Redis的key的数据类型为String,而value则支持多种不同的数据类型
常见的数据类型有:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
不常见的数据类型有:bitmap,geo,HyperLogLog。
一、String(字符串)
string是redis最基本的类型,一个key对应一个value。
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
语法
redis 127.0.0.1:6379> COMMAND KEY_NAME实例
redis 127.0.0.1:6379> SET w3ckey redis
OK
redis 127.0.0.1:6379> GET w3ckey "redis"
在以上实例中我们使用了 SET 和 GET 命令,键为 w3ckey。
常用命令
| 序号 | 命令及描述 |
|---|---|
| 1 | SET key value 设置指定 key 的值 |
| 2 | GET key 获取指定 key 的值。 |
| 3 | GETRANGE key start end 返回 key 中字符串值的子字符 |
| 4 | GETSET key value 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 |
| 5 | GETBIT key offset 对 key 所储存的字符串值,获取指定偏移量上的位(bit)。 |
| 6 | MGET key1 [key2..] 获取所有(一个或多个)给定 key 的值。 |
| 7 | SETBIT key offset value 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。 |
| 8 | SETEX key seconds value 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 |
| 9 | SETNX key value 只有在 key 不存在时设置 key 的值。 |
| 10 | SETRANGE key offset value 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。 |
| 11 | STRLEN key 返回 key 所储存的字符串值的长度。 |
| 12 | MSET key value [key value ...] 同时设置一个或多个 key-value 对。 |
| 13 | MSETNX key value [key value ...] 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。 |
| 14 | PSETEX key milliseconds value 这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位。 |
| 15 | INCR key 将 key 中储存的数字值增一。 |
| 16 | INCRBY key increment 将 key 所储存的值加上给定的增量值(increment) 。 |
| 17 | INCRBYFLOAT key increment 将 key 所储存的值加上给定的浮点增量值(increment) 。 |
| 18 | DECR key 将 key 中储存的数字值减一。 |
| 19 | DECRBY key decrement key 所储存的值减去给定的减量值(decrement) 。 |
| 20 | APPEND key value 如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。 |
使用场景:
缓存功能:String字符串是最常用的数据类型,不仅仅是Redis,各个语言都是最基本类型,因此,利用Redis作为缓存,配合其它数据库作为存储层,利用Redis支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
计数器:许多系统都会使用Redis作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
共享用户Session:用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存Cookie,但是可以利用Redis将用户的Session集中管理,在这种模式只需要保证Redis的高可用,每次用户Session的更新和获取都可以快速完成。大大提高效率。
分布式锁
分布式系统全局序列号
二、Hash(哈希)
Redis hash 是一个string类型的field和value的映射表,hash特别适合用于存储对象。
Redis 中每个 hash 可以存储 2^32- 1 键值对(40多亿)。
实例
redis 127.0.0.1:6379> HMSET w3ckey name "redis tutorial" description "redis basic commands for caching" likes 20 visitors 23000
OK
redis 127.0.0.1:6379> HGETALL w3ckey
1) "name"
2) "redis tutorial"
3) "description"
4) "redis basic commands for caching"
5) "likes"
6) "20"
7) "visitors"
8) "23000"
在以上实例中,我们设置了 redis 的一些描述信息(name, description, likes, visitors) 到哈希表的 w3ckey 中。
每个 hash 可以存储 2^32- 1 键值对(40多亿)。
常用命令
| 序号 | 命令及描述 |
|---|---|
| 1 | HDEL key field2 [field2] 删除一个或多个哈希表字段 |
| 2 | HEXISTS key field 查看哈希表 key 中,指定的字段是否存在。 |
| 3 | HGET key field 获取存储在哈希表中指定字段的值 |
| 4 | HGETALL key 获取在哈希表中指定 key 的所有字段和值 |
| 5 | HINCRBY key field increment 为哈希表 key 中的指定字段的整数值加上增量 increment 。 |
| 6 | HINCRBYFLOAT key field increment 为哈希表 key 中的指定字段的浮点数值加上增量 increment 。 |
| 7 | HKEYS key 获取所有哈希表中的字段 |
| 8 | HLEN key 获取哈希表中字段的数量 |
| 9 | HMGET key field1 [field2] 获取所有给定字段的值 |
| 10 | HMSET key field1 value1 [field2 value2 ] 同时将多个 field-value (域-值)对设置到哈希表 key 中。 |
| 11 | HSET key field value 将哈希表 key 中的字段 field 的值设为 value 。 |
| 12 | HSETNX key field value 只有在字段 field 不存在时,设置哈希表字段的值。 |
| 13 | HVALS key 获取哈希表中所有值 |
| 14 | HSCAN key cursor [MATCH pattern] [COUNT count] 迭代哈希表中的键值对。 |
使用场景:
- 适用于存储对象,比如把用户的信息存到hash里,以用户id为key,用户的详细信息为value。
- 电商购物车,以用户ID为key,商品ID为field,商品数量为value。
三、List(列表)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 2^32- 1 个元素 (4294967295, 每个列表超过40亿个元素)。
实例
redis 127.0.0.1:6379> LPUSH w3ckey redis
(integer) 1
redis 127.0.0.1:6379> LPUSH w3ckey mongodb
(integer) 2
redis 127.0.0.1:6379> LPUSH w3ckey mysql
(integer) 3
redis 127.0.0.1:6379> LRANGE w3ckey 0 10
1) "mysql"
2) "mongodb"
3) "redis"
在以上实例中我们使用了 LPUSH 将三个值插入了名为 w3ckey 的列表当中。
| 序号 | 命令及描述 |
|---|---|
| 1 | BLPOP key1 [key2 ] timeout 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 2 | BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 3 | BRPOPLPUSH source destination timeout 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 4 | LINDEX key index 通过索引获取列表中的元素 |
| 5 | LINSERT key BEFORE|AFTER pivot value 在列表的元素前或者后插入元素 |
| 6 | LLEN key 获取列表长度 |
| 7 | LPOP key 移出并获取列表的第一个元素 |
| 8 | LPUSH key value1 [value2] 将一个或多个值插入到列表头部 |
| 9 | LPUSHX key value 将一个或多个值插入到已存在的列表头部 |
| 10 | LRANGE key start stop 获取列表指定范围内的元素 |
| 11 | LREM key count value 移除列表元素 |
| 12 | LSET key index value 通过索引设置列表元素的值 |
| 13 | LTRIM key start stop 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。 |
| 14 | RPOP key 移除并获取列表最后一个元素 |
| 15 | RPOPLPUSH source destination 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
| 16 | RPUSH key value1 [value2] 在列表中添加一个或多个值 |
| 17 | RPUSHX key value 为已存在的列表添加值 |
使用场景:
- Stack栈:LPUSH+LPOP
- Queue队列:LPUSH+RPOP
- Blocking MQ阻塞队列:LPUSH+BRPOP
- 最新列表,List 类型的 lpush 命令和 lrange 命令能实现最新列表的功能,每次通过 lpush 命令往列表里插入新的元素,然后通过 lrange 命令读取最新的元素列表,如朋友圈的点赞列表、评论列表:
1、A关注了B,C等大V
2、B发微博了,消息ID为1001:LPUSH msg:{A的ID} 1001
3、C发微博了,消息ID为1002:LPUSH msg:{A的ID} 1002
4、A查看最新的5条微博消息:LRANGE msg:{A的ID} 0 5
四、Set(集合)
Redis的Set是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
集合中最大的成员数为 2^32- 1 (4294967295, 每个集合可存储40多亿个成员)。
实例
redis 127.0.0.1:6379> SADD w3ckey redis
(integer) 1
redis 127.0.0.1:6379> SADD w3ckey mongodb
(integer) 1
redis 127.0.0.1:6379> SADD w3ckey mysql
(integer) 1
redis 127.0.0.1:6379> SADD w3ckey mysql
(integer) 0
redis 127.0.0.1:6379> SMEMBERS w3ckey
1) "mysql"
2) "mongodb"
3) "redis"
在以上实例中我们通过 SADD 命令向名为 w3ckey 的集合插入的三个元素。
常用命令
| 序号 | 命令及描述 |
|---|---|
| 1 | SADD key member1 [member2] 向集合添加一个或多个成员 |
| 2 | SCARD key 获取集合的成员数 |
| 3 | SDIFF key1 [key2] 返回给定所有集合的差集 |
| 4 | SDIFFSTORE destination key1 [key2] 返回给定所有集合的差集并存储在 destination 中 |
| 5 | SINTER key1 [key2] 返回给定所有集合的交集 |
| 6 | SINTERSTORE destination key1 [key2] 返回给定所有集合的交集并存储在 destination 中 |
| 7 | SISMEMBER key member 判断 member 元素是否是集合 key 的成员 |
| 8 | SMEMBERS key 返回集合中的所有成员 |
| 9 | SMOVE source destination member 将 member 元素从 source 集合移动到 destination 集合 |
| 10 | SPOP key 移除并返回集合中的一个随机元素 |
| 11 | SRANDMEMBER key [count] 返回集合中一个或多个随机数 |
| 12 | SREM key member1 [member2] 移除集合中一个或多个成员 |
| 13 | SUNION key1 [key2] 返回所有给定集合的并集 |
| 14 | SUNIONSTORE destination key1 [key2] 所有给定集合的并集存储在 destination 集合中 |
| 15 | SSCAN key cursor [MATCH pattern] [COUNT count] 迭代集合中的元素 |
使用场景:
- 给用户添加标签,跟我们上面的例子一样。一个人对应多个不同的标签。
- 好友/关注/粉丝/感兴趣的人集合,可以使用上面的取交集、并集相关的命令。
- 随机展示,通过 srandmember 随机返回对应的内容,像一些首页获取动态内容可以这么玩。
- 黑名单/白名单,有业务出于安全性方面的考虑,需要设置用户黑名单、ip 黑名单、设备黑名单等,set 类型适合存储这些黑名单数据,sismember 命令可用于判断用户、ip、设备是否处于黑名单之中。
- 微信抽奖小程序
1、点击参与抽奖加入集合:SADD item:1001 {userID}
2、查看参与抽奖的所有用户:SMEMBERS item:1001
3、抽取3名中奖者:SRANDMEMBER/SPOP item:1001 3 (SRANDMEMBER后,中奖的用户不会从集合中移除,SPOP 后,中奖的用户会从集合中移除)
五、zset(sorted set:有序集合)
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 2^32- 1 (4294967295, 每个集合可存储40多亿个成员)。
实例
redis 127.0.0.1:6379> ZADD w3ckey 1 redis
(integer) 1
redis 127.0.0.1:6379> ZADD w3ckey 2 mongodb
(integer) 1
redis 127.0.0.1:6379> ZADD w3ckey 3 mysql
(integer) 1
redis 127.0.0.1:6379> ZADD w3ckey 3 mysql
(integer) 0
redis 127.0.0.1:6379> ZADD w3ckey 4 mysql
(integer) 0
redis 127.0.0.1:6379> ZRANGE w3ckey 0 10 WITHSCORES
1) "redis"
2) "1"
3) "mongodb"
4) "2"
5) "mysql"
6) "4"
常用命令
使用场景:
- 标签:比如我们博客网站常常使用到的兴趣标签,把一个个有着相同爱好,关注类似内容的用户利用一个标签把他们进行归并。
- 共同好友功能,共同喜好,或者可以引申到二度好友之类的扩展应用。
- 统计网站的独立 IP。利用 set 集合当中元素不唯一性,可以快速实时统计访问网站的独立 IP。
- 统计用户的点赞/取消点赞
- 排行榜功能,比如展示获取赞数最多的十个用户
- Zset本质就是Set结构上加了个排序的功能,除了添加数据value之外,还提供另一属性score,这一属性在添加修改元素时候可以指定,每次指定后,Zset会自动重新按新的值调整顺序。可以理解为有两列字段的数据表,一列存value,一列存顺序编号。操作中key理解为zset的名字,那么对延时队列又有何用呢?试想如果score代表的是想要执行时间的时间戳,在某个时间将它插入Zset集合中,它变会按照时间戳大小进行排序,也就是对执行时间前后进行排序,这样的话,起一个死循环线程不断地进行取第一个key值,如果当前时间戳大于等于该key值的socre就将它取出来进行消费删除,就可以达到延时执行的目的, 注意不需要遍历整个Zset集合,以免造成性能浪费。
六、bitmap
按字面意思来拆分一下bit和map。首先bit比特是二进制单位( binary unit)或二进制数字(binary digit)的缩写,是电脑记忆体中最小的单位,在二进位电脑系统中,每一bit 可以代表0 或 1(也就是二进制) 的数位讯号(非黑即白,非 0 即 1)。map这个的话好哥哥们很熟悉了吧,像Java(这不会不知道,世界上最好的语言,没有之一)中的HashMap。
在Redis中,Bitmaps本身不是一种数据结构,可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。实际上它就是字符串,但是它可以对字符串的位进行操作。
二进制表示字符串
好哥哥就会问了,那要怎么用bit来表示一个字符串呢? 那我就勉为其难的举个栗子,用bit 来表示Dawn。首先Dawn对应字母的ASCII码分别是68、97、119、110。那bit又只能存0 或 1,所以我们把对应的ASCII码转换成二进制得到01000100、01100001、01110111、01101110(一个字节Byte占八位bit)。如下图

ASCII码表
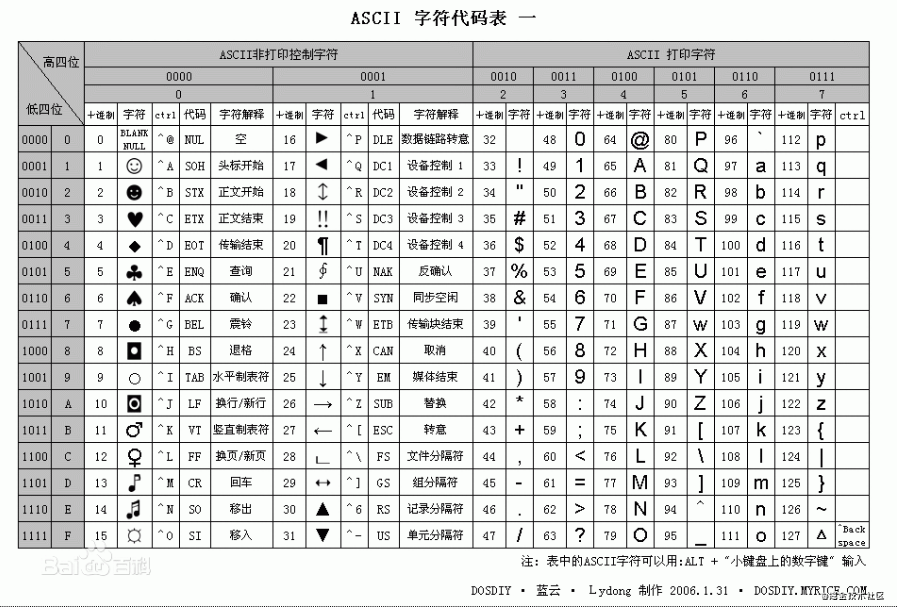
Bitmaps 存储结构
上面我们已经知道Bitmaps大概的一些概念,那在 Redis 中它是个什么样子的呢?实际上是差不多的,把对应的二进制字符串存入当成 value,这样是不是就可以对字符串进行做位进制的计算了,如图
实例
背景:将每个独立用户是否访问过网站存放在Bitmaps中,将访问的用户 记做1,没有访问的用户记做0,用偏移量作为用户的 id。
设值
设置键的第offset个位的值(从 0 算起),假设现在有 20 个用户, userid=0,5,11,15,19的用户对网站进行了访问,那么当前 Bitmaps 初始化结果如下图。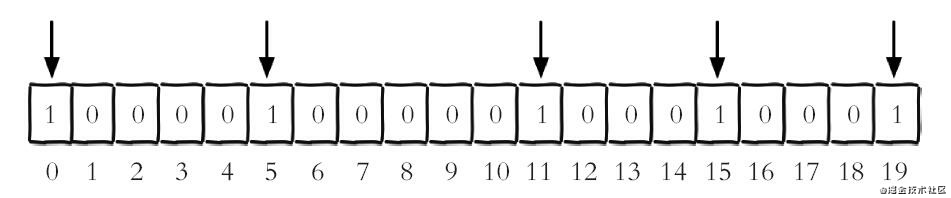
## 格式 key:键, offset:下标偏移量, value: 0或1
setbit key offset value
## 具体的操作过程
127.0.0.1:6379> setbit unique:users:2020-12-13 0 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2020-12-13 5 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2020-12-13 11 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2020-12-13 15 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2020-12-13 19 1
(integer) 0
复制代码如果此时有一个userid=50的用户访问了网站,那么 Bitmaps 的结构变成如下图,第 20 位~49 位都是 0。
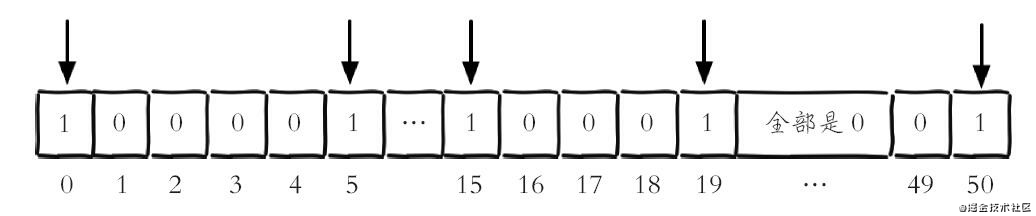
平时我们很多应用的用户id以一个指定数字(例如 10000 或者使用雪花算法产生)开头,直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费,通常的做法是每次做setbit操作时将用户 id 减去这个指定数字。在第一次初始化 Bitmaps 时,假如偏移量非常大,那么整个初始化过程执行会比较慢,可能会造成 Redis 的阻塞。
取值
如果我们需要获取用户 id 为 11 在 2020-12-13 是否有访问过网站,就可以使用以下的命令
## 格式 key:键, offset:下标偏移量
gitbit key offset
## 获取结果就是0或者1,如果offset在key中不存在则返回0
127.0.0.1:6379> getbit unique:users:2020-12-13 11
(integer) 1
复制代码获取 Bitmaps 指定范围内值为 1 的个数
按天统计访问过网站的用户数量
127.0.0.1:6379> bitcount unique:users:2020-12-13
(integer) 5
复制代码如果要计算用户 id 在第 1 个字节(一个字节等于 8 位,0-17offset)到第 3 个字节之间的独立访问用户数,对应的用户 id 是 11,15,19。
## 格式 [start]和[end]代表起始和结束字节数
bitcount [start][end]
## 返回统计结果
127.0.0.1:6379> bitcount unique:users:2020-12-13 1 3
(integer) 3
复制代码Bitmaps 间的运算
bitop是一个复合操作,它可以做多个Bitmaps的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中。
举个栗子,假设 2020-12-12 访问网站的 userid 为 1、2、5、9。
交集: 计算出 2020-12-12 和 2020-12-13 两天都访问过网站的用户数量
## 格式 op: 具体操作(and or),destkey: 结果集
bitop op destkey key[key....]
## 取交集
127.0.0.1:6379> bitop and unique:users:and:2020-12-12_13 unique:users:2020-12-12
unique:users:2020-12-13
(integer) 2
127.0.0.1:6379> bitcount unique:users:and:2020-12-12_13
(integer) 2
复制代码并集: 算出 2020-12-12 和 2020-12-13 任意一天都访问过网站的用户数量(例如月活跃就是类似这种)
## 取并集
127.0.0.1:6379> bitop or unique:users:or:2020-12-12_13 unique:users:2020-12-12 unique:users:2020-12-13
(integer) 2
127.0.0.1:6379> bitcount unique:users:or:2020-12-12_13
(integer) 6
复制代码计算 Bitmaps 中第一个值为 targetBit 的偏移量
例如我们要计算在 2020-12-13 在第 0 个字节到第 1 个字节之间访问网站的最小用户 id
## 格式 targetBit: 0或者1,[start]和[end]代表起始和结束字节数,和上面一样
bitpos key targetBit [start] [end]
## 栗子
127.0.0.1:6379> bitpos unique:users:2020-12-13 0 0 1
(integer) 0
复制代码对比
大数据量和高日活量场景下。假设网站有 1 亿用户,每天独立访问的用户有 5 千万,如果每天用集合类型和 Bitmaps 分别存储活跃用户结果图
看到区别了吗。很明显,这种情况下使用 Bitmaps 能节省很多的内存空间,尤其是随着时间推移节省的内存还是非常可观的
但是如果说这个网站的用户量很少,假设只有 10 万,那么使用 Bitmaps(基数太大)就不是很合适了,大量的值都是 0。
使用场景:
- 统计网站的日/月活量
- 用户按天签到
- 统计用户登录、在线等状态
- 实现布隆过滤器,不熟悉的可以看布隆过滤器这一篇就够了
总结
合理使用Bitmaps是能极大的减少内存空间的占用,在某些只有两个状态的统计中,性能也是非常好的。但是在值存储状态上来说Bitmaps的值实际上只能存bit,也就是说只能存 0 或者 1。这也就意味着我们需要统计或者标记的状态不能超过两个,例如男或者女,当某种神秘力量出现第三种其他性别时就无法完成统计或者标记。这也是使用Bitmaps的一个局限性。
七、geo
Redis3.2 版本提供了GEO(地理信息定位)功能,GEO 主要用于存储地理位置信息,并对存储的信息进行操作,用于实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能,对于需要实现这些功能的开发者来说是一大福音。
命令
增加地理位置信息
Redis 提供geoadd命令来添加或者更新地理信息位置,其中longitude、latitude、member分别是该地理位置的经度、纬度、成员。添加如下图的城市经纬度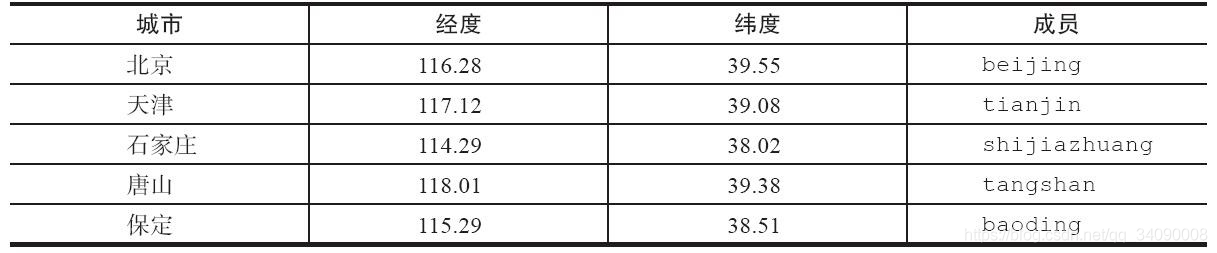
## 格式
geoadd key longitude latitude member [longitude latitude member ...]
## 添加北京,返回结果代表添加成功的个数,假如已经存在了则返回0
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 1
复制代码获取地理信息位置
## 格式 ,member 成员
geopos key member [member ...]
## 获取天津的地理位置
127.0.0.1:6379> geopos cities:locations tianjin
1) 1) "117.12000042200088501"
2) "39.0800000535766543"
复制代码获取两个地理位置的距离
Redis提供了geodist来获取两个地理位置的距离。其中unit代表返回结果的单位,包含以下四种:
- m(meters)代表米。
- km(kilometers)代表公里。
- mi(miles)代表英里。
- ft(feet)代表尺。
## 格式
geodist key member1 member2 [unit]
## 计算北京到天津的距离
127.0.0.1:6379> geodist cities:locations tianjin beijing km
"89.2061"
复制代码获取指定位置范围内的地理信息位置集合
georadius和georadiusbymember两个命令的作用是一样的,都是以一个地 理位置为中心算出指定半径内的其他地理信息位置,不同的是georadius命令 的中心位置给出了具体的经纬度,georadiusbymember只需给出成员即可。其 中radiusm|km|ft|mi是必需参数,指定了半径(带单位),这两个命令有很多 可选参数,如下:
- withcoord:返回结果中包含经纬度。
- withdist:返回结果中包含离中心节点位置的距离。
- withhash:返回结果中包含 geohash,有关 geohash 后面介绍。
- COUNT count:指定返回结果的数量。
- asc|desc:返回结果按照离中心节点的距离做升序或者降序。
- store key:将返回结果的地理位置信息保存到指定键。
- storedist key:将返回结果离中心节点的距离保存到指定键。
## 格式
georadius key longitude latitude radiusm|km|ft|mi [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [store key] [storedist key]
## 格式
georadiusbymember key member radiusm|km|ft|mi [withcoord] [withdist]
[withhash] [COUNT count] [asc|desc] [store key] [storedist key]
## 计算五座城市中,距离北京150公里以内的城市
127.0.0.1:6379> georadiusbymember cities:locations beijing 150 km
1) "beijing"
2) "tianjin"
3) "tangshan"
4) "baoding"
复制代码获取 GeoHash
GeoHash
GeoHash本质上是空间索引的一种方式,其基本原理是将地球理解为一个二维平面,将平面递归分解成更小的子块,每个子块在一定经纬度范围内拥有相同的编码。以 GeoHash 方式建立空间索引,可以提高对空间 poi 数据进行经纬度检索的效率。具体可以看Geohash 原理 使用 geohash 将二维经纬度转换为一维字符串,geohash有如下特点:
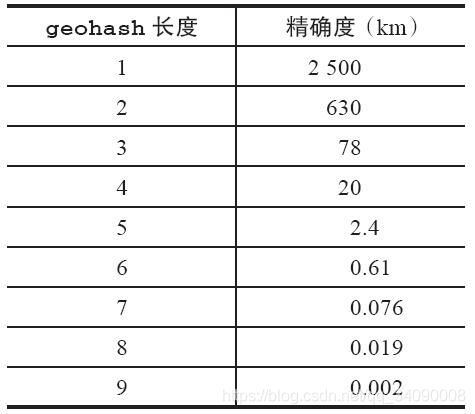
GEO的数据类型为zset,Redis 将所有地理位置信息的geohash存放在zset中。- 字符串越长,表示的位置更精确,例如
geohash长度为 9 时,精度在 2 米左右。如下图 - 两个字符串越相似,它们之间的距离越近,Redis 利用字符串前缀匹配算法实现相关的命令。
geohash编码和经纬度是可以相互转换的。
## 格式
geohash key member [member ...]
## 计算北京的geohash
127.0.0.1:6379> geohash cities:locations beijing
1) "wx4ww02w070"
复制代码删除地理位置信息
GEO没有提供删除成员的命令,但是因为GEO的底层实现是zset,所以 可以借用zrem命令实现对地理位置信息的删除。
## 格式
zrem key member
127.0.0.1:6379> zrem cities:locations beijing
1
复制代码原理
增加地理位置原理
上面有说GEO的底层数据结构是zset(sorted set),这个基本的数据结构不了解的话可以看Redis Sorted Set 运用场景、API 解析。先看一个zset的新增命令zadd key score member [score member ...],好哥哥们发现了吗,是不是很相似。有比较杠的好哥哥就会说了,这哪里相似,GEO明显有经纬度两个值,而zset只有一个score。是的,实际上这个地方是运用了一个算法那就是通过经纬度计算出对应的 52 位(bit)的 GEOHASH(这个其实也是一个算法,上面有提到过) 值作为元素的 Score值。那这样是不是就和zset一样了呢。所以其存储的原理和zset是一样的,只是多了一个计算Score值的过程。
geohash 原理分析
这个实际上上面已经有提到了,如果好哥哥们没有看懂那篇的话猛男我又找了一篇比较好懂的,可以看下GeoHash 核心原理解析,如果不想看的话那我总结如下(好哥哥们我都这样了你确定还不点赞加个关注吗)。 理解GeoHash需要解决以下两个问题:
- 如何唯一表示地球上的一块空间?
- 如何将地球切分成大小近似的区块,并支持不同粒度的表示?
方案:
- 将三维地球变成二维: 地球纬度区间是[-90,90],经度区间是[-180,180]。 将它展开想象成一个很大的矩形。
- 将二维再转成一维: 通过第一步的方法,我们能够将地球的表面转换成二维空间的平面。那接下来要将二维转变成一维。如果切割二维空间,可以切割出很多正方形。如何表示这个正方形呢?最简单的方法是在平面上进行遍历。每遍历到一个点,就给它标注一个值,比如 00、01、10、11,随着二进制数字增加,相当于遍历面上不同的位置。当将空间划分为四块时候,编码的顺序分别是左下角 00,左上角 01,右下脚 10,右上角 11,也就是类似于 Z 的曲线。
- 将一维表示成二进制码存储:
Geohash也有几种编码形式,常见的有 2 种,base 32和base 36。 会将落到网格中的二进制数据编码成字符串。
使用场景:
这个上面已经提到了,例如附近位置、附件的人、摇一摇这类依赖于地理位置信息的功能都可以使用GEO来实现。
总结
这一篇关于地理信息定位GEO,没有讲的太深,这个篇幅就已经很长了。主要的一个难点就是在于GeoHash的一个计算算法上,要搞懂这个的话好哥哥们还是要看看上面的两篇文章,当然也可以自己去搜索相关的资料,讲道理这个功能还是挺好玩的。后面有机会去踩踩坑,有熟悉的好哥哥可以把坑留着评论区。
八、HyperLogLog
首先HyperLogLog 并不是一个数据结构,而是一种基数1统计算法。通过HyperLogLog可以利用极小的内存空间完成独立总数的统计,数据集可以是 IP、Email、ID 等。因为HyperLogLog 只会根据输入元素来计算基数,而不会存储输入元素本身,所以 HyperLogLog 不能想集合那样,返回输入的各个元素。
原理
在上面有提到说HyperLogLog 使用的是概率算法,通过存储元素的hash值的第一个 1 的位置,来计算元素数量。举个栗子:
有一天小明和小红在操场上快乐的玩耍。突然小明红着脸对小红说我们来玩一个玩抛硬币的游戏,我赢的话你就做我女朋友,输了的我话我就做你男朋友,规则是我来负责抛硬币,每次抛到国徽面为一个回合,我可以决定抛几个回合,最后我会告诉你我最长的那个回合抛了多少次,然后你就来猜我一共抛了几个回合。小红红着脸说好呀,但是这不好猜呀,你先抛吧,我要算算这个概率了,于是快速在脑海中绘制了一幅图。
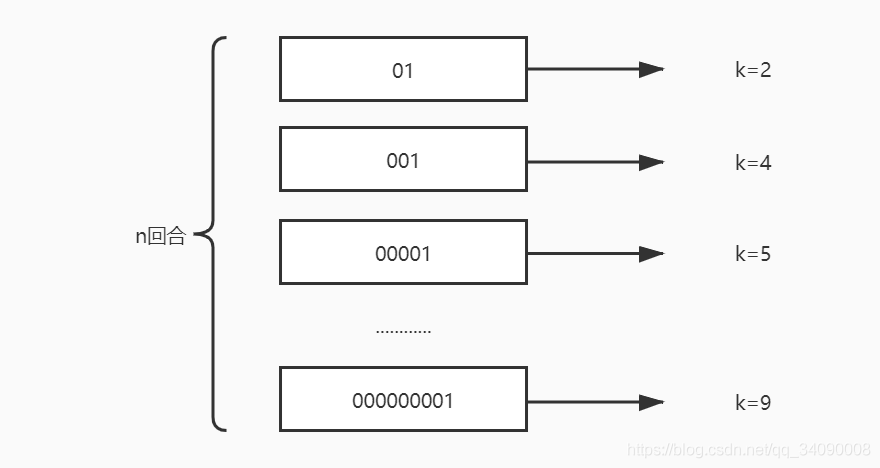
k是每回合抛到1(1 是国徽面,0 是数字面)所用的次数,我们已知的是最大的k值,用kmax表示,由于每次抛硬币的结果只有0和1两种情况。所以,kmax 在任意回合出现的概率即为 (1/2)kmax(1/2) ^{kmax}(1/2)kmax ,因此可以推测 n = 2kmax2 ^{kmax}2kmax 。概率学把这种问题叫做伯努利实验2。
然后小明已经完成了 n 个回合,并且告诉小红最长的一次抛了 3 次。小红胸有成竹,马上说出他的答案 8,最后的结果是:小明只抛了一回合,小红输了生气的对小明说玩游戏都不让女朋友赢你个渣男,你走吧,我们不可能了(没想到吧,哈哈哈哈)。
细心的好哥哥能发现上面的的概率算法是存在问题的(导致小红都输了),Philippe Flajolet 教授针对于于上面的问题引入了桶的概念,计算m个桶的加权平均值,这样就能得到比较准确的答案了(实际上还要进行其他修正)。最终的公式如图

回到 Redis 的HyperLogLog,对于一个新插入的字符串,首先得到 64 位的hash值,用前 14 位来定位桶的位置(共有 2142 ^{14}214,即 16384 个桶)。后面 50 位即为伯努利过程,每个桶有6bit,记录第一次出现 1 的位置count,如果count>oldcount,就用count替换oldcount。
命令
在 Redis 中操作HyperLogLog 只提供三个命令
1 添加
## 格式,key:键 element: 元素
pfadd key element [element … ]
## 添加一个元素,添加成功返回1
127.0.0.1:6379> pfadd 2020-12-14:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
复制代码2 计算基数
pfcount 用于计算一个或多个HyperLogLog的独立总数
## 格式,key:键
pfcount key [key … ]
## 返回总个数
127.0.0.1:6379> pfcount 2020-12-14:unique:ids
(integer) 4
复制代码3 合并
pfmerge 可以求出多个HyperLogLog的并集并赋值给destkey
## 格式,destkey :结果集key, sourcekey:需要合并的键
pfmerge destkey sourcekey [sourcekey ...]
## 添加2020-12-13号添加元素
127.0.0.1:6379> pfadd 2020-12-13:unique:ids "uuid-4" "uuid-5" "uuid-6" "uuid-7"
(integer) 1
## 计算2020-12-13和2020-12-14号基数
127.0.0.1:6379> pfmerge 2020-12_13_14:unique:ids 2020-12_13:unique:ids 2020-12-14:unique:ids
OK
127.0.0.1:6379> pfcount 2020-12_13_14:unique:ids
(integer) 7
复制代码内存使用
1 初始内存统计
127.0.0.1:6379> info memory
# 内存统计
used_memory:835144
used_memory_human:815.57K
复制代码2 插入批量数据
elements=""
key="020-12-14:unique:ids"
for i in `seq 1 1000000`
do
elements="${elements} uuid-"${i}
if [[ $((i%1000)) == 0 ]];
then
redis-cli pfadd ${key} ${elements}
elements=""
fi
done
复制代码3 统计使用内存
执行完添加元素操作内存只增加了 15K 左右
info memory
# 内存统计
used_memory:850616
used_memory_human:830.68K
复制代码4 准确率分析
使用pfcount的执行结果并不是 100 万
127.0.0.1:6379> pfcount 2016_05_01:unique:ids
(integer) 1009838
复制代码使用场景
HyperLogLog 内存占用量非常小,但是存在错误率。所以在使用是需要符合以下两点
- 只为了计算独立总数,不需要获取单条数据,上面说了只会存计算基数,不会存数据本身。
- 可以容忍一定误差率, 上面准确率分析也说到了。