处理框架却无人问津。即使企业中一直都有批处理的需求,但因缺乏一个标准的、可重用的批处理框架,致使项目/产品中出现大量一次编写,一次使用的代码片段,以及很多其他不同的临时解决方案。
SpringSource和Accenture(埃森哲)联手协作,致力于改善这种状况。埃森哲在实现批处理架构上有着丰富的产业实践经验,SpringSource有深入的技术开发积累,背靠Spring框架提供的编程模型,强强联合,势必创造出高质量的、市场认可的企业级java解决方案——SpringBatch,基于埃森哲数十年宝贵的经验并基于最新的软件平台(如COBOL/Mainframe,C++/Unix 及现在非常流行的Java平台)来构建的项目。Spring Batch未来将会由开源社区提交者来驱动项目的开发、增强、以及未来的路线图。而埃森哲咨询公司与SpringSource合作的目标是促进软件处理方法、框架和工具的标准化改进。
1.3场景
典型的批处理流程是读数据、处理数据、写数据的三步式架构——从数据库、文件或队列中读取大量数据,然后通过业务规则处理数据,最后将处理完的数据按需求方式写(数据库、文件等)。通常Spring Batch工作在离线模式下,不需要用户干预、就能自动进行基本的批处理迭代,进行类似事务方式的处理。
1.3.1 适用业务
Ø 定期提交批处理任务(日终处理)
Ø 并发批处理:并行执行任务
Ø 分阶段,企业消息驱动处理
Ø 高并发批处理任务
Ø 失败后手动或定时重启
Ø 按顺序处理依赖任务 (使用工作流驱动的批处理插件)
Ø 局部处理:跳过记录(例如在回滚时)
Ø 完整的批处理事务:因为可能有小数据量的批处理或存在存储过程/脚本
1.3.2核心能力
Ø 利用Spring编程模式:使开发者专注于业务逻辑,让框架解决基础功能
Ø 明确划分在批处理基础架构、执行环境、应用
Ø 通用的核心服务以接口形式提供
Ø 提供简单的默认实现,以实现核心执行接口的“开箱即用”
Ø 易于配置、定制和扩展服务
Ø 核心服务很容易扩展与替换,且不会影响基础层
Ø 简单部署模型
2关键架构与领域术语
2.1层次架构
Spring Batch的架构设计是充分考虑了系统的可扩展性和各类终端开发的普适性。下图2.1.1是Spring Batch的层次架构示意图。

图2.1.1-SpringBatch层次架构图
Spring Batch架构主要分为三类高级组件: 应用层(Application), 核心层(Core) 和基础架构层(Infrastructure)。
应用层(Application):指开发人员编写的所有批处理业务作业和自定义代码。
核心层(Core):指加载和控制批处理作业所必需的核心类。含JobLauncher,Job和 Step的实现。
基础架构层(Infrastructure):应用层与核心层都构建在基础架构层之上。基础架构包括通用的readers(ItemReader)和writers(ItemWriter),以及services (如重试模块 RetryTemplate),可以被应用层和核心层所使用。
2.2领域术语
Step:表示作业Job中的一个完整业务逻辑步骤,一个Job可以有一个或者多个Step组成。
StepExecution:表示试运行一个步骤step的句柄。只有步骤step真的得到运行才会被创建。
Job(作业):作业是封装整个批处理过程的实体。一个简单的作业需要配置作业名、有序的步骤step、及是否重启。
JobInstance(作业实例):一个作业实例与其要加载的数据无硬性关联,这完全是由数据读入器ItemReader决定。比如:是否使用同一个作业实例,是由ItemReader根据前一次执行的状态位(state)决定。用新的JobInstance意味从开头读取数据,用已有的表示从上次结束的地方开始。
JobParameter(作业参数):是指一个批量作业开始的参数集。同时,可以用于标识JobInstance的唯一性。所以可以认为JobInstance=Job+JobParameter。
JobExecution:表示试运行一个作业的句柄。
如下图2.2.1所示,Job好比是容器,可以包含多个业务逻辑步骤step与多个JobInstance,来组织作业的执行(亦可以保证作业的重启),而JobExecution则是致力于记录执行状态。每一次执行中JobExecution和step都会进行数据信息传输,比如:commitCount、rollbackCount、startTime、endTime等,这些都会记录进StepExecution。
图2.2.1-批处理框架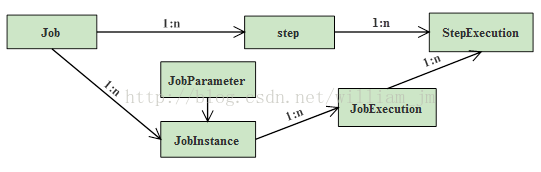 运行期的模型
运行期的模型
JobLauncher(作业调度器):是Spring Batch框架基础设施层提供运行Job的能力。对于将给定Job名称和作Job Parameters的Job,由Java程序、命令行或者其它调度框架(如Quartz)中调用JobLauncher执行Job。
JobRepository(作业仓库):来存储Job执行期的元数据(这里的元数据是指Job Instance、Job Execution、Job Parameters、Step Execution、Execution Context等数据)。有两种默认实现——内存或数据库。若将元数据存放在数据库中,可以随时监控批处理Job的执行状态。Job执行结果是成功还是失败,并且使失败Job重新启动Job成为可能。
ItemReader:是对step的输入的抽象,每次只读入一条记录,读取完所有记录后,则返回null。
ItemProcessor:是对每条记录按业务逻辑处理的抽象。
ItemWriter:是对step的输出的抽象,每次只可以提供给一次批作业或记录队(chunk)。
下图2.2.2显示了完整的SpringBatch领域概念模型。JobLancaster启动Job,Job可有多个Step组合,每一个step对应一个ItemReader、ItemProcessor及ItemWriter,而JobRepository记录Job执行信息。
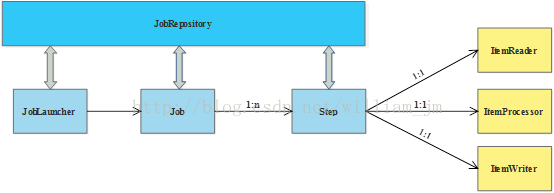
2.2.2-Spring Batch领域概念模型
3实战演习
光说不练假把式,这个章节就让我们一起实战操练下。
3.1What I’ll build
定时每天凌晨1点,按业务需求将TEST_TASK_PROPERTY表和DQP_TEST_FILE表数据汇总整合到表DQP_REPORT_A,即将结果数据表汇总到统计表中。
3.2What you’ll need
- Eclipse
- JDK 1.7 or later
- Maven 3.0
3.3Set up the project
本工程是由maven构建,使用SpringBoot简化复杂的依赖配置及部署,使用Quartz作为任务调度框架,SpringBatch作为批处理框架,数据持久化使用JPA。
3.3.1pom.xml文件
<?xml version="1.0"encoding="UTF-8"?>
<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.william.lab.springboot.springbatch</groupId>
<artifactId>springbatch</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>springbatch</name>
<description>Testproject for Spring Boot + Spring Batch + Quartz</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.6.RELEASE</version>
<relativePath/><!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.7</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<exclusions>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>jboss-logging</artifactId>
<groupId>org.jboss.logging</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<artifactId>log4j-over-slf4j</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.1</version>
<exclusions>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz-jobs</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<!--sftp连接 jar -->
<dependency>
<groupId>com.jcraft</groupId>
<artifactId>jsch</artifactId>
<version>0.1.54</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
<dependency>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>3.3.2Batch作业模块配置
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
private JobBuilderFactoryjobBuilderFactory;
@Autowired
private StepBuilderFactorystepBuilderFactory;
@PersistenceUnit
private EntityManagerFactory emf;
@StepScope
publicJpaPagingItemReader<TestReport> reader() {
JpaPagingItemReader<TestReport>reader = new JpaPagingItemReader<TestReport>();
reader.setQueryString("selectnew TestReport(ttp.taskId, tra.fileId, ttp.ruleId,sum( tra.count))"
+ " fromTestFile tra,TestTaskProperty ttp WHERE ttp.taskId=tra.taskId AND ttp.beginTimeBETWEEN ?1 AND ?2 "
+ "GROUP BYttp.taskId, tra.fileId, ttp.ruleId");
Map<String, Object>parameterValues = new HashMap<>();
parameterValues.put("1",CommonUtils.getTimeSection(0, 0, 0));
parameterValues.put("2",CommonUtils.getTimeSection(23, 59, 59));
reader.setParameterValues(parameterValues);
reader.setEntityManagerFactory(emf);
reader.setPageSize(Integer.MAX_VALUE);
return reader;
}
@Bean
public TestFileProcessor processor(){
return newTestFileProcessor();
}
@Bean
publicJpaItemWriter<TestReport> writer() {
JpaItemWriter<TestReport>writer = new JpaItemWriter<TestReport>();
writer.setEntityManagerFactory(emf);
return writer;
}
@Bean
public Step step() {
returnstepBuilderFactory.get("step").<TestReport, TestReport>chunk(10).reader(reader()).processor(processor())
.writer(writer()).build();
}
@Bean
public Job importUserJob(JobRepositoryjobRepository) {
returnjobBuilderFactory.get("importUserJob").incrementer(newRunIdIncrementer()).repository(jobRepository)
.flow(step()).end().build();
}
}在Spring的体系中@EnableBatchProcessing 注释的工作原理与其它的带有 @Enable * 的注释类似。在这种情况下, @EnableBatchProcessing 提供了构建批处理任务的基本配置。在这个基本的配置中,除了创建了一个StepScope的实例,还可以将一系列可用的bean进行自动装配:
JobRepositorybean 名称 "jobRepository"
JobLauncherbean名称"jobLauncher"
JobRegistrybean名称"jobRegistry"
PlatformTransactionManagerbean名称 "transactionManager"
JobBuilderFactorybean名称"jobBuilders"
StepBuilderFactorybean名称"stepBuilders"
这种配置的核心接口是BatchConfigurer。它为以上所述的bean提供了默认的实现方式,并要求在context中提供一个bean,即DataSource。数据库连接池由被JobRepository使用。
注意只有一个配置类需要有@ enablebatchprocessing注释。只要有一个类添加了这个注释,则以上所有的bean都是可以使用的。
3.3.2.1作业Job和步骤Step
Step()方法是组合特定业务需求步骤的,如上章节介绍,是由reader、processor和writer组成。importUserJob()方法提供的是组合业务作业的,由Step组成,并可以由jobRepository()方法将作业持久化。
3.3.2.2作业处理单元reader、writer、processor
reader()方法是读取数据的方法,这里实例化是JpaPagingItemReader()方法。JpaPagingItemReader允许您声明一个JPQL语句,并传入一个 EntityManagerFactory。然后就和其他的 ItemReader 一样,每次调用它的 read 方法都会返回一个 item。当需要更多实体,则内部就会自动发生分页。
writer()方法是将处理结果持久化进数据库的,其中JpaItemWriter是 JPA EntityManager aware 的,用来处理事务性工作,而执行实际的写入工作是委托另一个非jpa相关的(non-"jpa aware") ItemWriter做的。
processor()方法是业务数据处理方法,如下代码段,处理了简单业务逻辑。
public class TestFileProcessor implementsItemProcessor<TestReport, TestReport> {
private static final Logger log=LoggerFactory.getLogger(TestFileProcessor.class);
@Override
public TestReport process(finalTestReport testReport) throws Exception {
testReport.setTimeSection(CommonUtils.getTimeSection(0,0, 0));
log.info("StatisticResult 【" +testReport + "】");
return testReport;
}
}3.3.3Quartz调度模块配置
3.3.3.1Trigger触发器
@Component("cronTriggerFactoryBean")
public class CronTriggerFactoryBean {
@Autowired
private SchedulerFactoryBeanschedulerFactoryBean;
/**
* 添加或修改一个定时任务
*/
public void createNewTask(Stringexpression, int taskId) throws SchedulerException {
TriggerKey triggerKey =TriggerKey.triggerKey("TASK-" + taskId, "JOB-" +taskId);
CronTrigger trigger = null;
// 不存在,创建一个
JobKey jobKey = newJobKey("TASK-" + taskId, "JOB-" + taskId);
JobDetail jobDetail = JobBuilder.newJob(SpringQuartzJob.class).withIdentity(jobKey).build();
// 稽核任务基础信息
jobDetail.getJobDataMap().put("taskId",taskId);
// 表达式调度构建器
CronScheduleBuildercronScheduleBuilder = null;
cronScheduleBuilder =CronScheduleBuilder.cronSchedule(expression);
// 按cronExpression表达式构建一个新的trigger
trigger = TriggerBuilder.newTrigger().withIdentity(triggerKey).startAt(newDate()).withSchedule(cronScheduleBuilder).build();
// 加入任务队列
Scheduler scheduler =schedulerFactoryBean.getScheduler();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.rescheduleJob(triggerKey,trigger);
}
}
这是一个简单生成周期任务触发器类,由任务配置接口传入任务执行周期表达式(cron表达式)和任务编号等基础信息,建立CronTrigger定时触发器,调度quartz作业类。
3.3.3.2
@Component("springQuartzJob")
public class SpringQuartzJob extends QuartzJobBean {
@Autowired
Job importUserJob;
@Autowired
private JobLauncher jobLauncher;
@Override
public void executeInternal(finalJobExecutionContext context) throws JobExecutionException {
System.out.println("TestJobStart:" + Thread.currentThread().getId());
try {
init();
JobParameters jobParameters= new JobParametersBuilder().addLong("time", System.currentTimeMillis())
.toJobParameters();
JobExecution result =jobLauncher.run(importUserJob, jobParameters);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("Job1End");
}
public void init() {
importUserJob =(Job) MyApplicationContextUtil.getBeanObj("importUserJob");
jobLauncher =(JobLauncher) MyApplicationContextUtil.getBeanObj("jobLauncher",JobLauncher.class);
}
}JobParameters类似与Quartz中的JobDataMap,传递作业需要的数据。
jobLauncher.run()方法是通过作业Job和作业参数JobParameters来唯一标识作业仓库中已有的作业,并执行作业。
3.3.3.3ApplicationContextAware
public class MyApplicationContextUtil implementsApplicationContextAware {
private staticApplicationContext context;
public static void setContext(ApplicationContextcontext) {
MyApplicationContextUtil.context= context;
}
@Override
public void setApplicationContext(ApplicationContextcontext) throws BeansException {
this.context =context;
}
public staticApplicationContext getContext() {
return context;
}
public final staticObject getBeanObj(String beanName) {
return context.getBean(beanName);
}
public final static Object getBeanObj(StringbeanName, Class<?> requiredType) {
return context.getBean(beanName,requiredType);
}
}MyApplicationContextUtil继承了ApplicationContextAware接口,实现public void setApplicationContext(ApplicationContext context)throwsBeansException方法,获取spring配置上下文ApplicationContext,用于通过bean名字获取bean方法public final static ObjectgetBeanObj(StringbeanName)。
3.3.4SpringbatchApplication启动类
@SpringBootApplication
@PropertySource(value = {"./application.properties" })
publicclass SpringbatchApplication {
publicstatic ConfigurableApplicationContext ctx;
publicstatic void main(String[] args) {
ctx= SpringApplication.run(new Object[] { QuartzResource.class}, args);
}
@Bean
publicSchedulerFactoryBean schedulerFactoryBean() throws Exception {
SchedulerFactoryBeanschedulerFactoryBean = new SchedulerFactoryBean();
PropertiesquartzProperties = new Properties();
FileInputStream in = newFileInputStream("./src/main/resources/quartz.properties");
quartzProperties.load(in);
schedulerFactoryBean.setQuartzProperties(quartzProperties);
returnschedulerFactoryBean;
}
@Bean
publicMyApplicationContextUtil myApplicationContextUtil() {
returnnew MyApplicationContextUtil();
}
}public SchedulerFactoryBean schedulerFactoryBean()throwsException方法是用于初始化quartz配置信息quartz.properties。
3.3.5一个创建定时任务的web接口
@RestController
@ComponentScan(basePackages= { "com.william.lab.springboot.springbatch.springbatch" })
@RequestMapping("/quartz")
public class QuartzResource {
private Logger LOGGER =LoggerFactory.getLogger(QuartzResource.class);
@Autowired
private CronTriggerFactoryBeancronTriggerFactoryBean;
final int CREATE_ID = 17;
@RequestMapping(value ="/get/{taskId}", method = RequestMethod.GET)
public void createTask(@PathVariable("taskId")String taskId) throws SchedulerException {
String str[] =taskId.split(",");
for (int i = 0; i< str.length; i++) {
int taskIdx =Integer.parseInt(str[i]);
cronTriggerFactoryBean.createNewTask("00/1 * * * ?", 1);
}
}
}这是一个简单的接口,用户可以通过此接口定义quartz调度batch作业任务。
3.3.6配置文件application.properties与quartz.properties
3.3.6.1application.properties
# Tomcatport
server.port=18080
#Spring Batch
spring.batch.job.enabled=false
# MySQL DB
spring.datasource.url=jdbc:mysql://localhost:3306/william_lab?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
# log config
logging.config=file:./src/main/resources/logback-spring.xml
#database pool
spring.datasource.tomcat.max-idle=15
spring.datasource.tomcat.max-wait=1000
spring.datasource.tomcat.maxActive=50
spring.datasource.tomcat.min-idle=5
spring.datasource.tomcat.initial-size=10
spring.datasource.tomcat.validation-query=SELECT1
spring.datasource.tomcat.test-on-borrow=false
spring.datasource.tomcat.test-while-idle=true
spring.datasource.tomcat.time-between-eviction-runs-millis=18800
spring.datasource.tomcat.jdbc-interceptors=ConnectionState;SlowQueryReport(threshold=0)3.3.6.2quartz.properties
# Configure MainScheduler Properties
org.quartz.scheduler.instanceName:DQPScheduler
org.quartz.scheduler.instanceId:AUTO
org.quartz.scheduler.skipUpdateCheck:false
# Configure ThreadPool
org.quartz.threadPool.class:org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount:1000
org.quartz.threadPool.threadPriority:5
# ConfigureJobStore
org.quartz.jobStore.misfireThreshold:60000
org.quartz.jobStore.class:org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass:org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.useProperties:false
org.quartz.jobStore.dataSource:dqpDS
org.quartz.jobStore.tablePrefix:dqp_qrtz_
org.quartz.jobStore.isClustered:false
# Configure Datasources
org.quartz.dataSource.dqpDS.driver:com.mysql.jdbc.Driver
org.quartz.dataSource.dqpDS.URL:jdbc:mysql://localhost:3306/william_lab?useUnicode=true&characterEncoding=UTF-8&useSSL=false&autoReconnect=true
org.quartz.dataSource.dqpDS.user:root
org.quartz.dataSource.dqpDS.password:123456
org.quartz.dataSource.dqpDS.maxConnections:100
org.quartz.dataSource.dqpDS.validationQuery=select1
org.quartz.dataSource.dqpDS.idleConnectionValidationSeconds=60
org.quartz.dataSource.dqpDS.validateOnCheckout=true
org.quartz.dataSource.dqpDS.discardIdleConnectionsSeconds=60注意:最后4行配置是保证quartz的数据库连接池中,无效链接的释放。
4总结
Spring Batch将整个批处理作业流程分了3个基础阶段:读数据、业务处理、归档结果数据,且提供了许多读数据接口(文件,jpa,jdbc、MongDB等),同样写数据接口也很丰富(文件,jpa,jdbc、MongDB等),还有日志、监控、任务重启与跳过等特性。而开发者只需要关注事务的粒度,日志监控,执行方式,资源管理,读数据,处理数据,写数据的解耦等方面。但是,Spring Batch未提供关于批处理任务调度的功能,因此如何周期性的调用批处理任务需要自己想办法解决,就Java来说,Quartz是一个不错的解决方案,或者写脚本处理之。