数据库DDL
1.创建库的语法
CREATE DATABASE [IF NOT EXISTS] database_name [IF NOT EXISTS] --增强代码的健壮性
[COMMENT database_comment] --这个库是干嘛的
[LOCATION hdfs_path] --你当前的库存储的hdfs路径
[WITH DBPROPERTIES (property_name=property_value, ...)]; --一点用没有(鸡肋)
create database db_hive
comment 'this in my first db'
2.创建数据库: (增)
创建一个数据库,指定数据库在HDFS上存放的位置
hive (default)> create database db_hive2 location '/db_hive2';
--在你不指定的location的情况下 默认在你的hdfs/user/hive/warehouse下创建一个以database_name.db名的文件夹 来当做库
--在你指定location的情况下 拿最后一级目录当做库的名字
3.过滤显示查询的数据库: (查)
hive> show databases like 'db_hive*';
OK
db_hive
db_hive_1
显示数据库信息:
hive> desc database extended db_hive;
OK
db_hive hdfs://hadoop102:8020/user/hive/warehouse/db_hive.db atguiguUSER
4.改
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
alter database db_hive set dbproperties('dbtype'='db'); --修改原来的属性
alter database db_hive set dbproperties('createtime'='2020-08-19'); --增加原来的属性
所以其实数数据库的属性就是为了凑一个改的效果,并不怎么用
5.删
drop database if exists db_hive2; --加上 if exists 增加代码的健壮性
drop database db_hive cascade; --强制删除 (当你库下面有表的时候) 慎用(只有你确定所有表都没用的时候)
表DDL
创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
--external表示创建的表是否为外部表,内外部表的效果底下介绍
[(col_name data_type [COMMENT col_comment], ...)]
--列名--列的类型 --列的注释(列拿来干什么的)
例子: create table test (age int comment 'agemean');
可能会有问题的是,这里为什么列名和列的类型都是可选项,因为我们可以用底下写的模范命令(as,like)来模仿一个数据库,这样原本数据库的列的架构就是可选项了。!!!
=================================================================================
[COMMENT table_comment] --表的注释 这个表拿来干嘛的
=================================================================================
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] --分区表
[CLUSTERED BY (col_name, col_name, ...) --分桶表
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] --桶内分通字段,桶内以什么排序
注:后面在出文章写!!!
=================================================================================
[
ROW FORMAT DELIMITED
--这行数据分隔符
[FIELDS TERMINATED BY char] --!!!
--字段分隔符
-- songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing_10010 字段分隔符是 ','
--有默认值 默认值是 ascii 码表 0001 ^A ctrl+v ctrl+a
[COLLECTION ITEMS TERMINATED BY char]
--集合(map array struct)分隔符
--bingbing_lili xiao song:18_xiaoxiao song:19 hui long guan_beijing_10010 分隔符是'_'
--有默认值 默认值是 ascii 码表 0010 ^B ctrl+v ctrl+b
[MAP KEYS TERMINATED BY char]
--map的kv分隔符
--xiao song:18 分隔符是 ':'
--有默认值 默认值是 ascii 码表 0100 ^C ctrl+v ctrl+c
[LINES TERMINATED BY char]
--行分隔符 默认值是 '\n'
]
注:举例:
create table test(
name string,
friends array,
children map<string, int>,
address structstreet:string,city:string,email:int
)
row format delimited fields terminated by ‘,’
collection items terminated by ‘_’
map keys terminated by ‘:’
lines terminated by ‘\n’;
数据为:
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing_10010
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing_10011
=================================================================================!!!
[STORED AS file_format] --当前创建的表存储格式 --比如表可以以压缩文件存储,默认是textfile
=================================================================================!!!
[LOCATION hdfs_path] --当前表的hdfs存储路径 注:此时路径填的是目录也就是文件夹,为什么不能是文件呢
因为如果是文件的话,就相当于这个表就是这个文件,而我们后续还需要对表进行一些增加的操作,就没法实现了。
=================================================================================
[TBLPROPERTIES (property_name=property_value, ...)] --表的属性 这个用处比较大
=================================================================================
[AS select_statement] --根据查询结果创建一张表 会带表的结构和数据,但是不会带分割方式
如:create table test1 as select * from stu; 速度慢因为要走MR,重新创建了一张表,使用默认的分割方式
注:不能与[(col_name data_type [COMMENT col_comment], ...)]同时使用
[LIKE table_name] --模仿一张表 只模仿表结构但是没有模仿表的数据
如: create table test2 like test1; 速度快
管理表(增)
增加内部表(管理表)
内部表的含义:hive掌握着表的数据的生命周期,当在Hive里删除表的时候,会一并把hdfs上数据给删了,用的较少,一般为 1.中间表 2.测试表
补充:默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
–内部表测试
create table student(id int, name string)
row format delimited fields terminated by ‘\t’
–默认分隔符测试
create table test2(id int, name string)
–根据查询结构创建一张表 它虽然会带表结构和数据 但是分隔符不会带 会使用默认值^A
create table student2 as select * from student;
–根据查询结构创建一张表 他的分隔符跟模仿表的是一样的
create table student3 row format delimited fields terminated by ‘\t’ as select * from student;
–根据存在的表的结构来创建一张表 拿不到数据 --他的分隔符跟模仿表的是一样的
create table student4 like student;
增加外部表
外部表的含义:hive不掌握着表的数据生命周期,当在Hive里删除表的时候,不会一并把hdfs上数据给删了,只会删除元数据
除了上述内部表的情况 全是外部表
create external table if not exists dept(
deptno int,
dname string,
loc int)
row format delimited fields terminated by '\t'
location '/company/dept';
解释:也就是说表的内容我们可以通过往dept目录中传文件来改变,并且这张表被删除的时候,对应的表路径目录并不会删除
内部表和外部表相互转换
Table Type: EXTERNAL_TABLE
Table Parameters: EXTERNAL TRUE
表是否为内部表还是外部表是由Table Parameters 里面的EXTERNAL属性来控制 包括TRUE和FALSE 都得大写
--内部表转换成外部表
alter table student4 set tblproperties('EXTERNAL'='TRUE');
--外部表转成内部表
alter table emp set tblproperties('EXTERNAL'='FALSE'); 注:这里是区分大小写,为固定写法
查(表)
--展示库下面的所有表
show tables;
--描述表
desc student;
--描述表的详情
desc formatted student; 可以通过查看表详情来看是否是外部表,以计表中数据文件的数目(元数据),比如通过hadoop直接上传文件就不会走元数据,则这里查出的fils数目不会改变
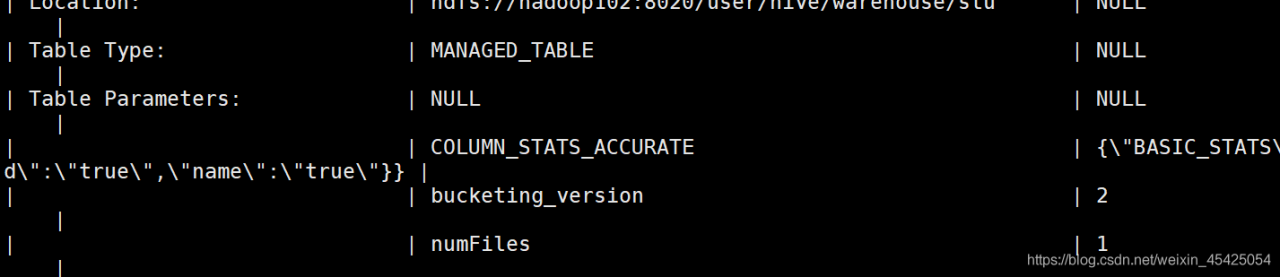
这里MANAGED_TABLE表示为内部表,numFiles为地址内的文件数,通过hadoop直接上传文件就不会走元数据,则这里查出的fils数目不会改变
删(表)
1.1 删除内部表
drop table student;
1.2 删除外部表
drop table dept; --只能删除元数据 不能删除hdfs上的数据
1.3 清空表
truncate table student3;
清空外部表测试 --也是不能清空外部表
truncate table emp;
改(表)
--改表名 会连同你的hdfs文件夹名字一起改掉
alter table student3 rename to student2;
--更新列 注意改的列的数据类型 只能由小往大改 或者不变
**顺序按hive的类型转化来,但是string比float大**
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
alter table stu2 change column id id int;
alter table stu2 change column id id tinyint; --这是错的
alter table stu2 change column id ids bigint;
alter table stu2 change column id idss bigint;
举例,原本的test6的格式为int,这个时候只能往bigint转,然后再只能往float,double转,无法往下转成tinyint
-- 增加列
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)
alter table stu2 add columns(weight double,money bigint);
-- 替换列
ALTER TABLE table_name REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
-- 替换之相同列,必须所有替换后的列都比原列等于或大于数据类型转化顺序。如string double类只能转换为string double,或者double double
-- 替换之减少列 如果你想替换时候较少列 那么你减少后剩余部分 应该和之前字段 满足类型的大小关系
alter table stu2 replace columns (id bigint , name string);
比如,double,double,int就无法变成double,int
-- 替换之增加列 增加部分可以没有类型大小的关系 ,如果有对应的部分则满足类型大小的对应关系
alter table stu2 replace columns (id bigint , name string , height double, hair bigint);
DML(数据操作语言)
数据导入
load 装载数据
load data [local] inpath ‘数据的path’ [overwrite] into table student [partition (partcol1=val1,…)];
测试表
create table student (id int ,name string) row format delimited fields terminated by ‘\t’;
–load 数据之追加数据 从本地(linux)导入 是复制进去的
load data local inpath ‘/opt/module/hive/datas/student.txt’ into table student;
–load 数据之覆盖数据,也就是会将student1.txt内的数据覆盖表中本来的数据
load data local inpath ‘/opt/module/hive/datas/student1.txt’ overwrite into table student;
–load 数据之hdfs导入 hdfs导入时剪切进去的 (从根目录的student.txt直接剪切到表的数据所放的hdfs的路径下,为了避免在hdfs中出现多份数据)
load data inpath ‘/student.txt’ into table student;
注:这里要区分与创建表时的location,load是在表创建好之后上传数据,location是在创建表时去就可以去相对目录下找寻数据
insert 插入数据
--追加插入
insert into table student2 values(1,'banzhang'),(2,'haiwangbin');
--覆盖插入
insert overwrite table student values(1,'banzhang'),(2,'haiwangbin');
--查询插入 --注意:第一你所插入的表必须存在 然后你查询的字段必须满足目标表的里的字段数
insert into table student select id,name from student3;
--查询覆盖
insert overwrite table student select id,name from student3;
as select方法直接在创建表的时候就往里搞数据
create table if not exists student3
as select id, name from student;
create as select, insert into table table_name select这两个方法就是拿来创建中间表
location,在创建表的时候就指定表内数据在hdfs中的文件夹,不能是文件
create table if not exists student4(
id int, name string
)
row format delimited fields terminated by '\t'
location '/student4';
--指定location 必须是文件夹
import 导入
后续再说
数据导出
--无格式导出
insert overwrite local directory '/opt/module/hive/datas/export/student1' select * from student;
--有格式导出
insert overwrite local directory '/opt/module/hive/datas/export/student1' row format delimited fields terminated by '\t' select * from student;
--没有local 写在hdfs上
insert overwrite directory '/test6' row format delimited fields terminated by '\t' select * from student;

然后可以通过hadoop fs -get方法下载下到本地
export 导出
后续说
数据查询
SELECT [ALL | DISTINCT] select_expr, select_expr, … all是默认值 distinct 对结果集做去重
FROM table_reference --从哪个表查
[WHERE where_condition] --过滤条件
[GROUP BY col_list] --以什么分组(可以多个列)
[HAVING col_list] --以结果过滤(可以多个列)
[ORDER BY col_list] --对结果做全局排序(可以有多个列)
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list] --hive里面独有个3个by
]
[LIMIT number] --限制结果输出的行数(翻页)
select
count()
from join where group by having order by limit
运行顺寻:
from<join<where<group by<count()<having<select <order by <limit
join
可以理解为将某个表按一定要求和另一个表拼接到一起
内连接:
select
e.empno,
e.ename,
d.dname
from emp e join dept d
on e.deptno=d.deptno
则就按照e.deptno=d.deptno的地方将两者拼接,没有的则补null
左外连接和右外连接意思一样,只不过是位置的问题
左外连接
select
*
from dept d left join emp e
on d.deptno=e.deptno
则以deft为准,emp中没有对应到deft的就不显示
多表连接
多表连接查询
hive (default)>SELECT e.ename, d.dname, l.loc_name
FROM emp e
JOIN dept d
ON d.deptno = e.deptno
JOIN location l
ON d.loc = l.loc;
笛卡尔积
笛卡尔集会在下面条件下产生
(1)省略连接条件
(2)连接条件无效
(3)所有表中的所有行互相连接
hive (default)> select empno, dname from emp, dept;