前言
最近在做项目的时候,遇到了在后端生成PDF的需求,而且生成的页面较多,且样式管理相对复杂,还原度要求较高。通过一系列的社区调研后发现,
Puppeteer这个Node库可以提供一个相对高级的API,以DevTools协议控制Chrome或者Chromium,其无头模式可以将HTML转为PDF。这是目前Node Server应用中最为主流的解决方案,但是在使用过程中还是会存在很多坑点和注意事项。因此本文围绕无头浏览器、Puppeteer、HTML转PDF等几个方面进行总结和介绍。
一、无头浏览器
1.1 无头浏览器的基本理解
在wiki百科中,无头浏览器指的是没有图形用户界面GUI的浏览器。
无头浏览器运行在类似于常规网络浏览器的环境中,同时提供对网页的自动控制,由于其没有图形用户界面,因此无头浏览器通过命令行界面或使用网络通信来执行。
无头浏览器对于测试网页、爬虫等场景下能够发挥巨大的作用,因为它们能够像浏览器一样呈现和理解超文本标记语言,包括页面布局、颜色、字体以及JavaScript和Ajax的执行等样式元素,这些元素在使用其他测试方法时通常是不可用的。
综上所述,可以对无头浏览器的基本内含进行如下的总结:
- 它没有内容的真实呈现 ,也就是说,它绘制了内存中的所有内容。
- 它消耗的内存更少,工作更快 ,因为不需要绘制出可视化的图形界面,它不需要在实际屏幕上呈现任何内容,而尝试将其放入后端运行。
- 具有用于管理的编程接口 。例如:
Puppeteer可以提供一个相对高级的API,以DevTools协议控制Chrome或者Chromium。 - 一个重要的特性是能够在裸露的Linux服务器上安装 。 这样,在全新安装的
Ubuntu或CentOS服务器上,则只需将二进制文件进行编译安装,无头浏览器即可使用。
在这里补充一点,Chrome和Chromium是2个玩意,是2个浏览器,他们大致的区别是:Chromium是一个开源浏览器项目,它是ChromeWeb浏览器的基础。具体差异参考下面这篇文章。
1.2 无头浏览器的应用场景
无头浏览器通常用来:
Web应用程序中的测试自动化、JavaScript库运行自动化测试- 对网页进行拍摄、截图、转PDF等操作
- 用浏览器自带的一些调试工具和性能分析工具帮助我们分析问题
- 抓取单页应用(
SPA)执行并渲染(解决传统HTTP爬虫抓取单页应用难以处理异步请求的问题) - 捕获站点的时间线跟踪以帮助诊断性能问题
- 收集网站数据(爬虫应用)
- 自动化网页交互、模拟用户行为(例如键盘输入、表单提交等)
- 用于发起一些恶意攻击QAQ
此处附上一篇文章,介绍的是基于Puppeteer控制的无头浏览器的反爬攻防:
当然无头浏览器不止一种,其他的无头浏览器检测相似,可以自行Google~
1.3 常见的无头浏览器
Puppeteer操作的Headless Chrome,基于WebkitPhantomJS,基于WebkitSlimerJS,基于GeckoHtmlUnit,基于RhnioTrifleJS,基于TridentSplash,基于Webkit
这里需要注意一点,在笔者的理解中,Puppeteer本质上不是无头浏览器,结合官方给出的定义:
Puppeteer is a Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol.(Puppeter是一个Node库,它提供了一个高级API来通过DevTools协议控制Chrome或Chromium)
因此他是用于操作、控制无头浏览器(如:Headless Chrome)的Node库,反过来Headless Chrome理论上也应该可以由多种方式进行操作。
但是对PhantomJS而言,官方给出的定义是:
a headless WebKit scriptable with JavaScript.(可使用JavaScript编写脚本的无头WebKit)
因此PhantomJS属于无头浏览器~
接下来就主要对Puppeteer进行介绍
二、Puppeteer的基本应用
2.1 官方上手资料
Puppeteer的整体架构如下:
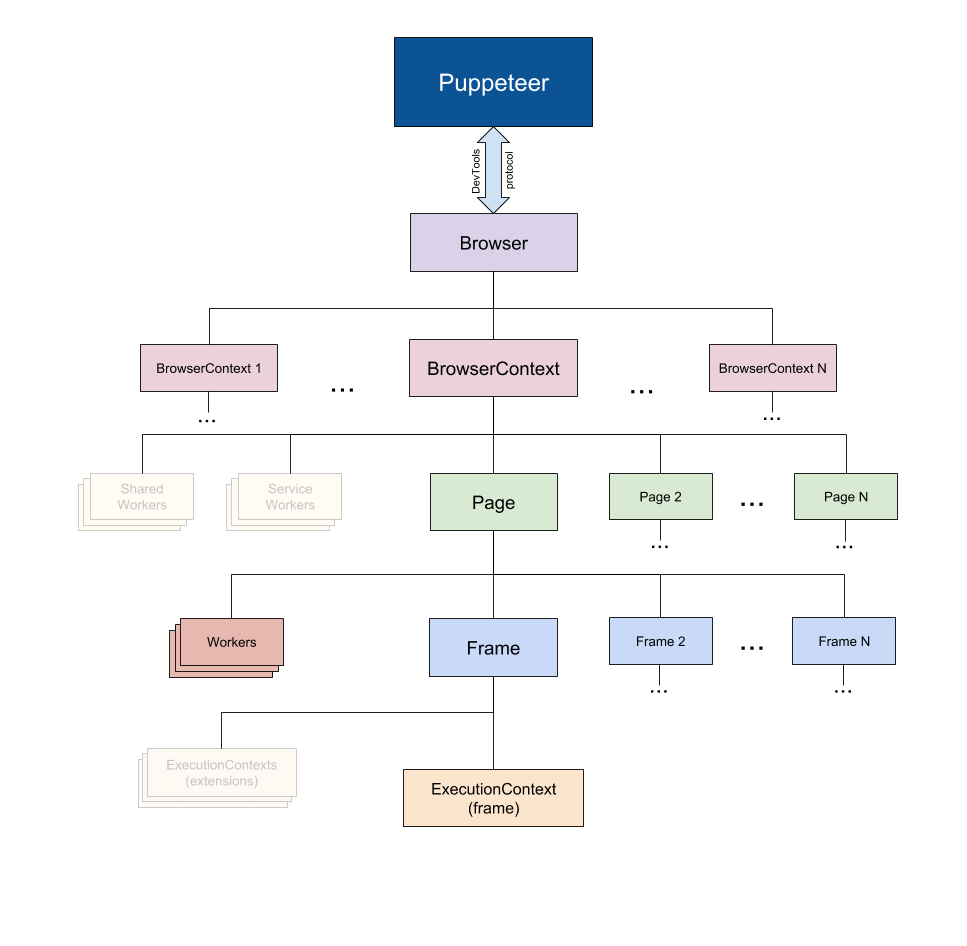
其实基本上就是Chrome的分层架构图。BrowserContext是浏览器环境的一个会话(如果这个概念较难理解,那么如果用新开一个浏览器隐私窗口的行为做类比,一个BrowserContext就是一个隐私窗口环境,各自不共享Cookie、CacheData这些),Page就是一个新建标签页产生的浏览器页面,Frame对应一个页面Document。
本章中主要对Puppeteer的一些常见的API和操作进行简要罗列,不进行很具体地展开,因为整体调用相对容易上手,直接参考文档即可:
同时,官方提供了一个用于演示Puppeteer Demo的网站
在这个网站可以查看Puppeteer的执行效果
本地测试,直接npm i puppeteer即可使用~
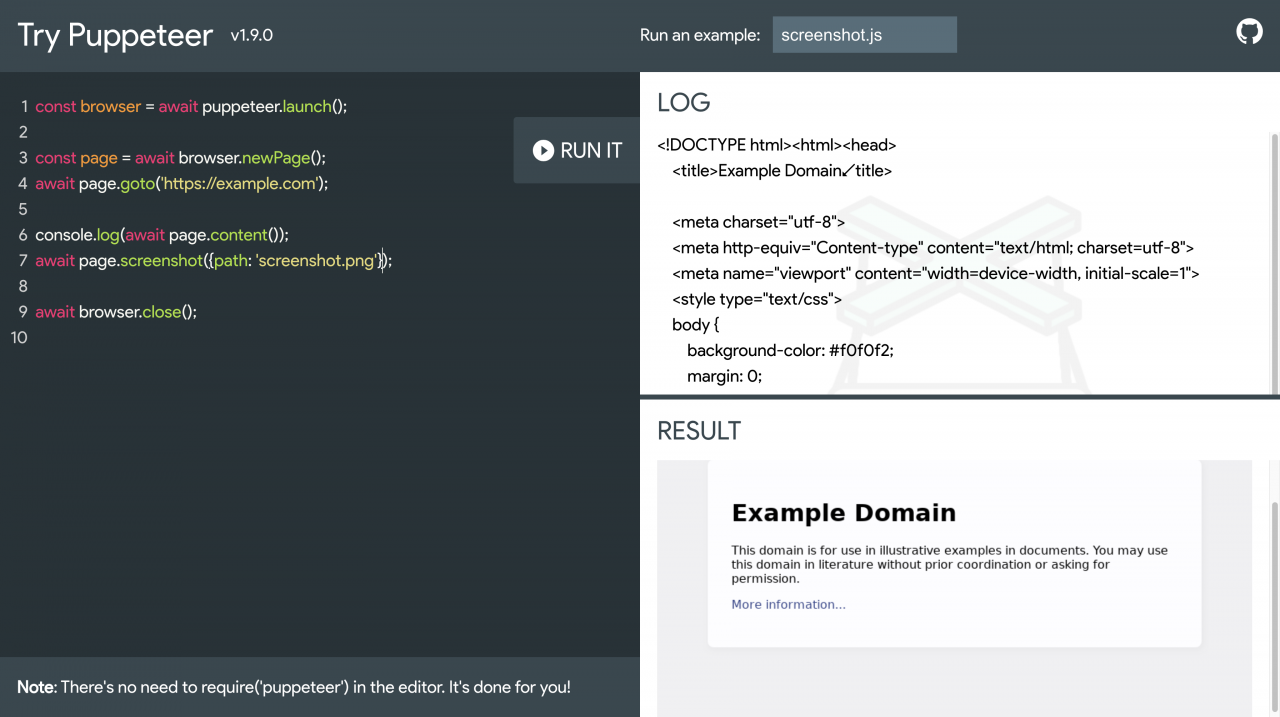
2.2 应用1:到指定Url将其页面存储为图片
本地执行:
// example.js
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: 'example.png' });
await browser.close();
})();
// 在命令行输入node example.js即可执行
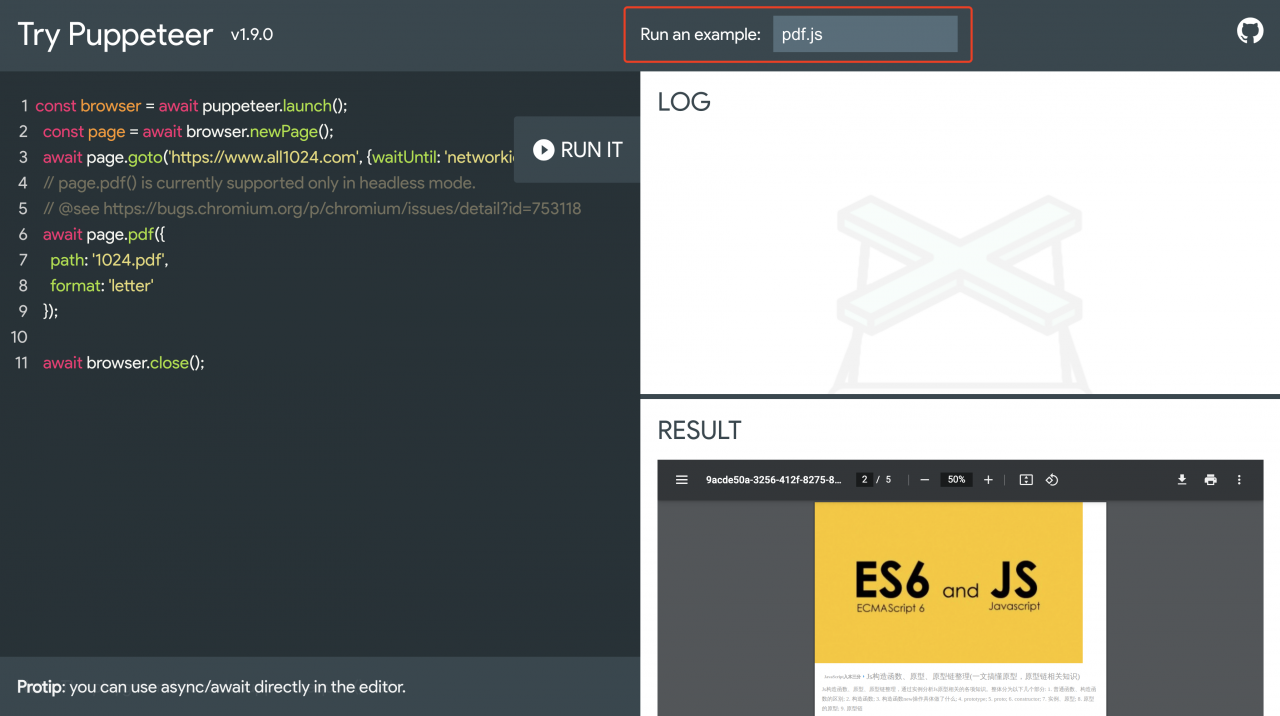
2.3 应用2:将网页(html字符串)存储为一个PDF
本地执行:
// example.js
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.all1024.com', {
waitUntil: 'networkidle2',
});
await page.pdf({ path: '1024.pdf', format: 'a4' });
await browser.close();
})();
// 在命令行输入node example.js即可执行
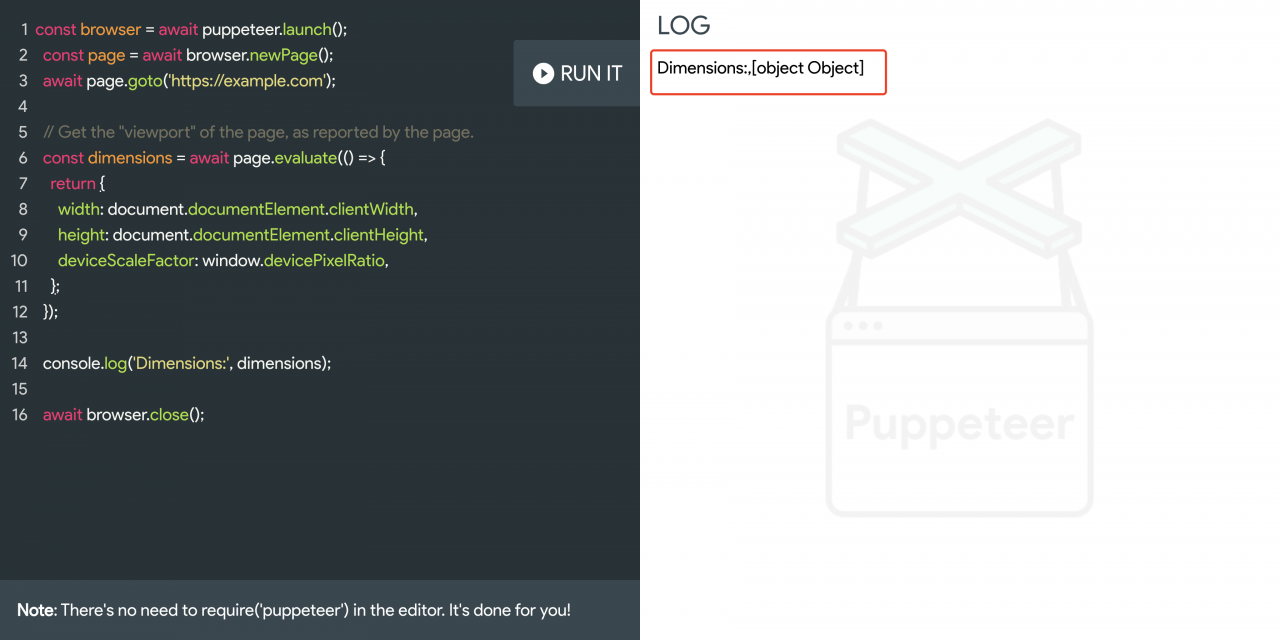
2.4 应用3:在页面上下文中执行脚本
本地执行:
// example.js
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
// 在命令行输入node example.js即可执行
2.5 应用4:代理
// example.js
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
// Launch chromium using a proxy server on port 9876.
// More on proxying:
// https://www.chromium.org/developers/design-documents/network-settings
args: [ '--proxy-server=127.0.0.1:9876' ]
});
const page = await browser.newPage();
await page.goto('https://google.com');
await browser.close();
})();
// 在命令行输入node example.js即可执行
2.6 应用5:自动提交表单
// example.js
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
// 地址栏输入网页地址
await page.goto('https://baidu.com/', {
waitUntil: 'networkidle2',
});
// 输入搜索关键字
await page.type('#kw', '腾讯公司', {
delay: 1000, // 控制 keypress 也就是每个字母输入的间隔
});
// 回车
await page.keyboard.press('Enter');
})();
// 在命令行输入node example.js即可执行
除此之外还有很多应用,可以自行查找和探索~
三、Puppeteer在HTML转PDF的应用
由于最近在项目中主要使用的是PDF生成相关的API,遇到了不少坑点,因此下一章就对HTML转PDF中常见问题进行总结~
项目场景是这样的:前后端分离的应用中,后端为
Koa服务,基于Puppeteer进行HTML转PDF的应用,此处的HTML并非Url,而是通过ejs进行模板渲染后读取出来的HTML字符串。我们需要同时导出数十个
3.1 ejs模板引擎的使用
为什么要在本项目中使用ejs呢?原因显而易见,我们需要动态渲染数据,但整体结构和样式固定,因此需要用到模板引擎,ejs相对比较老牌,是中规中矩的技术选型,ejs的官方文档如下。
在ejs与Puppeteer的配合中,理论上有2种方案:
一种是,直接通过ejs的renderFileAPI进行ejs字符串与数据的聚合,而后将生成的HTML字符串传给Puppeteer的page API,进行PDF的生成;
另一种是,把经过ejs渲染后的HTML字符串存为HTML文件,将其挂载为Koa的静态资源,这样就可以通过Url访问到该HTML,然后将Url传给Puppeteer的page API,进行PDF的生成;
两种方式Puppeteer都是支持的,一个是接收HTML字符串,一个是接收Url,但相比而言,前者的效率要搞很多,因此实际项目应用中使用前者,核心代码如下:
// 环境TypeScript
// ejs传入数据的类型定义
interface PDFDataObj {
[propName: string]: any
}
async function getHTML(pdfReportData:PDFDataObj) {
// 解析html字符串
let EJS2HTML = await new Promise((resolve, reject) => {
ejs.renderFile(
path.resolve(__dirname, "../../../", "public/htmlModel/", "report.ejs"), // ejs模板文件的存储路径
pdfReportData, // 给ejs传入的渲染数据
function (err, string) {
// 回调函数
if (err) {
reject(string);
} else {
resolve(string);
}
}
);
});
return EJS2HTML as string;
}
3.2 ejs中外部资源文件的引入问题(css、js文件及图片文件)
如果在ejs模板中,使用路径的格式调用资源,最终在Puppeteer生成PDF的时候是无法成功加载出静态资源的,例如:
<script type="text/javascript" src="/public/js/echarts.min.js"></script>
<script type="text/javascript" src="./js/echarts.min.js"></script>
因为此时的路径环境已经发生了变化,如何解决呢,有两种方式:
- 将资源文件上传到CDN或者一些
对象存储服务(如腾讯的COS,阿里的OSS),然后获取资源链接,进行替换,但前提是项目支持外网资源调用; - 当项目不可以调用外网资源的时候(本项目就是这样),我们只能将静态资源文件挂载到当前的Server中;
在Koa中Koa-static可以为我们挂载静态资源。
在本项目中,需要启用Koa的多静态资源路径,一个分配给前端的打包文件,另一个分配给后端使用到的静态文件(如ejs引入的外部文件)。这些需要用到另一个npm包koa-mount,如果在项目中开启了路径的权限验证时,记得将这些静态资源的权限释放出来,部分核心的设置代码如下:
// TypeScript环境
import Koa from "koa"
import koaJwt from "koa-jwt"
import koaMount from "koa-mount"
import koaStatic from "koa-static"
import { Config } from "./config"
export class App {
public app: Koa
private server!: Server
private config: Config
public constructor() {
this.app = new Koa()
this.config = new Config()
}
private addRouter() {
let staticPath = path.resolve(__dirname, "../client/dist")
let publicPath = path.resolve(__dirname, "../public")
this.app.use(koaJwt({secret:this.config.config.jwt.secretKey, key:"jwt", cookie: "jwt_token"}).unless({ path: [/^\/(v1|login|js|img|css|font|images|public)/] }))
this.app.use(koaStatic(staticPath, { index: "index.html", maxage: 24 * 3600 * 1000, defer: true }))
// 挂载多个静态目录
this.app.use(koaMount("/public", koaStatic(publicPath)))
}
}
本项目基于typescript进行构建,javascript的构建方式类似,可以参考addRouter中的设置方式~
最后的效果就是,通过xxx.com/login 这样的路径可以映射到前端入口,通过xxx.com/public/images/xxx.png可以映射到后端的静态资源,css文件、js文件、font文件等都是同样的道理。
之所以这样做,是因为项目目录结构的问题,为了方便开发,在本项目中,前端源文件放在了后端的目录列表中,方便在前端npm run build打包后,可以无缝更新到后端所指向的前端dist目录中,而不需要手动更新dist。
ejs相关的静态资源文件是后端的模板渲染用到的,因此不能放在默认的dist静态资源目录中,否则只要前端打包,那么后端的这些文件就会被自动删除。因此他们独立于前端,应该放在一个新的public静态资源目录中,这样以来Koa就需要启用2个静态资源目录。
整体的目录结构大致如下,client中即为前端的源代码,同时包含有dist资源包;public为后端静态资源依赖~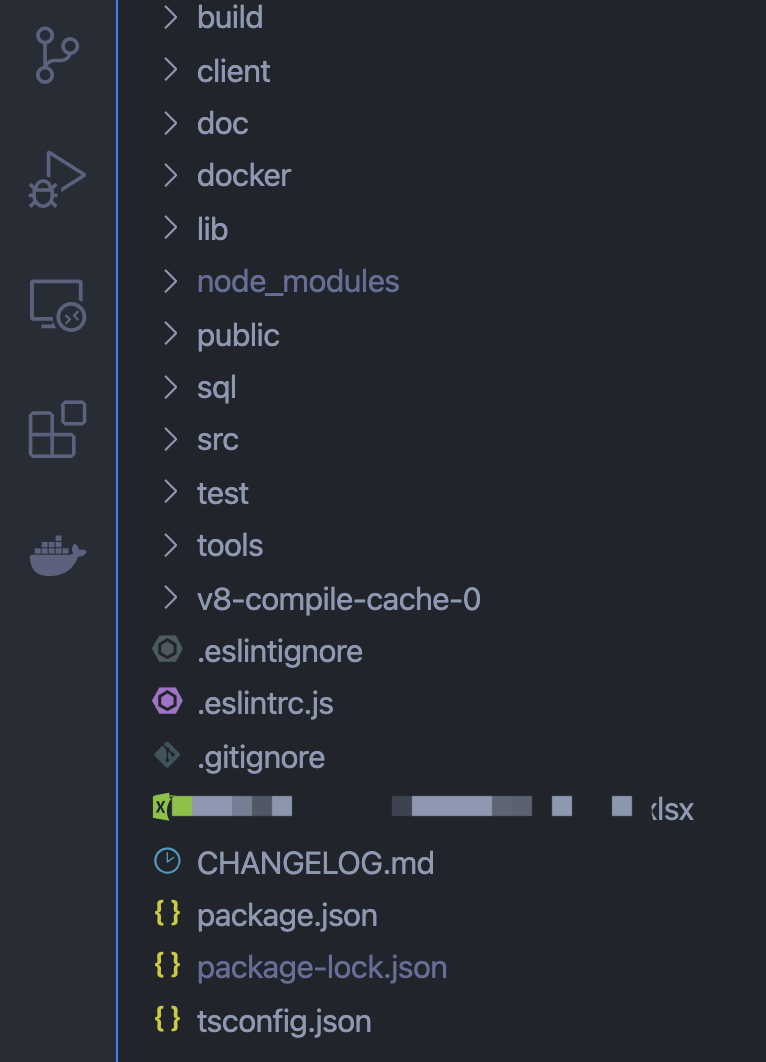
上述配置好之后,在ejs文件中,就以url的形式进行资源调用。为了进行动态配置,这里的https://www.xxx.com,就配置成了resourcesUrl这个参数进行传递:
<script type="text/javascript" src="<%= resourcesUrl %>/public/js/echarts.min.js"></script>
3.3 Puppeteer中的字体失效问题
通常在html、css的样式书写中,当网页需要指定字体,
如果我们直接将font-family设置为Microsoft YaHei,而不进行其他处理,那么对于一些内置微软雅黑字体的浏览器,页面呈现效果,就是微软雅黑;而部分浏览器没有内置微软雅黑字体那么,呈现出来的就是浏览器的默认字体。
为了避免这种情况,我们通常会在资源文件夹中存储相关的字体文件,然后以类似下面的方式进行调用:
@font-face {
font-family: 'MyWebFont';
src: url('../font/webfont.woff') format('woff'),
url('../font/webfont.ttf') format('truetype');
}
.targetDom {
font-family: MyWebFont;
}
但是在Puppeteer应用中,这样使用是会出问题的,因为Puppeteer生成PDF最终依赖的是操作系统层级的字体库,也就是说系统中安装了什么字体,我们在css中就可以调用什么字体,且名字必须一致。这个听起来挺离谱的,但我在项目实践过程中确实是这样的,试了很多种方式都没有解决,最后发现与系统字体有关系。
通过查看文档,大致推测,这个现象是与Puppeteer对于chromium的依赖引起的,而chromium直接依赖于底层的OS。
也就是说,我们只要在系统层级安装好字体库,那么这个问题就可以解决。
3.4 Puppeteer在Linux中部署存在的问题及Docker的应用
那么新问题又来了,绝大多数情况下,我们部署的Server都是Linux操作系统,Linux系统对于字体的安装与Windows或macOS截然不同,而开发环境往往又是windows或macOS。
对于Linux中的字体安装问题,可以参考下面这篇文章,或者参考下面的Dockerfile中的执行步骤:
当在公司的自研上云平台进行部署时,很容易会产生本地开发与线上部署出现不同效果甚至报错的情况,因此就引出了Docker的应用,原本在引入Puppeteer之前整个项目似乎不太需要Docker,但事实证明,长线项目开发还是把Docker用起来,会方便很多~
除了字体的问题外,Puppeteer在Linux的应用中也会出现chromium报错,这里需要单独对chromium进行安装。
把上述所有的操作进行梳理后,就形成了下面的Dockerfile,在文件中对命令都进行了注解,在实际项目开发中可以参考,其他的配置参考3.9。
# 此处填写基础镜像的地址
FROM mirrors.tencent.com/xxxxx/xxxxxx
ARG NODEJS_VERSION=v14.1.0
LABEL MAINTAINER="Alexzhli"
# Install
# 安装chromium
RUN yum -y install chromium \
# 获取并安装 nodejs
&& wget https://github.com/nvm-sh/nvm/archive/v0.35.1.zip \
&& unzip v0.35.1.zip -d /root/ \
&& rm v0.35.1.zip \
&& mv /root/nvm-0.35.1 /root/.nvm \
&& echo ". /root/.nvm/nvm.sh" >> /root/.bashrc \
&& echo ". /root/.nvm/bash_completion" >> /root/.bashrc \
&& source /root/.bashrc \
&& nvm install $NODEJS_VERSION \
# 安装ts及ts-node
&& npm install -g typescript ts-node \
# 安装并且设置linux中文字体
# 安装中文字体支持
&& yum -y groupinstall chinese-support \
# 设置linux语言环境
&& LANG=zh_CN.UTF-8 \
# 从COS中下载字体
&& wget https://xxx.com./xxx/TencentSans-W7.ttf \
# 从COS中下载字体
&& wget https://xxx.com./xxx/msyh.ttf \
# 安装字体
&& cp TencentSans-W7.ttf /usr/share/fonts \
&& cp msyh.ttf /usr/share/fonts \
&& cd /usr/share/fonts \
&& mkfontscale \
&& mkfontdir \
# 更新缓存
&& fc-cache
WORKDIR /usr/local/app
这样以来,开发环境和生产环境就会完全一致~
3.5 页眉、页脚、页码的注意要点
Puppeteer提供的页眉页脚方案,是通过设置headerTemplate和footerTemplate来实现的,将两者设置为HTML字符串,然后传递给page.pdf()中。- 通过
margin参数设置页面的边距,这里留出来的边距,就是headerTemplate和footerTemplate的展示空间。 headerTemplate和footerTemplate中不支持使用路径和url的形式调用图片资源,那如果需要展示img该怎么办呢?将img尽可能压缩后,转为base64,放在src中,就可以正常显示。headerTemplate和footerTemplate不支持css的background,如需进行丰富样式的页眉页脚设计,就需要把背景转为img,再放进去。headerTemplate和footerTemplate设置的页眉和页脚,并不在html的dom流中,他们不属于<html/>也不属于<body/>,html的dom会自动跳过这片区域,与word类似。因此无法在html文件中的css中控制其样式,只能将其样式写入Template的字符串中,作为行间样式。headerTemplate和footerTemplate设置的页眉和页脚,默认会有一些偏移,因此需要在行间样式额外指定margin-top、margin-bottom来进行位置调整。- 目前经过实践,在
Puppeteer的应用中我们没法在除了headerTemplate和footerTemplate的其他地方获取到page的页码,headerTemplate和footerTemplate提供了默认的页码显示支持,将span标签的class设置为totalPages为总页数,设置为pageNumber为当前页数。
3.6 Echarts或图片发生跨页断裂时的解决方案
对于整个页面生成来说,长图片跨页断裂的情况很难避免,在word这样的高级操作软件中,官方把问题抛给了用户,直接不允许长图跨页,因此用户就只能手动切分,或者是将图片缩小。
在Puppeteer中发生断页,会是这样的效果(有页眉页脚和margin配置):
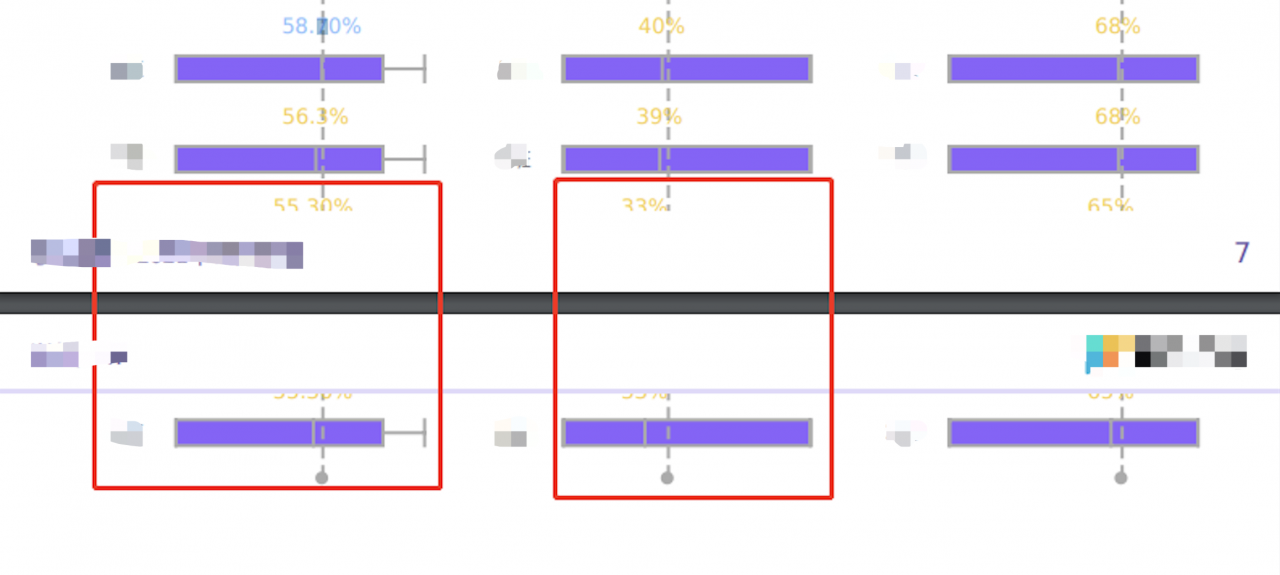
但是对于复杂的动态PDF生成场景而言,我们没法人为干预切分或缩小,这样会影响到本身预计的效果,或者是导致过高的开发成本。word页面本质上是静态的,也就是说,用户必须把每一页固定下来,不会存在不确定的页面。而在生成纵向的Echarts图表时,如果数据项过多,就会占用多个不确定数目的页面。这种情况下有3种大致的解决方案:
- 与产品沟通,将页面的总长度尽可能静态化,即每一页的每个地方放置什么,长度大小都是确定的,这样肯定是最万无一失的。
- 可以接受图片或者
Echarts表发生断裂跨页,那么就不需要做任何处理(前提是配置了页眉页脚和margin),只是图片在展示的时候有可能会在两个页面中间断开。 - 在必须支持
Echarts完美分割的场景下,将动态高度的地方摘出来处理,之前只创建一个Echarts实例,那么在动态场景下就按需创建多个Echarts实例,严格计算charts中每一个item的高度,再结合整个Page的高度进行跨页处理。例如:如果一个chart有40个item纵向堆积,每一个Page可以放15个,而当前Page还残留有8个item的空档,那么就生成4个chart实例,一共占用4个页面,其中item的数目分别为8、15、15、2,再给每一个chart的dom元素动态设置恰好的高度,即可实现完美呈现。这些都是可以由js的动态style设置和css属性page-break-after: always;及page-break-before: always;控制的,不同的场景代码书写方式有比较大的差异,此处不列出具体代码,给一个大致的效果图,可以看到Echarts进行了相对完美的分割~
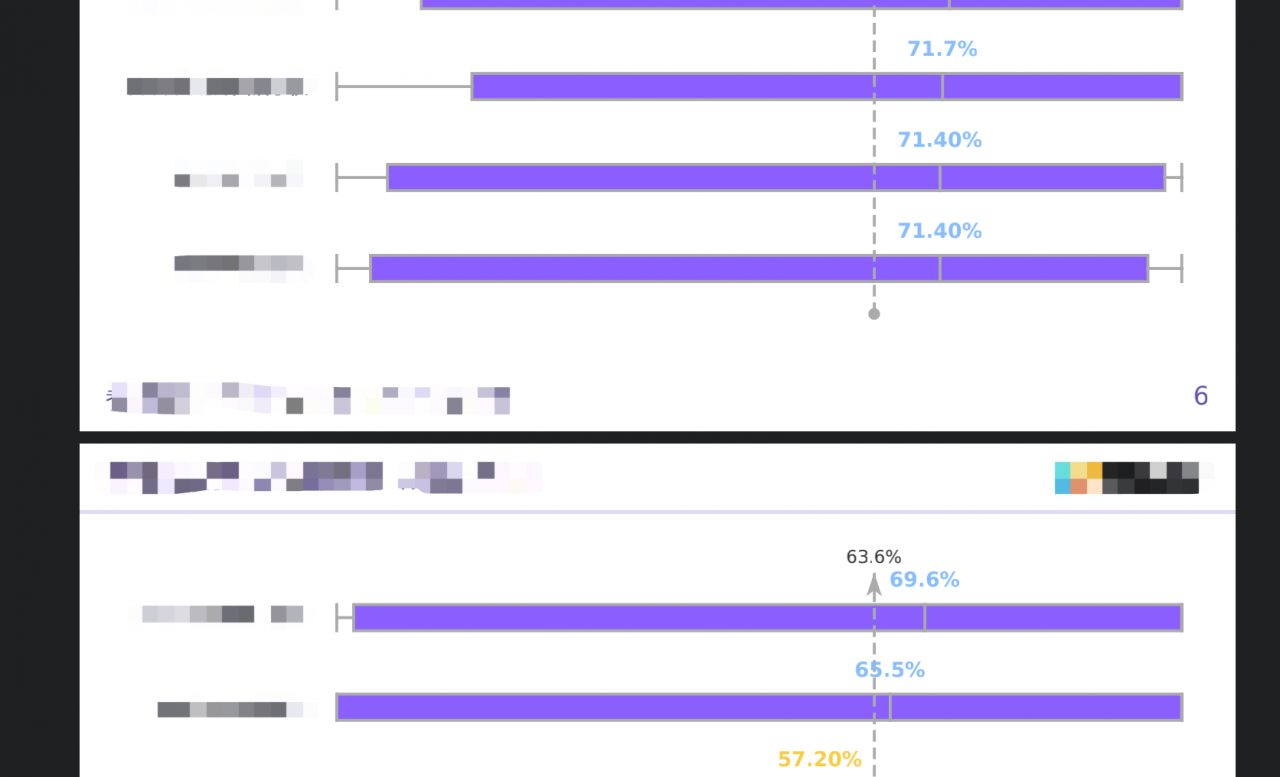
3.7 原生table表跨页解决方案
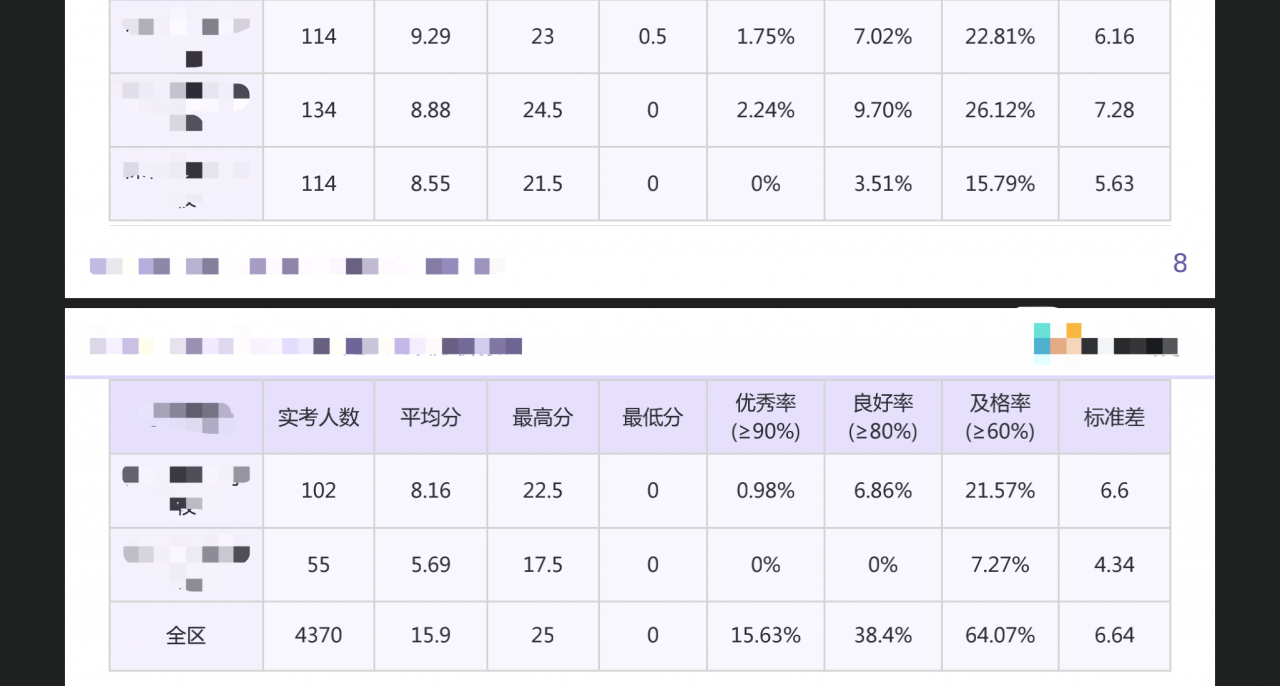
同上,如果不对table跨页进行处理,那么是这样的效果(前提是设置了页眉页脚margin):

table的跨页设置相对简单,需要使用thead:
table thead {
display: table-header-group;
break-inside: avoid;
}
跨页的地方会自动补齐tablehead,效果如下:
3.8 如何进行所见及所得的调试
由于是基于无头浏览器,因此浏览器绘制出的页面我们无法看到,通过将buffer存为PDF文件,点开PDF文件再查看,这样还原度是最高的,但是调试效率会特别低。
我们可以在相关的ejs模板中,加一端脚本:
setTimeout(() => {
window.print()
}, 2000)
然后在后台新开一个router,用于加载最终生成的HTML字符串(含数据),这样就可以在浏览器中直接查看。
之所以使用window.print是因为PDF生成和常规的HTML的DOM流不太一样,会产生一些效果差异,例如:页眉页脚、页面宽度,甚至HTML在正常的显示中是没有“页”的概念的,直接一长片显示。
目前在应用中,A4大小PDF的像素尺寸为 794px * 1124px(包含页眉页脚)
window.print可以大致模拟PDF的呈现效果,同时结合最终生成的PDF,可以大大提高调试效率。
3.9 HTML转PDF的最佳实践(仅指PDF的创建及生成)
由于本项目中,涉及到了同时生成数十个PDF,因此使用了Promise.all()做了异步处理。
同时针对Puppeteer中browser的关闭时机、实例个数等,我自己简单做了下测试,结果是这样的:
处理速度 多个browser实例 > 单browser实例多进程 > 单browser单进程;
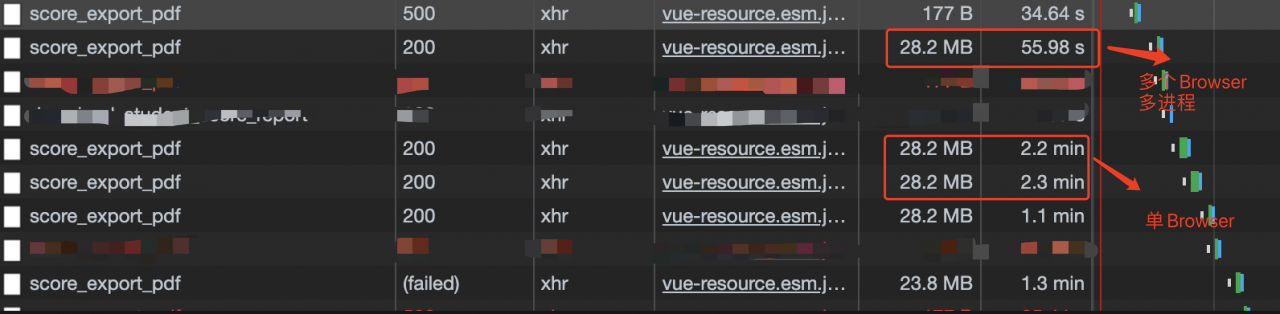
当然这个也与业务场景和服务器环境有关系,上面的测试结果并不系统,整个功能也不需要承载特别多的并发,因此对于速度的要求并不高~
本项目中每一个PDF体积较大,HTML绘制过程占用时间较多,因此多个browser会很有优势;另外服务器的配置也可能会影响不同配置下的处理速度,所以有条件的话,服务器配置拉上去,应该问题不大,因为Puppeteer本质上就是开了很多个浏览器,还是很吃服务器资源的。
因此在项目中,在每个PDF生成的时候都会创建一个browser实例,以空间换时间。
阅读了一些文章,结合一些坑点,得出一个相对最佳的实践。这当然是基于本项目的应用场景,仅指使用Puppeteer进行PDF的创建及生成,并不包括UI开发相关的内容,在代码中也对一些额外的注意事项进行了标注~
browser的args配置可以参考:
async function getPDF() {
const browser = await puppeteer.launch({
headless: true,
args: [
"--no-sandbox", // linux系统中必须开启
"--no-zygote",
// "--single-process", // 此处关掉单进程
"--disable-setuid-sandbox",
"--disable-gpu",
"--disable-dev-shm-usage",
"--no-first-run",
"--disable-extensions",
"--disable-file-system",
"--disable-background-networking",
"--disable-default-apps",
"--disable-sync", // 禁止同步
"--disable-translate",
"--hide-scrollbars",
"--metrics-recording-only",
"--mute-audio",
"--safebrowsing-disable-auto-update",
"--ignore-certificate-errors",
"--ignore-ssl-errors",
"--ignore-certificate-errors-spki-list",
"--font-render-hinting=medium",
]
});
// try...catch...
try {
const page = await browser.newPage();
// 页眉模板(图片使用base64,此处的src的base64为占位值)
const headerTemplate = `<div
style="width: calc(100% - 28px); margin-top: -13px; font-size:8px;border-bottom:2px solid #e1dafb;padding:6px 14px;display: flex; justify-content: space-between; align-items:center;">
<span style="color: #9a7ff7; font-size: 12px; font-family: my-font;">李钟航的报告模板</span>
<img style="width: 80px; height: auto;" src="https://img-blog.csdnimg.cn/2022010702200041286.png" />
</div>`
// 页脚模板(pageNumber处会自动注入当前页码)
const footerTemplate = `<div
style="width:calc(100% - 28px);margin-bottom: -20px; font-size:8px; padding:15px 14px;display: flex; justify-content: space-between; ">
<span style="color: #9a7ff7; font-size: 10px;">这里是页脚文字</span>
<span style="color: #9a7ff7; font-size: 13px;" class="pageNumber"></span>
</div>`;
// 对于大的PDF生成,可能会时间很久,这里规定不会进行超时处理
await page.setDefaultNavigationTimeout(0);
// 定义html内容
await page.setContent(this.HTMLStr, { waitUntil: "networkidle2" });
// 等待字体加载响应
await page.evaluateHandle("document.fonts.ready");
let pdfbuf = await page.pdf({
// 页面缩放比例
scale: 1,
// 是否展示页眉页脚
displayHeaderFooter: true,
// pdf存储单页大小
format: "a4",
// 页面的边距
// 页眉的模板
headerTemplate,
// 页脚的模板
footerTemplate,
margin: {
top: 50,
bottom: 50,
left: 0,
right: 0
},
// 输出的页码范围
pageRanges: "",
// CSS
preferCSSPageSize: true,
// 开启渲染背景色,因为 puppeteer 是基于 chrome 浏览器的,浏览器为了打印节省油墨,默认是不导出背景图及背景色的
// 坑点,必须加
printBackground: true,
});
// 关闭browser
await browser.close();
// 返回的是buffer不需要存储为pdf,直接将buffer传回前端进行下载,提高处理速度
return pdfbuf
} catch(e) {
await browser.close();
throw e
}
}
本文大概就总结这些内容,后面有时间的话会再次细化QAQ~
由于是公司项目,就不贴特别具体的代码和最终的效果展示了,如有疑问可以联系我~
参考文献
- Chrome DevTools Protocol
- Wiki Headless_browser
- 无头浏览器测试的优点和缺点
- 无头Chrome的工作原理
- 无头浏览器Puppeteer初探
- Puppeteer Github
- Linux中文字体安装
- ejs官方文档
- Chrome启动参数
如有疑问,欢迎添加我的个人微信:
