所谓的暗网在上篇文章已经简单介绍,是指目前搜索引擎爬虫按照常规方式很难抓取到的网页。在网络中很多网站的内容是以数据库方式进行存储的,而搜索引擎爬虫依赖页面中的链接关系发现新页面。比例携程网中的机票数据,很难有直接显示的链接指向数据库内的记录,而是以网站提供组合查询界面,在用户输入想要查询的数据之后,才能够获取相关的数据。这些数据是网络爬虫无法搜索到的。所以,为了实现这些暗网数据的索引,需要相对应地研究暗网爬虫。暗网爬虫可以从数据库中将暗网数据进行挖掘出来,从而增加信息的覆盖范围。
暗网爬虫需要做人工模拟,填写这些查询界面的的内容,提交表单。其中主要涉及两个方面,其一是查询组合过多,为减少被访问网站的压力,需要精心组合查询;第二,有的查询是文本框,如图书搜索中需要输入书名,那么爬虫如何才能够填入合适的内容呢?这也是一大挑战。
1)查询组合
搜索网站提供的多个查询输入框,不同输入框表示不同的属性,通过对这些属性的组合来缩小搜索范围。google提出的方法称为“富含信息查询模板”的技术。所谓的查询模板是对部分属性赋值。而其他属性不赋值,则这几个赋值的属性一起构成了查询模板。对于固定的查询模板,如果给模板内的每个属性都赋值,形成不同的查询组合,提交给搜索引擎,获得的返回结果如果内容相差甚大,则这个查询模板是富含信息的查询模板。举个例子:有职位和行业两个属性,其中职位有3种不同的赋值,行业有2种不同的赋值,则可以产生6种的查询组合方式。将这6个查询提交搜索引擎,观察其返回结果的变化情况,如果大部分返回结果内容相似或者相同,则该查询模板不富含信息。否则可以认识是富含信息的查询模板。上述规定的出发点是:如果返回结果内容重复太多,有可能是该查询模板维度太高,很多组合并没有搜索结果;另一种可能是构造的查询本身是无效的或者错误的,搜索系统返回了错误的页面。但是这又有一个问题:需要对所有查询模板进行试探,判断其是否是富含信息的查询模板。为了进一步减少提交的查询模板数量,Google采用ISIT算法。
该算法:先从1维开始,判断是否是富含信息模板,如果是的话,将该1维模板拓展到2维,再次依次考察对应的二维模板,如此类推,逐渐增加维数,直到再也找不到富含信息模板为止。该算法和经典的Apriori规则挖掘算法有异曲同工之处。
2)文本框填写问题
对于输入中的文本框,需要爬虫自动生成查询,常用的流程图如下:
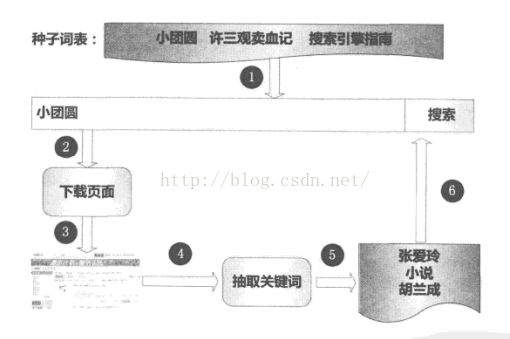
在爬虫运转起来之前,由于对目标网站一无所知,所以需要一些人工提示。在上述例子中通过人工观察网站进行定位,提供一个与网站内容相关的初始种子查询关键词表。对于不同的网站需要人工提供不同的词表。以此作为爬虫继续工作的基础条件。爬虫根据初始种子词表,向搜索引擎提交查询,并下载返回的结果,之后再从返回的结果页面中自动挖掘出相关的关键词,并形成一个新的查询列表,依次将挖掘出的查询提交给搜索引擎。如此往复,直到无法下载到新的内容为止。通过这种人工启发结合递归迭代的方式,尽可能覆盖数据库里面的记录。