Pandas 基础使用教程(1)
![]()
Pandas 是非常著名的开源数据处理库,我们可以通过它完成对数据集进行快速读取、转换、过滤、分析等一系列操作。除此之外,Pandas 拥有强大的缺失数据处理与数据透视功能,可谓是数据预处理中的必备利器。这是 Pandas 使用教程的第 1 章节,将学会安装它,并了解 Pandas 的数据结构。
官方文档
下载官方文档(英文)
二、Pandas 安装
Linux:
sudo pip install pandas
Windows10:
pip install --upgrade pandas
三、 一维数据 Series
Series 是 Pandas 中最基本的 1 维数据形式。其可以储存整数、浮点数、字符串等形式的数据。Series 的新建方法如下:
s = pandas.Series(data, index=index)
其中,data 可以是字典、numpy 里的 ndarray 对象等。index 是数据索引,索引是 pandas 数据结构中的一大特性,它主要的功能是帮助我们更快速地定位数据,这一点后面会谈到。
3.1 字典 -> Series
将把不同类型的数据转换为为 Series。首先是字典类型。
import pandas as pd
d = {'a' : 10, 'b' : 20, 'c' : 30}
pd.Series(d)
这里,数据值是 10, 20, 30,索引为 a, b, c 。我们可以直接通过 index= 参数来设置新的索引。
d = {'a' : 10, 'b' : 20, 'c' : 30}
s = pd.Series(d, index=['b', 'c', 'd', 'a'])
s
你会发现,pandas 会自动匹配人为设定的索引值和字典转换过来的索引值。而当索引无对应值时,会显示为 NaN 缺失值。
3.2 ndarray -> Series
ndarray 是著名数值计算包 numpy 中的多维数组。我们也可以将 ndarray 直接转换为 Series。
import numpy as np
data = np.random.randn(5) # 一维随机数
index = ['a', 'b', 'c', 'd', 'e'] # 指定索引
s = pd.Series(data, index)
s
上面的两个例子中,我们都指定了 index 的值。而当我们非人为指定索引值时,Pandas 会默认从 0 开始设置索引值。
s = pd.Series(data)
s
当我们需要从一维数据 Series 中返回某一个值时,可以直接通过索引完成。
data = np.random.randn(5) # 一维随机数
index = ['a', 'b', 'c', 'd', 'e'] # 指定索引
s = pd.Series(data, index)
print(s)
print("------输出分割线------")
print(s['a'])
除此之外,Series 是可以直接进行运算的。例如:
data = np.random.randn(5) # 一维随机数
index = ['a', 'b', 'c', 'd', 'e'] # 指定索引
s = pd.Series(data, index)
print(s)
print("------输出分割线------")
print(2*s)
print("------输出分割线------")
print(s-s)
四、二维数据 DataFrame
DataFrame 是 Pandas 中最为常见、最重要且使用频率最高的数据结构。你可以想到它箱型为电子表格或 SQL 表具有的结构。DataFrame 可以被看成是以 Series 组成的字典。它和 Series 的区别在于,不但具有行索引,且具有列索引。
DataFrame 可以用于储存多种类型的输入:
- 一维数组、列表、字典或者 Series 字典。
- 二维 numpy.ndarray。
- 结构化的 ndarray。
- 一个 Series。
- 另一个 DataFrame。
4.1 Series 字典 -> DataFrame
# 带 Series 的字典
d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d) # 新建 DataFrame
df
我们可以看到,这里的行索引为 a, b, c, d ,而列索引为 one, two。
4.2 ndarrays 或 lists 字典 -> DataFrame
# 列表构成的字典
d = {'one' : [1, 2, 3, 4], 'two' : [4, 3, 2, 1]}
df1 = pd.DataFrame(d) # 未指定索引
df2 = pd.DataFrame(d, index=['a', 'b', 'c', 'd']) # 指定索引
print(df1)
print("------输出分割线------")
print(df2)
4.3 带字典的列表 -> DataFrame
# 带字典的列表
d = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(d)
df
4.4 DataFrame.from_ 方法
pandas 的 DataFrame 下面还有 4 个以 from_ 开头的方法,这也可以用来创建 Dataframe,它们分别是:
from_csv()from_dict()from_items()from_records()
d = [('A', [1, 2, 3]), ('B', [4, 5, 6])]
c = ['one', 'two', 'three']
df = pd.DataFrame.from_items(d, orient='index', columns=c)
df
4.5 列选择,添加,删除
接下来,我们延续上面的 4.4 里面的数据来演示。
在一维数据结构 Series 中,我们用 df['标签'] 来选择行。而到了二维数据 DataFrame 中,df['标签'] 表示选择列了。例如:
df['one']
删除列的方法为 df.pop('列索引名'),例如:
df.pop('one')
df
添加列的方法未 df.insert(添加列位置索引序号, '添加列名', 数值),例如:
df.insert(2, 'four', [10, 20])
df
五、三维数据 Panel
Panel 是 Pandas 中使用频率较低的一种数据结构,但它是三维数据的重要容器。
5.1 面板数据
Panel data 又称面板数据,它是计量经济学中派生出来的一个概念。在计量经济学中,数据大致可分为三类:截面数据,时间序列数据,以及面板数据。而面板数据即是截面数据与时间序列数据综合起来的一种数据类型。
简单来讲,截面数据指在某一时间点收集的不同对象的数据。而时间序列数据是指同一对象在不同时间点所对应的数据集合。
这里引用一个城市和 GDP 关系的示例来解释上面的三个概念(面板数据):
截面数据:
- 例如城市:北京、上海、重庆、天津在某一年的 GDP 分别为 10、11、9、8(单位亿元)。
时间序列数据:
- 例如:2000、2001、2002、2003、2004 各年的北京市 GDP 分别为 8、9、10、11、12(单位亿元)。
面板数据:
- 2000、2001、2002、2003、2004 各年中国所有直辖市的 GDP 分别为(单位亿元): 北京市分别为 8、9、10、11、12; 上海市分别为 9、10、11、12、13; 天津市分别为 5、6、7、8、9; 重庆市分别为 7、8、9、10、11。
5.2 Panel 构成
在 Pandas 中,Panel 主要由三个要素构成:
- items: 每个项目(item)对应于内部包含的 DataFrame。
- major_axis: 每个 DataFrame 的索引(行)。
- minor_axis: 每个 DataFrame 的索引列。
简而言之,在 Pandas 中,一个 Panel 由多个 DataFrame 组成。下面就生成一个 Panel。
wp = pd.Panel(np.random.randn(2, 5, 4), items=['Item1', 'Item2'], major_axis=pd.date_range('1/1/2000', periods=5), minor_axis=['A', 'B', 'C', 'D'])
wp
我们可以看到,wp 由 2 个项目、5 个主要轴和 4 个次要轴组成。其中,主要轴由 2000-01-01 到 2000-01-05 这 5 天组成的时间序列,次轴从 A 到 D。
你可以输出 Item1 看一看。
wp['Item1']
再看一看 Item2。
wp['Item2']
可以看到,这两个 Dataframe 的行索引及列索引是一致的。由于数据是随机生成的,所以不一致。
5.2 Panel
由于 Panel 在 Pandas 中的使用频率远低于 Series 和 DataFrame,所以 Pandas 决定在未来的版本中将 Panel 移除,转而使用 MultiIndex DataFrame 来表示多维数据结构。
这里,可以用到 Panel.to_frame() 输出多维数据结构。就拿上面的例子继续:
wp.to_frame()
你知道 Pandas 的名字是怎么来的吗?
答案:点击
https://www.shiyanlou.com/courses/906/labs/3375/document
Pandas 基础使用教程(2)- Pandas 常用的基本方法
1.4 官方文档
学习本课程之前,你可以先自行 下载官方文档(英文)作为辅助学习资料。
1.5 数据文件
学习本课程之前,请先打开在线环境终端,下载本文可能会用到的两个数据文件。
!wget http://labfile.oss.aliyuncs.com/courses/906/los_census.csv
!wget http://labfile.oss.aliyuncs.com/courses/906/los_census.txt
两个文件均为为洛杉矶人口普查数据,仅格式有区别。
下面的内容均在 iPython 交互式终端中演示,你可以通过在线环境左下角的应用程序菜单 > 附件打开。如果你在本地进行练习,推荐使用 Jupyter Notebook 环境。
二、Pandas 常见的基本方法
2.1 数据读取与存储
Pandas 支持大部分常见数据文件读取与存储。一般清楚下,读取文件的方法以 pd.read_ 开头,而写入文件的方法以 pd.to_ 开头。详细的表格如下。
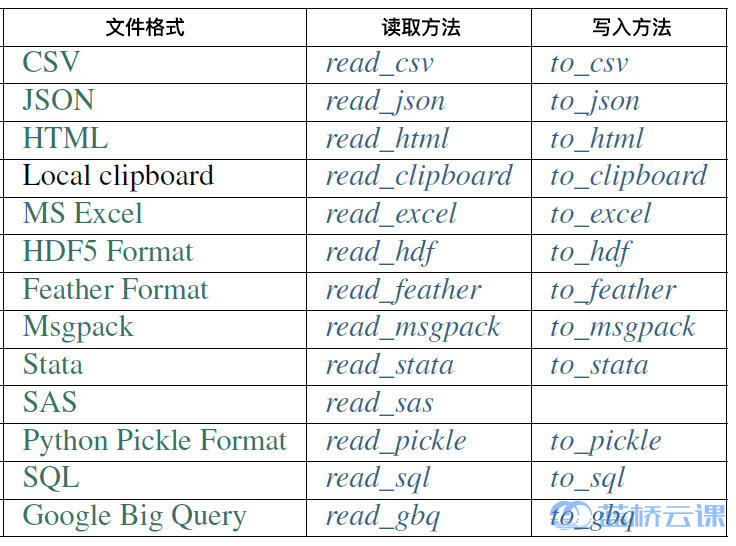
拿刚刚下载好的数据文件举例,如果没有下载,请看 1.5 小节。
import pandas as pd
pd.read_csv("los_census.csv") #读取 csv 文件
pd.read_table("los_census.txt") #读取 txt 文件
其实 los_census.txt 也就是 los_census.csv 文件,因为 csv 文件又叫逗号分隔符文件,数据之间采用逗号分割。
那么,我们怎样将这种文件转换为 DataFrame 结构的数据呢?这里就要使用到读取方法中提供的一些参数了,例如 sep[] 分隔符参数。
pd.read_table("los_census.txt", sep=',') #读取 txt 文件
除了 sep,读取文件时常用的参数还有:
header=,用来选择将第几行作为列索引名称。names=[],自定义列索引名称。
例如:
pd.read_csv("los_census.csv", header=1 ) #将第二行作为列索引名称。
pd.read_csv("los_census.csv", names=['A', 'B', 'C', 'D', 'E', 'F', 'G']) #自定义列索引名称。
好了,说了这么久的读取文件,再说一说存储文件。存储文件的方法也很简单。比如我们将 los_census.csv 文件,存储为 json 格式的文件。
df_los_census = pd.read_csv("los_census.csv") #读取 csv 文件
df_los_census.to_json("1.json") # 将其存储为 json 格式文件
!ls | grep json # 列出当前目录下的 json 文件
当然,你也可以通过 to_excel("1.xlsx") 储存为 Excel 默认支持的 .xlsx 格式。只是,需要注意在线环境会报错。这时候需要再补充安装 openpyxl 包就好了:
!sudo pip install openpyxl
2.2 Head & Tail
有些时候,我们读取的文件很大。如果全部输出预览这些文件,既不美观,又很耗时。还好,Pandas 提供了 head() 和 tail() 方法,它可以帮助我们只预览一小块数据。
顾名思义,head() 方法就是从数据集开头预览,不带参数默认显示头部的 5 条数据,你也可以自定义显示条数。
df_los_census.head() # 默认显示前 5 条
df_los_census.head(7) # 显示前 7 条
tail() 方法就是从数据集尾部开始显示了,同样默认 5 条,可自定义。
df_los_census.tail() # 默认显示后 5 条
df_los_census.tail(7) # 显示后 7 条
2.3 统计方法
Pandas 提供了几个统计和描述性方法,方便你从宏观的角度去了解数据集。
1. describe()
describe() 相当于对数据集进行概览,会输出该数据集的计数、最大值、最小值等。
df_los_census.describe()
例如上面,针对一个 DataFrame 会对每一列的数据单独统计。
2. idxmin() & idxmax()
idxmin() 和 idxmax() 会计算最小、最大值对应的索引标签。
df_los_census.idxmin()
df_los_census.idxmax()
3. count()
count() 用于统计非空数据的数量。
df_los_census.count()
4.value_counts()
value_counts() 仅仅针对 Series,它会计算每一个值对应的数量统计。
import numpy as np
s = pd.Series(np.random.randint(0, 9, size=100)) # 生成一个 Series,并在 0-9 之间生成 100 个随机值。
print(s)
print('------分割线------')
print(s.value_counts())
2.4 计算方法
除了统计类的方法,Pandas 还提供了很多计算类的方法。
1. sum()
sum() 用于计算数值数据的总和。
df_los_census.sum()
2. mean()
mean() 用于计算数值数据的平均值。
df_los_census.mean()
3. median()
median() 用于计算数值数据的算术中值。
df_los_census.median()
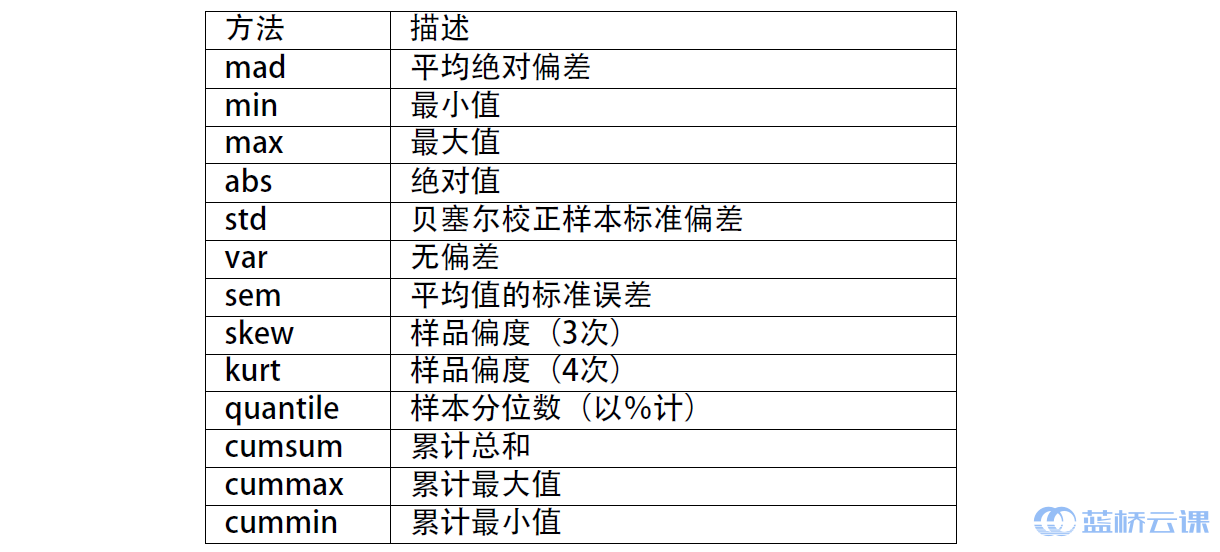
除此之外,剩下的一些常见计算方法如下表所示。
2.5 标签对齐
索引标签是 Pandas 中非常重要的特性,有些时候,由于数据的缺失等各种因素导致标签错位的现象,或者想匹配新的标签。于是 Pandas 提供了索引标签对齐的方法 reindex()。
reindex() 主要有三个作用:
- 重新排序现有数据以匹配新的一组标签。
- 在没有标签对应数据的位置插入缺失值(NaN)标记。
- 特殊情形下,使用逻辑填充缺少标签的数据(与时间序列数据高度相关)。
s = pd.Series(data=[1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
print(s)
print('------分割线------')
print(s.reindex(['e', 'b', 'f', 'd']))
我们可以看到,重新排列的数据中,原有索引对应的数据能自动匹配,而新索引缺失的数据通过 NaN 补全。
当然,对于 DataFrame 类型的数据也是一样的。
df = pd.DataFrame(data={'one': [1, 2, 3], 'two': [4, 5, 6], 'three': [7, 8, 9]}, index=['a', 'b', 'c'])
df
df.reindex(index=['b', 'c', 'a'], columns=['three', 'two', 'one'])
你甚至还可以将上面 Series 的数据按照下面的 DataFrame 的索引序列对齐。
s.reindex(df.index)
2.6 排序
既然是数据处理,就少不了排序这一常用的操作。在 Pandas 中,排序拥有很多「姿势」,下面就一起来看一看。
1. 按索引排序
首先是按照索引排序,其方法为Series.sort_index()或者是DataFrame.sort_index()。
df = pd.DataFrame(data={'one': [1, 2, 3], 'two': [4, 5, 6], 'three': [7, 8, 9], 'four': [10, 11, 12]}, index=['a', 'c', 'b'])
df
下面按索引对行重新排序:
df.sort_index()
或者添加参数,进行倒序排列:
df.sort_index(ascending=False)
1. 按数值排序
第二种是按照数值排序,其方法为Series.sort_values()或者是DataFrame.sort_values()。举个例子:
df = pd.DataFrame(data={'one': [1, 2, 3, 7], 'two': [4, 5, 6, 9], 'three': [7, 8, 9, 2], 'four': [10, 11, 12, 5]}, index=['a', 'c', 'b','d'])
df
将第三列按照从小到大排序:
df.sort_values(by='three')
也可以同时按照两列:
df[['one', 'two', 'three', 'four']].sort_values(by=['one','two'])
Pandas 基础使用教程(3)- Pandas 数据选择与过滤
1.5 数据文件
学习本课程之前,请先打开在线环境终端,下载本文可能会用到的两个数据文件。
!wget http://labfile.oss.aliyuncs.com/courses/906/los_census.csv
los_census.csv 为为洛杉矶人口普查数据,仅格式有区别。
下面的内容均在 iPython 交互式终端中演示,你可以通过在线环境左下角的应用程序菜单 > 附件打开。如果你在本地进行练习,推荐使用 Jupyter Notebook 环境。
二、数据选择
在数据预处理过程中,我们往往会对数据集进行切分,只将需要的某些行、列,或者数据块保留下来,输出到下一个流程中去。这也就是这里所说的数据选择。
由于 Pandas 的数据结构中存在索引、标签,所以我们可以通过多轴索引完成对数据的选择。
2.1 基于索引数字选择
当我们新建一个 DataFrame 之后,如果未自己指定行索引或者列对应的标签,那么 Pandas 会默认从 0 开始以数字的形式作为行索引,并以数据集的第一行作为列对应的标签。其实,这里的「列」也有数字索引,默认也是从 0 开始,只是未显示出来。
所以,我们首先可以基于数字索引对数据集进行选择。这里用到的 Pandas 中的 .iloc 方法。该方法可以接受的类型有:
- 整数。例如:
5 - 整数构成的列表或数组。例如:
[1, 2, 3] - 布尔数组。
- 可返回索引值的函数或参数。
下面,我们还是用 los_census.csv 数据集演示该方法的使用。如果未下载该数据集,请看 1.5 节。
import pandas as pd
df = pd.read_csv("los_census.csv")
df.head()
首先,我们可以选择前 3 行数据。这和 python 或者 numpy 里面的切片很相似。
df.iloc[:3]
我们还可以选择特定的一行。
df.iloc[5]
那么选择多行是不是 print df.iloc[1, 3, 5] 这样呢?答案是错误的。df.iloc[] 的 [[行],[列]] 里面可以同时接受行和列的位置,如果你直接键入 df.iloc[1, 3, 5] 就会报错。
所以,很简单。如果你想要选择 1,3,5 行,可以这样做。
df.iloc[[1, 3, 5]]
选择行学会以后,选择列就应该能想到怎么办了。你可以先暂停浏览下面的内容,自己试一试。
例如,我们要选择第 2-4 列。
df.iloc[:, 1:4]
这里选择 2-4 列,输入的却是 1:4。这和 python 或者 numpy 里面的切片操作非常相似。
既然我们能定位行和列,那么只需要组合起来,我们就可以选择数据集中的任何一块数据了。
2.2 基于标签名称选择
除了根据数字索引选择,我们还可以直接根据标签对应的名称选择。这里用到的方法和上面的 iloc 很相似,少了个 i 为 df.loc[]。
df.loc[] 可以接受的类型有:
- 单个标签。例如:
2或'a',这里的2指的是标签而不是索引位置。 - 列表或数组包含的标签。例如:
['A', 'B', 'C']。 - 切片对象。例如:
'A':'E',注意这里和上面切片的不同支持,首位都包含在内。 - 布尔数组。
- 可返回标签的函数或参数。
下面,我们来演示 df.loc[] 的用法。我们先随机生成一个 DataFrame。
import numpy as np # 加载 numpy 模块
df = pd.DataFrame(np.random.randn(6,5),index=list('abcdef'),columns=list('ABCDE'))
df
先选择前 3 行:
df.loc['a':'c']
再选择 1,3,5 行:
df.loc[['a', 'c', 'd']]
然后,选择 2-4 列:
df.loc[:, 'B':'D']
最后,选择 1,3 行和 C 后面的列:
df.loc[['a','c'], 'C':]
2.3 数据随机取样
上面,的 .iloc 和 .loc 可用于精准定位数据块。而 Pandas 同样也提供了随机取样的方法,用于满足各种情况。随机取样用 .sample() 完成,下面我们就演示一下它的用法。
首先,看一看 Series 数据结构。
s = pd.Series([0,1,2,3,4,5,6,7,8,9])
s.sample()
我们可以看到,默认情况下 .sample() 返回了一个数值。注意,前面的 2 是数字索引,后面的 2 才是值。
我们可以通过 n= 参数,设定返回值的数量。
s.sample(n=5)
同样也可以用 frac= 参数设定返回数量的比例。
s.sample(frac=.6) # 返回 60% 的数值
对应 DataFrame 而言,过程也很相似,只是需要选择坐标轴。举个例子:
☞ 示例代码:
df = pd.DataFrame(np.random.randn(6,5),index=list('abcdef'),columns=list('ABCDE'))
df.sample(n=3)
默认会返回行,如果要随机返回 3 列。需要添加 axis= 参数。
df.sample(n=3, axis=1)
2.4 条件语句选择
数据选择的时候,我们还可以加入一些条件语句,从而达到对数据筛选的目的。这个过程和 numpy 里面的效果很相似。我们先举一个 Series 的例子:
s = pd.Series(range(-5, 5))
s
s[(s < -2) | (s > 1)] # 添加 逻辑或 条件
对于 DataFrame 也是相似的。
df = pd.DataFrame(np.random.randn(6,5),index=list('abcdef'),columns=list('ABCDE'))
df
df[(df['B'] > 0) | (df['D'] < 0)] # 添加条件
2.5 where() 方法选择
接下来,再介绍一种通过 where() 方法进行数据选择得方法。DataFrame 和 Series 都带有 where(),可以通过一些判断句来选择数据。举个例子:
df = pd.DataFrame(np.random.randn(6,5),index=list('abcdef'),columns=list('ABCDE'))
df
df.where(df < 0) # 添加条件
.where(df < 0) 会返回所有负值,而非负值就会被置为空值 NaN。 你也可以对判断条件以外得值重新替代,例如这里将非负值全部变号为负值。
df.where(df < 0, -df) # 筛选负值并将正值变号
故,where() 实际上期待了匹配和替换得效果。我们可以借助该方法实现对数据的自由设定。
2.6 query() 方法选择
针对数据变换和筛选的方法还很多,除了上面的提到的,Pandas 0.13 之后的版本中增加了 query() 实验性方法,该方法也可以被用来选择数据。
query() 是 DataFrame 具有的方法,你可以通过一个比较语句对满足行列条件的值进行选择,举个例子:
df = pd.DataFrame(np.random.rand(10, 5), columns=list('abcde'))
df
df.query('(a < b) & (b < c)') # 添加 逻辑与 条件
上面的判断语句应该很容易看明白,也就是满足 a 列的值需小于 b 列,且 b 列的值小于 c 列所在的行。
当然,在没有 query() 之前,我们也是可以通过前面提到的条件语句选择。
df[(df.a < df.b) & (df.b < df.c)]
结果虽然一致,但是 query() 语句的确要简洁和自然很多。query() 包含很多内容,非常强大。你可以通过官方文档了解,这里就不再赘述了。
针对数据集的处理,无外乎就是变换、筛选,最终得到我们想要的数据。
Pandas 基础使用教程(4)- Pandas 进行缺失值处理
二、认识缺失值
在真实的生产环境中,我们需要处理的数据文件往往没有想象中的那么美好。其中,很大几率会遇到的情况就是缺失值。
2.1 什么是缺失值?
缺失值主要是指数据丢失的现象,也就是数据集中的某一块数据不存在。除此之外、存在但明显不正确的数据也被归为缺失值一类。例如,在一个时间序列数据集中,某一段数据突然发生了时间流错乱,那么这一小块数据就是毫无意义的,可以被归为缺失值。
当然,除了原始数据集就已经存在缺失值以外。当我们用到前面章节中的提到的索引对齐(reindex())的方法时,也容易人为导致缺失值的产生。举个例子:
首先,我们生成一个 DataFrame。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(5, 5), index=list('cafed'),columns=list('ABCDE'))
df
然后,我们使用 reindex()` 完成索引对齐。
df.reindex(list('abcde'))
由于原始数据集中,没有索引 b,所以对齐之后,b 后面全部为缺失值,也就造成了数据缺失。
2.2 检测缺失值
Pandas 为了更方便地检测缺失值,将不同类型数据的缺失均采用 NaN 标记。这里的 NaN 代表 Not a Number,它仅仅是作为一个标记。例外是,在时间序列里,时间戳的丢失采用 NaT 标记。
Pandas 中用于检测缺失值主要用到两个方法,分别是:isnull() 和 notnull(),故名思意就是「是缺失值」和「不是缺失值」。默认会返回布尔值用于判断。
下面,演示一下这两个方法的作用,我们这里沿用上面进行索引对齐后的数据。
df2 = df.reindex(list('abcde'))
df2.isnull()
df2.notnull()
然后,我们来看一下对时间序列缺失值的检测,对上面的 df2 数据集进行稍微修改。
# 插入 T 列,并打上时间戳
df2.insert(value=pd.Timestamp('2017-10-1'),loc=0,column='T')
# 将 T 列的 1,3,5 行置为缺失值
df2.loc[['a','c','e'],['T']] = np.nan
这里,我们也更清晰看到,时间序列的缺失值用 NaT 标记。我们对 df2 进行缺失值检测。
df2.isnull()
df2.notnull()
三、填充和清除缺失值
上面已经对缺省值的产生、检测进行了介绍。那么,我们面对缺失值时,到底有哪些实质性的措施呢?接下来,就来看一看如何完成对缺失值填充和清除。
填充和清除都是两个极端。如果你感觉有必要保留缺失值所在的列或行,那么就需要对缺失值进行填充。如果没有必要保留,就可以选择清除缺失值。
Pandas 中,填充缺失的方法为 fillna(),清除为 dropna()。
3.1 填充缺失值 fillna()
首先,我们看一看 fillna() 的使用方法。重新打开一个 ipython 终端,我们生成和上面相似的数据。
df = pd.DataFrame(np.random.rand(9, 5), columns=list('ABCDE'))
# 插入 T 列,并打上时间戳
df.insert(value=pd.Timestamp('2017-10-1'),loc=0,column='Time')
# 将 1, 3, 5 列的 1,3,5 行置为缺失值
df.iloc[[1,3,5,7], [0,2,4]] = np.nan
# 将 2, 4, 6 列的 2,4,6 行置为缺失值
df.iloc[[2,4,6,8], [1,3,5]] = np.nan
我们用相同的标量值替换 NaN,比如用 0。
df.fillna(0)
注意,这里的填充并不会直接覆盖原数据集,你可以重新输出 df 比较结果。
除了直接填充值,我们还可以通过参数,将缺失值前面或者后面的值填充给相应的缺失值。例如使用缺失值前面的值进行填充:
df.fillna(method='pad')
或者是后面的值:
df.fillna(method='bfill')
最后一行由于没有对于的后序值,自然继续存在缺失值。
上面的例子中,我们的缺失值是间隔存在的。那么,如果存在连续的缺失值是怎样的情况呢?试一试。首先,我们将数据集的第 2,4 ,6 列的第 3,5 行也置为缺失值。
df.iloc[[3,5], [1,3,5]] = np.nan
然后来正向填充:
df.fillna(method='pad')
可以看到,连续缺失值也是按照前序数值进行填充的,并且完全填充。这里,我们可以通过 limit= 参数设置连续填充的限制数量。
df.fillna(method='pad', limit=1)
除了上面的填充方式,还可以通过 Pandas 自带的求平均值方法等来填充特定列或行。举个例子:
df.fillna(df.mean()['C':'E'])
对 C 列和 E 列用平均值填充。
3.2 清除缺失值 dropna()
上面演示了缺失值填充。但有些时候,缺失值比较少或者是填充无意义时,就可以直接清除了。
由于填充和清除在赋值之前,均不会影响原有的数据。所以,我们这里依旧延续使用上面的 df。
df.dropna()
我们可以看到,dropna() 方法带来的默认效果就是,凡是存在缺失值的行均被直接移除。此时,dropna() 里面有一个默认参数是 axis=0,代表依据行来移除。
如果我们像将凡是有缺失值的列直接移除,可以将 axis=1,试一试。☞ 示例代码:
df.dropna(axis=1)
由于上面的 df 中,每一列都有缺失值,所以全部被移除了。
四、插值 interpolate()
插值是数值分析中一种方法。简而言之,就是借助于一个函数(线性或非线性),再根据已知数据去求解未知数据的值。插值在数据领域非常常见,它的好处在于,可以尽量去还原数据本身的样子。
Pandas 中的插值,通过 interpolate() 方法完成,默认为线性插值,即 method='linear'。除此之外,还有{‘linear’, ‘time’, ‘index’, ‘values’, ‘nearest’, ‘zero’, ‘slinear’, ‘quadratic’, ‘cubic’, ‘barycentric’, ‘krogh’, ‘polynomial’, ‘spline’, ‘piecewise_polynomial’, ‘from_derivatives’, ‘pchip’, ‘akima’}等插值方法可供选择。
举个例子:
# 生成一个 DataFrame
df = pd.DataFrame({'A': [1.1, 2.2, np.nan, 4.5, 5.7, 6.9], 'B': [.21, np.nan, np.nan, 3.1, 11.7, 13.2]})
df
对于上面存在的缺失值,如果通过前后值,或者平均值来填充是不太能反映出趋势的。这时候,插值最好使。我们用默认的线性插值试一试。
df_interpolate = df.interpolate()
df_interpolate
如果你熟悉 Matplotlib,我们可以将数据绘制成图看一看趋势。
%matplotlib inline
from matplotlib import pyplot as plt
plt.style.use('ggplot')
df_interpolate.plot(
x='A',
y='B'
)
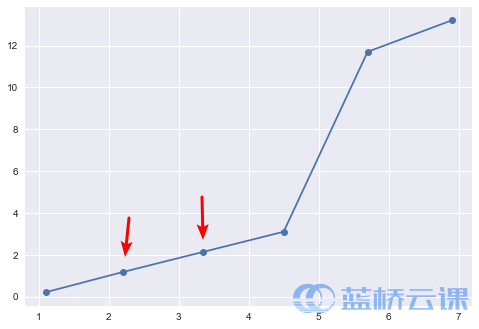
图中,第 2,3 点的坐标是我们插值的结果。
上面提到了许多插值的方法,也就是 method=。下面给出几条选择的建议:
- 如果你的数据增长速率越来越快,可以选择
method='quadratic'二次插值。 - 如果数据集呈现出累计分布的样子,推荐选择
method='pchip'。 - 如果需要填补缺省值,以平滑绘图为目标,推荐选择
method='akima'。
当然,最后提到的 method='akima',需要你的环境中安装了 Scipy 库。除此之外,method='barycentric' 和 method='pchip' 同样也需要 Scipy 才能使用。
本章节学习了如何通过 Pandas 处理数据集中的缺失值。并了解了检测缺失值、填充缺失值、清除缺失值以及相关的插值方法。当然,这些内容相对于强大的 Pandas 而言仅仅是开始,每一种方法都还包含很多参数。入门之后,需要通过官方文档来学习更高阶的使用方法。
六、课后作业
自己尝试生成一个 DataFrame,并制造一些零散的缺失值。最后,通过不同的插值方法完成缺失值的填充。
Pandas 基础使用教程(5)- Pandas 时间序列分析
1.2 实验知识点
- 时间戳 Timestamp
- 时间索引 DatetimeIndex
- 时间转换 to_datetime
- 时间序列检索
- 时间序列计算
二、时间序列分析介绍
2.1 简介
时间序列(英语:time series)是实证经济学的一种统计方法,它是采用时间排序的一组随机变量,国内生产毛额(GDP)、消费者物价指数(CPI)、股价指数、利率、汇率等等都是时间序列。时间序列的时间间隔可以是分秒(如高频金融数据),可以是日、周、月、季度、年、甚至更大的时间单位。[维基百科]
我们针对时间序列数据进行挖掘的过程又被成为时间序列分析,简称:时序分析。
2.2 常见问题
Pandas 经常被用于处理与时间序列相关的数据,尤其是像财务数据。在处理时间序列数据时,会遇到各类需求,包括但不限于:
- 生成固定跨度的时期构成时间序列。
- 将现有的时间序列,转换成需要的时间序列格式。
- 计算序列中的相对时间,例如:每季度的第一周。
三、Pandas 处理时间序列
接下来,我们就时间序列中常遇到的一些需求类型,列举一些示例,并使用 Pandas 提供的方法进行处理。
3.1 时间戳 Timestamp
既然是时间序列类型的数据,那么就少不了时间戳这一关键元素。Pandas 中,我们有两个创建时间戳的方法,分别是:to_datatime和 Timestamp。
to_datatime 后面集中详说。首先看一看 Timestamp,它针对于单一标量,举个例子:
import pandas as pd
pd.Timestamp('2017-10-01')
如果要包含小时:分钟:秒:
pd.Timestamp('2017-10-01 13:30:59')
当然,还支持其他的格式输入,比如:
pd.Timestamp('1/10/2017 13:30:59')
3.2 时间索引 DatetimeIndex
在实际工作中,我们很少遇到用单个时间戳的情况。而大多数时候,是使用由时间戳构成的时间索引。
首先,我们来看一下如何使用 Pandas 创建时间索引。这里用到的方法为 date_range(),date_range() 和 python 自带的 range() 很相似。它可以用来创建一系列等间距时间,并作为 Series 或者 DataFrame 的索引。
date_range() 方法带有的默认参数如下:
pandas.date_range(start=None, end=None, periods=None, freq=’D’, tz=None, normalize=False,
name=None, closed=None, **kwargs)
常用参数的含义如下:
start=:设置起始时间end=:设置截至时间periods=:设置时间区间,若None则需要设置单独设置起止和截至时间。freq=:设置间隔周期,默认为D,也就是天。可以设置为小时、分钟、秒等。tz=:设置时区。
举个例子:
pd.date_range('1/10/2017', periods=24, freq='H')
可以这样:
pd.date_range('1/10/2017', periods=10, freq='D')
我们可以发现 freq= 参数的特点:
freq='s': 秒freq='min': 分钟freq='H': 小时freq='D': 天freq='w': 周freq='m': 月
除了上面这些参数值,还有一些特别的:
freq='BM': 每个月最后一天freq='W':每周的星期日
如果你想同时按天、小时更新,也是可以的。但需要像下面这样设置参数值:
pd.date_range('1/10/2017', periods=20, freq='1H20min')
所以,只要适当地组合,你可以生成任意想要的时间序列索引。
3.3 时间转换 to_datatime
to_datatime 是 Pandas 用于处理时间序列时的一个重要方法,它可以将实参转换为时间戳。to_datatime 包含的默认参数如下:
pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, box=True, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix')
arg:可以接受整数、浮点数、字符串、时间、列表、元组、一维数组、Series 等。errors=:默认为raise,表示遇到无法解析数据将会报错。还可以设置为coerce,表示无法解析设为NaT,或者设为ignore忽略错误。dayfirst=:表示首先解析日期,例如:1/10/17被解析为2017-10-1。yearfirst=:表示首先解析年,例如:1/10/17被解析为2001-10-17。utc=:返回UTC格式时间索引。box=:True表示返回时间索引DatatimeIndex,False表示返回多维数组ndarray。format=:时间解析格式,例如:%d /%m /%Y。
对于 to_datatime 的返回值而言:
- 输入列表,默认返回时间索引
DatetimeIndex。 - 输入
Series,默认返回datetime64的Series。 - 输入标量,默认返回时间戳
Timestamp。
下面,针对输入数据类型的不同,我们来看一看 to_datatime 的不同用法。
3.3.1 输入标量
pd.to_datetime('1/10/2017 10:00', dayfirst=True)
3.3.2 输入列表
pd.to_datetime(['1/10/2017 10:00','2/10/2017 11:00','3/10/2017 12:00'])
3.3.2 输入 Series
pd.to_datetime(pd.Series(['Oct 11, 2017', '2017-10-2', '3/10/2017']), dayfirst=True)
3.3.2 输入 DataFrame
pd.to_datetime(pd.DataFrame({'year': [2017, 2018], 'month': [9, 10], 'day': [1, 2], 'hour': [11, 12]}))
3.3.2 errors=
接下来,看一看 errors= 遇到无法解析的数据时,所对应的不同返回值。这个参数对于我们解析大量数据时非常有用。
pd.to_datetime(['2017/10/1', 'abc'], errors='raise')
如果对错误不处理,这里会出现 ValueError: Unknown string format 的报错信息。
# 忽略错误
pd.to_datetime(['2017/10/1', 'abc'], errors='ignore')
# 错误设置为 NaT
pd.to_datetime(['2017/10/1', 'abc'], errors='coerce')
3.4 时间序列检索
上面,我们介绍了时间索引 DatetimeIndex 的生成方法。那么,它主要是用来做什么呢?
答案当然是 Pandas 对象的索引啦。将时间变成索引的优点非常多,包含但不限于:
- 查找和检索特定日期的字段非常快。
- 进行数据对齐时,拥有相同时间间隔的索引的数据将会非常快。
- 可以很方便地通过 shift 和 ishift 方法快速移动对象。
下面,针对时间序列索引的检索等操作举几个例子。首先,我们生成 10 万条数据:
import numpy as np
ts = pd.DataFrame(np.random.randn(100000,1), columns=['Value'], index=pd.date_range('20170101', periods=100000, freq='T'))
ts
☞ 动手练习:
当我们对数据进行快速检索是,其实和除了 Series 和 DataFrame 数据别无二致。例如:
检索 2017 年 3 月 2 号的数据:
ts['2017-3-2']
一共 1440 行。 检索 2017 年 3 月 3 号下午 2 点到 5 点 23 分之间的数据:
ts['2017-3-2 14:00:00':'2017-3-2 17:23:00']
一共返回了 204 行。 总之,一切在 Series 和 DataFrame 上可以用的数据选择与定位的方法,像 iloc(), loc() 等均可以用于时间序列,这里就不再赘述了。
3.5 时间序列计算
在 Pandas 中,包含有很多可以被加入到时间序列计算中去的类,这些被称为 Offsets 对象。
关于这一点,我们举出几个例子就一目了然了。例如:
from pandas.tseries import offsets # 载入 offsets
dt = pd.Timestamp('2017-10-1 10:59:59')
dt + offsets.DateOffset(months=1, days=2, hour=3) # 增加时间
又或者我们减去 3 个周的时间:
dt - offsets.Week(3)
看明白了吧。这类的对象非常多,就不再一一演示,通过表格列举如下:
3.6 其他方法
最后,再介绍几个与时间序列处理相关的方法。
移动 Shifting
shifting 可以将数据或者时间索引沿着时间轴的方向前移或后移,举例如下:
ts = pd.DataFrame(np.random.randn(7,2), columns=['Value1','Value2' ], index=pd.date_range('20170101', periods=7, freq='T'))
ts
接下来开始移动。
ts.shift(3)
默认是数据向后移动。这里数据值向后移动了 3 行。
ts.shift(-3)
可以通过添加负号,使得向前移动。
那么,想移动索引怎么办?这里使用 tshift()。
ts.tshift(3)
向前移动索引就不再演示了,同样可以通过负号完成。除此之外,shift() 是可以接受一些参数的,比如 freq=''。而这里的 freq='' 参数和上文在介绍 时间索引 DatetimeIndex 时提到的一致。
举个例子:
ts.shift(3, freq='D') # 日期向后移动 3 天
所以说,shifting 可以让我们更加灵活地去操作时间序列数据集,完成数据对齐等目标。
重采样 Resample
重采样,即是将时间序列从一个频率转换到另一个频率的过程。实施重采样的情形如下:
- 有时候,我们的时间序列数据集非常大,比如百万级别甚至更高。如果将全部数据用于后序计算,其实很多情况下是没有必要的。此时,我们可以对原有的时间序列进行降频采样。
- 除了上面的情形,重采样还可以被用于数据对齐。比如,两个数据集,但是时间索引的频率不一致,这时候,可以通过重采样使二者频率一致,方便数据合并、计算等操作。
下面,我们看一看 resample() 的使用。首先,还是生成一个数据集。
# 生成一个时间系列数据集
ts = pd.DataFrame(np.random.randn(50,1), columns=['Value' ], index=pd.date_range('2017-01', periods=50, freq='D'))
ts
首先,可以升频采样,间隔变成小时。但是,由于间隔变小,我们就必须对新增加的行进行填充。
ts.resample('H').ffill()
下面,接着开始降频采样,从 1 天变成 5 天:
ts.resample('5D').sum()
四、实验总结
本章节介绍了利用 Pandas 对时间序列数据进行处理的一些手段,重点演示了时间索引的构建、时间索引转换以及移动、重采样等方法。当然,文中对这些方法的介绍依然还不够细致。如果你需要在实际工作中进行数据处理,还需要对照官方文档熟悉每一个方法的每一个参数的使用,这样才能发挥出 Pandas 的强大作用。